Building with Databricks Document Intelligence and Lakeflow
Turn locked enterprise knowledge into queryable, trusted intelligence
by Giselle Goicochea and Joanna Zouhour
- Most enterprise knowledge is inaccessible in unstructured documents, while current intelligent document processing (IDP) is often brittle and unreliable
- Databricks Document Intelligence and Lakeflow enable data engineers to easily build and automate an end-to-end IDP workflow: ingesting unstructured data, parsing it with AI intelligence grounded in enterprise context, and then orchestrating at scale, all within a governed platform
- Data teams can surface previously hidden documents into trusted, queryable datasets that help unlock new insights, agentic workflows, and value for their business
Despite decades of perfecting structured data pipelines, 80% of enterprise knowledge remains functionally invisible, trapped in PDFs, images, and office documents.
Traditionally, Intelligent Document Processing (IDP) has been a fragmented nightmare. Before the era of Generative AI, organizations were forced to rely on disconnected NLP and computer vision APIs that were outside of their primary data platforms. These siloed OCR (optical character recognition) vendors offered limited accuracy and lacked formal governance protocols, creating significant friction. To deliver on the promise of Enterprise AI, we need a unified approach that integrates data intelligence directly into the data lifecycle.
Today, we’re showing how data engineers can leverage Lakeflow, Databricks’ unified data engineering solution, and Databricks Document Intelligence to unlock that data and turn it into business-impacting intelligence by building production-grade autonomous IDP in their Databricks Platform.

Step 1: Secure Ingestion with Lakeflow Connect
Enterprise documents live in siloed graveyards, accessible only through fragile, custom-coded API integrations that break the moment a folder is renamed. Lakeflow Connect, Databricks' solution for ingesting data into the lakehouse, changes the game with built-in connectors for many popular enterprise applications, databases, and file sources including SharePoint and Google Drive.
This solution offers zero-maintenance ingestion by removing the need to manage complex OAuth flows or custom Python scripts. Documents land directly in Unity Catalog Volumes and tables, so access control, lineage, and auditing apply as soon as the file is in the lakehouse, and you can reuse the same fine‑grained, attribute‑based policies you already rely on for structured data.
You also get fast and efficient ingestion at scale thanks to Lakeflow Connect’s robust capabilities, including incremental reads and writes which avoids full re‑pulls of large libraries for both batch backfills and near‑real‑time document flows when combined with streaming downstream.
Step 2: Getting started with Databricks Document Intelligence
These enterprise documents carry some of your organization’s most valuable insights but are inherently messy, variable and inconsistent. Scanned pages, handwritten notes and nested tables trap your most valuable insights. To fix this, you don’t just need another document extraction tool; as Forrester notes, you need a “reasoning-first architectural evolution.” With this approach, Gartner predicts GenAI will reduce the need for custom-trained document models by 70%.
Today, with Databricks Document Intelligence, you can bring state-of-the-art document understanding directly to your data. Your data engineering teams can leverage purpose-built AI functions that can reliably parse, structure, and enrich complex documents right alongside your existing data pipelines, all seamlessly governed by Unity Catalog.
- ai_parse_document (new - GA): This function converts unstructured files into structured representations using the Variant data type. It natively handles input complexity that typically trips up traditional parsers, such as scanned images, handwriting, and variable layouts, while preserving critical document structure (e.g., nested tables, sections, and headers) that flat text extraction would lose. This allows you to evolve schemas over time without breaking your pipelines. Downstream, you treat the VARIANT output as a flexible bronze/silver representation, projecting it into Delta columns in your silver/gold layers using SQL or PySpark in Lakeflow Spark Declarative Pipelines.
On top of the parsed structure, you can chain additional research-tuned AI Functions:
- ai_extract (PuPr) to pull structured insights such as contract effective and expiration dates, counterparties, invoice totals, taxes, currency, and PO numbers.
- ai_classify (PuPr) to route documents by type (invoice, PO, SOW, NDA), urgency/risk, or owning business unit.
- ai_prep_search (new - Beta) to intelligently divide documents into chunks for high-quality downstream embedding, preparing them for retrieval or search use cases
Below is a simple example of chaining ai_parse_document and ai_extract together.
Note: this example shows PySpark, but you can also use SQL (see documentation).
Because these are managed AI Functions integrated into the Databricks Platform, Document Intelligence can combine them with your enterprise context (catalog metadata, business semantics, existing tables) to power agentic workflows that reason over your data with high accuracy, grounded in your enterprise domain context.
Step 3: Productionizing IDP Workloads at Scale
Once you have ingestion and parsing working in notebooks, you need to productionize your IDP: orchestrate ingestion, parsing, enrichment, and serving. But you also want to monitor SLAs, failures, and retries in CI/CD to ensure pipelines remain healthy.
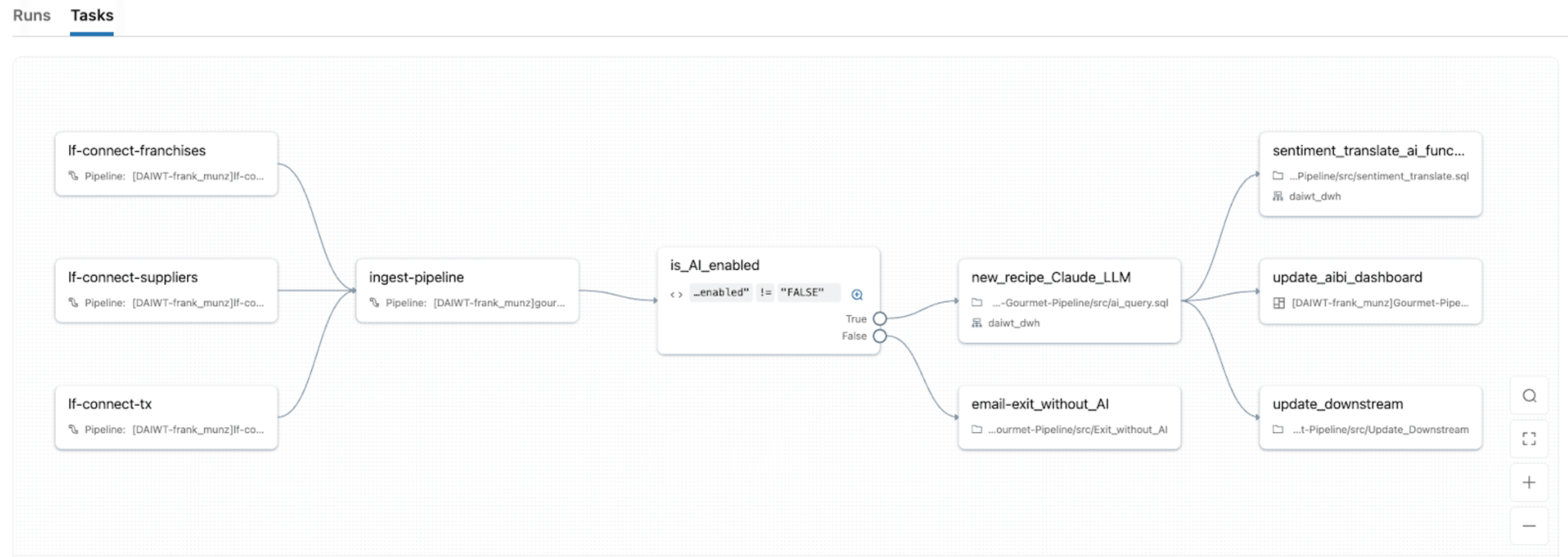
With Lakeflow Jobs, Databricks’ native orchestrator, you can turn IDP workloads into robust, automated pipelines with the same orchestration system you use for ETL, analytics, and ML. It provides unified orchestration for every task in the IDP DAG, so you can chain notebooks, Python scripts, SQL queries, pipelines, LLMs, or agent calls in a single job and model the full flow from document ingestion.
Lakeflow Jobs also comes with built-in advanced control flow (including if/else conditions, for each, retries, etc.) and triggers (table update, file arrival, continuous, etc.). This makes it easy to 1) re‑process only failed partitions or specific document batches and 2) manage jobs to fit specific schedules, event‑based triggers, or continuous mode for real‑time document streams.
With Lakeflow Jobs’ serverless compute with native observability, you also get automatic scaling with spikes in document volume while surfacing real‑time monitoring, metrics, and alerts so you can pinpoint bottlenecks and repair failures without needing to re-run successful tasks.
Grounding AI in Enterprise Context
IDP is most valuable when it is backed by enterprise context: your unique schemas, business definitions, and custom semantics.
Unity Catalog
Unity Catalog provides unified governance and discovery across structured data, unstructured files, ML models, and business metrics on any cloud. For IDP, that means:
- A single place to define access policies, lineage, and auditing for both raw documents and derived structured tables
- Support for open formats (Delta, Apache Iceberg, Hudi, Parquet) so you aren’t locked into a proprietary document representation
- Business semantics and catalog‑level metadata that agents can use to consistently name and interpret entities such as “Vendor,” “Customer,” or “Contract Value.”
Document Intelligence
Document Intelligence uses this context to build production AI agents that know which tables, tools, and models to use for a given IDP task, are governed end‑to‑end so they never access more than they should, and continuously improve via LLM‑based quality scoring, task‑specific benchmarks, and learning loops. For developers, Databricks provides APIs and SDKs so you can define these agents as code and integrate them into your existing CI/CD pipelines, just like any other data or ML asset.
Best Practices for the Modern IDP Stack
To move from pilot to platform, keep these best practices in mind:
- Data Enrichment: Don’t just extract a "Vendor Name." Join it with your internal Master Data or third-party sources (like Dun & Bradstreet) to provide full business context.
- Operational Excellence: Use Service Principals for Lakeflow Jobs to ensure pipeline stability.
- Monitoring: Use Lakehouse Monitoring to track model drift and extraction accuracy over time.
The Path to Modern Data Intelligence
With Databricks, you can own the full lifecycle of Intelligent Document Processing on a modern data platform. Combining Lakeflow and AI functions lets you turn unstructured, hidden data into trusted, queryable datasets and seamlessly run observable document pipelines alongside your core ETL and ML.
Now that we’ve covered the strategic value of autonomous document intelligence, it’s time to build it. Check out our companion post, From PDF to Insights, for a step-by-step technical walkthrough on deploying this exact architecture using Databricks.
You can also explore the Document Intelligence and Lakeflow documentation to start building your first IDP pipeline today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.