Why your agents can't read enterprise documents — and how to fix it
Introducing Document Intelligence on Databricks
by Archika Dogra, Sergei Tsarev and Erich Elsen
- Frontier agents still score below 50% on real enterprise document tasks. The bottleneck isn't reasoning, it's reading.
- Document processing is the accuracy ceiling for every agentic workflow.
- We’re announcing Document Intelligence to close this gap: delivering research-backed accuracy, enterprise scale, and end-to-end simplicity.
The most important business intelligence isn't just stored in warehouses — it lives in the millions of documents that power core enterprise workflows every day: contracts, claims, invoices and more. For a decade, Intelligent Document Processing (IDP) was treated as a narrow, back-office automation problem. In the agentic era, the stakes are fundamentally different: IDP is the critical foundation that determines whether your agents make decisions you'd actually trust.
Take insurance claims processing. On paper, it's an ideal agentic workflow: ingest a claim, extract details, flag anomalies, and route it. Today's frontier agents handle the reasoning easily. Where they break down is reading the documents: scanned PDFs with inconsistent layouts, nested tables, handwritten notes, and format variation across every vendor. A "$10,000" gets hallucinated as "$3,000," the agent makes a misinformed decision, and the wrong amount gets silently paid out.
We're seeing this pattern across the board: agents reason well over clean text but fall apart when faced with real enterprise documents. A few months ago, Databricks AI Research released OfficeQA, a benchmark based on real-world enterprise document workflows. We found that even highly capable frontier agents scored below 50% accuracy on document reasoning tasks. The bottleneck wasn't reasoning — it was reading.
That's why we’re excited to announce Document Intelligence, built on three core pillars: research-backed accuracy, enterprise scale, and end-to-end simplicity.
At Intercontinental Exchange, we process millions of complex, highly variable financial documents every month. Document Intelligence helps us turn that complexity into structured market intelligence, enabling us to move faster, deliver greater value to our clients, and unlock agentic workflows that accelerate analysis and decision-making at scale." —Anand Pradhan, CTO and Head of AI, Mortgage Data at Intercontinental Exchange (NYSE)
Improving agent quality on real-world, enterprise documents
Document processing is the accuracy ceiling for every agent. To get this right, the Databricks AI Research team set out to build specialized systems designed for the messy reality of what enterprises actually deal with: inconsistent layouts, nested tables, images, and handwriting.
This research powers a set of chainable AI Functions that break document processing into composable steps: ai_parse_document (now Generally Available) converts raw scans into layout-enriched structured text, while downstream, ai_classify routes documents correctly, and ai_extract pulls the key structured insights that matter most. Together, they form a document intelligence pipeline you can assemble with ease: parse once, then classify, extract, and re-extract without reprocessing the original document.
So does better document processing actually make agents more accurate? When we benchmarked real-world treasury bond documents through OfficeQA, pre-processing with ai_parse_document delivered a 16% average performance gain across every agent framework we tested. The agent's reasoning harness didn't change at all, but the document data layer beneath it did.
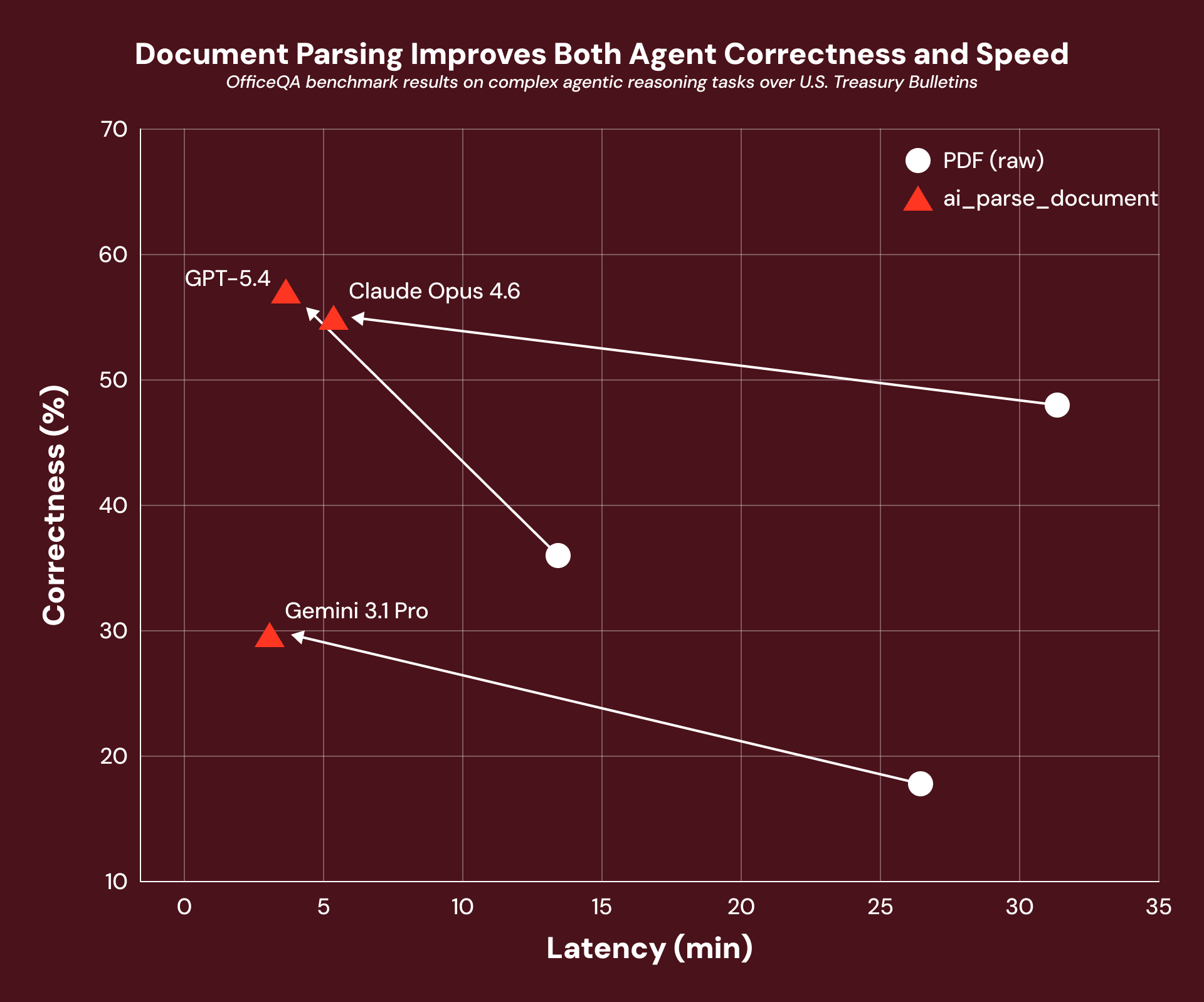
That’s exactly why we built Document Intelligence as the foundation of your agentic workflows: the quality and performance gains compound through everything built on top of it.
With Document Intelligence, we’re laying the groundwork for an intelligent document processing pipeline that unlocks key structured insights from millions of unstructured technical PDFs each year, sourced from thousands of organizations and spanning highly inconsistent formats. —Graham Lammers, Executive Director of Data Intelligence, Accuris
Unlocking document intelligence at enterprise scale
Even when quality is solved, the graveyard of enterprise IDP is full of projects that nailed the pilot but couldn't survive the economics of production. This is thanks to costs that balloon to six figures and batch jobs that take days instead of hours.
We designed Document Intelligence for production-scale economics from the start, not as an afterthought. Because AI Functions like ai_parse_document are research-specialized, they achieve state-of-the-art accuracy without the computational overhead of general-purpose models.
Across various solutions, we benchmarked accuracy and cost on structured document extraction tasks identifying key entities from enterprise invoices, contracts, medical notes, and financial filings. Document Intelligence consistently achieved the highest accuracy at 5–7x lower cost than comparable pipelines.

Note: Offerings marked (parse + extract) use a two-step pipeline architecture — parse once into a reusable silver layer, then extract and re-extract without re-parsing. VLM-based offerings reprocess the full document on every extraction call.
Importantly, to support this scale, every AI Function runs on serverless batch infrastructure built for high-volume workloads: the same one-line SQL call that processes 100 invoices processes 100,000 without rearchitecting your pipeline.
With Document Intelligence, we achieved the same high-quality entity extraction at nearly 90% lower cost within weeks. That price-performance breakthrough now powers our production pipelines, enabling us to expand into new disease areas faster, process hundreds of millions of clinical notes efficiently, and deliver insights to our customers at scale. —Jerry Dennany, CTO Loopback Analytics
Importantly, for at-scale processing, every AI Function runs on serverless batch infrastructure built for high-volume workloads: the same one-line SQL call that processes 100 invoices processes 100,000 without rearchitecting your pipeline.
From fragmented pipelines to a unified workflow
For most enterprises today, document intelligence isn't a platform capability. It's a collection of one-off pipelines. For just a single use case, a team stitches together an OCR service, bolts on a distinct extraction API, and wires in a classification model from yet another provider. Before long, they're managing three to five disconnected APIs held together by fragile custom glue code — a pipeline that's brittle, expensive to maintain, and nearly impossible to debug when it breaks at 3 AM. And when another team needs to process a different document type, there's nothing reusable to build on. They start from scratch.
This is the cycle that keeps document intelligence trapped as a series of one-off projects instead of an enterprise-wide capability. Document Intelligence breaks that cycle. Instead of stitching together disconnected services, every step runs natively inside your existing Databricks orchestration and governance layer:
- Ingest documents (e.g., from SharePoint) using Lakeflow Connect.
- Orchestrate the full pipeline using Lakeflow Jobs or Spark Declarative Pipelines, with built-in error handling, observability, and automatic handling of new documents.
- Govern the end-to-end lineage, security, and access controls of your pipelines and data—from the raw document to the structured table output—with Unity Catalog.
- Build agents on the new, enriched document data layer using the Agent Bricks platform.
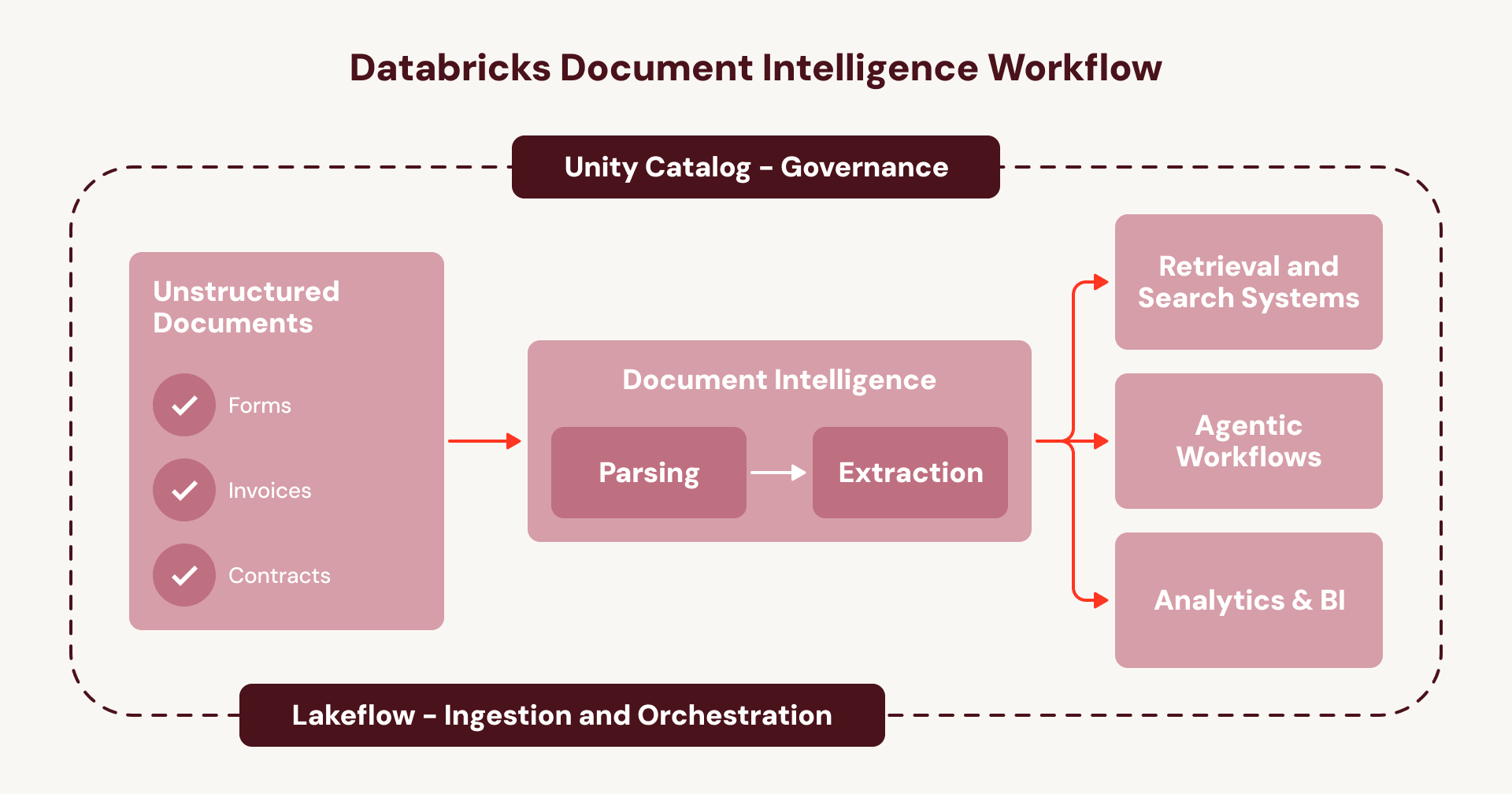
For enterprises, this means document intelligence runs on one unified and governed workflow instead of a web of opaque, fragmented services- a repeatable playbook to scale agentic use cases across all of your documents.
With Databricks, we’ve gone from manual, fragmented processes to automated, scalable intelligence. What used to take weeks, we now do in days - unlocking insights our clients can’t get anywhere else. —Tony Qui, EY-Parthenon Global Innovation Leader, Strategy and Transactions
Your agents are only as good as your document processing layer
The promise of enterprise agents rests on a question most organizations haven't yet answered: can your agents actually understand the millions of documents in your business?
That’s why we’re excited to announce Document Intelligence to close that gap: accurate enough for business-critical workflows, governed end to end so your compliance team isn't chasing data across vendors, and built to scale from your first pilot to production without changing a line of code.
Your documents are the richest source of intelligence in your enterprise. It's time your agents could read them.
- Read our how-to blog on building with Document Intelligence and Lakeflow.
- Sign up for the Databricks Trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.