Implementando um data warehouse dimensional com Databricks SQL: Parte 1
Definindo os objetos de dados
por Bryan Smith, Lorenz Verzosa, Krishna Satyavarapu, Peyman Mohajerian e Jesse Heravi
- Implemente data warehouses dimensionais no Databricks SQL para otimizar o desempenho rápido de consultas.
- A estrutura do modelo físico no Databricks SQL, incluindo a criação de tabelas de dimensão e fato, é feita com instruções SQL CREATE TABLE.
- É importante adicionar comentários descritivos a tabelas e colunas para um melhor gerenciamento de metadados.
Mais e mais organizações estão migrando suas cargas de trabalho de data warehouse para o Databricks. A natureza elástica da plataforma e os aprimoramentos significativos em seu motor de execução de consultas permitiram que o Databricks estabelecesse recordes mundiais tanto em desempenho de consultas de data warehouse quanto em desempenho de custo, tornando-o uma opção cada vez mais atraente para a consolidação da infraestrutura de análise.
Para apoiar esses esforços, já escrevemos anteriormente sobre como o Databricks suporta várias abordagens de design de data warehouse. Nesta série de posts, queremos dar uma olhada mais de perto em uma das abordagens mais populares para data warehousing, a modelagem dimensional, um padrão de design caracterizado por star- e snowflake schemas, e mergulhar nos padrões padronizados de extração, transformação e carregamento (ETL) amplamente adotados em suporte a essa abordagem.
Para tornar isso amplamente acessível à comunidade de modelagem dimensional, aderiremos estritamente aos padrões clássicos associados a essa abordagem de modelagem. Essas informações serão distribuídas pelos seguintes posts:
- Parte 1: Definindo os Objetos de Dados (Dimensionais) (este post)
- Parte 2: Construindo os Fluxos de Trabalho ETL de Dimensão
- Parte 3: Construindo os Fluxos de Trabalho ETL de Fato
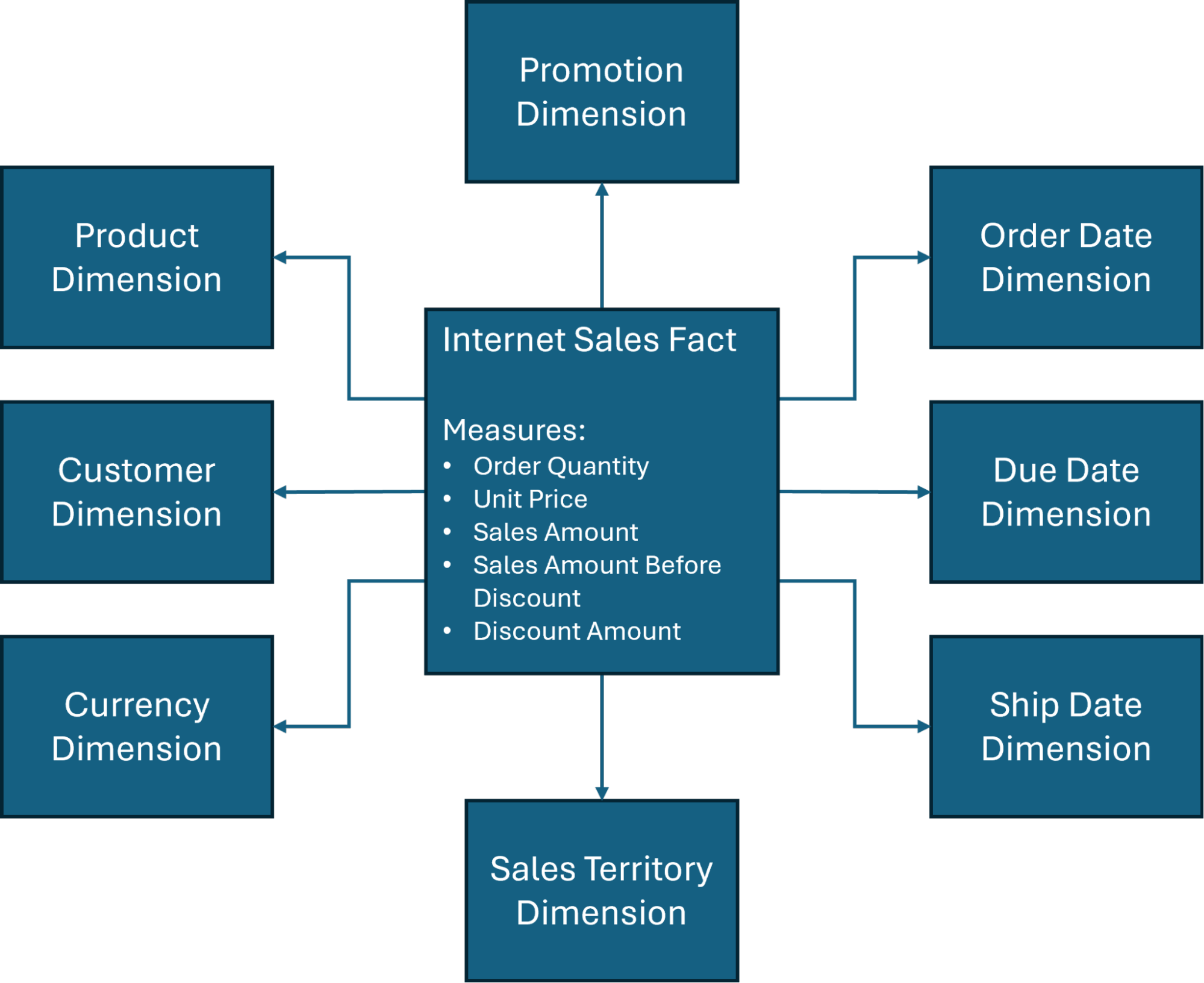
Além disso, centralizaremos nossas discussões de design em torno de um dos esquemas estrela mais comumente usados (Figura 1) no banco de dados AdventureWorksDW, um banco de dados de exemplo criado pela Microsoft e amplamente utilizado para fins de treinamento em data warehouse e Business Intelligence.
O que é modelagem dimensional em data warehousing?
A modelagem dimensional otimiza o armazenamento de dados para um desempenho rápido de consultas. Ao estruturar dados em fatos e dimensões, você pode analisar dados de várias perspectivas facilmente. Ela também permite explorar dados de vários ângulos simultaneamente (análise multidimensional).
Quais são as quatro dimensões de um data warehouse?
Como a Figura 1 indica, existem várias dimensões envolvidas no esquema estrela de data warehousing, mas as quatro dimensões primárias de data warehousing geralmente incluem o seguinte:
Tempo: Isso fornece uma estrutura de rastreamento histórico e é essencial para avaliar tendências ou realizar comparações. Você pode categorizar dados com base em intervalos de tempo específicos – dias, semanas, anos – para otimizar mudanças sazonais de negócios ou gerenciamento de estoque.
Cliente: As organizações precisam de insights precisos sobre quem está comprando seus produtos. Informações como nome, informações de contato e demografia podem oferecer segmentação de mercado útil e determinar decisões como gastos com publicidade ou estratégias gerais de marketing.
Produto: Essa dimensão define quais bens ou serviços estão sendo analisados e pode ser útil na realização de uma análise de desempenho para determinar quanto está sendo vendido, a taxa de vendas e quaisquer oportunidades de crescimento futuro.
Localização: Contextualizar onde os eventos ocorreram – seja geograficamente ou operacionalmente – pode ajudar as organizações a tomar decisões críticas com base em onde seus clientes provavelmente residem.
O modelo físico
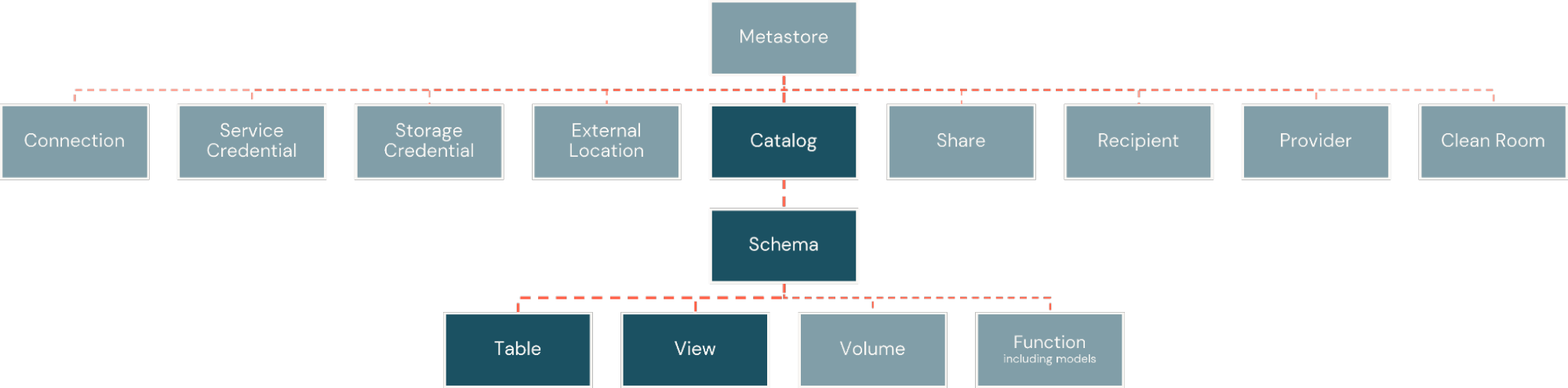
Dentro da Plataforma Databricks, fatos e dimensões são implementados como tabelas físicas. Elas são organizadas dentro decatalogs, semelhantes a bancos de dados, mas com maior flexibilidade para a amplitude de ativos de informação que a plataforma suporta. Os catálogos são então subdivididos emschemas, criando limites lógicos e de segurança em torno de subconjuntos de objetos no catálogo (Figura 2).
Tabelas de dimensão
Tabelas de dimensão aderem a um conjunto relativamente rígido de padrões estruturais. Um identificador sequencial, umasurrogate key, é tipicamente definida para suportar um link estável e eficiente entre tabelas de fatos e a dimensão. Identificadores únicos de sistemas operacionais (frequentemente referidos como chaves naturais ou chaves de negócios), juntamente com uma coleção desnormalizada de atributos de negócios relacionados, geralmente seguem. Atrás dos identificadores, geralmente há uma série de colunas de metadados destinadas a suportar processos ETL contínuos. Dentro da Plataforma Databricks, podemos implementar uma tabela de dimensão usando aCREATE TABLE statement, como mostrado aqui para a dimensão cliente:
Colunas de identidade
Neste exemplo, para a coluna de chave substituta, CustomerKey, usamos uma coluna de identidade que cria automaticamente um valor BIGINT sequencial para o campo conforme inserimos linhas. Se usamos a opção ALWAYS ou BY DEFAULT com a coluna de identidade depende se queremos proibir ou permitir a inserção de nossos próprios valores para este campo.
Entrada de membro ausente
Um padrão comum implementado com tabelas de dimensão é a criação de uma entrada de membro ausente. Essa entrada é usada em cenários onde registros de fatos chegam com ligação ausente ou desconhecida a uma dimensão e podem ser criados com um valor de chave substituta pré-determinado, como o mostrado aqui quando a opção BY DEFAULT é empregada:
Campos de identidade
Como uma boa prática, sempre que inserir valores em um campo de identidade, é melhor garantir que os metadados do campo de identidade sejam atualizados através do uso de uma instrução ALTER TABLE com a opção SYNC IDENTITY empregada:
Tipos de dados
Para a chave de negócios/natural e outros campos vinculados a dados em sistemas de origem, precisaremos alinhar os tipos de dados do sistema de origem com os tipos de dados suportados pela Plataforma Databricks (Tabela 1). Para campos de metadados onde um valor de bit é empregado, como 0 ou 1, observe que frequentemente usamos um tipo de dado INT em vez dos tipos de dados BOOLEAN ou TINYINT para facilitar um pouco o manuseio de literais.
|
BIGINT |
DECIMAL |
INTERVAL |
TIMESTAMP |
MAP |
|
BINARY |
DOUBLE |
VOID |
TIMESTAMP_NTZ |
STRUCT |
|
BOOLEAN |
FLOAT |
SMALLINT |
TINYINT |
VARIANT |
|
DATE |
INT |
STRING |
ARRAY |
OBJECT |
Tabela 1. Os tipos de dados suportados pela Plataforma Databricks
Tabelas de fatos
As tabelas de fatos também seguem suas convenções estruturais. Compostas principalmente de medidas e referências de chave estrangeira para dimensões relacionadas, as tabelas de fatos também podem incluir identificadores únicos para registros transacionais (ou outros atributos descritivos em um relacionamento quase um para um com os registros de fatos), referidos como dimensões degeneradas. Elas também podem incluir campos de metadados para suportar o carregamento incremental (também conhecido como extração delta) de dados de sistemas de origem. Dentro da Plataforma Databricks, podemos implementar uma tabela de fatos usando a instrução CREATE TABLE semelhante ao que é mostrado aqui para o fato de vendas pela Internet:
Chaves estrangeiras referenciadas
Como mencionado na seção anterior sobre tabelas de dimensão, os tipos de dados no ambiente Databricks são mapeados de forma flexível para os usados pelos sistemas de origem. As referências de chave estrangeira entre as tabelas de fatos e de dimensão também podem ser explicitadas usando a instrução ALTER TABLE, como mostrado aqui:
Observação: Se você preferir definir as restri�ções de chave estrangeira como parte da instrução CREATE TABLE, basta adicionar uma lista separada por vírgulas de cláusulas FOREIGN KEY (na forma FOREIGN KEY (foreign_key) REFERENCES table_name (primary_key) logo após a lista de definição de colunas.
Metadados e outras considerações
O apelo do modelo dimensional é sua relativa acessibilidade para analistas de negócios. Com isso em mente, muitas organizações adotam convenções de nomenclatura para fatos e dimensões, como os prefixos Fact e Dim nos exemplos acima, e incentivam o uso de nomes longos e autoexplicativos para tabelas e campos, que muitas vezes se desviam significativamente dos nomes usados em sistemas operacionais de origem.
Com isso em mente, é importante observar as limitações do Databricks na nomeação de objetos. Estas incluem:
- Nomes de objetos não podem exceder 255 caracteres
- Os seguintes caracteres especiais não são permitidos:
- Ponto (.)
- Espaço ( )
- Barra (/)
- Todos os caracteres de controle ASCII (00-1F hex)
- O caractere DELETE (7F hex)
Além disso, é importante notar que os nomes dos objetos não diferenciam maiúsculas de minúsculas e são, de fato, armazenados no repositório de metadados em letras minúsculas. Se isso puder criar problemas com a legibilidade dos objetos, você pode considerar a adoção de uma convenção snake case para melhorar a legibilidade de alguns nomes de objetos.
Independentemente de suas convenções de nomenclatura, é uma boa ideia definir comentários descritivos para todos os objetos e campos dentro do data warehouse. Isso é feito através do uso da instrução COMMENT ON para objetos de tabela e da instrução ALTER TABLE para campos individuais, como demonstrado aqui:
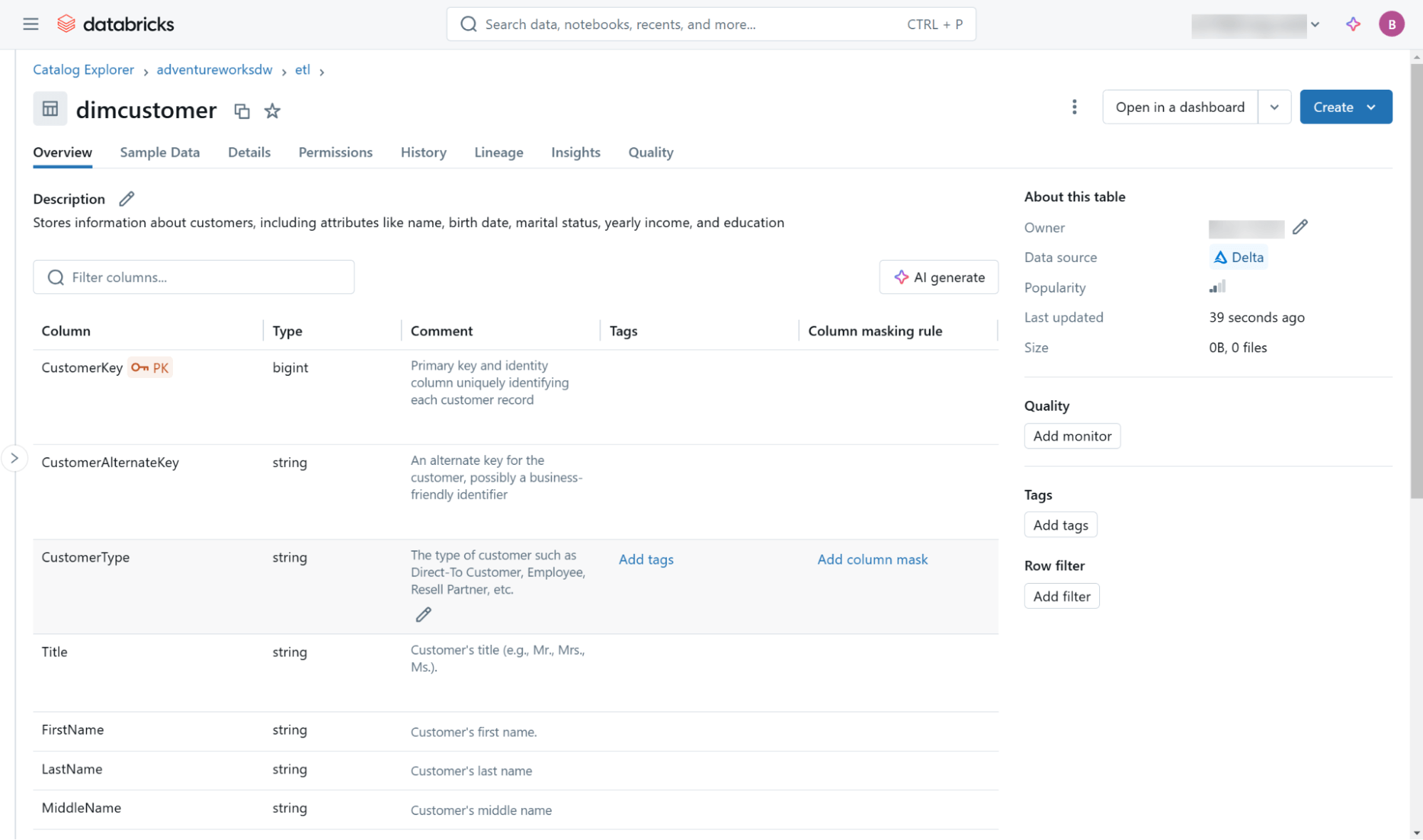
Isso e outros metadados (incluindo informações de linhagem) são acessíveis através da interface do usuário do Databricks Catalog Explorer (Figura 3) e através de objetos no information schema integrado encontrado em cada catálogo.
Por último, este blog aborda a criação de tabelas de fatos e dimensões puramente da perspectiva de adesão aos princípios de design dimensional. Se você quiser explorar algumas opções adicionais para definição de tabelas que considerem otimizações de desempenho e manutenção, por favor, confira este blog sobre otimização de desempenho de esquema estrela.
Próximos passos: implementando o ETL da tabela de dimensão
Após abordarmos os conceitos básicos por trás da criação de tabelas de fatos e dimensões, voltaremos nossa atenção no próximo artigo para a implementação dos padrões de ETL que suportam tabelas de dimensões, com ênfase especial nos padrões de dimensão de alteração lenta (SCD) Tipo 1 e Tipo 2, utilizando tanto Python quanto SQL. Por fim, a Parte 3 abordará como o ETL para essas tabelas pode ser implementado.
Para saber mais sobre Databricks SQL, visite nosso site ou leia a documentação. Você também pode conferir o tour do produto para Databricks SQL. Se você deseja migrar seu data warehouse existente para um data warehouse serverless de alta performance, com ótima experiência de usuário e menor custo total, o Databricks SQL é a solução — experimente gratuitamente.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.