Construindo com Databricks Document Intelligence e Lakeflow
Transforme o conhecimento corporativo bloqueado em inteligência consultável e confiável
- A maior parte do conhecimento empresarial é inacessível em documentos não estruturados, enquanto o processamento inteligente de documentos (IDP) atual é frequentemente frágil e não confiável
- Databricks Document Intelligence e Lakeflow permitem que engenheiros de dados criem e automatizem facilmente um fluxo de trabalho de IDP de ponta a ponta: ingerindo dados não estruturados, analisando-os com inteligência de IA fundamentada no contexto empresarial e, em seguida, orquestrando em escala, tudo dentro de uma plataforma governada
- As equipes de dados podem trazer documentos anteriormente ocultos para conjuntos de dados confiáveis e consultáveis que ajudam a desbloquear novos insights, fluxos de trabalho agentivos e valor para seus negócios
Apesar de décadas aperfeiçoando pipelines de dados estruturados, 80% do conhecimento corporativo permanece funcionalmente invisível, preso em PDFs, imagens e documentos do Office.
Tradicionalmente, o Processamento Inteligente de Documentos (IDP) tem sido um pesadelo fragmentado. Antes da era da IA Generativa, as organizações eram forçadas a depender de APIs desconectadas de NLP e visão computacional que estavam fora de suas plataformas de dados primárias. Esses fornecedores de OCR (reconhecimento óptico de caracteres) isolados ofereciam precisão limitada e careciam de protocolos formais de governança, criando atrito significativo. Para cumprir a promessa da IA Corporativa, precisamos de uma abordagem unificada que integre a inteligência de dados diretamente no ciclo de vida dos dados.
Hoje, estamos mostrando como engenheiros de dados podem alavancar Lakeflow, a solução unificada de engenharia de dados da Databricks, e Databricks Document Intelligence para desbloquear esses dados e transformá-los em inteligência de impacto nos negócios, construindo IDP autônomo em nível de produção em sua Databricks Platform.

Passo 1: Ingestão Segura com Lakeflow Connect
Documentos corporativos vivem em silos isolados, acessíveis apenas por meio de integrações de API frágeis e codificadas sob medida que quebram no momento em que uma pasta é renomeada. Lakeflow Connect, a solução da Databricks para ingerir dados no lakehouse, muda o jogo com conectores integrados para muitos aplicativos corporativos populares, bancos de dados e fontes de arquivos, incluindo SharePoint e Google Drive.
Esta solução oferece ingestão sem manutenção, removendo a necessidade de gerenciar fluxos OAuth complexos ou scripts Python personalizados. Os documentos chegam diretamente aos Volumes do Unity Catalog e tabelas, portanto, controle de acesso, linhagem e auditoria se aplicam assim que o arquivo está no lakehouse, e você pode reutilizar as mesmas políticas granulares baseadas em atributos nas quais você já confia para dados estruturados.
Você também obtém ingestão rápida e eficiente em escala graças às capacidades robustas do Lakeflow Connect, incluindo leituras e gravações incrementais que evitam re-pulls completos de grandes bibliotecas tanto para backfills em lote quanto para fluxos de documentos quase em tempo real quando combinados com streaming downstream.
Passo 2: Começando com Databricks Document Intelligence
Esses documentos corporativos carregam algumas das percepções mais valiosas de sua organização, mas são inerentemente confusos, variáveis e inconsistentes. Páginas digitalizadas, anotações manuscritas e tabelas aninhadas prendem suas percepções mais valiosas. Para corrigir isso, você não precisa apenas de mais uma ferramenta de extração de documentos; como observa a Forrester, você precisa de uma “evolução arquitetônica com foco em raciocínio”. Com essa abordagem, a Gartner prevê que a GenAI reduzirá a necessidade de modelos de documentos treinados personalizados em 70%.
Hoje, com o Databricks Document Intelligence, você pode trazer compreensão de documentos de ponta diretamente para seus dados. Suas equipes de engenharia de dados podem alavancar funções de IA projetadas para fins específicos que podem de forma confiável analisar, estruturar e enriquecer documentos complexos diretamente ao lado de seus pipelines de dados existentes, tudo perfeitamente governado pelo Unity Catalog.
- ai_parse_document (novo - GA): Esta função converte arquivos não estruturados em representações estruturadas usando o tipo de dados Variant. Ela lida nativamente com a complexidade de entrada que normalmente confunde os parsers tradicionais, como imagens digitalizadas, escrita manual e layouts variáveis, preservando a estrutura crítica do documento (por exemplo, tabelas aninhadas, seções e cabeçalhos) que a extração de texto plano perderia. Isso permite que você evolua esquemas ao longo do tempo sem quebrar seus pipelines. Downstream, você trata a saída VARIANT como uma representação bronze/prata flexível, projetando-a em colunas Delta em suas camadas prata/ouro usando SQL ou PySpark em Lakeflow Spark Declarative Pipelines.
Além da estrutura analisada, você pode encadear Funções de IA adicionais ajustadas para pesquisa:
- ai_extract (PuPr) para extrair insights estruturados como datas de vigência e expiração de contratos, contrapartes, totais de faturas, impostos, moeda e números de pedido de compra.
- ai_classify (PuPr) para rotear documentos por tipo (fatura, pedido de compra, SOW, NDA), urgência/risco ou unidade de negócios proprietária.
- ai_prep_search (novo - Beta) para dividir inteligentemente documentos em blocos para incorporação downstream de alta qualidade, preparando-os para casos de uso de recuperação ou pesquisa
Abaixo está um exemplo simples de encadeamento de ai_parse_document e ai_extract.
Nota: este exemplo mostra PySpark, mas você também pode usar SQL (veja a documentação).
Como essas são Funções de IA gerenciadas e integradas à Databricks Platform, o Document Intelligence pode combiná-las com seu contexto corporativo (metadados do catálogo, semântica de negócios, tabelas existentes) para potencializar fluxos de trabalho de agentes que raciocinam sobre seus dados com alta precisão, fundamentados no contexto do seu domínio corporativo.
Passo 3: Produção de Cargas de Trabalho de IDP em Escala
Depois que a ingestão e a análise estiverem funcionando em notebooks, você precisa produzir seu IDP: orquestrar ingestão, análise, enriquecimento e serviço. Mas você também quer monitorar SLAs, falhas e retentativas em CI/CD para garantir que os pipelines permaneçam saudáveis.
Com Lakeflow Jobs, o orquestrador nativo da Databricks, você pode transformar cargas de trabalho de IDP em pipelines robustos e automatizados com o mesmo sistema de orquestração que você usa para ETL, análise e ML. Ele fornece orquestração unificada para cada tarefa no DAG de IDP, para que você possa encadear notebooks, scripts Python, consultas SQL, pipelines, LLMs ou chamadas de agente em um único job e modelar o fluxo completo desde a ingestão do documento.
O Lakeflow Jobs também vem com controle de fluxo avançado integrado (incluindo condições if/else, for each, retentativas, etc.) e gatilhos (atualização de tabela, chegada de arquivo, contínuo, etc.). Isso facilita 1) reprocessar apenas partições com falha ou lotes de documentos específicos e 2) gerenciar jobs para se adequar a cronogramas específicos, gatilhos baseados em eventos ou modo contínuo para fluxos de documentos em tempo real.
Com a computação serverless do Lakeflow Jobs com observabilidade nativa, você também obtém escalonamento automático com picos no volume de documentos, ao mesmo tempo em que exibe monitoramento em tempo real, métricas e alertas para que você possa identificar gargalos e corrigir falhas sem precisar reexecutar tarefas bem-sucedidas.
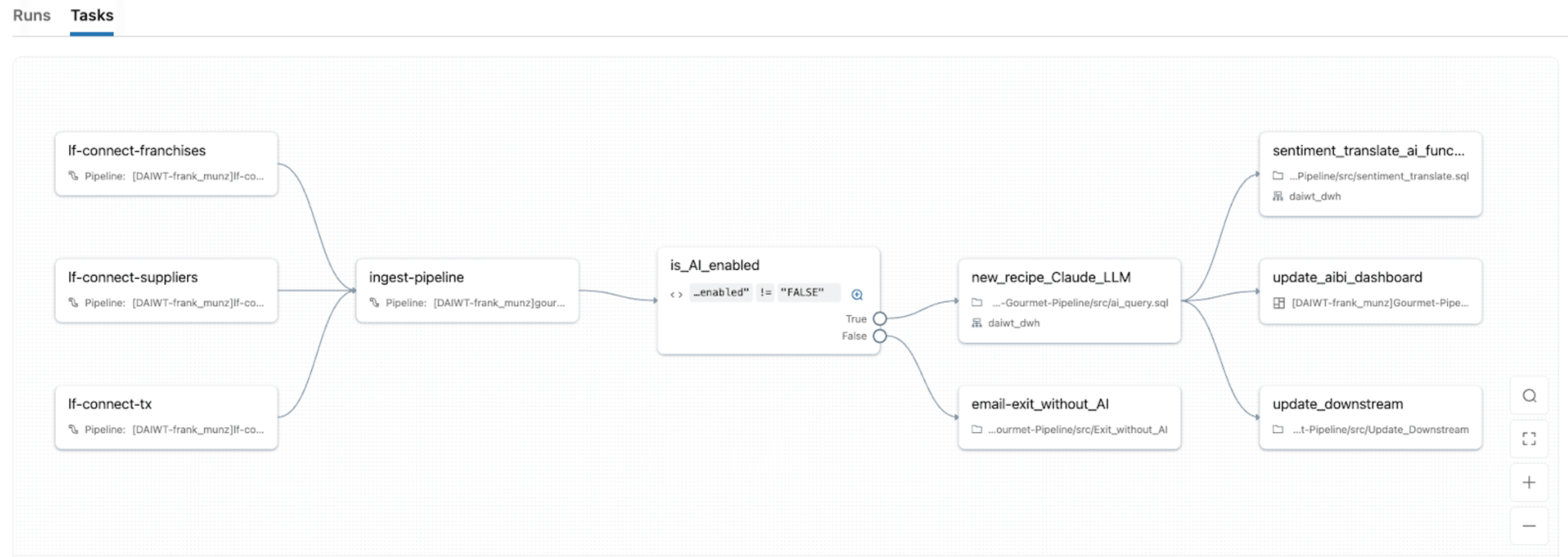
Fundamentando a IA no Contexto Corporativo
O IDP é mais valioso quando é apoiado pelo contexto corporativo: seus esquemas exclusivos, definições de negócios e semânticas personalizadas.
Unity Catalog
O Unity Catalog fornece governança e descoberta unificadas em dados estruturados, arquivos não estruturados, modelos de ML e métricas de negócios em qualquer nuvem. Para IDP, isso significa:
- Um local centralizado para definir políticas de acesso, linhagem e auditoria tanto para documentos brutos quanto para tabelas estruturadas derivadas
- Suporte para formatos abertos (Delta, Apache Iceberg, Hudi, Parquet) para que você não fique preso a uma representação proprietária de documentos
- Semântica de negócios e metadados em nível de catálogo que os agentes podem usar para nomear e interpretar consistentemente entidades como "Fornecedor", "Cliente" ou "Valor do Contrato".
Inteligência de Documentos
Inteligência de Documentos usa esse contexto para construir agentes de IA de produção que sabem quais tabelas, ferramentas e modelos usar para uma determinada tarefa de IDP, são governados de ponta a ponta para que nunca acessem mais do que deveriam, e melhoram continuamente por meio de pontuação de qualidade baseada em LLM, benchmarks específicos de tarefas e loops de aprendizado. Para desenvolvedores, Databricks fornece APIs e SDKs para que você possa definir esses agentes como código e integrá-los em seus pipelines de CI/CD existentes, assim como qualquer outro ativo de dados ou ML.
Melhores Práticas para a Pilha Moderna de IDP
Para ir de um piloto a uma plataforma, tenha em mente estas melhores práticas:
- Enriquecimento de Dados: Não extraia apenas um "Nome do Fornecedor". Junte-o com seus Dados Mestres internos ou fontes de terceiros (como Dun & Bradstreet) para fornecer contexto de negócios completo.
- Excelência Operacional: Use Service Principals para Jobs do Lakeflow para garantir a estabilidade do pipeline.
- Monitoramento: Use o Monitoramento do Lakehouse para rastrear a deriva do modelo e a precisão da extração ao longo do tempo.
O Caminho para a Inteligência de Dados Moderna
Com Databricks, você pode gerenciar o ciclo de vida completo do Processamento Inteligente de Documentos em uma plataforma de dados moderna. A combinação do Lakeflow e funções de IA permite transformar dados não estruturados e ocultos em conjuntos de dados confiáveis e consultáveis, e executar pipelines de documentos observáveis perfeitamente ao lado de seu ETL e ML principal.
Agora que cobrimos o valor estratégico da inteligência de documentos autônoma, é hora de construí-la. Confira nosso post complementar, Do PDF às Insights, para um guia técnico passo a passo sobre como implantar essa arquitetura exata usando Databricks.
Você também pode explorar a documentação de Inteligência de Documentos e Lakeflow para começar a construir seu primeiro pipeline de IDP hoje mesmo!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.