Pipelines de dados confiáveis simplificados
Simplifique o ETL em lotes e streaming com confiabilidade automatizada e qualidade de dados inte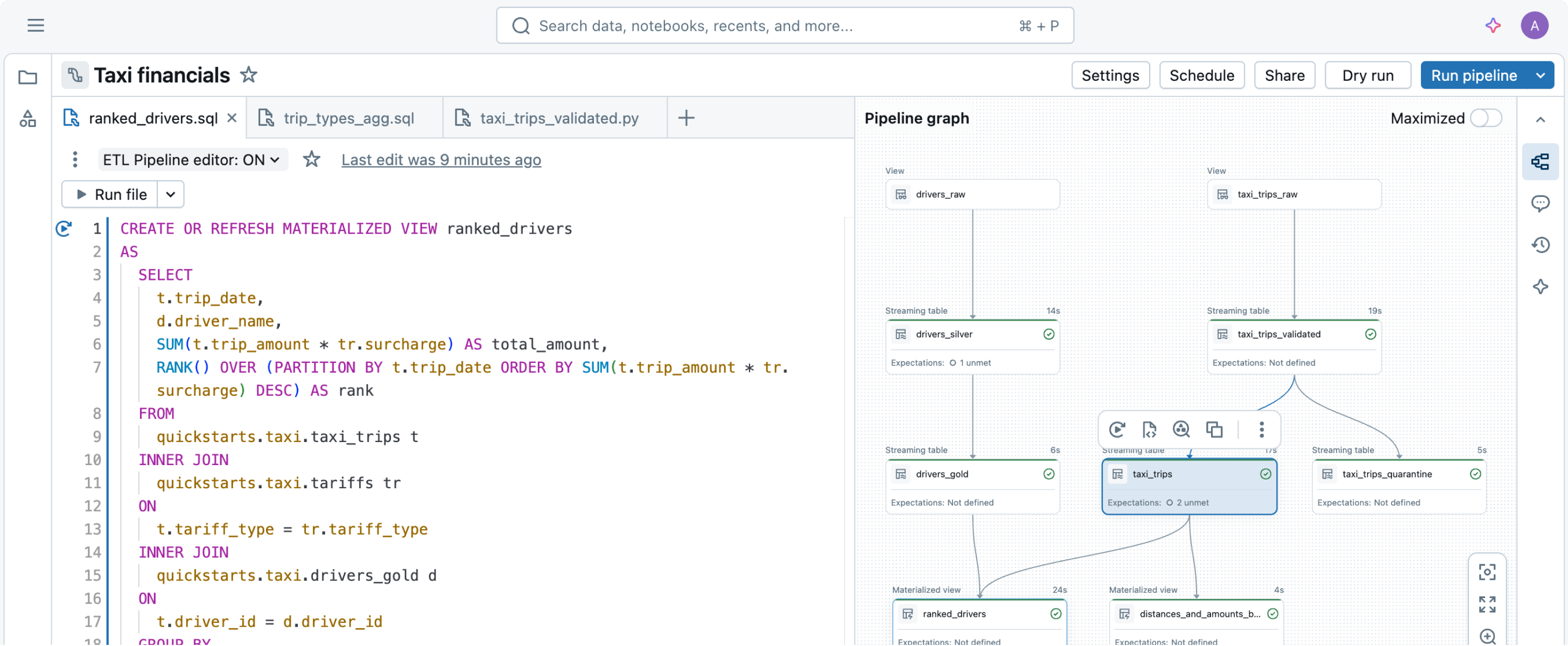
EQUIPES DE ALTO DESEMPENHO OBTÊM SUCESSO COM PIPELINES DE DADOS INTELIGENTES
Melhores práticas de pipeline de dados, codificadas
Basta declarar as transformações de dados de que você precisa e deixar que os pipelines declarativos do Lakeflow cuidem do resto.Ingestão eficiente
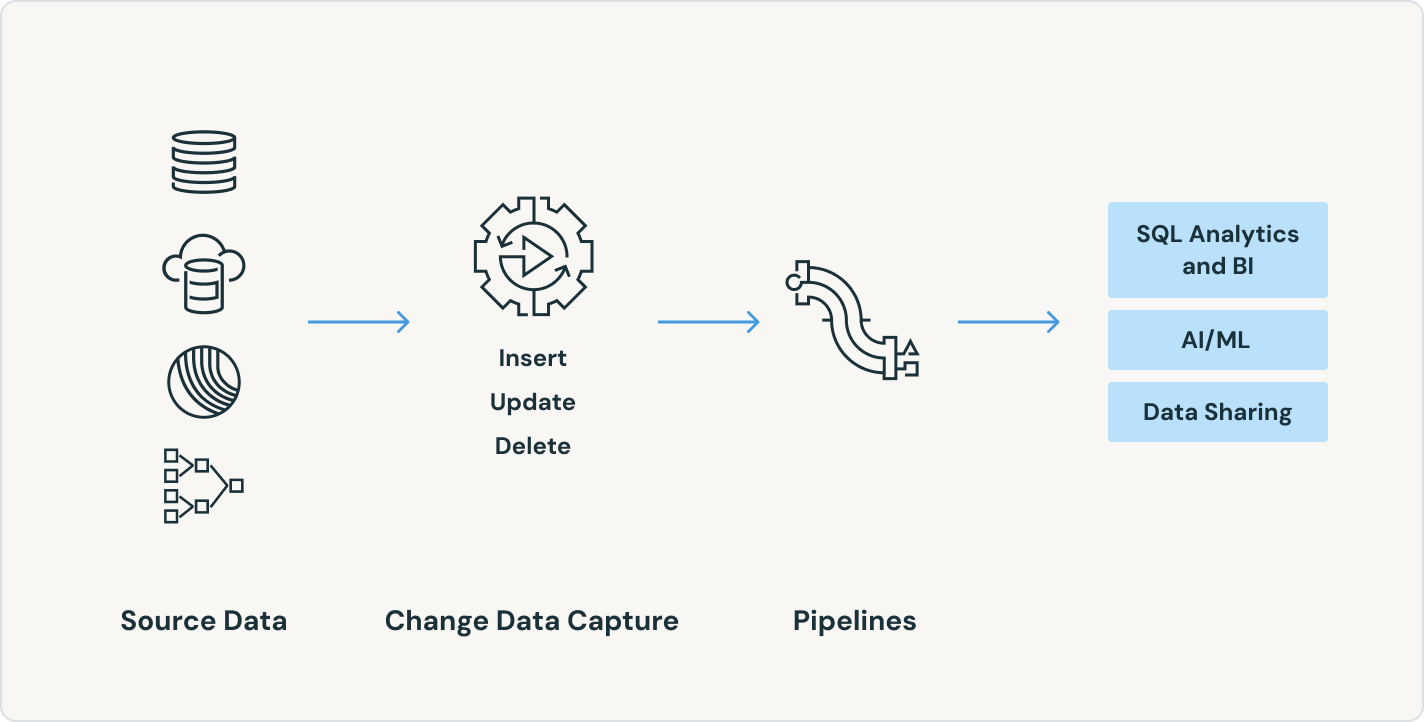
A construção de pipelines ETL prontos para produção começa com a ingestão. Os pipelines declarativos do Lakeflow possibilitam uma ingestão eficiente para engenheiros de dados, desenvolvedores de Python, cientistas de dados e analistas de SQL. Carregue dados de qualquer fonte compatível com Apache Spark™ na Databricks, seja em lotes, streaming ou CDC.
Transformação inteligente
Com apenas algumas linhas de código, os pipelines declarativos do Lakeflow determinam a maneira mais eficiente de construir e executar seus pipelines de dados em lotes ou de streaming, otimizando automaticamente para custo ou desempenho enquanto minimiza a complexidade.
Operações automatizadas
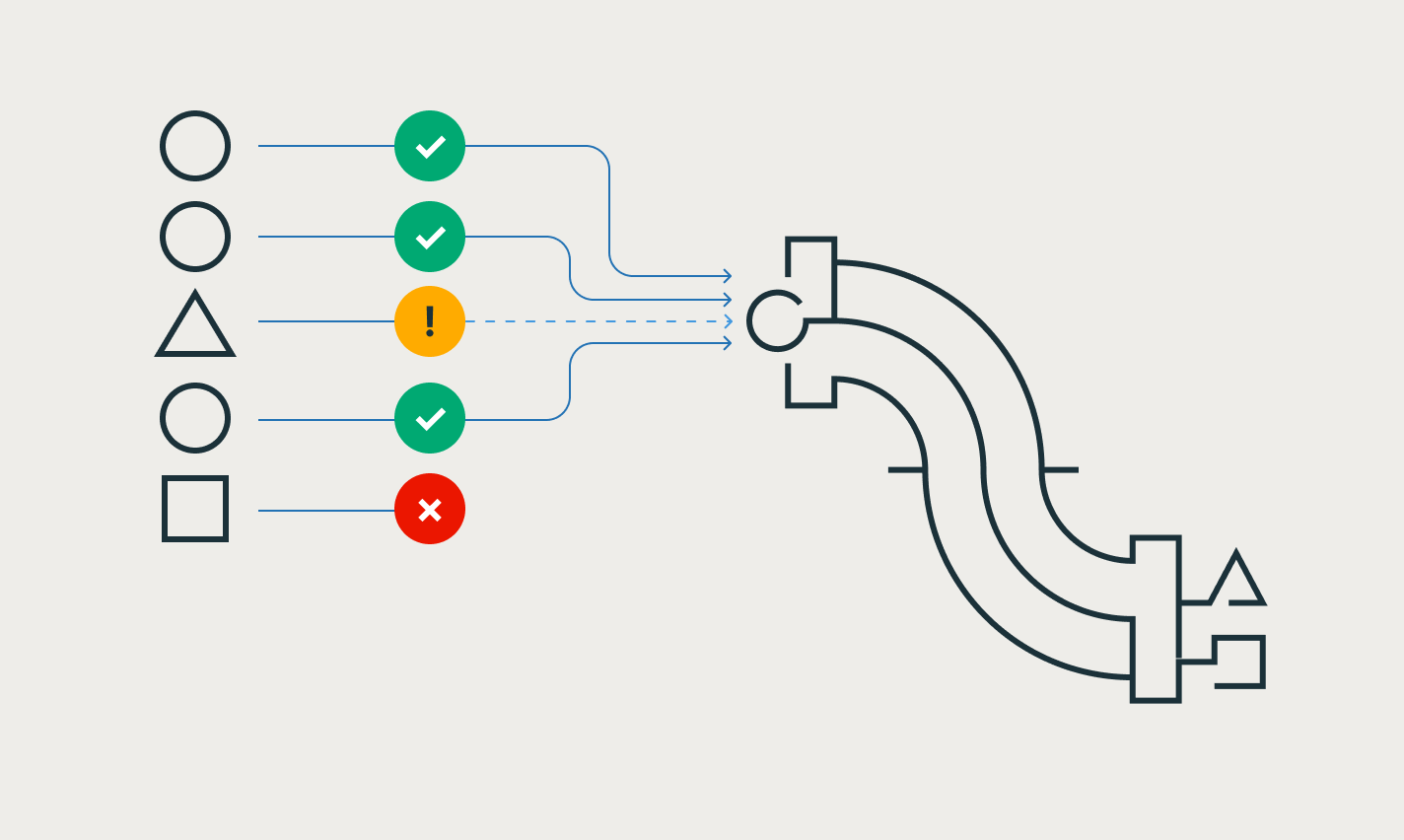
O Spark Declarative Pipelines simplifica o desenvolvimento de pipelines, codificando as melhores práticas por padrão, automatizando o gerenciamento de dependências, o escalonamento e a recuperação, as regras de qualidade de dados e muito mais. Com os pipelines declarativos do Lakeflow, os engenheiros podem se concentrar em fornecer dados de alta qualidade em vez de operar e manter a infraestrutura do pipeline.
Projetado para simplificar o pipeline de dados
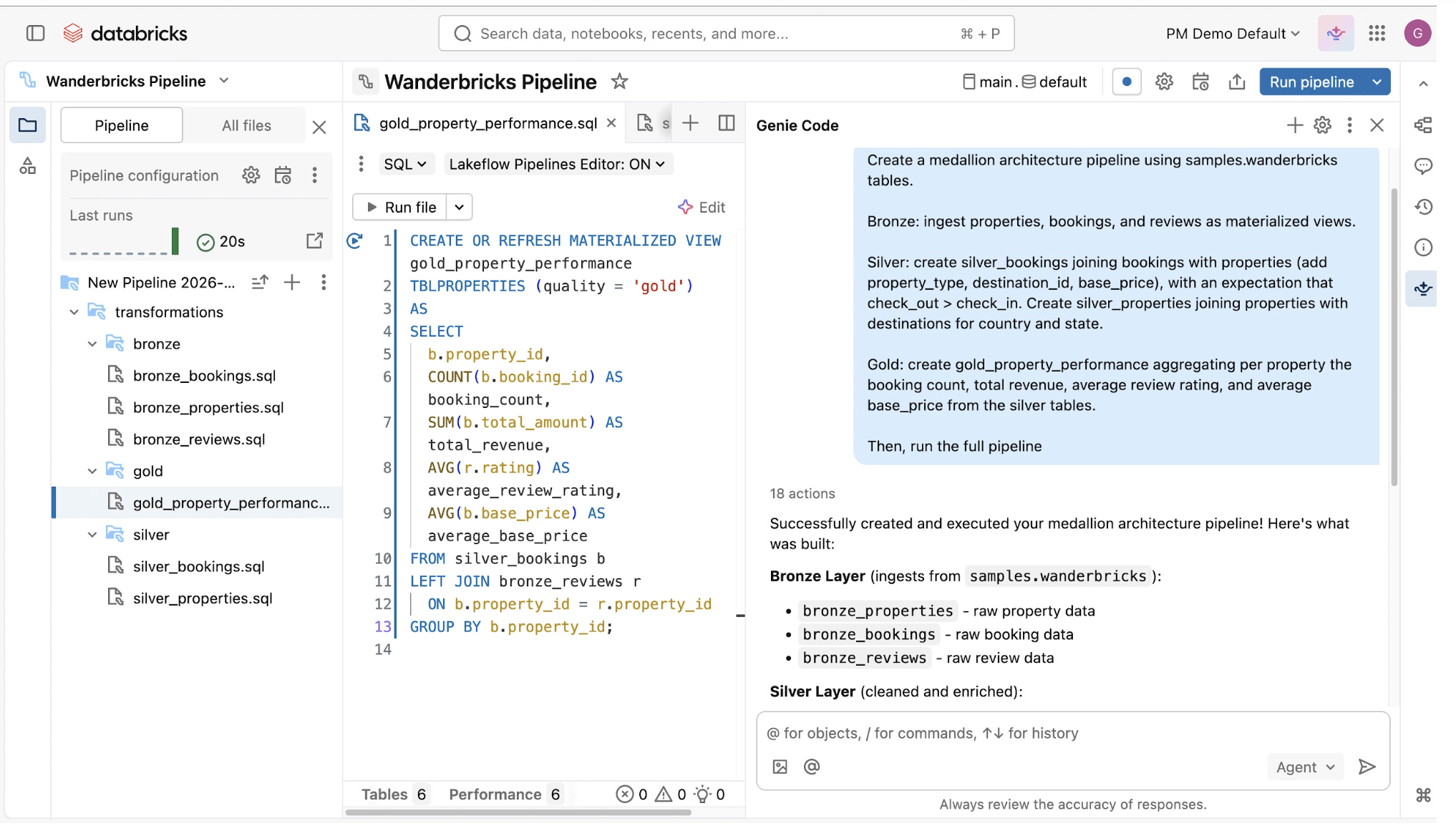
Construir e operar pipelines de dados pode ser difícil, mas não precisa ser. Os pipelines declarativos do Lakeflow são projetados para oferecer simplicidade poderosa, permitindo que você realize ETL robusto com apenas algumas linhas de códigoUse o Genie Code para automatizar cargas de trabalho de ETL, otimizar consultas e criar pipelines por meio de conversas naturais.
Aproveitando a API unificada do Spark para processamento em lotes e streaming, os pipelines declarativos do Lakeflow permitem alternar facilmente entre os modos de processamento.

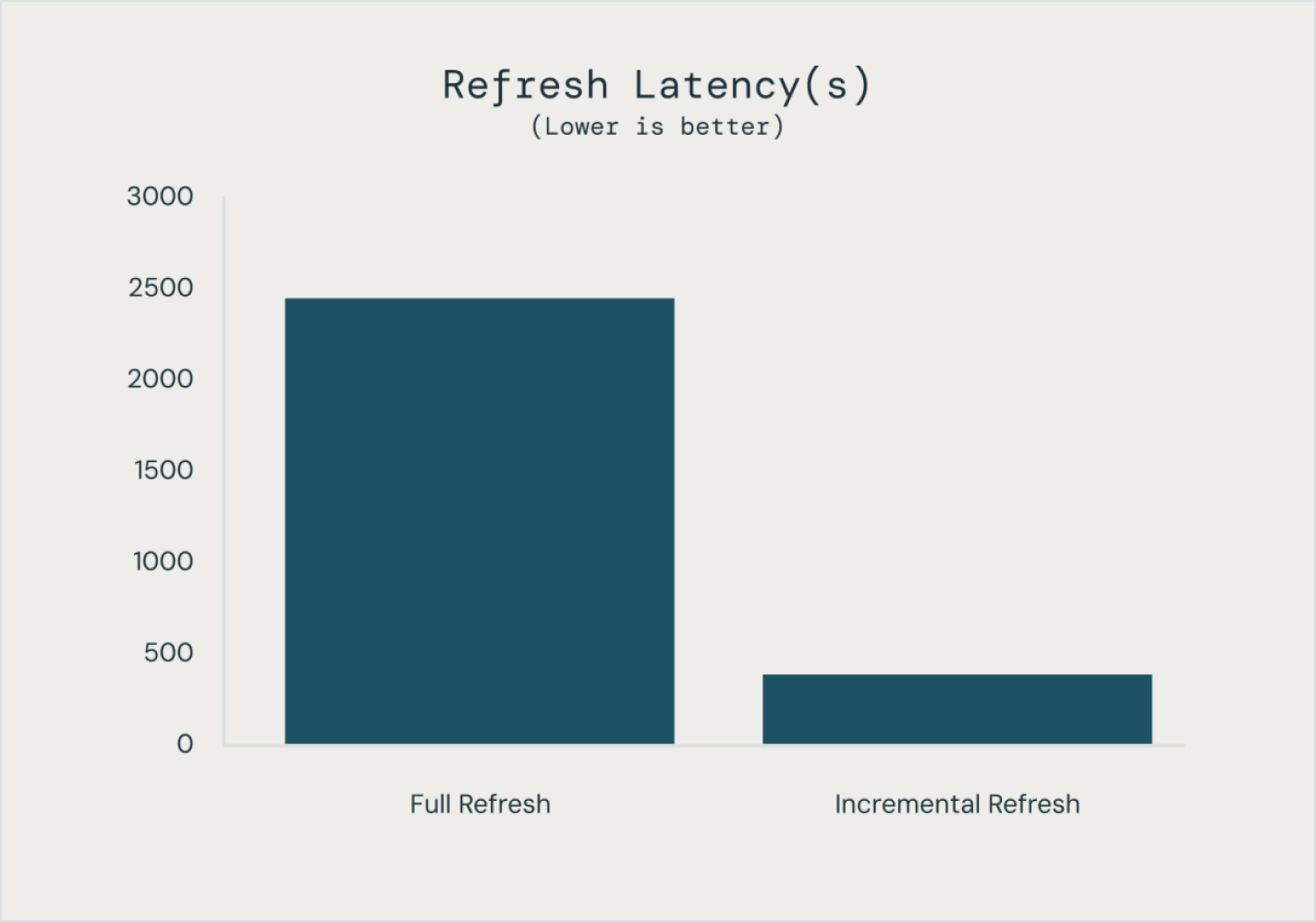
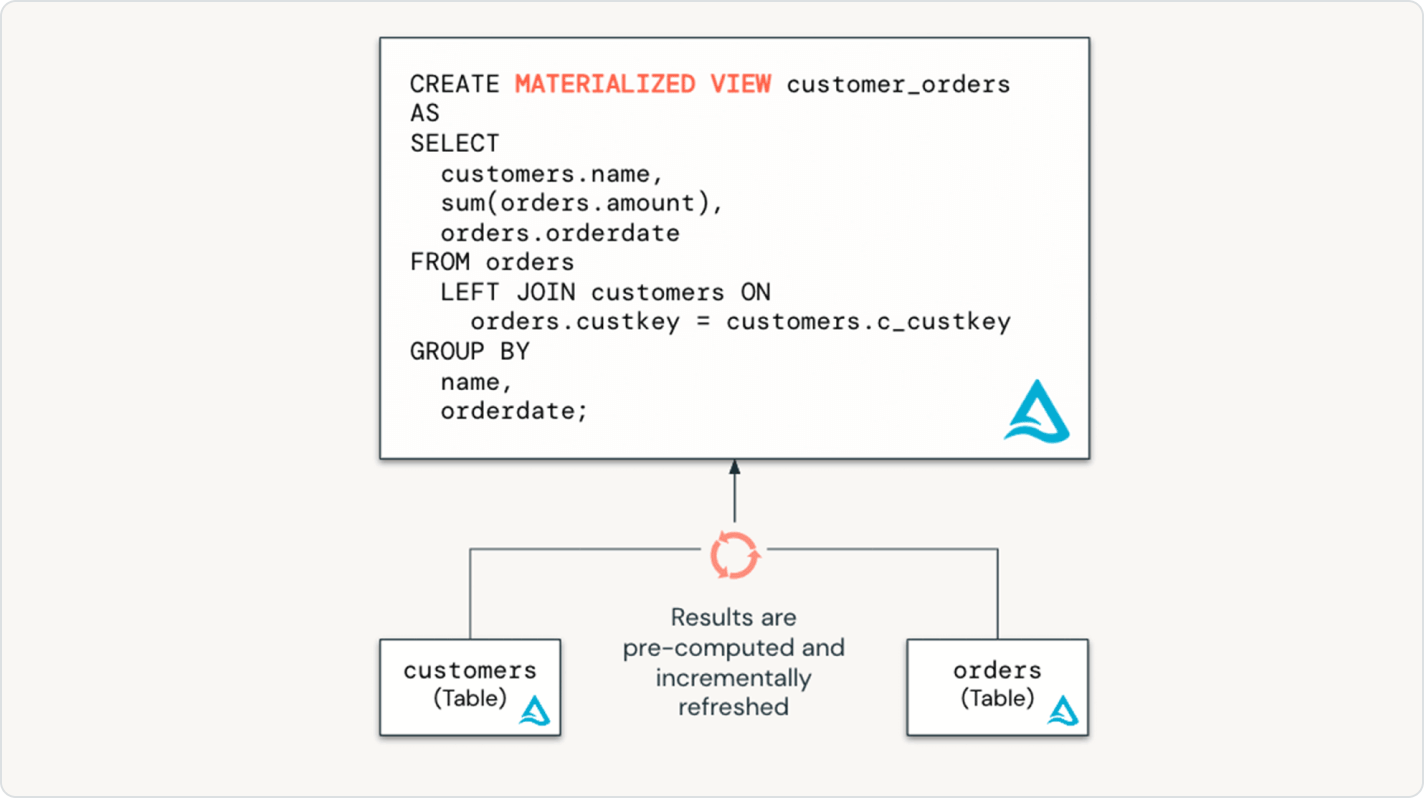
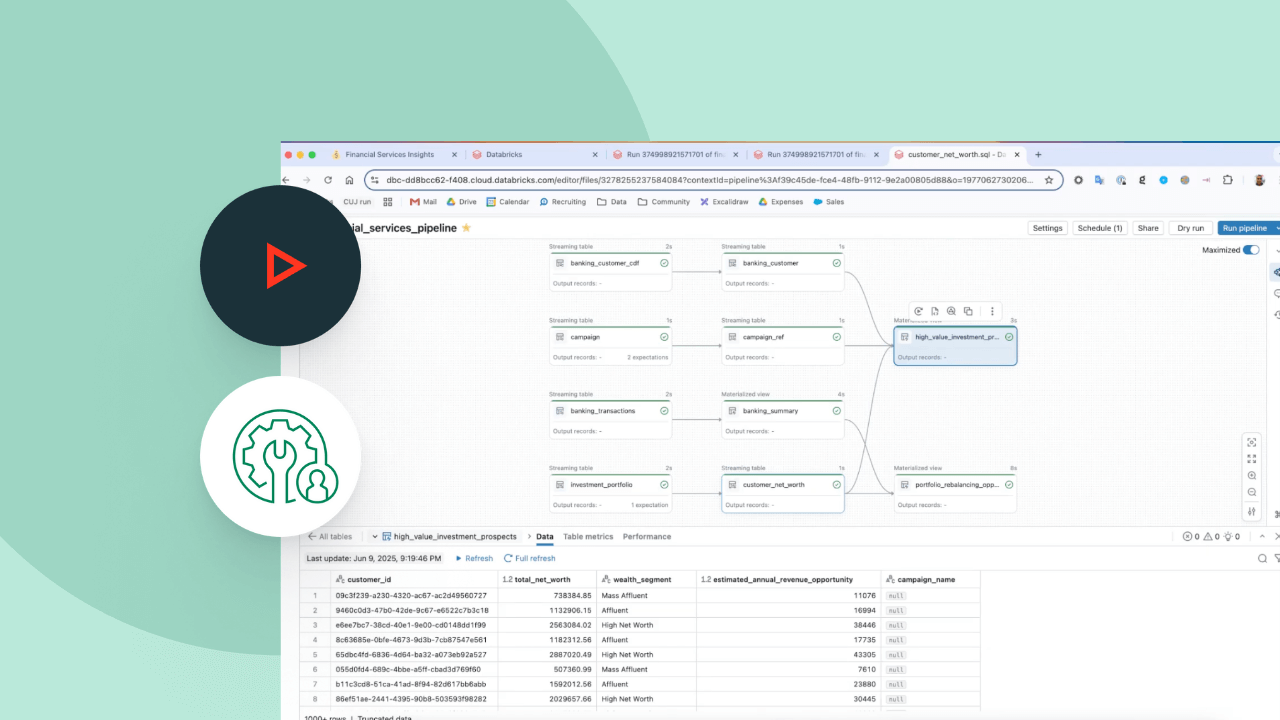
Os pipelines declarativos do Lakeflow facilitam a otimização do desempenho do pipeline ao declarar um pipeline de dados incremental completo com tabelas de streaming e visualizações materializadas.
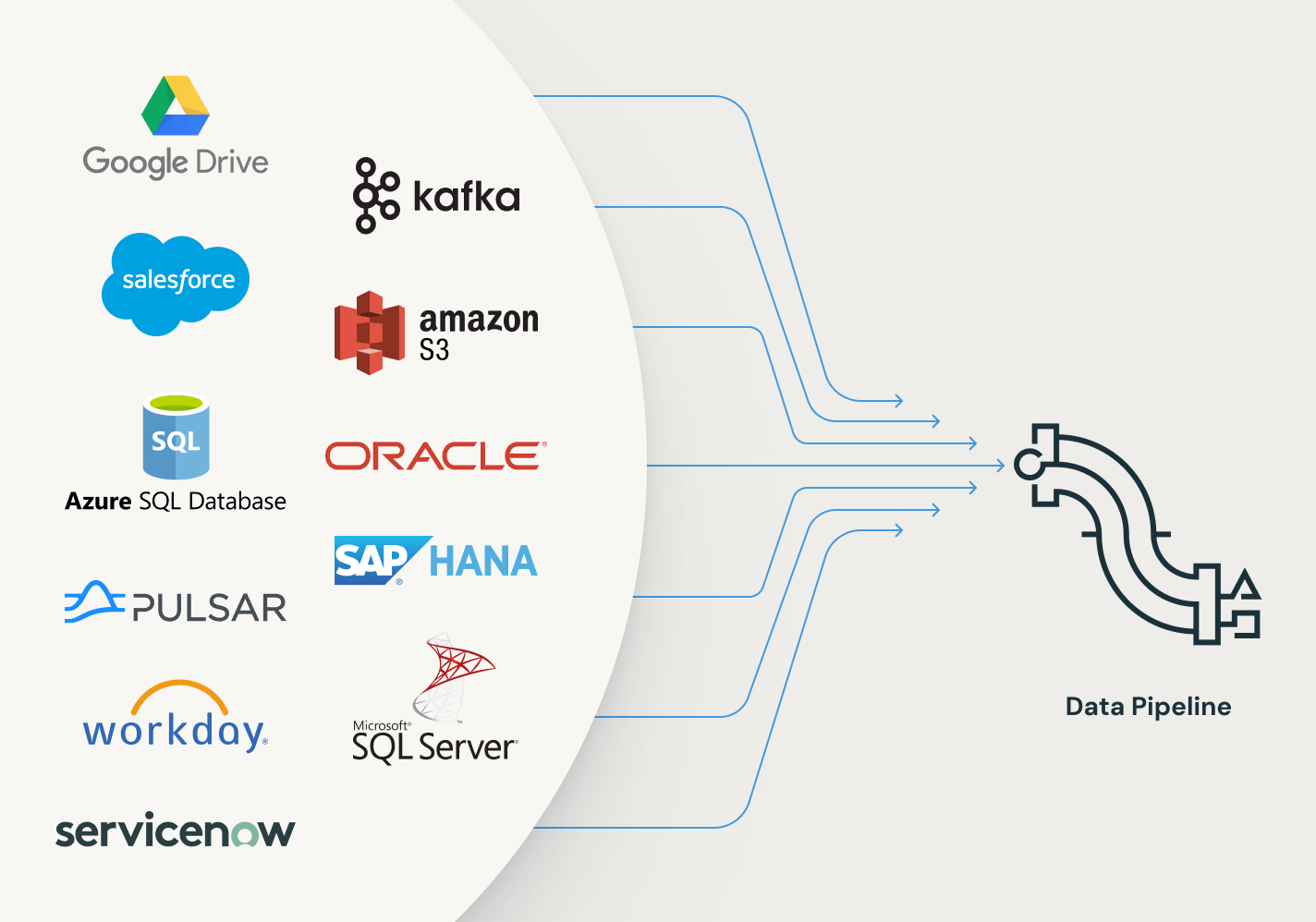
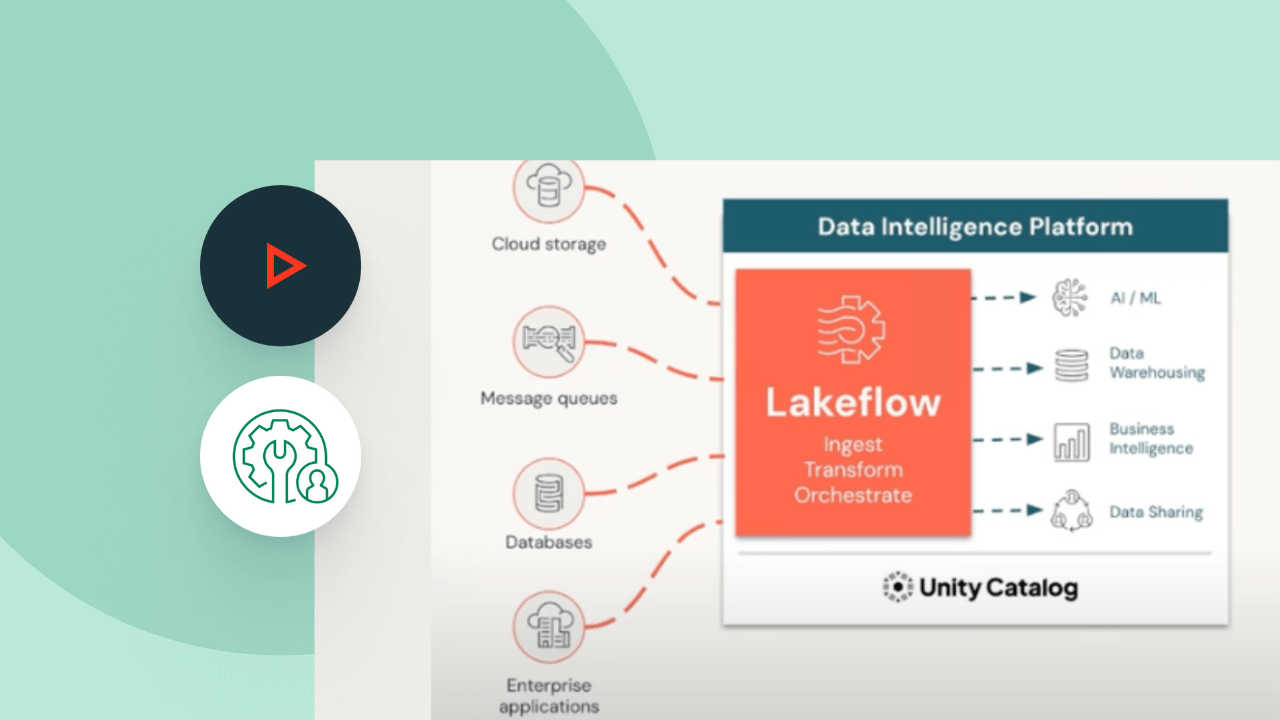
Os pipelines declarativos do Lakeflow são compatíveis com um amplo ecossistema de fontes e destinos. Carregue dados de qualquer fonte, incluindo armazenamento em nuvem, barramentos de mensagens, feeds de dados de alteração, bancos de dados e aplicativos corporativos.
As expectativas permitem que você garanta que os dados que chegam às tabelas atendam aos requisitos de qualidade de dados e forneçam insights sobre a qualidade dos dados a cada atualização do pipeline.
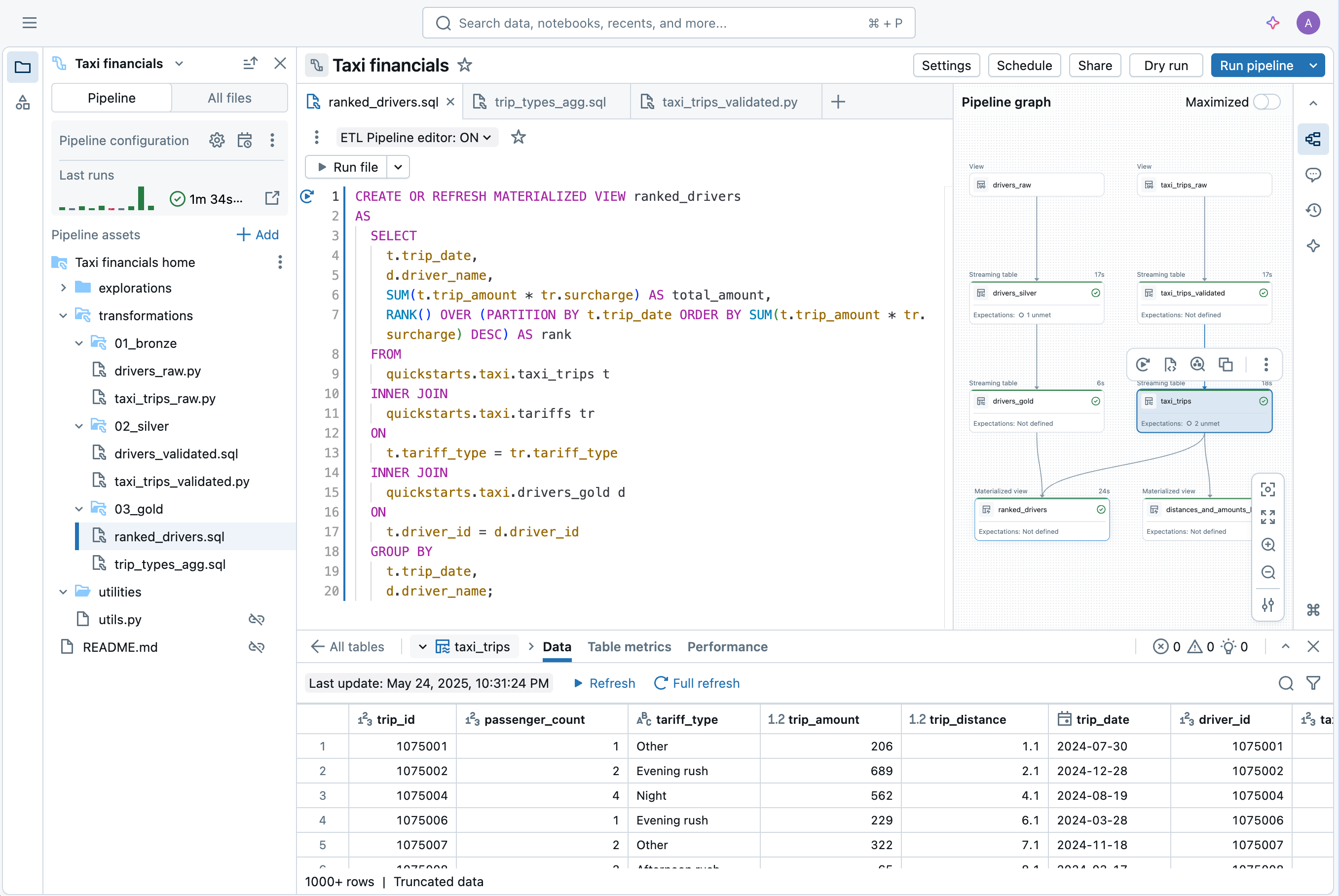
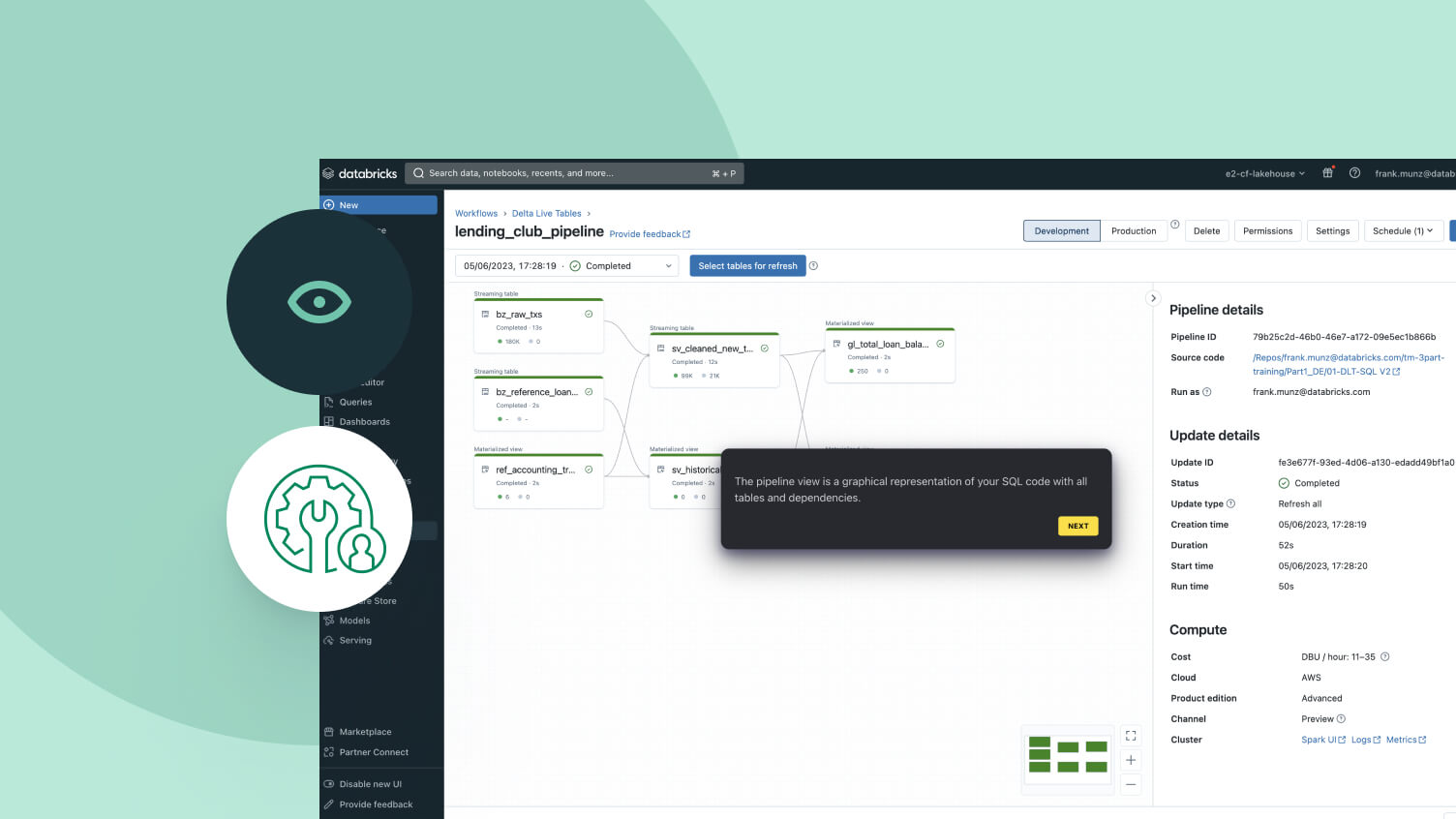
Desenvolva pipelines no IDE para data engineering sem alternar de contexto. Visualize o DAG, a pré-visualização de dados e as percepções de execução em uma única interface de usuário. Desenvolva código facilmente com preenchimento automático, erros em linha e diagnósticos.
Mais recursos
Simplifique seus pipelines de dados

Simplifique as fontes, transformações e destinos
A programação declarativa permite que você aproveite o poder do ETL na Plataforma de Inteligência de Dados com apenas algumas linhas de código.
O preço baseado no uso ajuda a controlar despesas
Pague apenas pelos produtos que usar por segundo.Descubra mais
Explore outras ofertas integradas e inteligentes na plataforma de inteligência de dados.
LakeFlow Connect
Conectores eficientes de data ingestion de qualquer fonte e integração nativa com a Plataforma de Inteligência de Dados desbloqueiam fácil acesso a analytics e AI, com governança unificada.

Jobs do Lakeflow
O Workflows permite definir, gerenciar e monitorar facilmente fluxos de trabalho multitarefa para ETL, análises e pipelines de machine learning. Com uma ampla variedade de tipos de tarefas compatíveis, recursos de observabilidade detalhada e alta confiabilidade, suas equipes de dados podem automatizar e orquestrar melhor qualquer pipeline e aumentar a produtividade.

Genie Code
Seu parceiro autônomo de AI para trabalho com dados.

Armazenamento lakehouse
Unifique os dados em seu lakehouse, em todos os formatos e tipos, para todas as suas cargas de trabalho de analytics e AI.

Unity Catalog
Governe sem esforço todos os seus ativos de dados com a única solução de governança unificada e aberta do setor para dados e AI, integrada à Databricks Data Intelligence Platform.
A Plataforma Databricks
Descubra como a Databricks Platform permite suas cargas de trabalho de dados e IA.
Dê um passo adiante




Pipelines Declarativos do Spark
Pronto para se tornar uma empresa de dados + IA?
Dê os primeiros passos em sua transformação