Construindo uma Data Mesh Baseada no Databricks Lakehouse, Parte 2
por Bernhard Walter, Sharon Richardson, Guillermo Schiava D'Albano, Pawarit Laosunthara, Amr Ali e Fran Medina Castro
No último post "Databricks Lakehouse e Data Mesh", apresentamos o Data Mesh com base no Databricks Lakehouse. Este post explorará como os recursos do Databricks Lakehouse suportam o Data Mesh de um ponto de vista arquitetônico.
Data Mesh é um paradigma arquitetônico e organizacional, não uma tecnologia ou solução que você compra. No entanto, para implementar um Data Mesh de forma eficaz, você precisa de uma plataforma flexível que garanta a colaboração entre personas de dados, entregue qualidade de dados e facilite a interoperabilidade e a produtividade em todas as cargas de trabalho de dados e IA.
Vamos ver como os recursos da plataforma Databricks Lakehouse atendem a essas necessidades.
O bloco de construção básico de um data mesh é o domínio de dados, geralmente composto pelos seguintes componentes:
- Dados de origem (pertencentes ao domínio)
- Recursos de computação e orquestração self-service (dentro dos Databricks Workspaces)
- Produtos de dados orientados a domínio servidos para outras equipes e domínios
- Insights prontos para consumo por usuários de negócios
- Aderência a políticas de governança computacional federada
Isso é representado na figura abaixo:
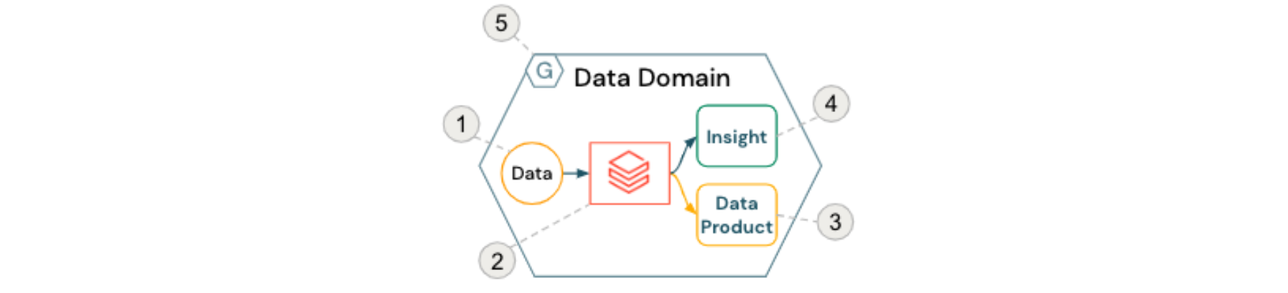
Para facilitar a colaboração entre domínios e a análise self-service, serviços comuns em torno de mecanismos de controle de acesso e catalogação de dados são frequentemente fornecidos centralmente. Por exemplo, o Databricks Unity Catalog fornece não apenas recursos de catalogação informativos, como descoberta de dados e linhagem, mas também a aplicação de controles de acesso granulares e auditoria desejados por muitas organizações hoje.
O Data Mesh pode ser implantado em uma variedade de topologias. Fora de empresas digitais modernas, um Data Mesh altamente descentralizado com domínios totalmente independentes geralmente não é recomendado, pois leva à complexidade e sobrecarga nas equipes de domínio, em vez de permitir que elas se concentrem na lógica de negócios e em dados de alta qualidade. Dois exemplos populares frequentemente vistos em empresas são o Harmonized Data Mesh e o Hub & Spoke Data Mesh.
1) Abordagem para um Data Mesh Harmonizado
Um data mesh harmonizado enfatiza a autonomia dentro dos domínios:
- Os domínios de dados criam e publicam produtos de dados específicos do domínio
- A descoberta de dados é habilitada automaticamente pelo Unity Catalog
- Os produtos de dados são consumidos de forma peer-to-peer
- A infraestrutura de domínio é harmonizada através de
- modelos de plataforma, garantindo segurança e conformidade
- serviços de plataforma self-service (automação de provisionamento de domínio, catalogação de dados, publicação de metadados, políticas sobre dados e recursos de computação)
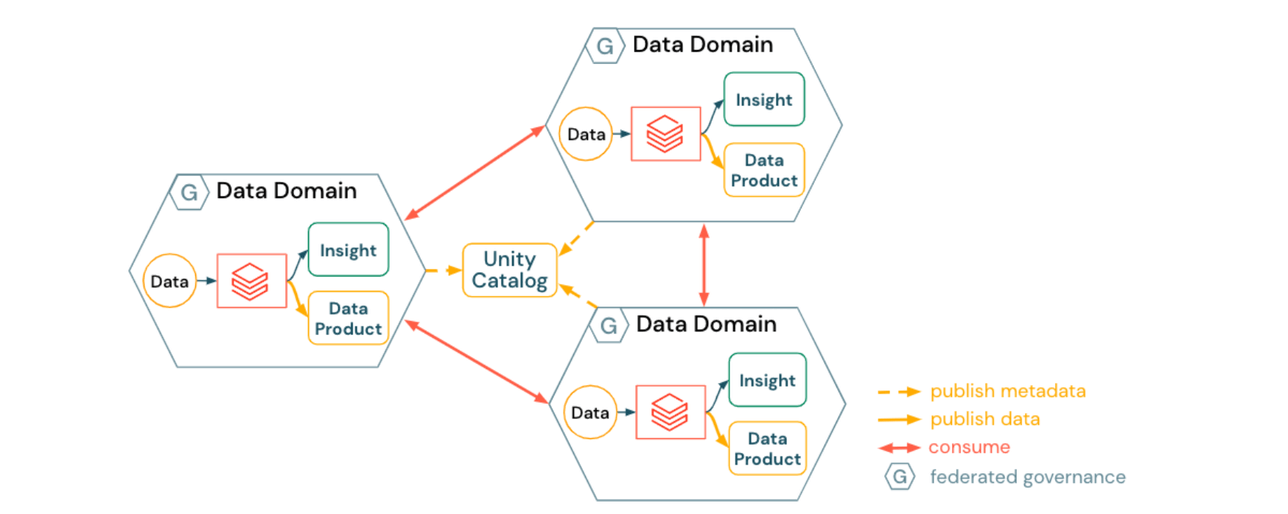
As implicações de uma abordagem harmonizada podem incluir:
- Cada Domínio de Dados precisa aderir a padrões e melhores práticas para interoperabilidade e gerenciamento de infraestrutura
- Cada Domínio de Dados gasta independentemente mais tempo e esforço em tópicos como controles de acesso, contas de armazenamento subjacentes ou até mesmo infraestrutura (por exemplo, brokers de eventos para produtos de dados de streaming)
Essa abordagem pode ser desafiadora em organizações globais onde diferentes equipes têm diferentes amplitudes e profundidades de habilidades e podem ter dificuldade em se manter totalmente sincronizadas com as práticas e políticas mais recentes.
2) Abordagem para um Data Mesh Hub & Spoke
Um Data Mesh Hub & Spoke incorpora um local centralizado para gerenciar ativos de dados compartilháveis e dados que não se encaixam logicamente em um único domínio:
- Os domínios de dados (spokes) criam produtos de dados específicos do domínio
- Os produtos de dados são publicados no data hub, que possui e gerencia a maioria dos ativos registrados no Unity Catalog
- O data hub fornece serviços genéricos de operações de plataforma para domínios de dados, como:
- publicação de dados self-service em locais gerenciados
- catalogação de dados, linhagem, auditoria e controle de acesso via Unity Catalog
- serviços de gerenciamento de dados, como viagem no tempo e processos de GDPR entre domínios (por exemplo, solicitações de direito ao esquecimento)
- O data hub também pode atuar como um domínio de dados. Por exemplo, pipelines ou ferramentas para conjuntos de dados genéricos ou adquiridos externamente, como clima, pesquisa de mercado ou dados macroeconômicos padrão.
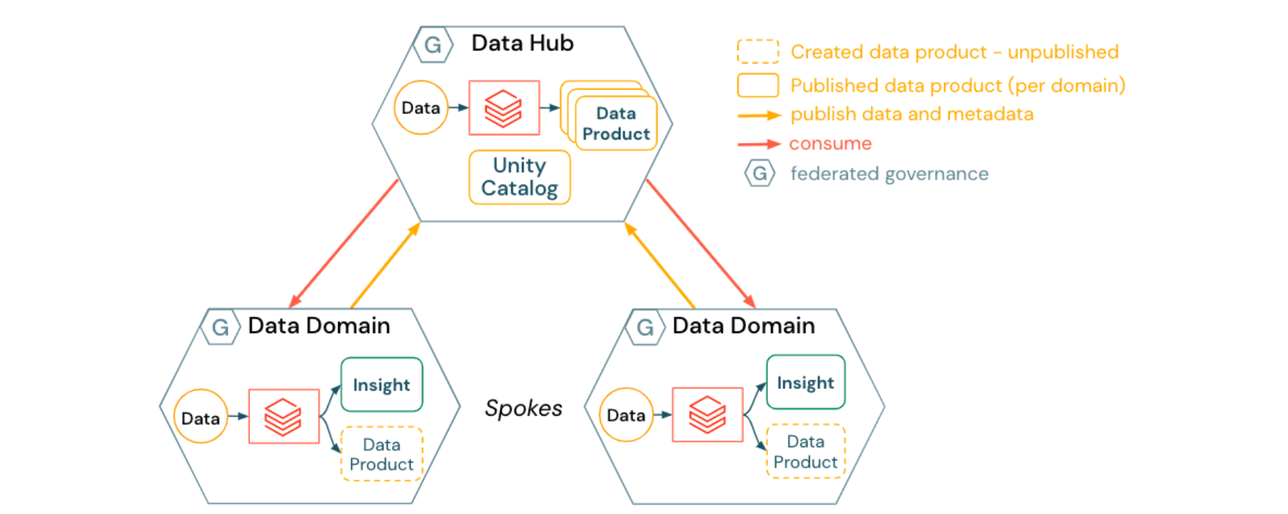
As implicações para um Data Mesh Hub and Spoke incluem:
- Os domínios de dados podem se beneficiar de serviços de dados desenvolvidos e implantados centralmente, permitindo que eles se concentrem mais na lógica de negócios e transformação de dados
- A automação de infraestrutura e a computação self-service podem ajudar a evitar que a equipe do data hub se torne um gargalo para a publicação de produtos de dados
Em ambas essas abordagens, os domínios também podem ter necessidades comuns e repetíveis, como:
- Ferramentas e conectores de ingestão de dados
- Frameworks, modelos ou melhores práticas de MLOps
- Pipelines para CI/CD, qualidade de dados e monitoramento
Ter um pool centralizado de habilidades e expertise, como um centro de excelência, pode ser benéfico tanto para atividades repetíveis comuns entre os domínios quanto para atividades infrequentes que exigem expertise de nicho que pode não estar disponível em cada domínio.
Também é perfeitamente viável ter alguma variação entre um data mesh totalmente harmonizado e um modelo hub-and-spoke. Por exemplo, ter um data hub global mínimo para hospedar apenas ativos de dados que não se encaixam logicamente em um único domínio e para gerenciar dados adquiridos externamente que são usados em vários domínios. O Unity Catalog desempenha o papel fundamental de fornecer descoberta de dados autenticada onde quer que os dados sejam gerenciados em uma implantação Databricks.
Escalando e evoluindo o Data Mesh
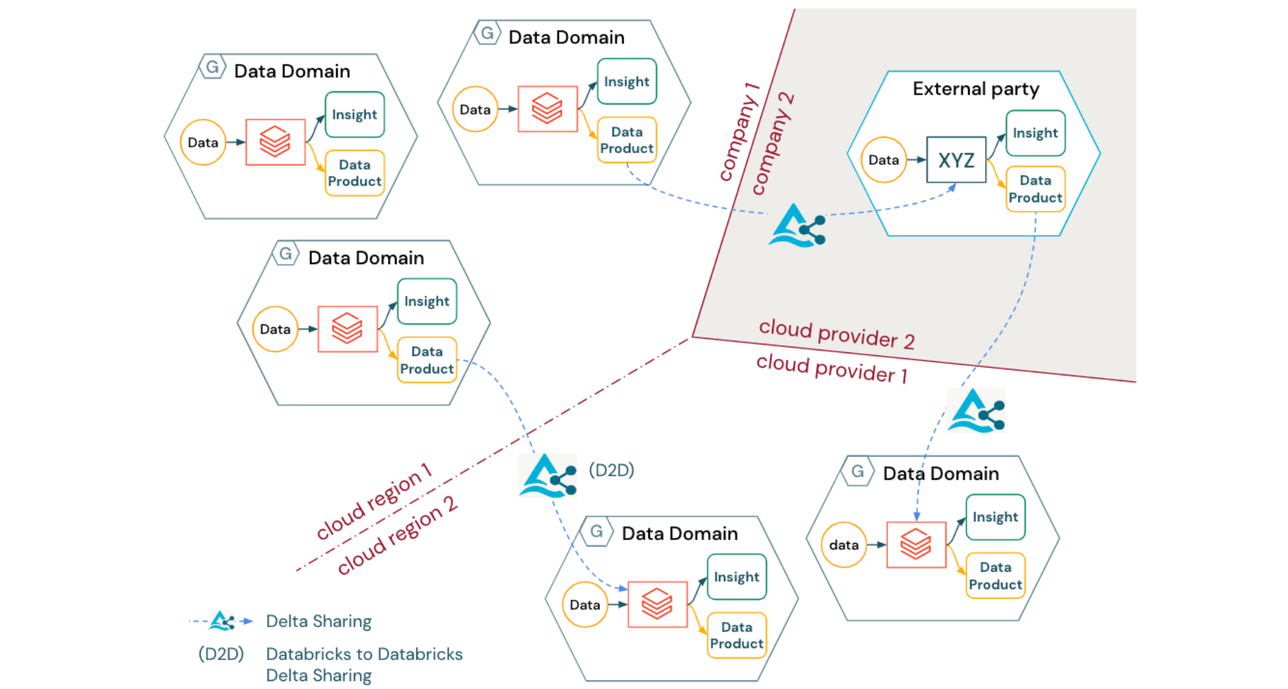
Independentemente do tipo de arquitetura lógica de Data Mesh implantada, muitas organizações enfrentarão o desafio de criar um modelo operacional que abranja regiões de nuvem, provedores de nuvem e até mesmo entidades legais. Além disso, à medida que as organizações evoluem para a produtização (e potencialmente até monetização) de ativos de dados, o compartilhamento de dados interoperável em nível empresarial permanece primordial para a colaboração não apenas entre domínios internos, mas também entre empresas.
Delta Sharing oferece uma solução para este problema com os seguintes benefícios:
- Delta Sharing é um protocolo aberto para compartilhar com segurança produtos de dados entre domínios através de fronteiras organizacionais, regionais e técnicas
- O protocolo Delta Sharing é agnóstico em relação ao fornecedor (incluindo um amplo ecossistema de clientes), fornecendo uma ponte entre diferentes domínios ou até mesmo diferentes empresas sem exigir que elas usem a mesma pilha de tecnologia ou provedor de nuvem
Observações finais
Data Mesh e Lakehouse surgiram devido a pontos problemáticos e deficiências comuns de data warehouses corporativos e data lakes tradicionais[1][2]. O Data Mesh articula abrangentemente a visão de negócios e as necessidades para melhorar a produtividade e o valor dos dados, enquanto o Databricks Lakehouse fornece uma base aberta e escalável para atender a essas necessidades com máxima interoperabilidade, custo-benefício e simplicidade.
Neste artigo, enfatizamos duas capacidades de exemplo da plataforma Databricks Lakehouse que melhoram a colaboração e a produtividade, ao mesmo tempo em que suportam a governança federada, a saber:
- Unity Catalog como habilitador para publicação independente de dados, descoberta central de dados e governança computacional federada na Data Mesh
- Delta Sharing para organizações grandes e distribuídas globalmente que possuem implantações em nuvens e regiões. O Delta Sharing compartilha de forma eficiente e segura dados atualizados entre domínios em diferentes limites organizacionais sem duplicação
No entanto, há uma infinidade de outros recursos do Databricks que servem como ótimos habilitadores na jornada da Data Mesh para diferentes personas. Por exemplo:
- Workflows e Delta Live Tables para pipelines de dados de autoatendimento de alta qualidade, suportando cargas de trabalho em batch e streaming
- Databricks SQL permitindo consultas BI & SQL performáticas diretamente no lake, reduzindo a necessidade de equipes de domínio manterem múltiplas cópias/armazenamentos de dados para seus produtos de dados
- Databricks Feature Store que promove o compartilhamento e a reutilização entre equipes de Ciência de Dados & Machine Learning
Para saber mais sobre Lakehouse para Data Mesh:
- Matei Zaharia: Data Mesh and Lakehouse
- Zalando & Thoughtworks: Data Lakehouse and Data Mesh—Two Sides of the Same Coin
- Databricks: Meshing About with Databricks
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.