Modo em Tempo Real do Apache Spark para Jogos: Uma Maneira Melhor de Fazer Sessionização em Tempo Real
Crie pipelines de streaming com estado que rastreiam milhões de sessões de dispositivos de jogos ativos, gerando heartbeats em tempo real com latência de subsegundos no Apache Spark
por Neha Prabhu e Murali Talluri
- Explore como o Modo de Tempo Real do Apache Spark™ permite a sessionalização de jogos em tempo real para milhões de sessões de dispositivos ativos
- Saiba como os temporizadores do transformWithState alimentam heartbeats proativos e orientados por temporizador, gerando saídas de acordo com um cronograma, independentemente dos dados de entrada
- Veja como o Modo de Tempo Real combinado com o transformWithState substitui aplicações internas personalizadas e mecanismos de streaming externos, oferecendo precisão de subsegundos tanto para o processamento de entrada quanto para a saída orientada por temporizador.
No setor de jogos, cada milissegundo conta. Para impulsionar a personalização no jogo, alimentar mecanismos de recomendação e tomar decisões dinâmicas de agendamento de conteúdo, as plataformas precisam processar dados de sessão de milhões de jogadores em todo o mundo com latência abaixo de um segundo.
Hoje, atender a esses requisitos de latência ultrabaixa não exige mais uma arquitetura fragmentada com vários mecanismos. Neste blog, exploramos uma implementação real do Apache Spark Real-Time Mode. Ao aproveitar o novo operador transformWithState para lógica de estado complexa, demonstramos como o Spark oferece desempenho de milissegundos de ponta a ponta. Descubra como sua equipe pode acelerar o desenvolvimento e criar aplicativos operacionais de missão crítica usando o ecossistema familiar do Structured Streaming.
Visão geral do caso de uso
Do início ao fim do jogo: por que o rastreamento de sessão é importante
Para plataformas de jogos, saber quais dispositivos estão ativos e por quanto tempo não é apenas uma preocupação de infraestrutura — isso impulsiona os negócios. Os dados de sessão em tempo real alimentam experiências personalizadas no jogo, motores de recomendação, decisões de agendamento de conteúdo e fornecem sinais de integridade do dispositivo em milhões de consoles e PCs. As equipes de operações os utilizam para aplicar controles parentais e detectar padrões de sessão anômalos.
Fundamentos dos eventos de sessão
Os eventos de sessão de consoles e PCs fluem para tópicos do Kafka. Cada evento carrega um ID de dispositivo e um ID de sessão. O ID do dispositivo identifica o console ou PC; o ID da sessão identifica a sessão de jogo. Apenas uma sessão pode estar ativa por dispositivo a qualquer momento.
O pipeline lida com quatro cenários:
- Início da sessão (GameStart): um evento de início chega. O pipeline armazena o ID da sessão e o horário de início, emite um evento SessionActive e registra um timer de tempo de processamento de 30 segundos. Se outra sessão já estiver ativa para esse dispositivo, ela encerrará a antiga primeiro.
- Heartbeat da sessão (Active): o timer é acionado a cada 30 segundos. O pipeline calcula now - start_time, emite um heartbeat SessionActive com a duração atual e registra o timer novamente.
- Fim da sessão (GameEnd): um evento de fim chega correspondendo à sessão ativa. O pipeline emite um SessionEnd com a duração final e limpa o estado.
- Timeout da sessão (GameSessionTimeout): o timer é acionado e a duração calculada excede um limite máximo configurável. Em vez de emitir um heartbeat, o pipeline emite um SessionEnd com um motivo de timeout e limpa o estado.
Por que o Spark com Real-Time Mode é um divisor de águas
O Spark Structured Streaming no modo micro-batch pode lidar com a sessionalização com estado, mas quando o caso de uso exige precisão abaixo de um segundo tanto para o processamento de entrada quanto para a saída orientada por timer, o micro-batch deixa a desejar. No passado, essa lacuna levava as equipes a gerenciar mecanismos especializados adicionais ou a criar soluções personalizadas.
Com o Apache Flink: o gerenciamento de estado e os timers podem ser implementados, mas adotar o Flink significa adotar todo um ecossistema paralelo: um cluster separado, back-end de estado, modelo de implantação, pilha de monitoramento e base de código, tudo junto com a plataforma Databricks. O resultado é a fragmentação da infraestrutura, complexidade operacional e o custo de operar e manter uma equipe para um segundo mecanismo de streaming.
Com soluções internas personalizadas: algumas equipes criam seu próprio serviço de sessionalização — por exemplo, um sistema de atores baseado em Akka onde cada dispositivo recebe um ator que gerencia o estado da sessão, timers e emissão de heartbeat. Eles trazem a mesma sobrecarga operacional e de infraestrutura do Flink, com um desafio adicional: não escalam. Distribuir milhões de atores com estado entre nós é algo que você mesmo precisa desenvolver. Esses sistemas funcionam inicialmente, mas com o tempo acabam em modo de manutenção — estáveis o suficiente para rodar, mas difíceis de estender.
Hoje, o Real-Time Mode elimina essa lacuna para os clientes — oferecendo precisão abaixo de um segundo com as mesmas APIs do Spark que as equipes já usam, tudo em um único mecanismo unificado.
Real-Time Mode com transformWithState
transformWithState é um operador de última geração no Spark Structured Streaming que torna o processamento com estado complexo flexível e escalável. Os principais recursos incluem gerenciamento de estado orientado a objetos, tipos de dados compostos, lógica orientada por timer, suporte automático a TTL e evolução de esquema. Combinado com o Real-Time Mode, ele oferece precisão abaixo de um segundo tanto para o processamento de entrada quanto para a saída orientada por timer.
O caso de uso de sessionalização de jogos exige duas coisas:
- Processamento reativo: lidar com o início e o fim das sessões à medida que chegam.
- Saída proativa: produzir um heartbeat para cada sessão ativa em um cronograma, independentemente dos dados de entrada
transformWithState oferece ambos em uma única classe StatefulProcessor com dois métodos dedicados.
O handleInputRows() reage aos eventos recebidos do Kafka — processando o início e o fim das sessões, mantendo o estado de sessionalização à medida que os eventos chegam.
O handleExpiredTimer() lida com tudo o que acontece no intervalo — sendo acionado para produzir saídas proativas, como heartbeats e timeouts, independentemente de novos dados terem chegado ou não.
Como funciona: criando um pipeline de sessionalização de jogos em tempo real
Visão geral da arquitetura do pipeline
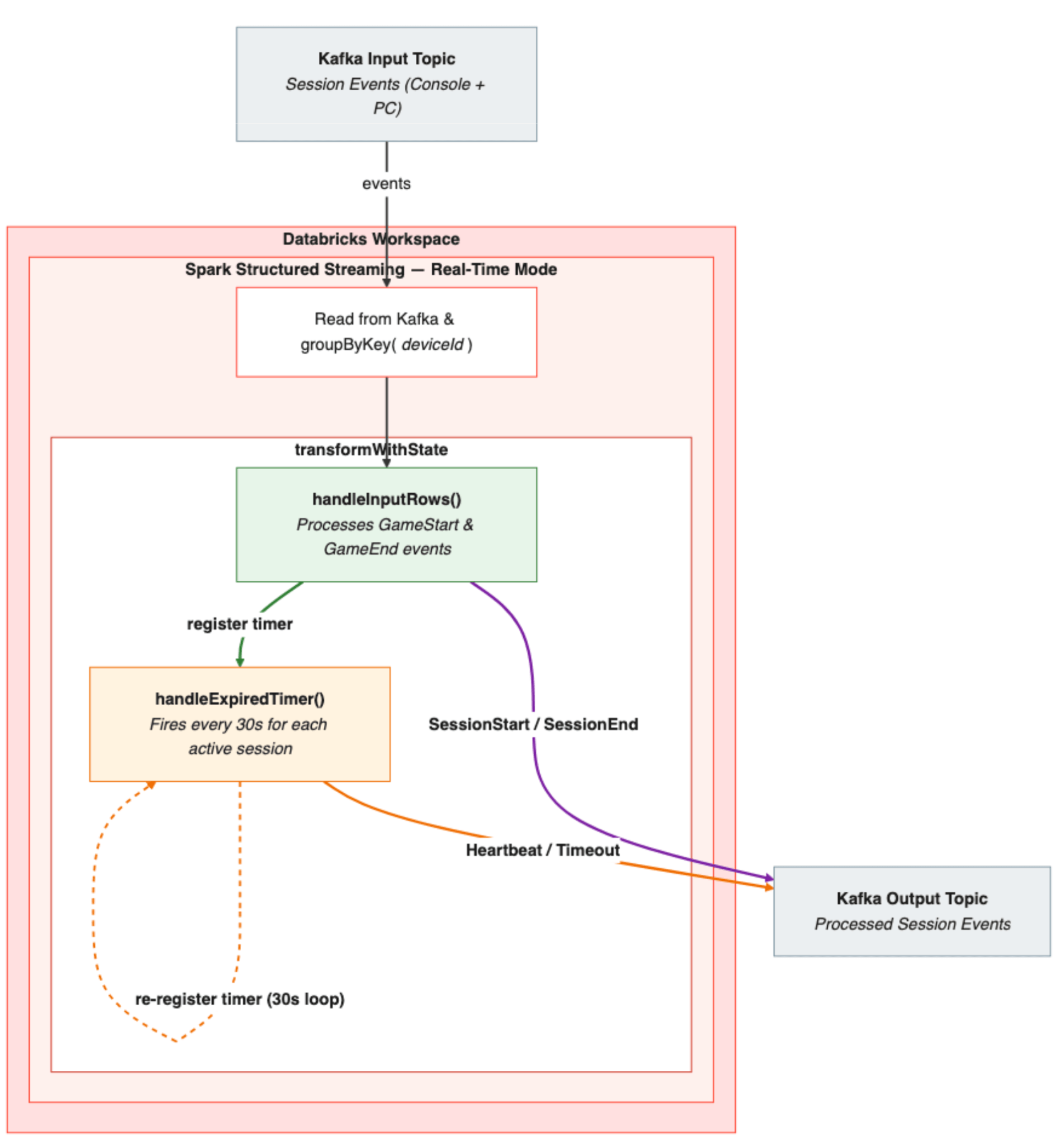
- Ingestão de eventos: os eventos de sessão (inícios e fins) de consoles e PCs chegam aos tópicos do Kafka. Cada evento é analisado e um deviceId é derivado do identificador específico do dispositivo.
- Agrupamento com estado: o stream é agrupado por deviceId — garantindo que todos os eventos de um determinado dispositivo sejam roteados para a mesma instância do processador com estado.
- Processamento: o transformWithState aplica o processador de sessionalização, que usa um MapState chaveado pelo ID da sessão para rastrear a sessão ativa por dispositivo. Quando um início de sessão chega, o handleInputRows() armazena o estado da sessão, emite um evento SessionActive e registra o primeiro timer de 30 segundos. A partir desse momento, o handleExpiredTimer() assume o controle — emitindo heartbeats a cada 30 segundos e verificando timeouts. Quando um evento de fim de sessão chega, o handleInputRows() o retoma — emitindo um SessionEnd com a duração final, limpando o estado e interrompendo o loop do timer.
- Saída: os eventos de sessão processados — inícios, heartbeats, fins e timeouts — são gravados como JSON em um tópico de saída do Kafka, prontos para consumo downstream.
Aprofundamento na implementação
Para uma análise detalhada da arquitetura, implementação do código e considerações de produção, consulte este blog complementar — onde detalhamos o código do StatefulProcessor, o ciclo de vida do timer, os padrões de gerenciamento de estado e o monitoramento com o StreamingQueryListener. Os resultados a seguir ilustram as características de taxa de transferência e latência do pipeline, destacando as diferenças significativas de latência entre o modo micro-batch (MBM) e o Real-Time Mode (RTM):
Taxa de transferência
Para validar o pipeline sob uma carga realista, testamos com a seguinte taxa de transferência sustentada:
Métrica (por minuto) | Valor |
Eventos de entrada (inícios + fins de sessão) | ~500K |
Número de sessões ativas | ~4M |
Registros de heartbeat emitidos | ~8M |
Amplificação de entrada para saída | ~16x |
A grande maioria das saídas não é acionada por dados de entrada — ela é gerada inteiramente pelo handleExpiredTimer(), emitindo heartbeats proativamente em um cronograma.
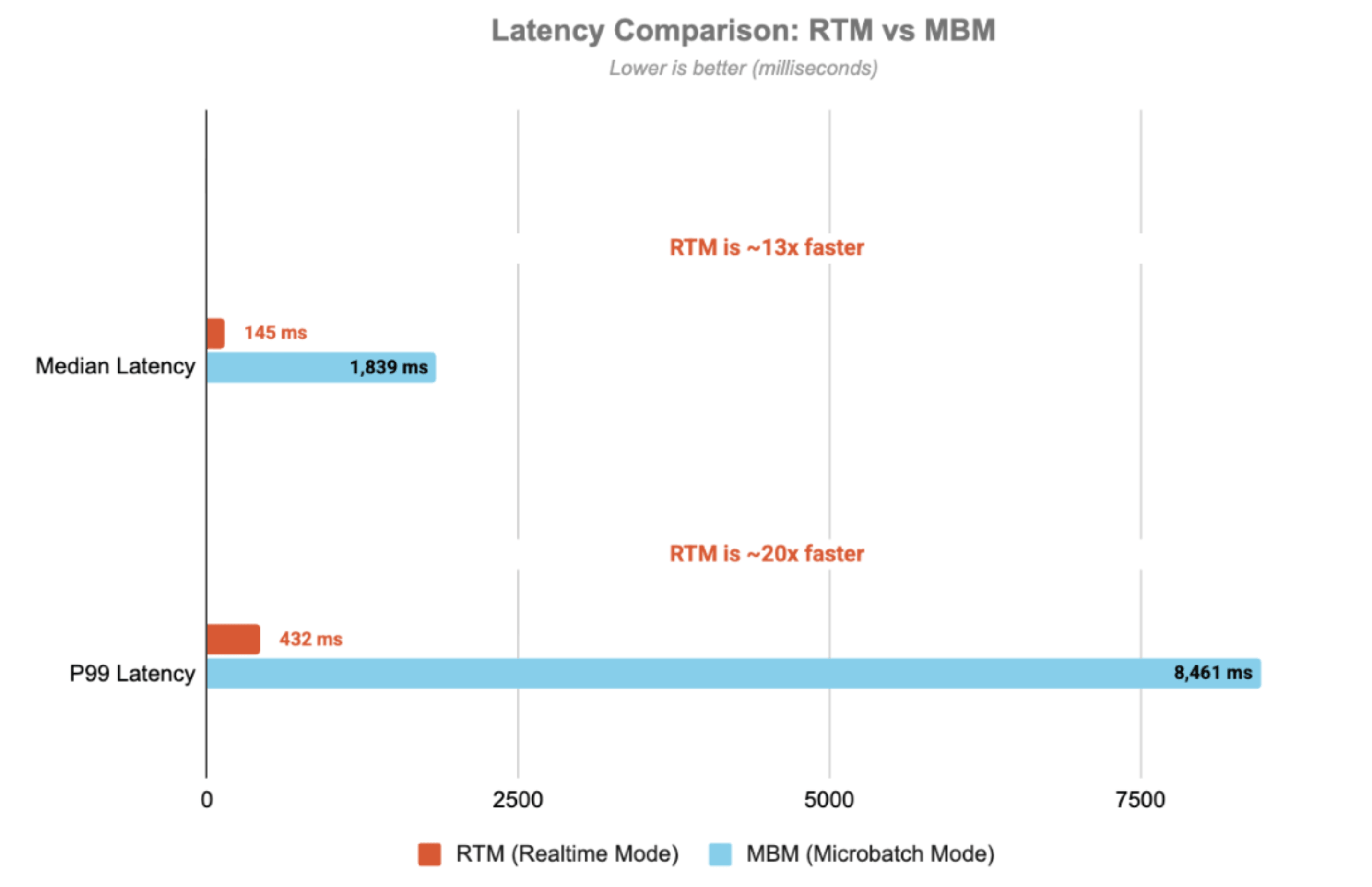
Latência
A latência é medida de ponta a ponta — do timestamp do tópico de entrada do Kafka ao timestamp do tópico de saída. Com o Real-Time Mode, o pipeline atinge uma latência p99 de 432 ms — 20 vezes mais rápido que o modo micro-batch.
Conclusão
Casos de uso como a sessionalização de jogos exigem pipelines que vão além do processamento de eventos recebidos — emitindo heartbeats proativamente em um cronograma, rastreando milhões de sessões simultâneas e gerenciando o estado de forma eficiente. O padrão não se limita a jogos. Qualquer carga de trabalho que precise de saídas acionadas por temporizadores — heartbeats de IoT, rastreamento de sessões, alertas em tempo real, monitoramento de equipamentos — pode ser criada da mesma forma.
Temporizadores no transformWithState tornam isso possível. Uma única classe StatefulProcessor lida com todo o ciclo de vida da sessão — processamento reativo de entrada e saída proativa acionada por temporizadores. Combinado com o Real-Time Mode, os registros de entrada são processados e os temporizadores são acionados com precisão de subsegundos — não no próximo intervalo de lote, mas agora. Tudo dentro do Databricks, sem a necessidade de um segundo mecanismo.
Se você já executa pipelines do Structured Streaming no modo micro-batch e está buscando um segundo mecanismo para obter menor latência, experimente o Real-Time Mode primeiro. A mudança é apenas uma alteração de trigger — sem reescritas, sem replataformização:
Experimente você mesmo:
- Notebook complementar com gerador de dados: execute o pipeline completo de sessionalização de jogos e compare você mesmo a latência de MBM vs RTM.
- Guia da API transformWithState: variáveis de estado, temporizadores, TTL e evolução de esquema
- Referência do Real-Time Mode: operadores suportados, modos de execução, fontes, destinos e suporte a linguagens
O Real-Time Mode agora está em Disponibilidade Geral.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.