Anunciando gatilhos de atualização de tabelas no Lakeflow Jobs
Reduza os custos acionando jobs para serem executados somente quando uma tabela for atualizada
- Apresentando os gatilhos de atualização de tabelas: acione jobs automaticamente sempre que as tabelas especificadas forem atualizadas
- Capacite equipes de dados descentralizadas, permitindo que os usuários orquestrem pipelines orientados a eventos de forma independente dos agendamentos de origem
- Melhore a eficiência acionando jobs assim que os dados chegarem, reduzindo a latência e diminuindo os custos
A Databricks tem o prazer de anunciar que os gatilhos de atualização de tabelas já estão disponíveis para todos no Lakeflow Jobs. Muitas equipes de dados ainda dependem de cron jobs para estimar quando os dados estão disponíveis, mas essa adivinhação pode levar ao desperdício de recursos computacionais e a insights tardios. Com os gatilhos de atualização de tabelas, seus jobs são executados automaticamente assim que as tabelas especificadas são atualizadas, permitindo uma maneira mais responsiva e eficiente de orquestrar pipelines.
Acione jobs instantaneamente quando os dados mudam
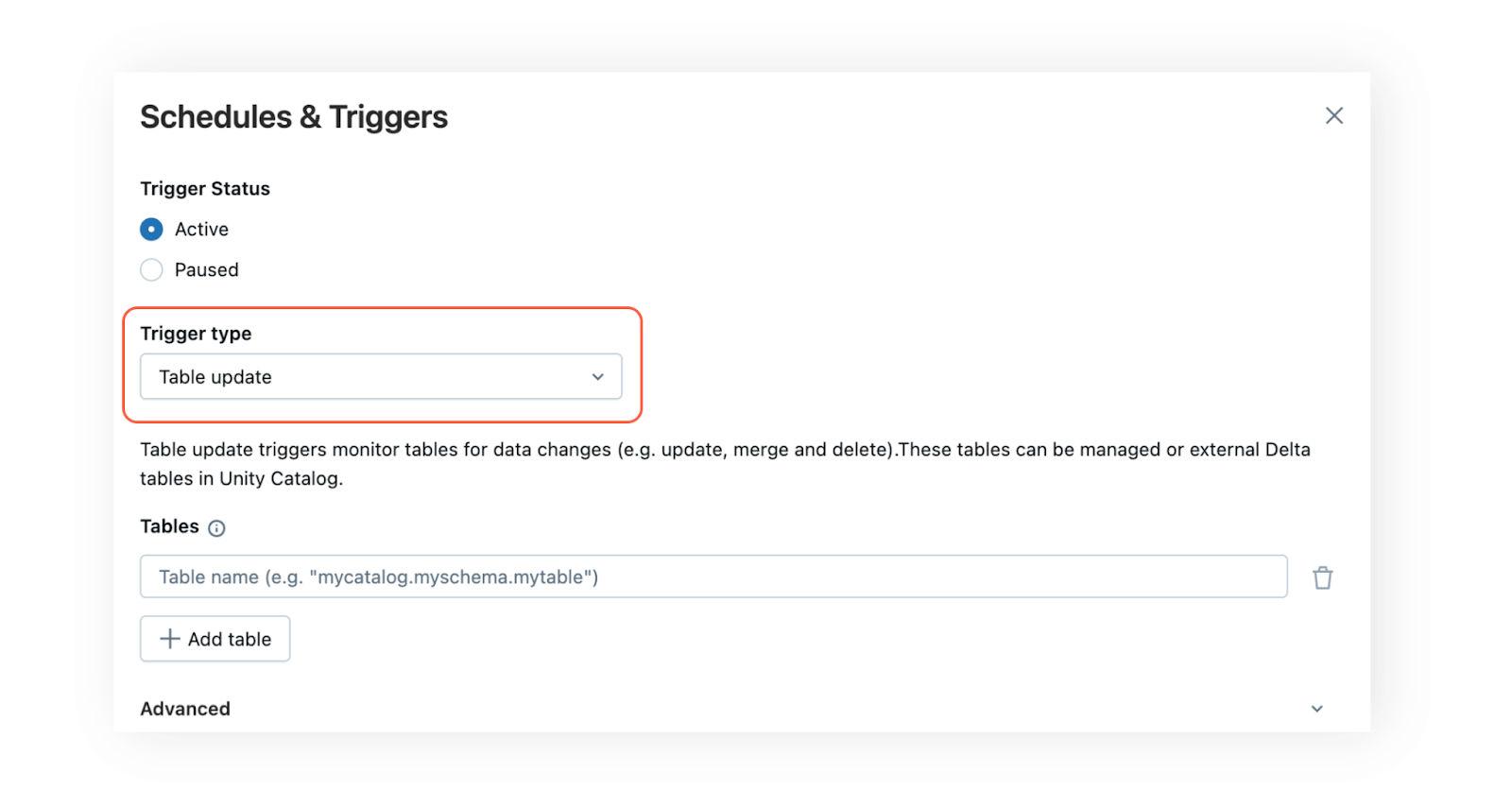
Gatilhos de atualização de tabela permitem acionar tarefas com base em atualizações de tabela. Seu job é iniciado assim que os dados são adicionados ou atualizados. Para configurar um gatilho de atualização de tabela no Lakeflow Jobs, basta adicionar uma ou mais tabelas conhecidas do Unity Catalog usando o tipo de gatilho “Table update” no menu Schedules & Triggers. Uma nova execução será iniciada assim que as tabelas especificadas forem atualizadas. Se várias tabelas forem escolhidas, você poderá determinar se o job deverá ser executado após a atualização de uma única tabela ou somente quando todas as tabelas selecionadas forem atualizadas.
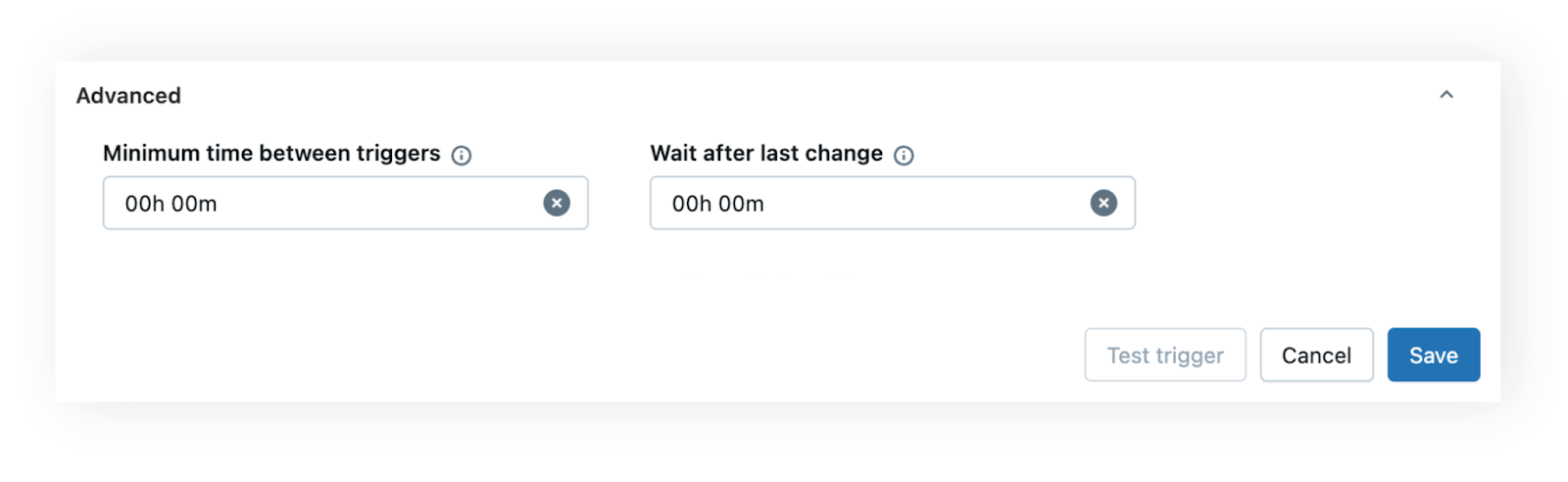
Para lidar com cenários em que as tabelas recebem atualizações frequentes ou picos de dados, você pode aproveitar as mesmas configurações de tempo avançadas disponíveis para gatilhos de chegada de arquivos: tempo mínimo entre gatilhos e esperar após a última alteração.
- O tempo mínimo entre gatilhos é útil quando uma tabela é atualizada com frequência e você quer evitar o início de tarefas com muita frequência. Por exemplo, se um pipeline de ingestão de dados atualiza uma tabela algumas vezes por hora, definir um intervalo de 60 minutos impede que o job seja executado mais de uma vez dentro dessa janela de tempo.
- Aguardar após a última alteração ajuda a garantir que todos os dados foram carregados antes de o job começar. Por exemplo, se um sistema upstream grava vários lotes em uma tabela ao longo de alguns minutos, definir um “wait after last change” curto (por exemplo, 5 minutos) garante que o job seja executado apenas uma vez quando a gravação for concluída.
Essas configurações oferecem controle e flexibilidade para que suas tarefas sejam oportunas e eficientes em termos de recursos.
Reduza os custos e a latência eliminando a adivinhação
Ao substituir os agendamentos cron por gatilhos em tempo real, você reduz o desperdício de recursos computacionais e evita atrasos causados por dados desatualizados. Se os dados chegarem antes, o job será executado imediatamente. Se houver um atraso, você evita o desperdício de recursos de computação com dados desatualizados.
Isso é especialmente impactante em grande escala, quando as equipes operam em fusos horários diferentes ou gerenciam pipelines de dados de alto volume. Em vez de superprovisionar recursos computacionais ou arriscar a desatualização dos dados, você se mantém alinhado e responsivo ao reagir às mudanças em tempo real nos seus dados.
Potencialize pipelines descentralizados e orientados a eventos
Em grandes organizações, talvez você nem sempre saiba de onde vêm os dados de origem ou como são produzidos. Com os gatilhos de atualização de tabelas, você pode criar pipelines reativos que operam de forma independente, sem um acoplamento rígido com os agendamentos de origem. Por exemplo, em vez de agendar a atualização de um dashboard para as 8h todos os dias, você pode atualizá-lo assim que novos dados chegarem, garantindo que seus usuários sempre vejam os insights mais recentes. Isso é especialmente poderoso em ambientes de Data Mesh, onde a autonomia e o autoatendimento são fundamentais.
Os gatilhos de atualização de tabela se beneficiam da observabilidade integrada no Lakeflow Jobs. Os metadados da tabela (por exemplo, carimbo de data/hora do commit ou versão) são expostos a tarefas downstream por meio de parâmetros, garantindo que cada tarefa use o mesmo snapshot consistente de dados. Como os gatilhos de atualização de tabela dependem de alterações na tabela upstream, entender as dependências de dados é crucial. A linhagem de dados automatizada do Unity Catalog oferece visibilidade, mostrando quais jobs leem de quais tabelas. Isso é essencial para tornar os gatilhos de atualização de tabela confiáveis em grande escala, ajudando as equipes a entenderem as dependências e a evitar impactos downstream não intencionais.
Os gatilhos de atualização de tabelas são o recurso mais recente em um conjunto crescente de funcionalidades de orquestração no Lakeflow Jobs. Combinados com o fluxo de controle, gatilhos de chegada de arquivos e observabilidade unificada, eles oferecem uma base flexível, escalável e moderna para pipelines mais eficientes.
Introdução
Os gatilhos de atualização de tabelas já estão disponíveis para todos os clientes da Databricks que usam o Unity Catalog. Para começar:
- Obtenha informações detalhadas sobre gatilhos no Lakeflow Jobs
- Saiba mais sobre o Lakeflow Jobs
- Crie sua primeira tarefa com nosso Guia de Início Rápido
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.