Por que seus Agentes não conseguem ler Documentos Corporativos — e Como Resolver
Apresentando o Document Intelligence no Databricks
- Agentes de fronteira ainda pontuam abaixo de 50% em tarefas reais com documentos corporativos. O gargalo não é o raciocínio, é a leitura.\r\n* O processamento de documentos é o teto de precisão para cada fluxo de trabalho de agente.\r\n* Estamos anunciando o Document Intelligence para fechar essa lacuna: oferecendo precisão baseada em pesquisa, escala empresarial e simplicidade de ponta a ponta.
A inteligência de negócios mais importante não está apenas armazenada em data warehouses — ela reside nos milhões de documentos que impulsionam os fluxos de trabalho empresariais essenciais todos os dias: contratos, reivindicações, faturas e muito mais. Por uma década, o Processamento Inteligente de Documentos (IDP) foi tratado como um problema restrito de automação de back-office. Na era dos agentes, as apostas são fundamentalmente diferentes: o IDP é a base crítica que determina se seus agentes tomam decisões em que você realmente confiaria.
Considere o processamento de sinistros de seguro. No papel, é um fluxo de trabalho de agente ideal: ingerir um sinistro, extrair detalhes, sinalizar anomalias e roteá-lo. Os agentes de ponta de hoje lidam com o raciocínio facilmente. Onde eles falham é na leitura dos documentos: PDFs digitalizados com layouts inconsistentes, tabelas aninhadas, notas manuscritas e variação de formato entre cada fornecedor. Um "$10.000" é alucinado como "$3.000", o agente toma uma decisão desinformada e o valor errado é pago silenciosamente.
Estamos vendo esse padrão em todos os setores: os agentes raciocinam bem sobre texto limpo, mas falham quando confrontados com documentos empresariais reais. Há alguns meses, a Databricks AI Research lançou OfficeQA, um benchmark baseado em fluxos de trabalho de documentos empresariais do mundo real. Descobrimos que mesmo agentes de ponta altamente capazes obtiveram menos de 50% de precisão em tarefas de raciocínio sobre documentos. O gargalo não era o raciocínio — era a leitura.
É por isso que estamos entusiasmados em anunciar o Document Intelligence, construído sobre três pilares principais: precisão baseada em pesquisa, escala empresarial e simplicidade de ponta a ponta.
Na Intercontinental Exchange, processamos milhões de documentos financeiros complexos e altamente variáveis todos os meses. O Document Intelligence nos ajuda a transformar essa complexidade em inteligência de mercado estruturada, permitindo-nos mover mais rápido, entregar maior valor aos nossos clientes e desbloquear fluxos de trabalho de agentes que aceleram a análise e a tomada de decisões em escala." —Anand Pradhan, CTO e Head de IA, Mortgage Data na Intercontinental Exchange (NYSE)
Melhorando a qualidade do agente em documentos empresariais do mundo real
O processamento de documentos é o limite de precisão para cada agente. Para fazer isso corretamente, a equipe de Pesquisa de IA da Databricks se propôs a construir sistemas especializados projetados para a realidade complexa com a qual as empresas realmente lidam: layouts inconsistentes, tabelas aninhadas, imagens e caligrafia.
Esta pesquisa impulsiona um conjunto de Funções de IA encadeáveis que dividem o processamento de documentos em etapas composíveis: ai_parse_document (agora geralmente disponível) converte digitalizações brutas em texto estruturado enriquecido com layout, enquanto, a jusante, ai_classify roteia documentos corretamente, e ai_extract extrai os principais insights estruturados que mais importam. Juntos, eles formam um pipeline de inteligência de documentos que você pode montar com facilidade: analise uma vez, depois classifique, extraia e reextraia sem reprocessar o documento original.
Então, um melhor processamento de documentos realmente torna os agentes mais precisos? Quando avaliamos documentos de títulos do tesouro do mundo real através do OfficeQA, o pré-processamento com ai_parse_document proporcionou um ganho médio de desempenho de 16% em todos os frameworks de agentes que testamos. O mecanismo de raciocínio do agente não mudou em nada, mas a camada de dados do documento abaixo dele sim.
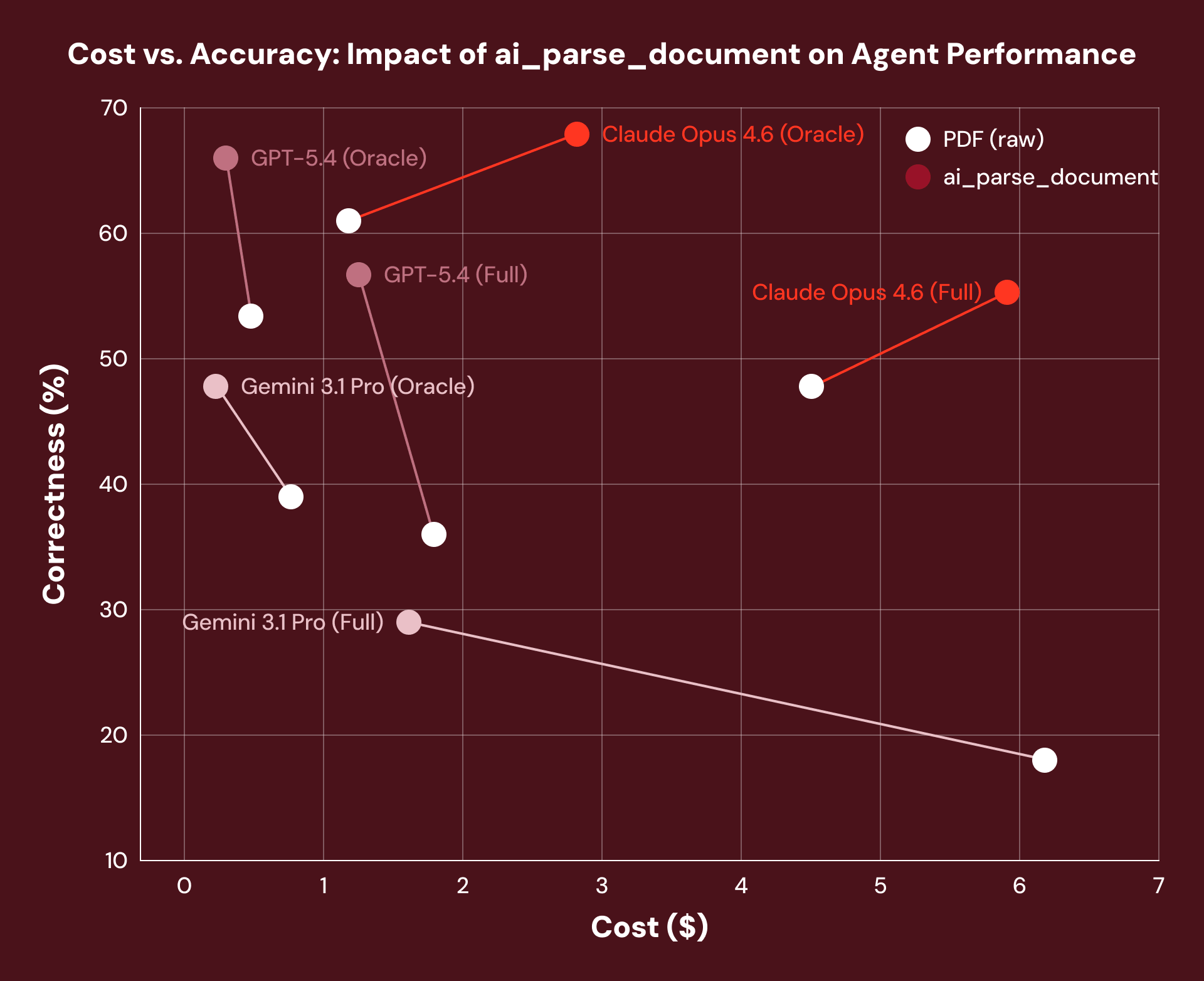
Nota: Observamos um aumento nos custos do Claude Opus 4.6 devido à tendência do modelo de recuperar mais tokens quando fornecido o texto de layout estruturado de um documento.
É exatamente por isso que construímos o Document Intelligence como a base dos seus fluxos de trabalho de agentes: os ganhos de qualidade e custo do processamento de documentos se multiplicam em tudo o que é construído sobre ele.
Com o Document Intelligence, estamos estabelecendo as bases para um pipeline de processamento inteligente de documentos que desbloqueia insights estruturados essenciais de milhões de PDFs técnicos não estruturados a cada ano, provenientes de milhares de organizações e abrangendo formatos altamente inconsistentes. —Graham Lammers, Diretor Executivo de Data Intelligence, Accuris
Desbloqueando a inteligência de documentos em escala empresarial
Mesmo quando a qualidade é resolvida, o cemitério do IDP empresarial está cheio de projetos que acertaram o piloto, mas não conseguiram sobreviver à economia da produção. Isso se deve a custos que chegam a seis dígitos e trabalhos em lote que levam dias em vez de horas.
Projetamos o Document Intelligence para a economia em escala de produção desde o início, não como um adendo. Como as Funções de IA como ai_parse_document são especializadas em pesquisa, elas alcançam precisão de ponta sem a sobrecarga computacional de modelos de uso geral.
Em várias soluções, avaliamos a precisão e o custo em tarefas de extração de documentos estruturados, identificando entidades-chave de faturas empresariais, contratos, notas médicas e registros financeiros. O Document Intelligence consistentemente alcançou a maior precisão com um custo 5 a 7 vezes menor do que pipelines comparáveis.

Nota: As ofertas marcadas (parse + extract) usam uma arquitetura de pipeline de duas etapas — analisam uma vez em uma camada silver reutilizável, depois extraem e reextraem sem reanalisar. As ofertas baseadas em VLM reprocessam o documento completo em cada chamada de extração.
É importante ressaltar que, para suportar essa escala, cada Função de IA é executada em uma infraestrutura de lote serverless construída para cargas de trabalho de alto volume: a mesma chamada SQL de uma linha que processa 100 faturas processa 100.000 sem reestruturar seu pipeline.
Com o Document Intelligence, alcançamos a mesma extração de entidades de alta qualidade com um custo quase 90% menor em semanas. Esse avanço de preço-desempenho agora impulsiona nossos pipelines de produção, permitindo-nos expandir para novas áreas de doenças mais rapidamente, processar centenas de milhões de notas clínicas eficientemente e entregar insights aos nossos clientes em escala. —Jerry Dennany, CTO Loopback Analytics
É importante ressaltar que, para processamento em escala, cada Função de IA é executada em uma infraestrutura de lote serverless construída para cargas de trabalho de alto volume: a mesma chamada SQL de uma linha que processa 100 faturas processa 100.000 sem reestruturar seu pipeline.
De pipelines fragmentados a um fluxo de trabalho unificado
Para a maioria das empresas hoje, a inteligência de documentos não é uma capacidade de plataforma. É uma coleção de pipelines pontuais. Para apenas um único caso de uso, uma equipe une um serviço de OCR, anexa uma API de extração distinta e conecta um modelo de classificação de outro provedor. Em pouco tempo, eles estão gerenciando de três a cinco APIs desconectadas, mantidas juntas por um código de cola personalizado frágil — um pipeline que é frágil, caro de manter e quase impossível de depurar quando quebra às 3 da manhã. E quando outra equipe precisa processar um tipo de documento diferente, não há nada reutilizável para construir. Eles começam do zero.
Este é o ciclo que mantém a inteligência de documentos presa como uma série de projetos pontuais, em vez de uma capacidade em toda a empresa. O Document Intelligence quebra esse ciclo. Em vez de unir serviços desconectados, cada etapa é executada nativamente dentro da sua camada existente de orquestração e governança da Databricks:
- Ingira documentos (por exemplo, do SharePoint) usando Lakeflow Connect.
- Orquestre o pipeline completo usando Lakeflow Jobs ou Spark Declarative Pipelines, com tratamento de erros integrado, observabilidade e tratamento automático de novos documentos.
- Governe a linhagem de ponta a ponta, segurança e controles de acesso de seus pipelines e dados — do documento bruto à saída da tabela estruturada — com o Unity Catalog.
- Construa agentes na nova camada de dados de documentos enriquecidos usando a plataforma Agent Bricks.
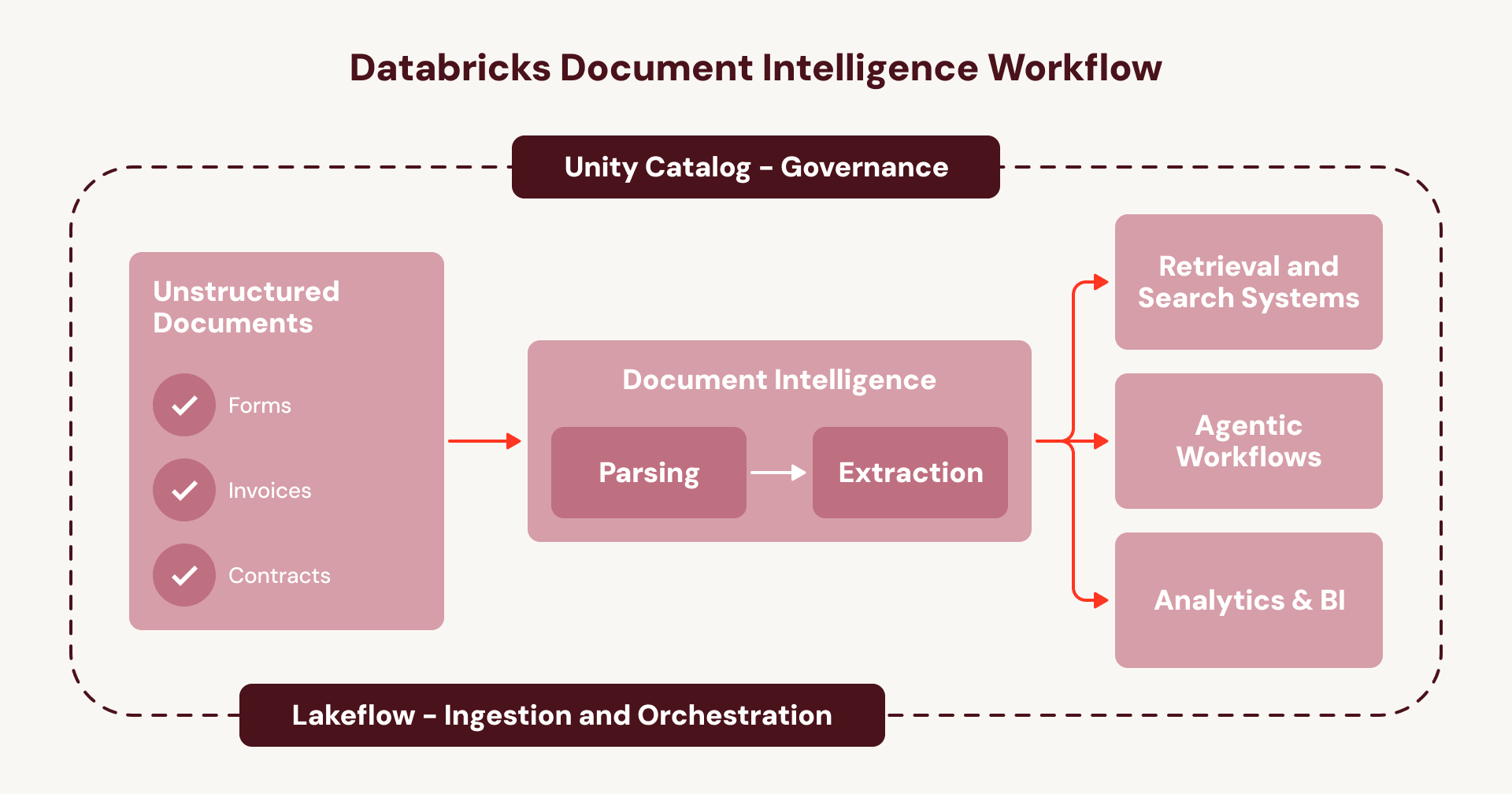
Para as empresas, isso significa que a inteligência de documentos é executada em um fluxo de trabalho unificado e governado, em vez de uma teia de serviços opacos e fragmentados — um manual repetível para escalar casos de uso de agentes em todos os seus documentos.
Com a Databricks, passamos de processos manuais e fragmentados para inteligência automatizada e escalável. O que costumava levar semanas, agora fazemos em dias — desbloqueando insights que nossos clientes não conseguem em nenhum outro lugar. —Tony Qui, Líder Global de Inovação da EY-Parthenon, Estratégia e Transações
Seus agentes são tão bons quanto sua camada de processamento de documentos
A promessa dos agentes empresariais reside em uma pergunta que a maioria das organizações ainda não respondeu: seus agentes podem realmente entender os milhões de documentos em sua empresa?
É por isso que estamos entusiasmados em anunciar o Document Intelligence para preencher essa lacuna: preciso o suficiente para fluxos de trabalho críticos de negócios, governado de ponta a ponta para que sua equipe de conformidade não precise procurar dados em vários fornecedores, e construído para escalar do seu primeiro piloto à produção sem alterar uma linha de código.
Seus documentos são a fonte mais rica de inteligência em sua empresa. É hora de seus agentes poderem lê-los.
- Leia nosso blog de instruções sobre como construir com Document Intelligence e Lakeflow.
- Inscreva-se para o Teste Databricks.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.