Apontadores de BI Serving; Maximizando para Desempenho e TCO
Um guia de baixo para cima para a pilha de BI Databricks — do layout físico a métricas governadas até materialização ciente de agregações
por Chris Koester
- Estruture sua camada física com esquemas em estrela, clusterização líquida e Otimização Preditiva para acelerar consultas de BI.
- Defina métricas de negócios governadas uma vez com as Visualizações de Métricas do Unity Catalog — uma camada semântica headless que atende a todas as ferramentas de BI, espaços Genie e agentes de IA a partir de uma única fonte de verdade.
- Habilite a materialização ciente de agregações para obter desempenho de pré-agregação no estilo OLAP sem construir e manter tabelas de agregação separadas.
Seus dashboards de BI estão lentos e otimizá-los está custando muito tempo e dinheiro.
É um padrão familiar. Uma consulta de dashboard leva 30 segundos, então alguém cria uma tabela agregada para acelerar. Essa tabela precisa de um pipeline de atualização. O pipeline precisa de monitoramento. Em seguida, uma segunda ferramenta de BI precisa dos mesmos dados em uma forma ligeiramente diferente, então alguém cria outra tabela agregada usando um pipeline separado. Em pouco tempo, você está gerenciando uma proliferação de agregados, extrações e camadas semânticas específicas da ferramenta — cada uma com sua própria janela de obsolescência, suas próprias lacunas de governança e sua própria linha no faturamento de computação.
Cargas de trabalho de BI são diferentes de outras cargas de trabalho analíticas. Elas são altamente concorrentes, sensíveis à latência e repetitivas em seus padrões de consulta. Essa combinação exige uma abordagem deliberada para modelar, armazenar, otimizar e servir dados. A boa notícia: Databricks fornece um stack completo para servir BI — desde o layout físico dos dados até uma camada semântica governada — e cada camada potencializa os ganhos de desempenho da camada abaixo dela.
Este post percorre esse stack de baixo para cima, com orientação prática sobre onde focar para as maiores melhorias no desempenho e custo das consultas.
O Stack de BI Serving
Antes de mergulhar em cada camada, aqui está a imagem completa:
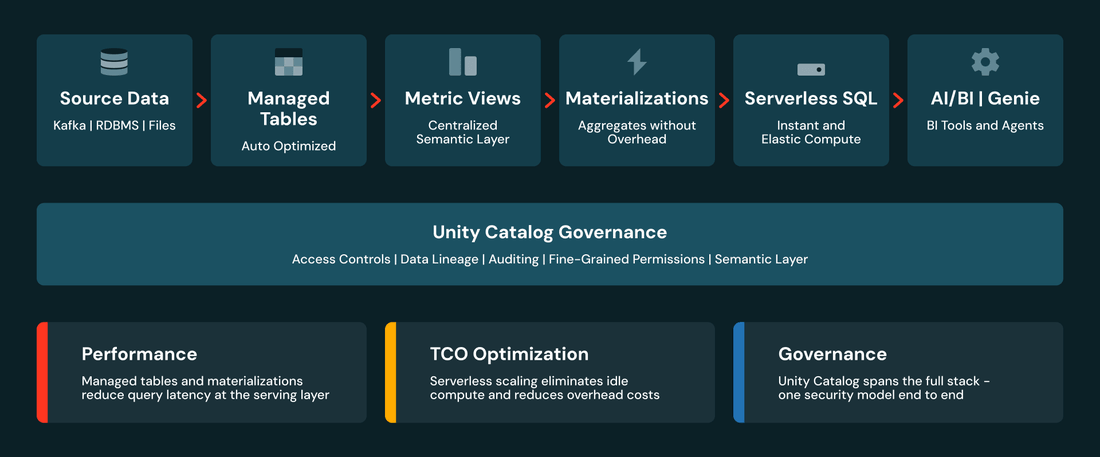
Unity Catalog fornece governança em todo o processo — linhagem e controle de acesso desde os dados brutos até a semântica e o consumo. Cada camada aborda um aspecto diferente de desempenho e custo. Vamos percorrê-las.
Otimize a Camada Física
A camada física é onde a maior parte do desempenho de BI é ganha ou perdida. Acertando isso, cada consulta se beneficia — antes mesmo de você tocar na camada semântica.
Comece com Modelagem Dimensional
Esquemas estrela continuam sendo o padrão ouro para o desempenho de consultas de BI. Tabelas de dimensão amplas e desnormalizadas unidas a tabelas de fatos via chaves substitutas fornecem ao otimizador de consulta caminhos de junção limpos e previsíveis.
Databricks suporta totalmente os construtos de modelagem relacional de que você precisa: restrições de chave primária e estrangeira (com RELY para dicas do otimizador), colunas de identidade para chaves substitutas e restrições de CHECK e NOT NULL. Se você está seguindo uma arquitetura medallion, mantenha seus modelos normalizados ou Data Vault no Silver e construa esquemas estrela desnormalizados no Gold para consumo de BI.
Para padrões detalhados de implementação — tratamento de SCD Tipo-1 e Tipo-2, ETL de tabelas de fatos com MERGE, dimensões de chegada tardia — consulte a série de posts do blog Implementando um Data Warehouse Dimensional no Databricks SQL.
Use Tabelas Gerenciadas
As tabelas gerenciadas do Unity Catalog são a base para todo o resto neste stack. Unity Catalog gerencia todas as responsabilidades de leitura, gravação, armazenamento e otimização para tabelas gerenciadas. Isso desbloqueia recursos automáticos que você não obtém com tabelas externas: Otimização Preditiva (abordada abaixo) está habilitada por padrão. Clustering líquido automático seleciona chaves de clustering que se adaptam conforme os padrões de consulta mudam. O cache de metadados está sempre ativo, reduzindo solicitações de armazenamento em nuvem e acelerando o planejamento de consultas.
Use tabelas gerenciadas em toda a plataforma — não apenas para servir BI, mas nas camadas Bronze, Silver e Gold. Elas são o tipo de tabela padrão no Unity Catalog, e os benefícios de desempenho e governança se acumulam com todas as outras otimizações neste stack.
Aplique Clustering Líquido
Clustering líquido substitui particionamento estático e Z-ORDER manual — e ao contrário dessas abordagens, você pode redefinir chaves de clustering sem reescrever dados existentes. Adicione CLUSTER BY (col1, col2) na criação da tabela ou use ALTER TABLE em tabelas existentes. Se você não tem certeza de quais colunas escolher, CLUSTER BY AUTO permite que a Otimização Preditiva selecione chaves com base nos padrões de consulta observados.
Para cargas de trabalho de BI, clusterize em suas colunas de filtro e junção mais comuns — chaves de data, região, categoria de produto. Você pode selecionar até quatro colunas e, se duas colunas forem altamente correlacionadas, inclua apenas uma. Quando os dashboards filtram em colunas de cluster, o clustering líquido melhora o desempenho da consulta através do pulo de dados.
Deixe a Otimização Preditiva Lidar com o Resto
A Otimização Preditiva executa automaticamente OPTIMIZE, VACUUM e coleta de estatísticas em tabelas que se beneficiariam dessas operações — para que você não precise agendar esses trabalhos. Ela coleta estatísticas de pulo de dados Delta e estatísticas do otimizador de consulta durante as gravações Photon, e preenche estatísticas para tabelas existentes. Em cargas de trabalho observadas, isso proporcionou uma melhora média de desempenho de 22%. Para cargas de trabalho de BI com padrões de filtro repetitivos, o impacto é especialmente significativo — melhores estatísticas significam melhor pulo de dados e planos de consulta mais eficientes.
Habilite a Otimização Preditiva no nível do catálogo e deixe-a rodar. Usar a Otimização Preditiva é uma das otimizações de maior retorno e menor esforço que você pode fazer.
O resultado: Consultas de BI escaneiam menos dados, juntam-se de forma mais eficiente e custam menos para executar — e você ainda não tocou na camada semântica.
Metric Views: Defina Suas Métricas Uma Vez
É aqui que as coisas ficam interessantes. A maioria das organizações tem as mesmas métricas de negócios definidas em vários lugares — um cálculo de receita em uma ferramenta de BI, um ligeiramente diferente em outra, uma terceira variante em um notebook SQL que alguém escreveu no trimestre passado. Cada definição se desvia independentemente. Ninguém tem certeza de qual está correta.
Metric Views no Unity Catalog resolvem isso fornecendo uma camada de BI sem cabeça — uma única camada semântica governada onde você define seu modelo de dados e KPIs uma vez, independentemente de qualquer ferramenta de BI específica. Você os define centralmente em SQL ou na interface de apontar e clicar no Unity Catalog Explorer. Dashboards de IA/BI, Genie, notebooks SQL e ferramentas de BI de terceiros resolvem métricas a partir das mesmas definições. Defina uma métrica uma vez, e cada consumidor — humano ou IA — obtém a mesma resposta.
Metric Views vão além das definições centralizadas de métricas — os metadados semânticos são o que as diferenciam. Campos como display_name, comment e synonyms dão aos sistemas de IA o contexto que eles precisam para interpretar corretamente as perguntas de negócios. Quando um usuário pergunta ao Genie "qual foi nossa receita na semana passada?", essas anotações são como o Genie mapeia a linguagem natural para a medida e as dimensões corretas. Sem prompts personalizados, sem glossário separado. O mesmo se aplica a agentes de IA construídos no Databricks — qualquer agente com acesso ao Unity Catalog pode descobrir e consultar métricas governadas através da camada semântica em vez de SQL codificado. Quanto mais ricos seus metadados, mais precisamente a IA fornece a resposta correta.
Aqui está um exemplo usando uma tabela do sistema, já que todo cliente Databricks tem acesso — mas o mesmo padrão se aplica a KPIs de negócios como receita, volume de pedidos ou retenção de clientes. Esta Metric View calcula métricas de warehouse DBSQL:
Consumidores consultam a Metric View usando MEASURE() para referenciar as definições de métricas governadas:
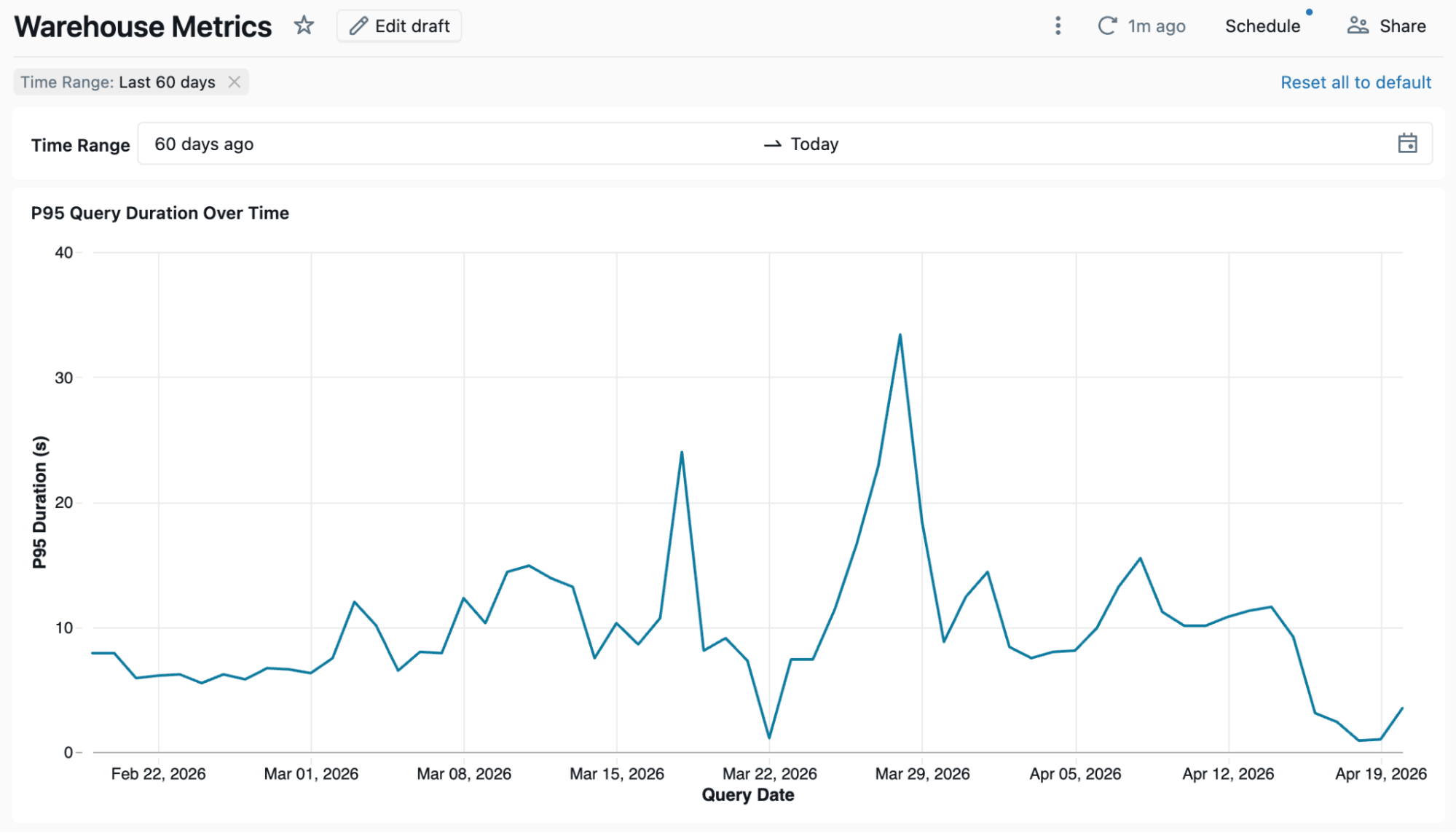
As métricas são definidas uma vez na Metric View. Cada dashboard, espaço Genie ou notebook que consulta metv_dbsql_metrics obtém o mesmo resultado. Abaixo está um dashboard usando a metric view como fonte.
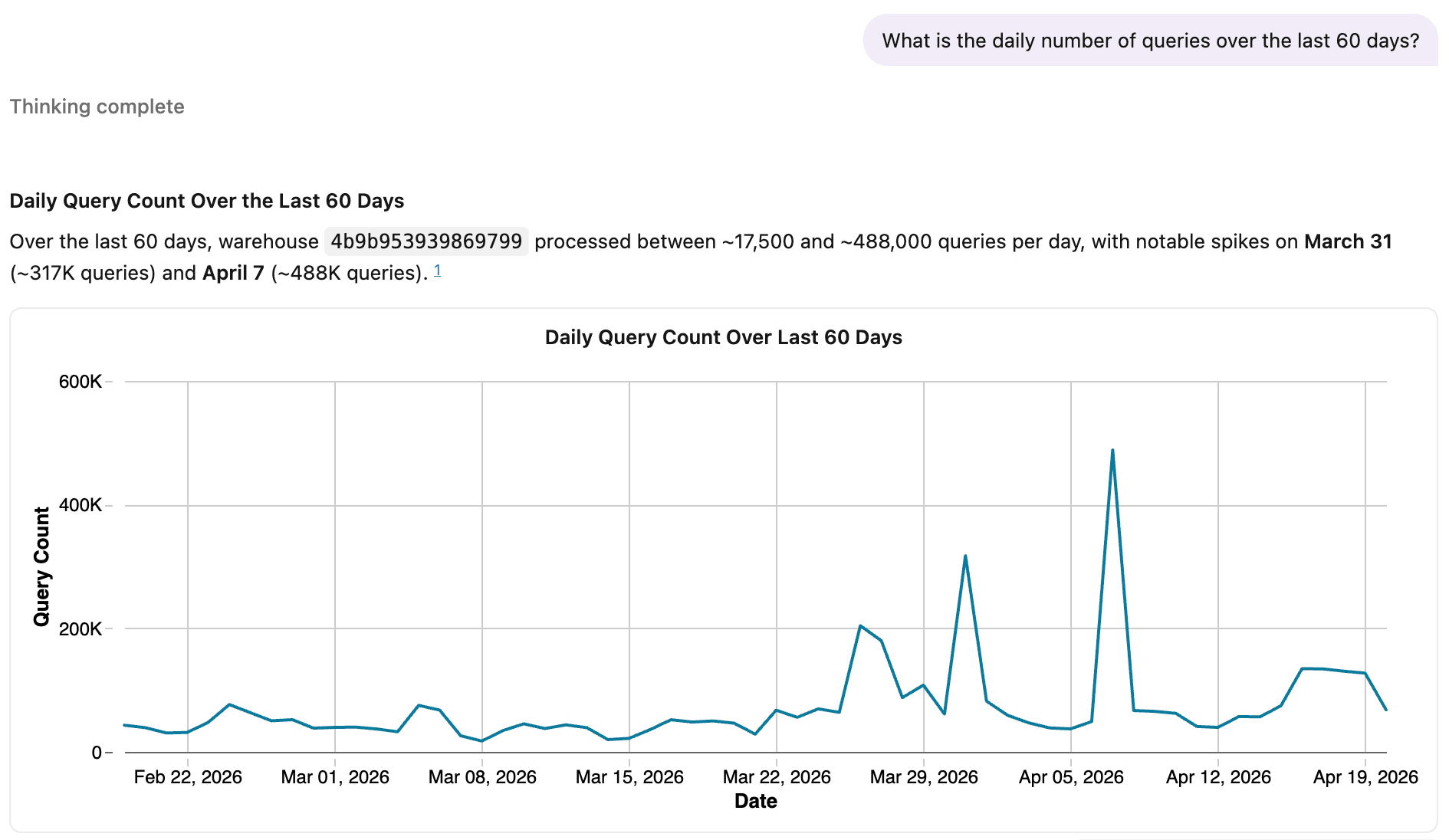
Veja o Genie usando a mesma visualização de métricas.
Para equipes com definições de métricas espalhadas por várias ferramentas de BI, as Visualizações de Métricas oferecem um caminho para consolidar a camada semântica no Databricks. Em vez de manter a lógica de métricas separada em cada ferramenta, você a define uma vez no Unity Catalog e conecta suas ferramentas de BI a essa fonte governada.
A implementação principal é de código aberto no Apache Spark™ (SPARK-54119), com suporte futuro para Unity Catalog OSS — assim, você está construindo sobre um padrão aberto sem dependência de fornecedor. Essa abertura se torna mais importante à medida que a IA assume mais da carga de trabalho de BI. Agentes consultando seus dados precisam de uma definição consistente e legível por máquina do que cada métrica significa, e um padrão aberto permite que qualquer ferramenta ou agente — não apenas os específicos do fornecedor — raciocine sobre as mesmas métricas governadas.
Materialização de Visualização de Métricas: Desempenho OLAP Sem a Sobrecarga
Tradicionalmente, quando os dashboards de BI eram muito lentos, a resposta era construir tabelas agregadas. Você criaria visualizações materializadas ou tabelas de pré-agregação personalizadas sobre seu esquema estrela, configuraria pipelines de atualização e redirecionaria suas ferramentas de BI para as novas tabelas. Funcionava, mas adicionava toda uma camada de objetos e pipelines para manter — e toda vez que a lógica de agregação mudava, você tinha que atualizar as consultas da ferramenta de BI para corresponder.
A materialização de Visualização de Métricas oferece uma alternativa mais simples. Quando você habilita a materialização em uma Visualização de Métricas, a plataforma mantém automaticamente os resultados pré-agregados por trás das mesmas definições de métricas que suas ferramentas de BI já consultam — sem tabelas agregadas separadas para construir, sem consultas de ferramentas de BI para refatorar. Veja o que acontece nos bastidores:
- Pré-agregação automática: Resultados de métricas são pré-computados e armazenados
- Atualização incremental: Métricas permanecem atualizadas sem recomputação completa
- Reescrita inteligente de consultas: O motor roteia consultas para a melhor materialização disponível
- Roteamento transparente: Usuários consultam métricas da mesma forma — o sistema fornece o caminho mais rápido
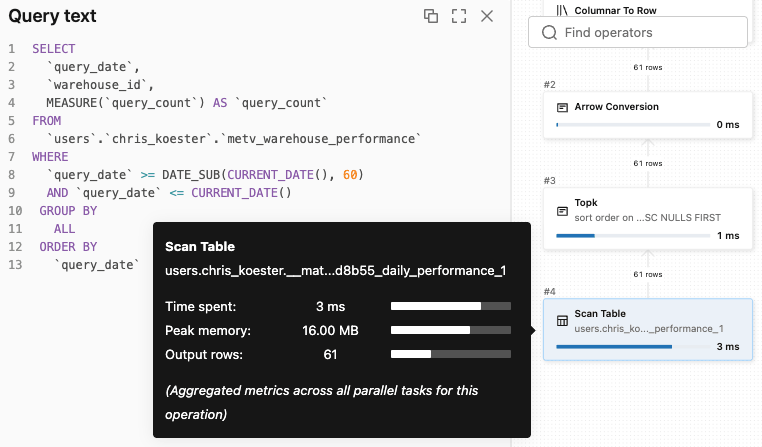
Consultas de dashboard que anteriormente escaneavam tabelas de fatos completas agora acessam materializações pré-agregadas — com menor latência e menor custo de computação. Os exemplos de dashboard e Genie acima consultaram a mesma Visualização de Métricas, e ambos tiveram suas consultas roteadas transparentemente para uma materialização. O plano de consulta abaixo do Genie mostra isso em ação.
Apontadores Práticos de TCO
Consultas mais rápidas e menor custo não são metas concorrentes — cada otimização que reduz os dados escaneados também reduz a computação pela qual você paga. E cada otimização na pilha se acumula. O clustering líquido e estatísticas melhores melhoram o salto de dados e os planos de consulta. As materializações podem ser atualizadas incrementalmente, reduzindo a computação que os armazéns SQL precisam para servir dashboards. Aqui estão algumas maneiras de reduzir o custo:
- Dimensionamento correto do seu armazém SQL. Use armazéns SQL serverless com escalonamento automático para picos de concorrência de BI. Você paga pelo que usa, não pela capacidade de pico.
- Aproveite os níveis de cache do DBSQL. O cache em disco mantém os dados quentes localmente no armazém, e o cache de resultados de consulta (QRC) atende a consultas repetidas sem reexecução. Para dashboards com padrões de consulta consistentes, o cache transforma muitas solicitações em respostas de latência de milissegundos com custo de computação quase zero.
- Elimine o movimento redundante de dados. Sirva BI diretamente do lakehouse via DirectQuery ou conexões ao vivo, em vez de usar extratos ou importações.
- Monitore com tabelas do sistema. Tabelas do sistema como
system.billing.usageesystem.query.historypodem ser usadas para rastrear o uso de BI por dashboard, usuário e armazém. Crie Visualizações de Métricas e um Dashboard de IA/BI em tabelas do sistema para obter visibilidade do seu uso de BI.
Comece
Você não precisa implementar toda a pilha de uma vez. Comece onde você verá o maior impacto:
- Construa (ou valide) seu esquema estrela de camada Gold com tabelas gerenciadas, chaves primárias/estrangeiras e clustering líquido
- Habilite a Otimização Preditiva em seu catálogo para gerenciar automaticamente
OPTIMIZE,VACUUMe a coleta de estatísticas - Defina Visualizações de Métricas para seus KPIs de negócios principais — comece com SQL ou a interface do UC Explorer
- Habilite a materialização de Visualização de Métricas para suas métricas de maior tráfego
- Monitore os resultados — aponte dashboards para Visualizações de Métricas e rastreie o desempenho das consultas por meio de tabelas do sistema
O Databricks fornece otimizações em todas as camadas da pilha de serviço de BI. Tabelas gerenciadas, clustering líquido e Otimização Preditiva minimizam os dados escaneados e a computação gasta. As Visualizações de Métricas centralizam sua lógica de negócios em uma camada semântica governada que atende dashboards, Genie e agentes de IA de forma consistente. A materialização oferece desempenho de consulta de subsegundo sem pipelines de pré-agregação manuais. Juntas, essas camadas se acumulam — reduzindo a latência de consulta e o custo total de propriedade.
Comece definindo sua primeira Visualização de Métricas em uma tabela de camada Gold existente e habilitando a materialização. Veja os recursos abaixo para começar.
- Visão Geral das Visualizações de Métricas do Unity Catalog
- Exibindo Visualizações de Métricas em IA/BI
- Consultando Visualizações de Métricas de um Editor SQL
- Implementando um Data Warehouse Dimensional no Databricks SQL
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.