Announcing the General Availability of Databricks Lakeflow
The unified approach to data engineering across ingestion, transformation, and orchestration
by Bilal Aslam and Michael Armbrust
- Databricks Lakeflow solves the data engineering challenges posed by fragmented stacks by offering a unified solution for ingestion, transformation, and orchestration on the data intelligence platform.
- Lakeflow Connect adds more connectors to databases, file sources, enterprise applications and data warehouses. Zerobus introduces high-throughput direct writes with low latency.
- Lakeflow Declarative Pipelines, built on the new open Spark Declarative Pipelines standard, features a new IDE for data engineers for better ETL pipeline development.
We’re excited to announce that Lakeflow, Databricks’ unified data engineering solution, is now Generally Available. It includes expanded ingestion connectors for popular data sources, a new “IDE for data engineering” that makes it easy to build and debug data pipelines, and expanded capabilities for operationalizing and monitoring ETL.
In last year’s Data + AI Summit, we introduced Lakeflow – our vision for the future of data engineering – an end-to-end solution which includes three core components:
- Lakeflow Connect: Reliable, managed ingestion from enterprise apps, databases, file systems, and real-time streams, without the overhead of custom connectors or external services.
- Lakeflow Declarative Pipelines: Scalable ETL pipelines built on the open standard of Spark Declarative Pipelines, integrated with governance and observability, and providing a streamlined development experience through a modern “IDE for data engineering”.
- Lakeflow Jobs: Native orchestration for the Data Intelligence Platform, supporting advanced control flow, real-time data triggers, and comprehensive monitoring.
By unifying data engineering, Lakeflow eliminates the complexity and cost of stitching together different tools, enabling data teams to focus on creating value for the business. Lakeflow Designer, the new AI-powered visual pipeline builder, empowers any user to build production-grade data pipelines without writing code.
It’s been a busy year, and we’re super excited to share what’s new as Lakeflow reaches General Availability.
Data engineering teams struggle to keep up with their organizational data needs
In every industry, a business’s ability to extract value from its data through analytics and AI is its competitive advantage. Data is being utilized in every facet of the organization - to create Customer 360° views and new customer experiences, to enable new revenue streams, to optimize operations and to empower employees. As organizations look to utilize their own data, they end up with a patchwork of tooling. Data engineers find it hard to tackle the complexity of data engineering tasks while navigating fragmented tool stacks that are painful to integrate and costly to maintain.
A key challenge is data governance - fragmented tooling makes it difficult to enforce standards, leading to gaps in discovery, lineage and observability. A recent study by The Economist found that “half of data engineers say governance takes up more time than anything else”. That same survey asked data engineers what would yield the biggest benefits for their productivity, and they identified “‘simplifying data source connections for ingesting data’, ‘using a single unified solution instead of multiple tools’ and ‘better visibility into data pipelines to find and fix issues’ among the top interventions”.
A unified data engineering solution built into the Data Intelligence Platform
Lakeflow helps data teams tackle these challenges by providing an end-to-end data engineering solution on the Data Intelligence Platform. Databricks customers can use Lakeflow for every aspect of data engineering - ingestion, transformation and orchestration. Because all of these capabilities are available as part of a single solution, there is no time spent on complex tool integrations or extra costs to license external tools.
In addition, Lakeflow is built into the Data Intelligence Platform and with this comes consistent ways to deploy, govern and observe all data and AI use cases. For example, for governance, Lakeflow integrates with Unity Catalog, the unified governance solution for the Data Intelligence Platform. Through Unity Catalog, data engineers gain full visibility and control over every part of the data pipeline, allowing them to easily understand where data is being used and root cause issues as they arise.
Whether it is versioning code, deploying CI/CD pipelines, securing data or observing real-time operational metrics, Lakeflow leverages the Data Intelligence Platform to provide a single and consistent place to manage end-to-end data engineering needs.
Lakeflow Connect: More connectors, and fast direct writes to Unity Catalog
This past year, we’ve seen strong adoption of Lakeflow Connect with over 2,000 customers using our ingestion connectors to unlock value from their data. One example is Porsche Holding Salzburg who is already seeing the benefits of using Lakeflow Connect to unify their CRM data with analytics to improve the customer experience.
“Using the Salesforce connector from Lakeflow Connect helps us close a critical gap for Porsche from the business side on ease of use and price. On the customer side, we're able to create a completely new customer experience that strengthens the bond between Porsche and the customer with a unified and not fragmented customer journey.” —Lucas Salzburger, Project Manager, Porsche Holding Salzburg
Today, we are expanding the breadth of supported data sources with more built-in connectors for simple, reliable ingestion. Lakeflow’s connectors are optimized for efficient data extraction including using change data capture (CDC) methods customized for each respective data source.
These managed connectors now span enterprise applications, file sources, databases, and data warehouses, rolling out across various release states:
- Enterprise applications: Salesforce, Workday, ServiceNow, Google Analytics, Microsoft Dynamics 365, Oracle NetSuite
- File sources: SFTP, SharePoint
- Databases: Microsoft SQL Server, Oracle Database, MySQL, PostgreSQL
- Data warehouses: Snowflake, Amazon Redshift, Google BigQuery
In addition, a common use case we see from customers is ingesting real-time event data, typically with message bus infrastructure hosted outside their data platform. To make this use case simple on Databricks, we are announcing Zerobus, a Lakeflow Connect API that allows developers to write event data directly to their lakehouse at very high throughput (100 MB/s) with near real-time latency (<5 seconds). This streamlined ingestion infrastructure provides performance at scale and is unified with the Databricks Platform so you can leverage broader analytics and AI tools right away.
“Joby is able to use our manufacturing agents with Zerobus to push gigabytes a minute of telemetry data directly to our lakehouse, accelerating the time to insights - all with Databricks Lakeflow and the Data Intelligence Platform.” —Dominik Müller, Factory Systems Lead, Joby Aviation Inc.
Lakeflow Declarative Pipelines: Accelerated ETL development built on open standards
After years of operating and evolving DLT with thousands of customers across petabytes of data, we’ve taken everything we learned and created a new open standard: Spark Declarative Pipelines. This is the next evolution in pipeline development - declarative, scalable, and open.
And today, we’re excited to announce the General Availability of Lakeflow Declarative Pipelines, bringing the power of Spark Declarative Pipelines to the Databricks Data Intelligence Platform. It’s 100% source-compatible with the open standard, so you can develop pipelines once and run them anywhere. It’s also 100% backward-compatible with DLT pipelines, so existing users can adopt the new capabilities without rewriting anything. Lakeflow Declarative Pipelines are a fully managed experience on Databricks: hands-off serverless compute, deep integration with Unity Catalog for unified governance, and a purpose-built IDE for Data Engineering.
The new IDE for Data Engineering is a modern, integrated environment built to streamline the pipeline development experience. It includes
- Code and DAG side by side, with dependency visualization and instant data previews
- Context-aware debugging that surfaces issues inline
- Built-in Git integration for rapid development
- AI-assisted authoring and configuration
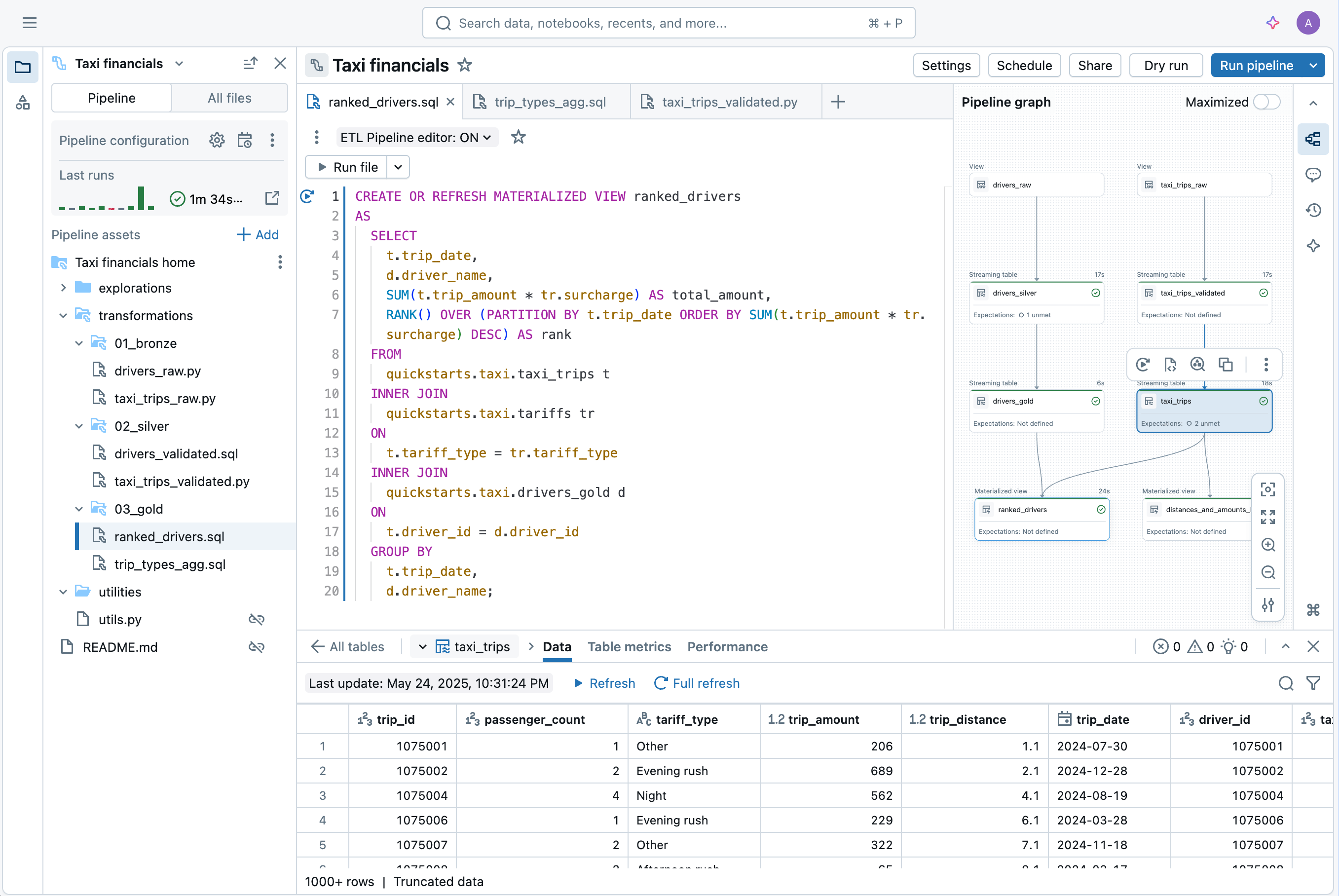
“The new editor brings everything into one place - code, pipeline graph, results, configuration, and troubleshooting. No more juggling browser tabs or losing context. Development feels more focused and efficient. I can directly see the impact of each code change. One click takes me to the exact error line, which makes debugging faster. Everything connects - code to data; code to tables; tables to the code. Switching between pipelines is easy, and features like auto-configured utility folders remove complexity. This feels like the way pipeline development should work.” —Chris Sharratt, Data Engineer, Rolls-Royce
Lakeflow Declarative Pipelines are now the unified way to build scalable, governed, and continuously optimized pipelines on Databricks - whether you’re working in code or visually through the Lakeflow Designer, a new no-code experience that enables data practitioners of any technical skill to build reliable data pipelines.
Lakeflow Jobs: Reliable orchestration for all workloads with unified observability
Databricks Workflows has long been trusted to orchestrate mission-critical workflows, with thousands of customers relying on our platform for pipelines to run over 110 million jobs every week. With the GA of Lakeflow, we’re evolving Workflows into Lakeflow Jobs, unifying this mature, native orchestrator with the rest of the data engineering stack.
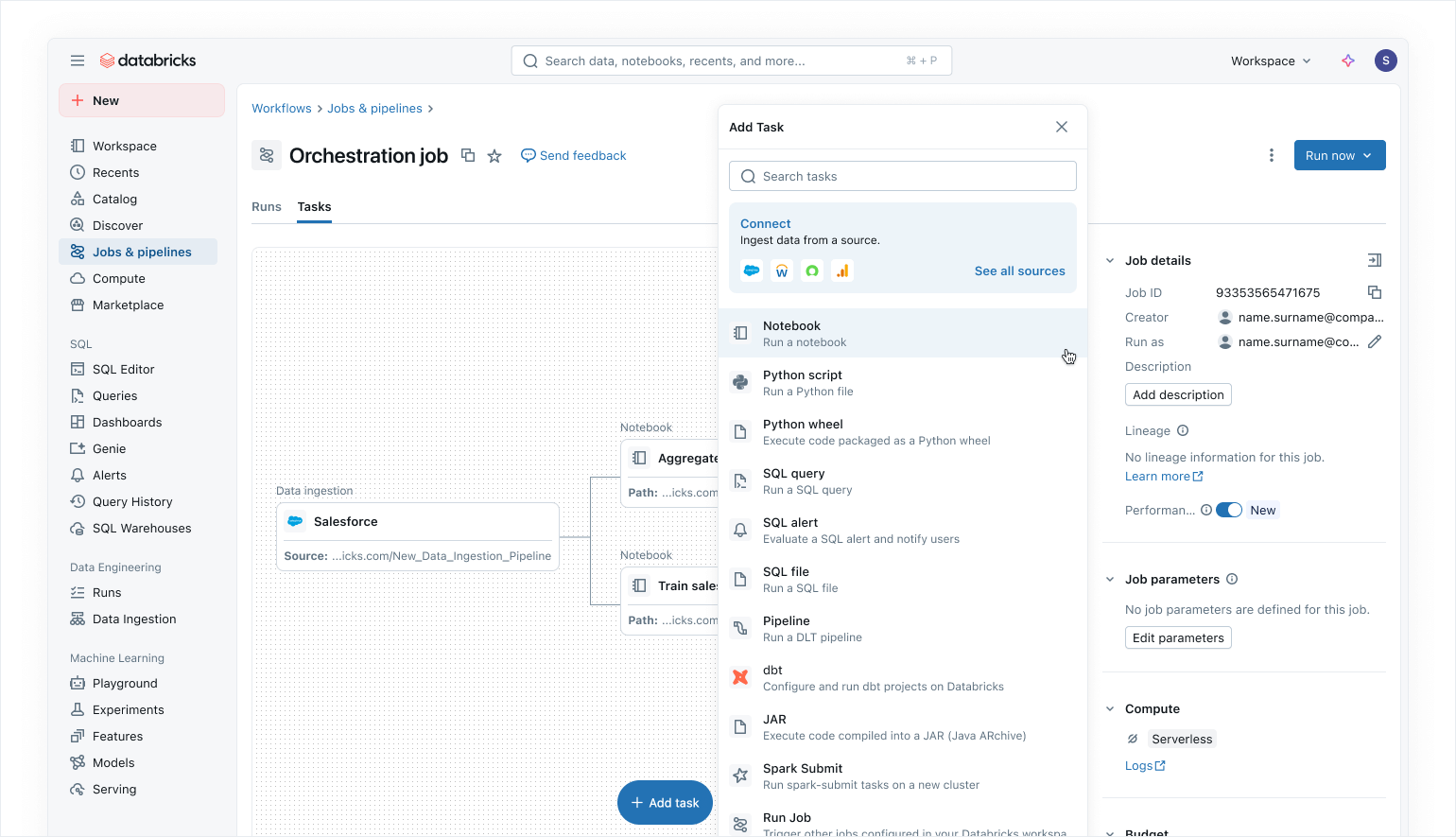
Lakeflow Jobs lets you orchestrate any process on the Data Intelligent Platform with a growing set of capabilities, including:
- Support for a comprehensive collection of task types for orchestrating flows that include Declarative Pipelines, notebooks, SQL queries, dbt transformations and even publishing AI/BI dashboards or to Power BI.
- Control flow features such as conditional execution, loops and parameter setting at the task or job level.
- Triggers for job runs beyond simple scheduling with file arrival triggers and the new table update triggers, which ensure jobs only run when new data is available.
- Serverless jobs that provides automatic optimizations for better performance and lower cost.
“With serverless Lakeflow Jobs, we’ve achieved a 3–5x improvement in latency. What used to take 10 minutes now takes just 2–3 minutes, significantly reducing processing times. This has enabled us to deliver faster feedback loops for players and coaches, ensuring they get the insights they need in near real time to make actionable decisions.” —Bryce Dugar, Data Engineering Manager, Cincinnati Reds
As part of Lakeflow's unification, Lakeflow Jobs brings end-to-end observability into every layer of the data lifecycle, from data ingestion to transformation and complex orchestration. A diverse toolset tailors to every monitoring need: visual monitoring tools provide search, status and tracking at a glance, debugging tools like query profiles help optimize performance, alerts and system tables help surface issues and offer historical insights and data quality expectations enforce rules and ensure high standards for your data pipeline needs.
Get started with Lakeflow
Lakeflow Connect, Lakeflow Declarative Pipelines and Lakeflow Jobs are all Generally Available for every Databricks customer today. Learn more about Lakeflow here and visit the official documentation to get started with Lakeflow for your next data engineering project.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.