Traga o Databricks para o Kiro IDE com o poder do AI Dev Kit
Duas maneiras de conectar o Kiro IDE à Databricks Data Intelligence Platform: os quatro servidores MCP gerenciados pelo Databricks para um caminho de 10 minutos, ou o novo Databricks AI Dev Kit Power para obter o escopo completo.
- Dois caminhos para conectar o Kiro IDE ao Databricks: os quatro servidores MCP gerenciados pelo Databricks (Genie, SQL, Unity Catalog Functions, Vector Search) para uma configuração de 10 minutos baseada em PAT, ou o novo Databricks AI Dev Kit Power — um clique, todas as ferramentas e habilidades essenciais, quatro opções de autenticação.
- Desenvolvimento assistido por IA baseado em metadados reais do workspace: ambos os caminhos herdam permissões baseadas em linha, coluna e tag do Unity Catalog, para que o assistente escreva SQL com suas colunas reais e veja apenas o que você pode ver — sem alucinações, sem leituras não autorizadas.
- Escolha pelo escopo: o Caminho A é a configuração mais leve para analistas e desenvolvedores focados em SQL; o Caminho B abre a plataforma Databricks completa (pipelines, jobs, Mosaic AI, Agent Bricks, Lakebase, Asset Bundles) dentro do IDE.
Por que isso é importante
O desenvolvimento assistido por IA desmorona no momento em que o assistente precisa adivinhar nomes de colunas, layouts de tabela ou quais catálogos você pode ler. A solução é a ancoragem (grounding): conecte o assistente aos metadados ativos do workspace via Model Context Protocol (MCP), e o SQL que ele escreve usará as colunas reais que você tem, os modelos dbt farão join de tabelas reais e cada consulta herdará as permissões do Unity Catalog que você já tem configuradas. Nada sai da plataforma. A IA vê apenas o que você pode ver.
Dois marcos importantes acabam de ser alcançados para tornar isso prático no Kiro IDE:
Primeiro, o Databricks AI Dev Kit adicionou suporte ao Kiro upstream no PR #511. O instalador unificado trata o kiro como um destino de primeira classe, ao lado de claude, cursor, copilot, codex e gemini. Com apenas um comando, o Kiro adquire o kit de ferramentas completo em ~/.kiro/skills/ e ~/.kiro/settings/mcp.json.
Segundo, o Databricks AI Dev Kit Power foi lançado no catálogo Kiro Powers no PR #129. Abra o painel Powers, clique em Try e o Power executará todo o onboarding: instalador, integração do MCP, detecção de autenticação e carregamento de habilidades.
Combinado com os quatro servidores MCP remotos gerenciados pela Databricks que já vêm integrados na plataforma, você tem duas maneiras de conectar o Kiro ao Databricks. Ambas compartilham um resultado comum: os desenvolvedores entregam análises, pipelines e fluxos de trabalho de agentes mais rapidamente quando o assistente herda permissões reais do workspace em vez de adivinhar esquemas, colunas e concessões.
Por que escolher a Databricks para o desenvolvimento assistido por IA
Os dois marcos acima tornam a integração Kiro × Databricks prática. O motivo de sua importância é o que está por trás dela. Três fatores tornam a Databricks a base ideal para o desenvolvimento assistido por IA, independentemente do caminho escolhido.
O Unity Catalog é a única camada de governança que ancora a IA no nível dos dados. Cada chamada de MCP — Caminho A ou Caminho B — herda permissões baseadas em linhas, colunas e tags. O assistente não tem uma visão privilegiada dos seus dados; ele vê exatamente o que você pode ver. Não há uma camada separada de controle de acesso para gerenciar, nem o risco de a IA escrever consultas em tabelas que ela nem deveria saber que existem.
Uma única cópia dos dados, um único conjunto de definições. Como a Databricks é um lakehouse, a tabela que o assistente consulta via databricks-sql é a mesma tabela na qual seu modelo dbt grava, a mesma tabela que seu espaço Genie expõe e a mesma tabela que seu painel de AI/BI lê. Não há sincronização de data warehouse para lake para quebrar, nem uma camada semântica separada para manter sincronizada. Quando o assistente se ancora em samples.tpch.lineitem, ele está se baseando na mesma definição que todas as outras ferramentas usam.
Toda a pilha de IA está integrada, não apenas acoplada. O Mosaic AI Gateway roteia as chamadas de modelo. O Agent Bricks orquestra fluxos de trabalho multiagentes. O MLflow rastreia experimentos e avaliações. O Vector Search potencializa a recuperação semântica. O Lakebase lida com o estado transacional. Tudo isso é disponibilizado no Power, tudo no mesmo UC. Você não está costurando cinco produtos diferentes; está usando uma única plataforma.
Há um quarto ponto que vale a pena mencionar: o próprio Power é desenvolvido pela Databricks. Nenhuma outra plataforma de dados oferece um Power de IDE com um clique para Kiro, Cursor, Claude, Copilot, Codex e Gemini. A camada MCP é aberta, o protocolo é aberto, a integração é aberta — mas a experiência que a envolve foi projetada pela Databricks especificamente para a maneira como nossos clientes desenvolvem.
Visão geral dos dois caminhos
Dimensão | Caminho A: Servidores MCP gerenciados | Caminho B: Databricks AI Dev Kit Power |
|---|---|---|
Escopo | 4 servidores: Genie, SQL, UC Functions, Vector Search | Todas as ferramentas e habilidades essenciais da Databricks |
O que você recebe | SQL em linguagem natural, busca semântica, execução de funções governada | Escopo do Caminho A mais pipelines, jobs, dashboards, Lakebase, Mosaic AI, Agent Bricks, Asset Bundles, MLflow, model serving, Apps |
Hospedagem | Gerenciado pela Databricks (HTTPS remoto) | Servidor MCP Python local via instalador do AI Dev Kit |
Autenticação | PAT em env do shell | OAuth U2M (recomendado), OAuth M2M, perfil .databrickscfg ou PAT |
Configuração | Editar | Instalação do Power com um clique e fluxo de autenticação guiado |
Ideal para | Analistas e desenvolvedores focados em SQL que desejam um caminho de 10 minutos para fazer perguntas ao seu data warehouse | Engenheiros de dados e desenvolvedores de plataforma que precisam de todo o escopo da Databricks em uma única IDE |
Visão geral da arquitetura de integração
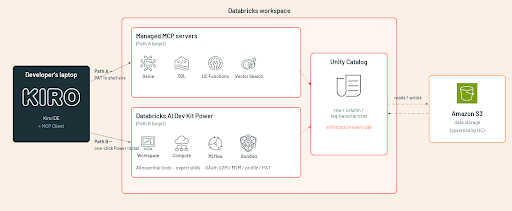
Ambos os caminhos compartilham o mesmo back-end: aplicação do Unity Catalog e identidade do workspace da Databricks. Eles diferem no escopo e no modelo de autenticação.
Caminho A: conectar-se aos quatro servidores MCP gerenciados
Esta é a configuração mais leve. Um arquivo mcp.json, um Token de Acesso Pessoal (PAT) da Databricks e uma edição no perfil do shell. Em menos de 10 minutos, o Kiro estará se comunicando com o Genie, SQL, Unity Catalog Functions e Vector Search.
Pré-requisitos
- Um workspace da Databricks na AWS com o Unity Catalog habilitado.
- Um Token de Acesso Pessoal (PAT) da Databricks ou token OAuth com escopo definido para os servidores MCP que você planeja usar (
sql,unity-catalog,genie,vector-search). Os PATs não utilizados são revogados automaticamente após 90 dias. - O Kiro instalado e iniciado pelo menos uma vez para que o
~/.kiro/exista. - O hostname do seu workspace no formato
<workspace>.cloud.databricks.com.
Gerar um PAT da Databricks
No workspace da Databricks, acesse Settings, Developer, Access tokens, Manage, Generate new token. Defina uma expiração alinhada com a política de rotação da sua equipe. Selecione apenas os escopos de API necessários; o menor privilégio é melhor do que a conveniência de liberar "tudo". Copie o token imediatamente. A Databricks não o exibirá novamente.
Onde o Kiro armazena a configuração do MCP
O Kiro lê a configuração do MCP a partir do JSON em dois escopos; o do workspace substitui o do usuário.
- Escopo do usuário:
~/.kiro/settings/mcp.jsonse aplica a todos os workspaces. - Escopo do workspace:
$PWD/.kiro/settings/mcp.jsonse aplica apenas ao workspace atual e substitui a entrada de escopo do usuário com a mesma chave.
Instalação com um clique a partir do diretório de servidores do Kiro
Abra kiro.dev/docs/mcp/servers/, encontre a linha da Databricks e clique em Add to Kiro. O navegador iniciará o Kiro e abrirá uma caixa de diálogo de confirmação com uma configuração pré-preenchida. Confirme para gravar a entrada databricks-sql no ~/.kiro/settings/mcp.json. A entrada faz referência a duas variáveis de ambiente que ainda não existem; nós as definiremos a seguir.
Verificar (ou adicionar) a entrada databricks-sql
Definir as variáveis de ambiente
No perfil do shell que inicia o Kiro (geralmente ~/.zshrc no macOS):
Execute o source no perfil (source ~/.zshrc) antes de iniciar o Kiro. Feche totalmente o Kiro (Cmd+Q no macOS) e abra-o novamente. A opção Reload Window não relê as variáveis de ambiente; apenas a reinicialização do processo faz isso.
Adicionar Genie, UC Functions, e Vector Search
Todos os quatro servidores gerenciados pela Databricks se conectam como MCP HTTP remoto. O handshake de inicialização é bem-sucedido mesmo com uma URL temporária; o servidor valida o recurso apenas quando uma ferramenta é invocada. Um estado conectado, mas inoperante, onde tools/call retorna RESOURCE_DOES_NOT_EXIST ou PERMISSION_DENIED, é o modo de falha mais comum. Execute estas verificações preliminares primeiro:
- Genie: confirme se existe um espaço Genie e se você consegue abri-lo. O ID do espaço aparece na URL.
- UC Functions: confirme se a função existe e se você tem
EXECUTE. Liste as funções comSELECT * FROM system.information_schema.routines WHERE routine_type = 'FUNCTION'. - Vector Search: confirme se existe um endpoint com pelo menos um índice acessível em Catalog, Vector Search.
- PAT scope: um PAT com escopo de workspace ainda pode atingir
PERMISSION_DENIEDem espaços Genie ou índices de vetor se o usuário não tiver a permissão Can View no recurso específico. Os espaços Genie são compartilhados individualmente.
Adicione as variáveis de ambiente adicionais (DATABRICKS_GENIE_MCP_URL, DATABRICKS_UC_FUNCTIONS_MCP_URL, DATABRICKS_VECTOR_SEARCH_MCP_URL) e atualize mcp.json para a configuração completa:
Formatos de URL por servidor:
Servidor | Padrão de URL |
|---|---|
databricks-genie | https:// |
databricks-sql | https:// |
databricks-uc-functions | https:// |
databricks-vector-search | https:// |
Feche e reinicie o Kiro novamente. Abra a seção MCP SERVERS do painel do Kiro; as quatro entradas databricks-* aparecerão com indicadores de status verdes. Clique em reconectar em qualquer item vermelho e verifique novamente o pre-flight. Tente uma primeira consulta de baixo risco no painel de chat: "Listar os catálogos aos quais tenho acesso."
Caminho B: instalar o Databricks AI Dev Kit Power
Os quatro servidores gerenciados cobrem SQL, busca semântica e análise de linguagem natural, o que é suficiente para muitos desenvolvedores. Se o seu fluxo de trabalho abrange pipelines, jobs, model serving, Lakebase, Asset Bundles, Mosaic AI, Agent Bricks, painéis de AI/BI, MLflow ou Databricks Apps, a configuração de quatro servidores fará com que você passe o dia copiando e colando de volta na UI do workspace.
O Databricks AI Dev Kit Power resolve isso. Uma única instalação. Todas as ferramentas e habilidades essenciais, quatro opções de autenticação, tudo carregável sob demanda.
O que você recebe
Área | Cobertura |
|---|---|
SQL e computação | Execute SQL em warehouses; execute Python ou Scala em clusters; gerencie o ciclo de vida da computação |
Pipelines e jobs | Spark Declarative Pipelines (streaming tables, CDC, SCD Tipo 2, Auto Loader); DAGs de jobs multitarefa |
Unity Catalog | Tabelas, volumes, permissões, tags, credenciais de armazenamento, tabelas de sistema, exibições de métricas, External Iceberg Reads |
Painéis de AI/BI | Visualizações, KPIs, painéis de análise |
Espaços Genie | Exploração de dados em linguagem natural em conjuntos de dados governados |
Agent Bricks | Assistentes de conhecimento (RAG) e supervisores multiagentes |
Vector Search | Busca semântica e RAG com índices gerenciados |
Model Serving | Modelos de ML, agentes de IA, e APIs de Modelos de Fundação (FMAPI) com pagamento por token, roteáveis por meio do AI Gateway |
MLflow | Experimentos, avaliações, instrumentação de rastreamento, consultas de métricas |
Lakebase | PostgreSQL gerenciado provisionado e com dimensionamento automático para cargas de trabalho OLTP |
Databricks Apps | Aplicativos web full-stack no Lakehouse |
Asset Bundles | Infraestrutura como código para recursos do Databricks |
Instalar com um clique
No Kiro, abra o painel Powers, pesquise por databricks e clique em Experimentar. O Power executa o instalador oficial do Databricks AI Dev Kit no modo Kiro não interativo:
O instalador baixa o servidor MCP, cria um ambiente virtual uv e extrai a biblioteca de habilidades especializadas para ~/.kiro/skills/. O Power copia as habilidades para seu próprio diretório steering/ para que sejam carregadas sob demanda com base na tarefa em questão. Nenhum conteúdo é empacotado no próprio Power; tudo é buscado upstream, de modo que as habilidades permaneçam atualizadas.
As quatro opções de autenticação
O fluxo de integração do Power detecta credenciais existentes e orienta você na escolha certa. Todas as quatro estão documentadas inline:
Opção | O que é | Ideal para |
|---|---|---|
A: OAuth U2M (recomendado para uso interativo) | A CLI do Databricks abre um navegador, você se autentica como você mesmo e o SDK é atualizado automaticamente a cada hora | Um único desenvolvedor humano em uma estação de trabalho. Fluxo interativo mais seguro, sem segredos de longa duração que possam vazar |
B: OAuth M2M | Um principal de serviço do Databricks se autentica com | Agentes headless, de CI/CD ou de produção |
C: Perfil | Aponte o Power para um perfil que você já usa para a CLI do Databricks ou outras ferramentas | Você já tem um perfil ativo e não quer configurar a autenticação novamente |
D: Personal Access Token (legado) | Token bearer no | Ferramentas que não oferecem suporte ao OAuth ou workspaces sem o OAuth U2M ativado |
O mcp.json do Power é fornecido com disabled: true até que você escolha uma opção; nada se conecta até que você tenha escolhido e configurado explicitamente suas credenciais. O fluxo de detecção de credenciais é neutro. Se várias credenciais forem detectadas, todas as quatro opções serão apresentadas em ordem, sem padrão e sem reutilização silenciosa.
Verificar a instalação
Reinicie o Kiro, abra o painel MCP SERVERS e confirme se a entrada databricks está conectada (verde). Pergunte ao chat: "Obter meu usuário atual do Databricks." Essa única chamada testa a autenticação, a resolução de variáveis de ambiente e a ativação do servidor. Se funcionar, toda a cadeia está saudável.
Como escolher entre os dois caminhos
Uma árvore de decisão simples:
- Apenas executando SQL, fazendo perguntas em linguagem natural sobre conjuntos de dados governados via Genie e pesquisando índices de vetor? Use o Caminho A. Os quatro servidores gerenciados fazem exatamente isso, e a configuração leva 10 minutos.
- Criar pipelines, gerenciar jobs, implantar Asset Bundles, trabalhar com o Lakebase, criar Databricks Apps ou chamar Mosaic AI / Agent Bricks? Use o Caminho B. O kit de ferramentas completo tem uma área de superfície grande demais para ser adicionada como servidores MCP remotos avulsos.
- Híbrido? Execute ambos. O Caminho A e o Caminho B não entram em conflito. O Power grava sua própria entrada
mcpServers.databricks, enquanto os quatro servidores do Caminho A (databricks-genie,databricks-sql,databricks-uc-functions,databricks-vector-search) são chaves separadas. O Kiro apresenta todos eles no painel do MCP.
Para desenvolvedores que planejam usar o Kiro no dia a dia em cargas de trabalho do Databricks, o Caminho B é a melhor solução a longo prazo. O Caminho A é a resposta certa se você tiver 10 minutos e quiser interagir com um SQL warehouse.
Pela perspectiva do desenvolvedor
Ambos os caminhos funcionam de maneira diferente dependendo de quem está usando a IDE. Quatro personas, quatro pontos de dor, quatro respostas.
O engenheiro de analytics. Você passa metade do dia consultando tabelas que nunca viu e a outra metade copiando e colando entre o seu editor e a UI do workspace. O Caminho A resolve isso em 10 minutos. Os servidores Genie e SQL baseiam cada consulta em metadados de esquema reais; o assistente escreve com base em suas colunas reais, sem adivinhações; e cada resultado herda suas permissões do Unity Catalog. Você para de alternar entre abas.
O engenheiro de dados. Seu dia a dia envolve pipelines, jobs, Asset Bundles e as promoções entre ambientes que acompanham os três. Criar o databricks.yml manualmente e executar databricks bundle deploy a partir de uma barra lateral do terminal é o caminho mais lento. O Caminho B é o caminho mais rápido. As habilidades de pipelines + jobs + Asset Bundles do Power produzem, validam e implantam IaC a partir de uma única conversa. Spark Declarative Pipelines, CDC, SCD Type 2, Auto Loader — tudo gerado com base em suas tabelas reais do UC e pronto para o commit.
O desenvolvedor de IA / agentes. Você está conectando chamadas de modelo, avaliação, governança e orquestração de agentes em três ou quatro ferramentas que não entram em acordo sobre o esquema. O Caminho B cobre toda a superfície de IA do Databricks — Mosaic AI Gateway para roteamento e fallbacks, Agent Bricks para supervisores multiagentes e assistentes de conhecimento, MLflow para avaliação, Vector Search para recuperação �— tudo governado pelo UC de ponta a ponta. Seu agente herda as mesmas permissões que quem o chamou, e seus rastreamentos de avaliação vão para o mesmo workspace que as suas execuções de treinamento.
O desenvolvedor de plataforma. Você gerencia recursos do Databricks como código, promove entre dev/stage/prod e responde à pergunta "tivemos desvios?" semanalmente. A habilidade de Asset Bundles do Caminho B, somada às habilidades de gerenciamento do Unity Catalog, gera o bundle completo, valida-o em relação ao estado real do seu workspace e detecta desvios antes que causem problemas. Você para de manter um conjunto de YAML manualmente e outro em um documento.
Um fluxo de trabalho que você pode executar hoje
Qualquer que seja o caminho escolhido, este exercício baseia o assistente em metadados reais do workspace usando o catálogo samples.tpch, disponível em todos os workspaces do Databricks.
Você pergunta: "Quais colunas e tipos o samples.tpch.lineitem possui e qual é a distribuição dos dados por ano de l_shipdate?"
O Kiro retorna o esquema real e um histograma a partir de uma única consulta executada pelo MCP. Nomes de colunas reais, distribuição real, sem alucinações.
Você pergunta: "Esboce um modelo dbt que faça um join de lineitem com orders e agregue a receita por nação por trimestre."
O Kiro gera o SQL usando os nomes reais das colunas (l_extendedprice, l_discount, o_orderdate) em vez de adivinhações. Como ele consultou o esquema primeiro, ele conhece os tipos exatos e a granularidade.
Você pergunta: "Execute minha nova agregação em samples.tpch e compare a contagem de linhas com o snapshot da semana passada em poc.gold.revenue_by_nation_qtr."
O Kiro executa ambas as consultas e exibe a diferença. Quando um número parece incorreto, "Mostre-me a linhagem de gold.revenue_by_nation_qtr" busca as tabelas de origem de system.access.table_lineage. Uma vez verificado, o Kiro gera o JSON do job do Databricks para o modelo e lista quais catálogos e esquemas ele afeta.
No Caminho B, o mesmo fluxo de trabalho se estende para "Gerar o Asset Bundle para este job e implantá-lo em staging" ou "Criar um painel de AI/BI baseado nesta agregação" ou "Conectar isso a um endpoint do Mosaic AI Gateway com um modelo de fallback", tudo sem sair da IDE.
Boas práticas, independentemente do caminho
- Autenticação de menor privilégio. Gere um PAT separado por estação de trabalho e por conjunto de escopo. No Caminho B, prefira o OAuth U2M para uso interativo em vez de PATs.
- Nunca faça commit de credenciais. Armazene
DATABRICKS_ACCESS_TOKENno seu perfil de shell ou em um gerenciador de segredos. Nunca o coloque emmcp.jsonenviado para o controle de versão. - Escopo por projeto. Mantenha os IDs de espaço do Genie e os caminhos de índice do Vector Search em
$PWD/.kiro/settings/mcp.jsonpara que cada projeto tenha suas próprias vinculações de recursos. - Confie nas permissões do UC. Todos os caminhos aplicam permissões baseadas em linha, coluna e tag do Unity Catalog. A IA herda suas permissões efetivas em cada chamada. Não há uma camada separada de controle de acesso para gerenciar.
- Reinicie, não recarregue. O Kiro lê as variáveis de ambiente uma vez no início do processo. Depois de editar seu perfil de shell ou adicionar autenticação, saia completamente (Cmd+Q no macOS) e abra novamente.
Solução de problemas
"Servidor não encontrado" ou status vermelho em uma entrada do MCP.
Caminho A: verifique echo $DATABRICKS_SQL_MCP_URL no shell que iniciou o Kiro. Um valor vazio significa que o Kiro não consegue resolver a URL. Confirme se o mcp.json de escopo do workspace não está sobrepondo sua configuração de escopo do usuário. Verifique se o PAT ainda é válido em Settings, Developer, Access tokens.
Caminho B: insira novamente o fluxo de detecção de credenciais a partir do onboarding do Power. Se o servidor MCP retornar Invalid access token ou 401, o gancho de recuperação 401 integrado do Power pausará as chamadas de ferramentas e exibirá novamente as opções de autenticação.
Conectado ao MCP, mas as chamadas de ferramentas retornam RESOURCE_DOES_NOT_EXIST ou PERMISSION_DENIED.
A falha mais comum do Caminho A. O handshake de inicialização é bem-sucedido com uma URL temporária porque o servidor adia a validação do recurso até a invocação. Execute novamente as verificações preliminares para o servidor específico (o espaço do Genie existe e está compartilhado com você, a função existe e você tem EXECUTE, o índice de vetor existe e você tem permissão de Can View).
Experimente hoje mesmo. O Databricks AI Dev Kit Power é a maneira mais rápida de obter a plataforma completa — pipelines, jobs, Lakebase, Mosaic AI, Agent Bricks e tudo mais listado acima — dentro do Kiro. Instale-o diretamente do catálogo do Kiro Powers em github.com/kirodotdev/powers ou visite github.com/databricks-solutions/ai-dev-kit para instalar o kit de ferramentas subjacente para o Kiro ou qualquer IDE compatível (Claude, Cursor, Copilot, Codex, Gemini). Para os quatro servidores MCP gerenciados pelo Databricks, a instalação com um clique está disponível em kiro.dev/docs/mcp/servers/.
Tem algum feedback ou encontrou um problema? Abra uma issue em databricks-solutions/ai-dev-kit — nós lemos todas.
As opiniões e ideias compartilhadas aqui são de nossa autoria e não representam a política oficial do Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.