Construindo um Leitor de Rótulos de Alimentos com Agente para Maior Transparência
Como o Agent Bricks simplifica o processamento automatizado de rótulos em grande escala
- Os consumidores exigem transparência alimentar, mas desconfiam das alegações dos produtores, o que impulsiona a necessidade de processamento automatizado de rótulos
- O Databricks Agent Bricks extrai e estrutura dados de ingredientes de imagens de pacote em grande escala
- As organizações podem criar fluxos de trabalho de leitura de rótulos prontos para produção em horas, usando ferramentas no-code
As expectativas dos clientes em relação ao rótulo de alimentos passaram por uma mudança fundamental. De acordo com uma pesquisa recente, três quartos dos consumidores dos EUA agora exigem informações completas sobre os alimentos que compram, e quase dois terços analisam os rótulos com mais cuidado do que há cinco anos. Isso não é uma tendência passageira, mas é impulsionado por mais famílias que lidam com alergias e intolerâncias e por mais consumidores comprometidos com dietas específicas, como vegana, vegetariana ou sem glúten.
Mas o desafio é o seguinte: apenas 16% dos consumidores confiam nas alegações de saúde dos produtores de alimentos. Isso significa que os consumidores querem avaliar os produtos por conta própria, em seus próprios termos. Eles escaneiam as listas de ingredientes e analisam cuidadosamente os rótulos dos pacotes para entender melhor a origem, as práticas de produção e a nutrição, e como esses fatores se alinham às suas necessidades específicas de saúde como parte da decisão de compra.
Enquanto os órgãos reguladores trabalham em requisitos de rótulo atualizados, os principais varejistas já estão agindo. Eles estão usando extração de dados avançada e analítica de ingredientes para transformar rótulos de embalagens e nutricionais em experiências digitais pesquisáveis e filtráveis. Isso permite que os clientes encontrem exatamente o que precisam, sejam opções sem alérgenos, produtos sem glúten ou itens de origem sustentável. Essas iniciativas de transparência não apenas diferenciam esses varejistas de seus concorrentes, mas também promovem um engajamento mais profundo com o cliente e aumentam as ventas, especialmente de produtos com maior margem de lucro.
A Solução Data + AI
É um desafio acompanhar os 35.000 SKUs exclusivos encontrados em um supermercado comum nos EUA, com 150 a 300 novos sendo lançados mensalmente. Mas com as aplicações de AI agêntica de hoje, agora você pode automatizar a leitura de rótulos de alimentos em grande escala e a um custo razoável.
Com imagens de rótulos nutricionais fornecidas como entradas, esses sistemas analisam as imagens para extrair informações brutas de ingredientes e nutrição. Essas informações são então processadas em dados estruturados que podem alimentar tanto analítica interna quanto experiências digital para o cliente. A partir desses dados, você pode criar classificações personalizadas para alérgenos, ingredientes ultraprocessados, atributos de sustentabilidade e preferências de estilo de vida, exatamente o que você precisa para dar suporte aos seus clientes.
Neste blog, mostraremos como implementar um processo de ponta a ponta usando os recursos do Agent Bricks da Databricks para simplificar e otimizar o desenvolvimento e a implantação de um leitor automatizado de rótulos de alimentos para sua organização.
Construindo a solução
Nosso fluxo de trabalho de leitura de rótulos de alimentos é bem simples (Figura 1). Carregaremos imagens de pacotes de alimentos em um local de armazenamento acessível, usaremos AI para extrair texto das imagens e convertê-lo em uma tabela e, em seguida, aplicaremos AI para alinhar o texto extraído a um esquema conhecido.

{kind=link}
Em nosso primeiro passo, coletamos várias imagens de pacotes de produtos que exibem listas de ingredientes, como a mostrada na Figura 2. Essas imagens em .png, .jpeg, ou .pdf formato são então carregados em um volume do Unity Catalog (UC), tornando-os disponíveis no Databricks.

{kind=link}
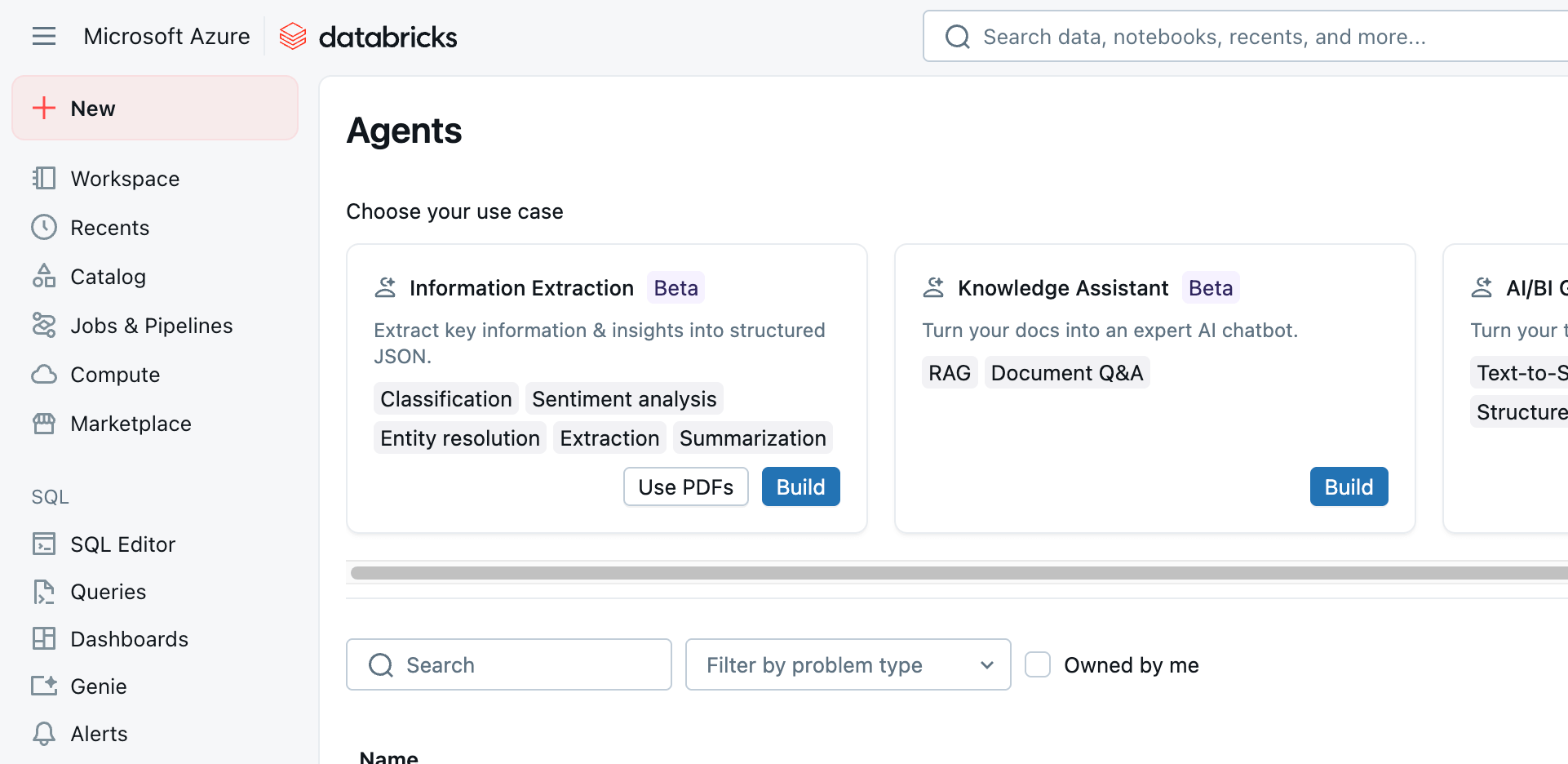
Com nossas imagens carregadas, selecionamos Agents no menu à esquerda do workspace do Databricks e navegamos até o agente de Extração de Informações exibido na parte superior da página (Figura 3).
{kind=link}
O agente informação Extraction nos fornece duas opções: Use PDFs e Build. Vamos começar selecionando a opção Use PDFs, que nos permitirá definir um job para extrair texto de vários formatos de imagem. (Enquanto o .pdf formato é indicado no nome da opção selecionada, outros formatos de imagem padrão são suportados.)
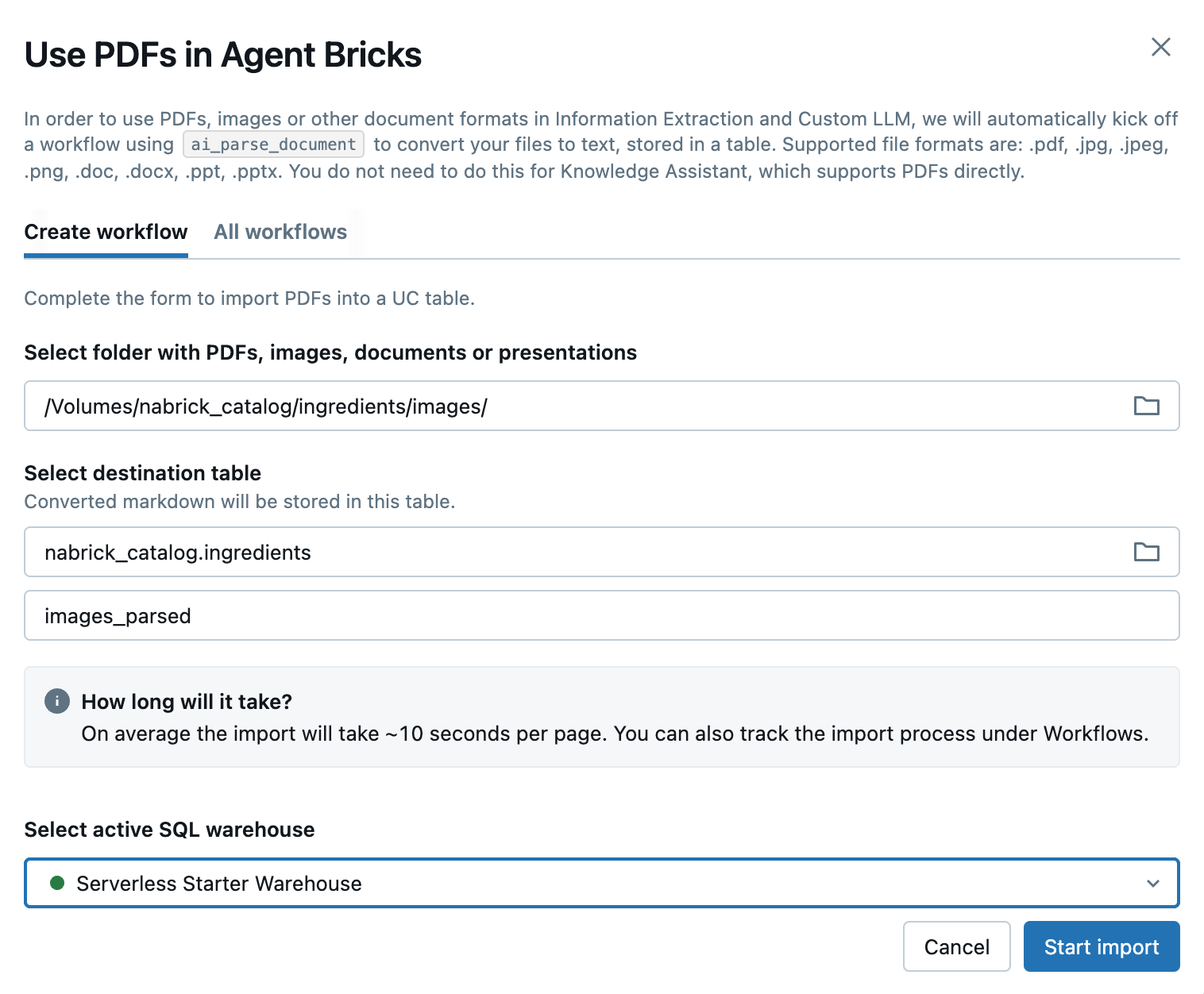
Ao clicar na opção Use PDFs, é exibida uma caixa de diálogo na qual identificaremos o volume UC onde nossos arquivos de imagem residem e o nome da tabela (ainda não existente) na qual as informações extraídas serão carregadas (Figura 4)
{kind=link}
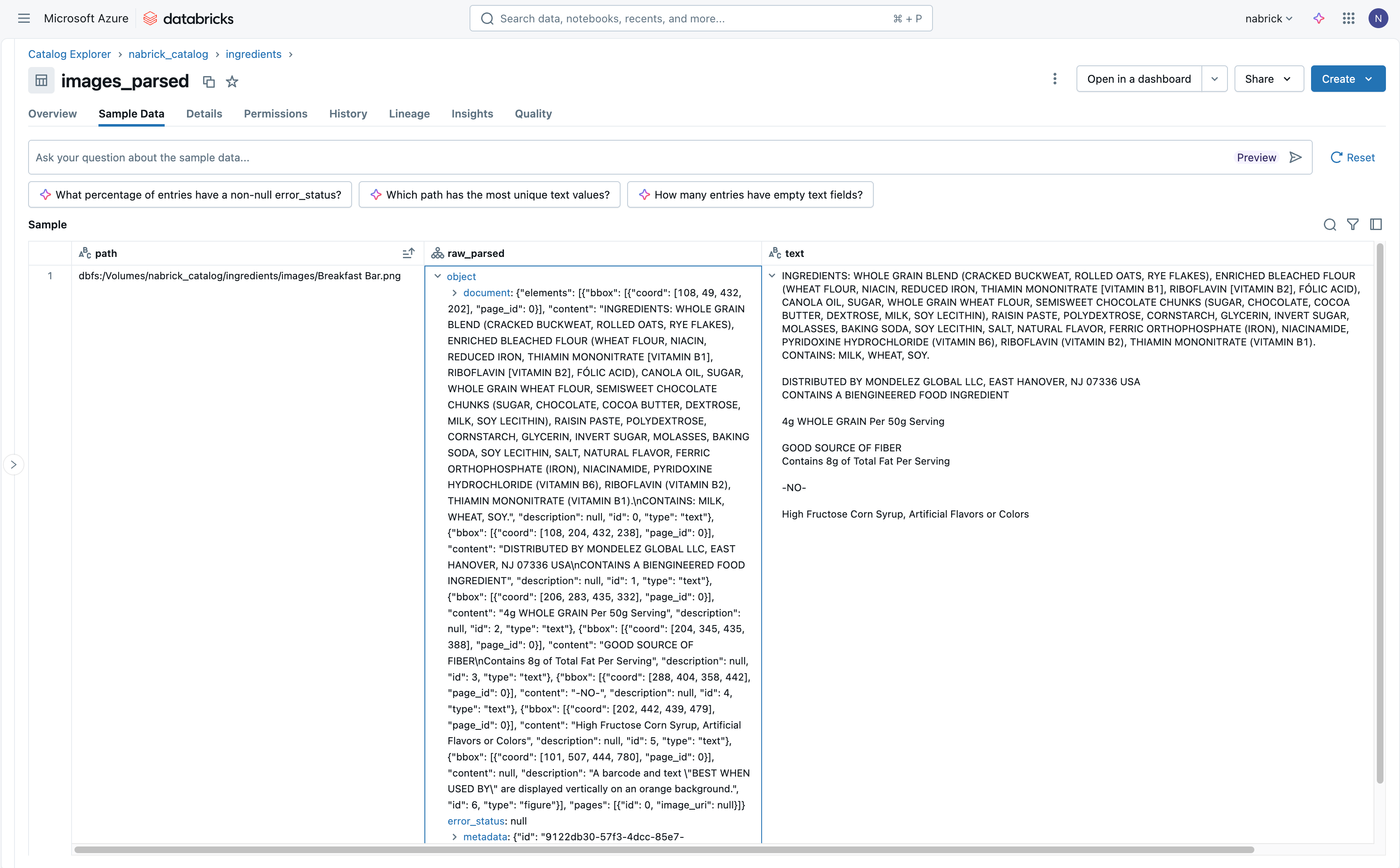
Clicar no botão começar importação inicia um job que extrai detalhes de texto das imagens em nosso volume do UC e os carrega em nossa tabela de destino. (Retornaremos a este job à medida que avançarmos para operacionalizar nosso fluxo de trabalho). A tabela resultante contém um campo que identifica o arquivo do qual o texto foi extraído, juntamente com um campo struct (JSON) e um campo de texto bruto contendo as informações de texto capturadas da imagem (Figura 5).
{kind=link}
Ao analisar as informações de texto entregues à nossa tabela de destino, podemos ver toda a variedade de conteúdo extraído de cada imagem. Qualquer texto legível da imagem é extraído e colocado nos campos raw_parsed e text para nosso acesso.
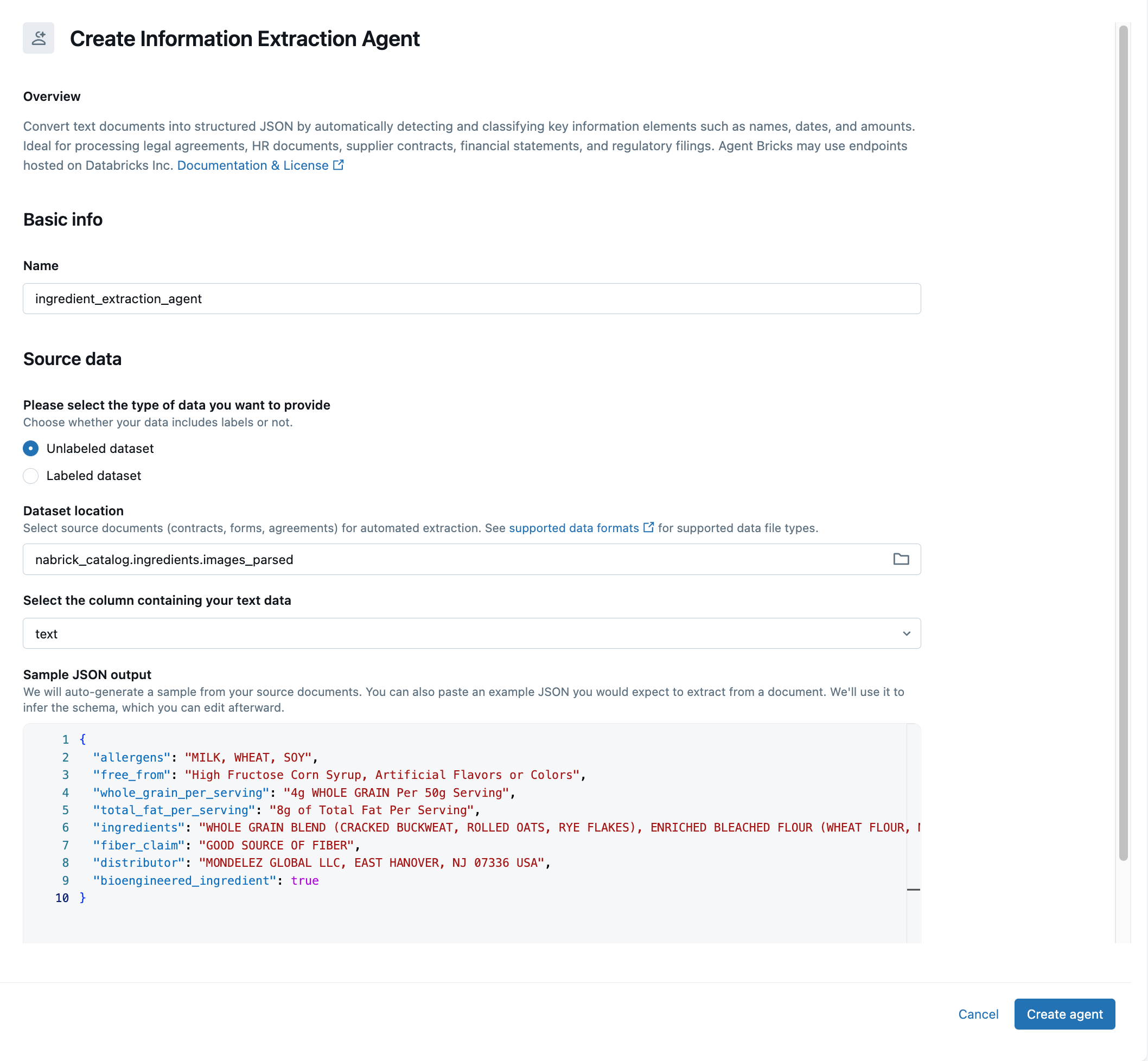
Como estamos interessados apenas no texto associado à lista de ingredientes encontrada em cada imagem, precisaremos implementar um agente para restringir nosso foco e selecionar partes do texto extraído. Para fazer isso, retornamos à página Agents e clicamos na opção Build associada ao agente informação Extraction. Na caixa de diálogo resultante, identificamos a tabela na qual inserimos anteriormente nosso texto extraído e identificamos o campo text nessa tabela como aquele que contém o texto bruto que desejamos processar (Figura 6).
{kind=link}
O agente tentará inferir um esquema para o texto extraído e apresentar elementos de dados mapeados para esse esquema como um exemplo de saída JSON na parte inferior da tela. Podemos aceitar os dados nesta estrutura ou reorganizar manualmente os dados como um documento JSON de nossa própria definição. Se adotarmos a segunda abordagem (como será o caso na maioria das vezes), simplesmente colamos o JSON reorganizado na janela de saída, permitindo que o agente infira um esquema alternativo para os dados de texto. Pode levar várias iterações para o Agent entregar exatamente o que você quer dos dados.
Depois que os dados estiverem organizados da maneira que queremos, clicamos no botão Create Agent para concluir a criação. A UI agora exibe o resultado da análise de vários registros, o que nos dá a oportunidade de validar seu trabalho e fazer outras modificações para chegar a um conjunto consistente de resultados (Figura 7).
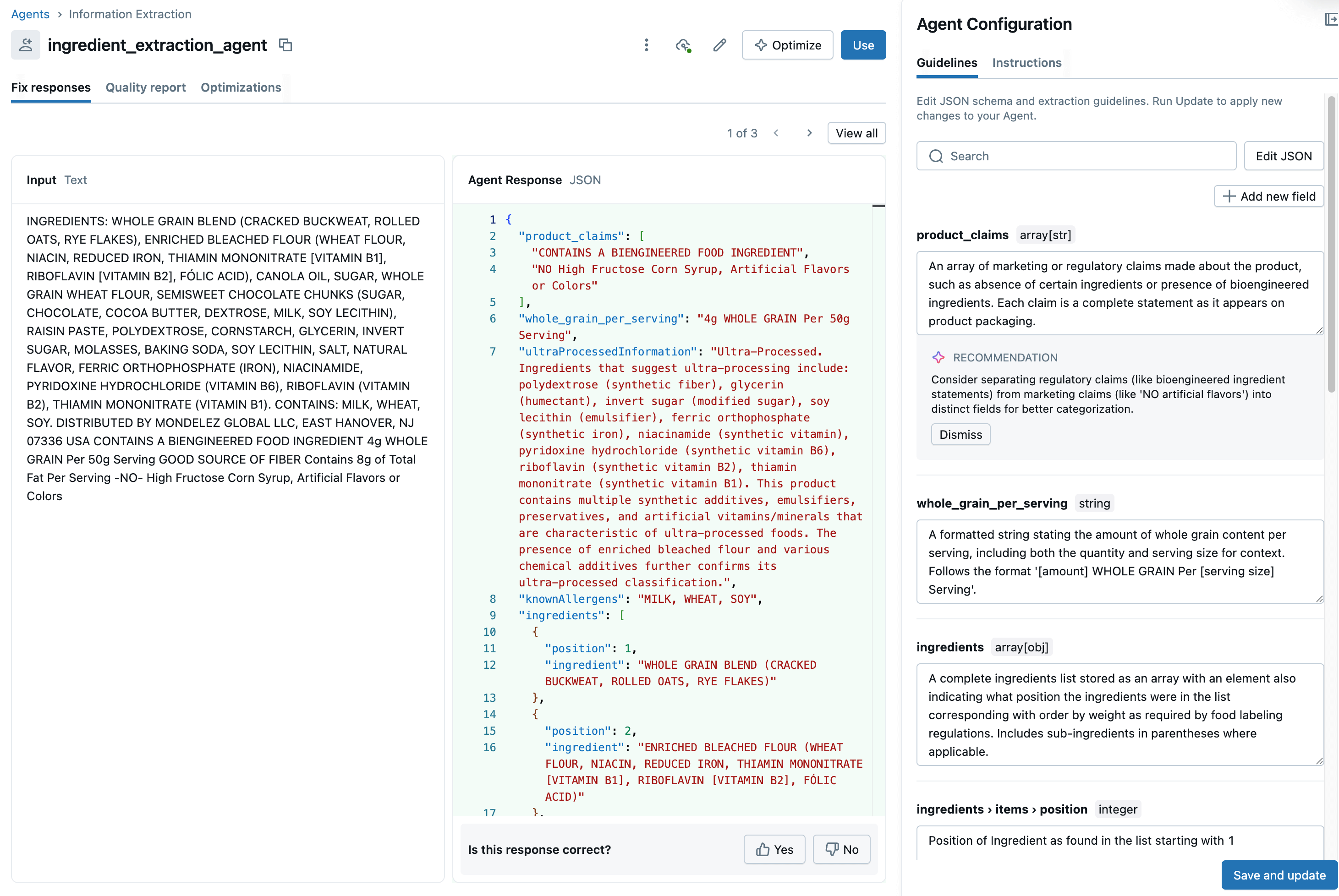
{kind=link}
Além de validar o texto esquematizado, podemos adicionar outros campos usando prompts simples que examinam nossos dados para chegar a um valor. Por exemplo, podemos pesquisar em nossa lista de ingredientes itens que provavelmente contenham glúten para inferir se um produto é sem glúten ou identificar ingredientes de origem animal para identificar um produto como adequado para veganos. O Agente combinará nossos dados com o conhecimento incorporado em um modelo subjacente para chegar a esses resultados.
Clicar em Salvar e atualizar salva nosso Agente ajustado. Podemos usar as tabs Relatório de qualidade e Otimização para aprimorar ainda mais nosso Agente, conforme descrito aqui. Quando estivermos satisfeitos com nosso Agente, clicamos em Usar para concluir a criação. A seleção da opção Create ETL Pipeline gerará um pipeline declarativo que nos permitirá operacionalizar nosso fluxo de trabalho.
Observação: você pode assistir a uma demonstração em vídeo dos seguintes passos aqui.
Operacionalizando a Solução
Neste ponto, definimos um job para extrair texto de imagens e carregá-lo em uma tabela. Também definimos um pipeline de ETL para mapear o texto extraído para um esquema bem definido. Agora podemos combinar esses dois elementos para criar um job de ponta a ponta com o qual podemos processar imagens de forma contínua.
Voltando à tarefa criada em nossa primeira etapa, ou seja, Use PDFs, podemos ver que este job consiste em um único passo. Este o passo é definida como uma query SQL que usa um modelo de AI generativa por meio de uma chamada para a função ai_query(). O interessante dessa abordagem é que ela simplifica, para os desenvolvedores, a personalização da lógica em torno do passo de extração de texto, como a modificação da lógica para processar apenas novos arquivos no volume do UC.
Supondo que estejamos satisfeitos com a lógica no primeiro o passo de nosso job, agora podemos adicionar um o passo subsequente ao job, chamando o pipeline de ETL que definimos anteriormente. As ações principais necessárias para isso estão aqui. O resultado final é que agora temos um job de duas etapas que captura nosso fluxo de trabalho de ponta a ponta para extração da lista de ingredientes, que podemos programar para ser executado de forma contínua (Figura 8).
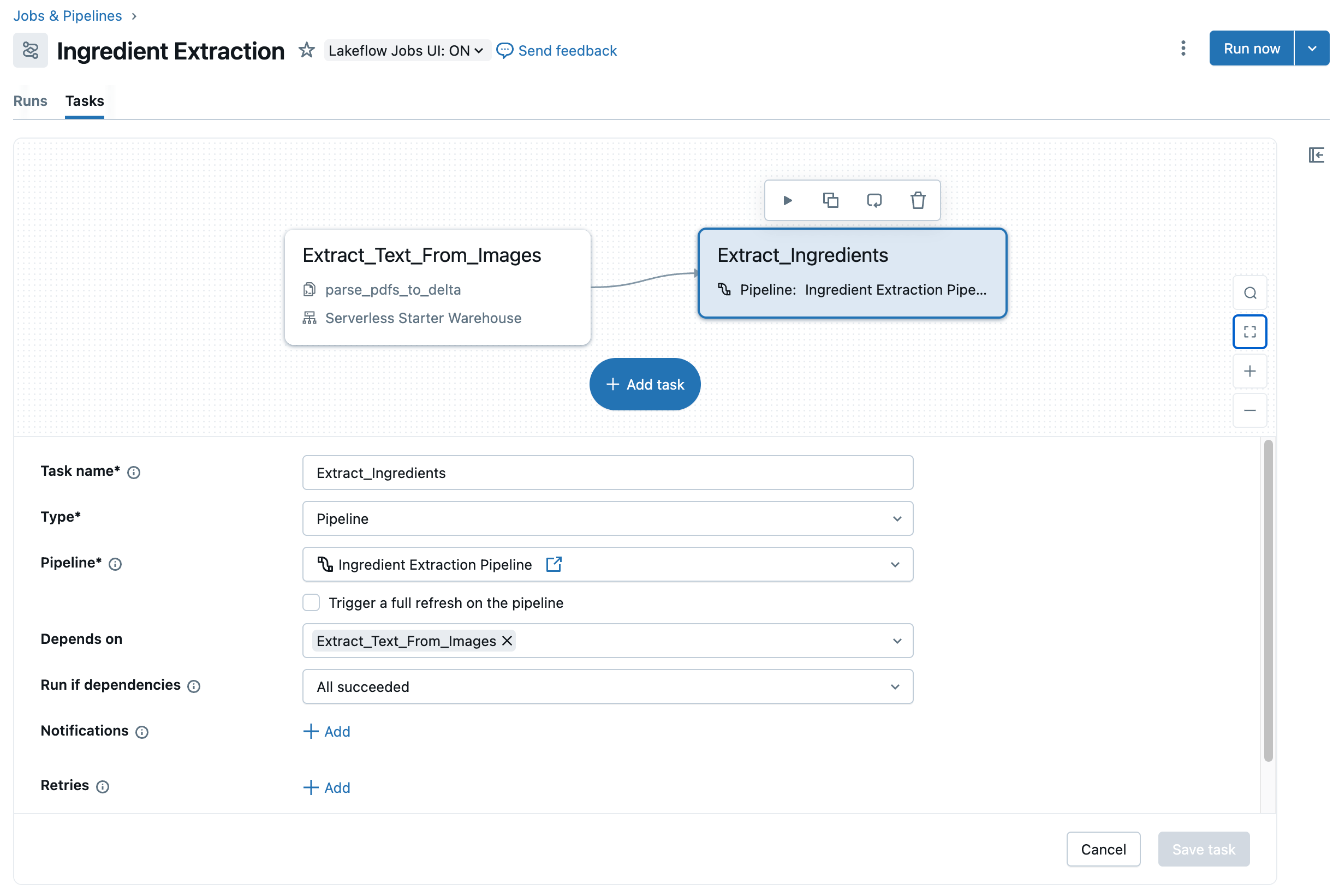
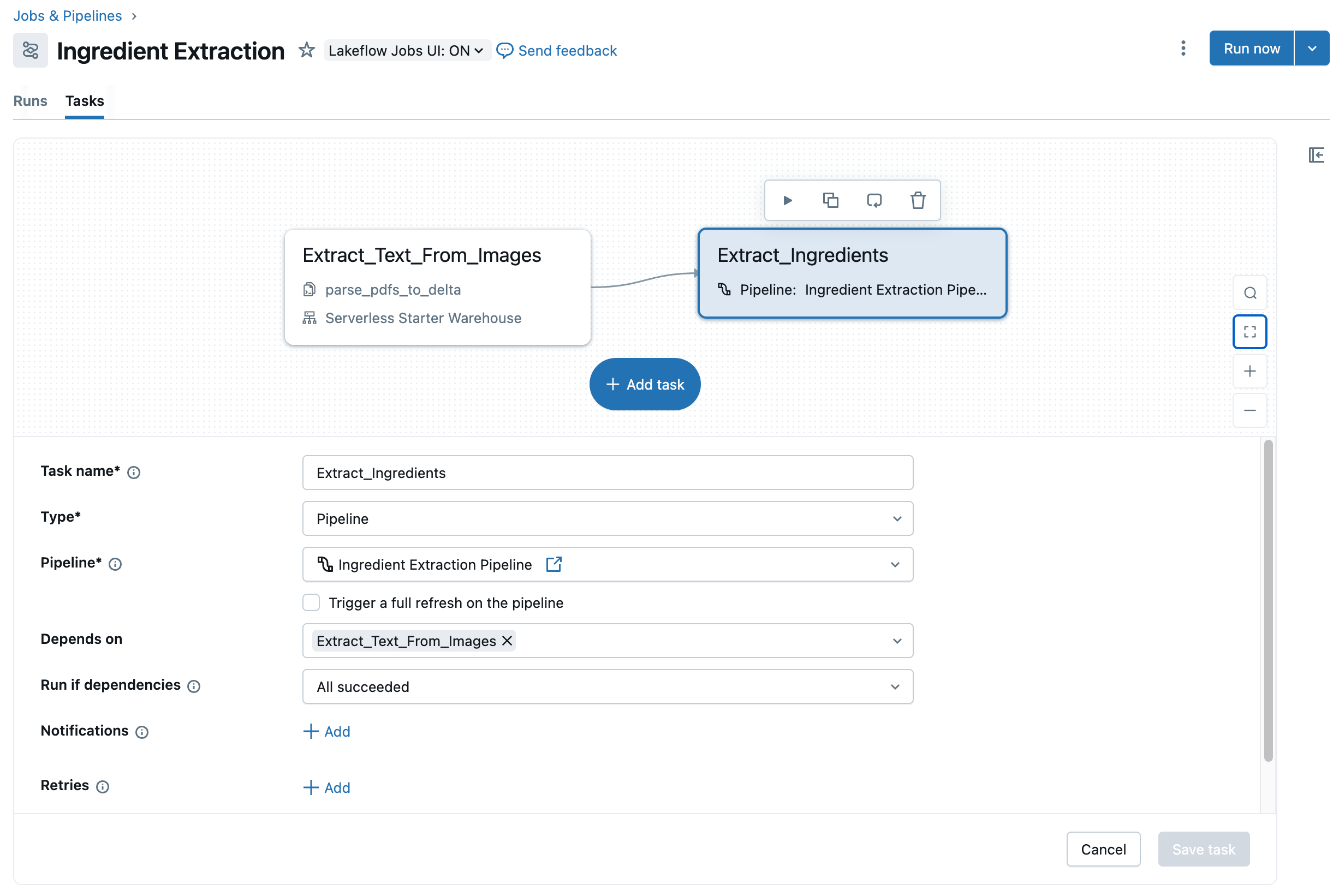{kind=link}
Comece hoje mesmo
Usando o novo recurso Agent Bricks da Databricks, é relativamente fácil criar fluxos de trabalho agênticos capazes de lidar com tarefas manuais anteriormente desafiadoras ou trabalhosas. Isso abre uma série de possibilidades para organizações prontas para automatizar o processamento de documentos em escala, seja para rótulos de alimentos, compliance de fornecedores, relatórios de sustentabilidade ou qualquer outro desafio que envolva dados não estruturados.
Pronto para criar seu primeiro agente? Comece com o Agent Bricks hoje e experimente o que as principais organizações já descobriram: otimização automática, desenvolvimento sem código e qualidade pronta para produção em horas, em vez de semanas. Acesse seu workspace do Databricks, navegue até a página Agentes e transforme suas operações de inteligência de documentos com a mesma tecnología comprovada que já processa milhões de documentos para clientes corporativos no mundo todo.
- Comece a criar seu primeiro agente com o Agent Bricks hoje em seu workspace do Databricks
- Experimente o desenvolvimento no-code e a qualidade pronta para produção em horas, em vez de semanas
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.