Apresentando o OfficeQA: um benchmark para raciocínio fundamentado de ponta a ponta
Existem vários benchmarks que exploram a fronteira das capacidades dos agentes (GDPval, Humanity's Last Exam (HLE), ARC-AGI-2), mas não os consideramos representativos dos tipos de tarefas que são importantes para nossos clientes. Para preencher essa lacuna, criamos e estamos disponibilizando como código aberto o OfficeQA, um benchmark que simula tarefas de valor econômico realizadas pelos clientes corporativos da Databricks. Focamos em uma tarefa corporativa muito comum, mas desafiadora: o Raciocínio Fundamentado, que envolve responder a perguntas com base em datasets proprietários e complexos que incluem documentos não estruturados e dados tabulares.
Apesar de os modelos de ponta terem um bom desempenho em questões no estilo de olimpíadas, percebemos que eles ainda têm dificuldade com essas tarefas economicamente importantes. Sem acesso ao corpus, eles respondem corretamente a ~2% das perguntas. Quando recebem um corpus de documentos PDF, os agentes atingem uma precisão de <45% em todas as perguntas e de <25% em um subconjunto das perguntas mais difíceis.
Neste post, primeiro descrevemos o OfficeQA e nossos princípios de design. Depois, avaliamos as soluções de agentes de AI existentes — incluindo um Agente GPT-5.1 usando a API File Search & Retrieval da OpenAI e um Agente Claude Opus 4.5 usando o SDK de Agente da Claude — no benchmark. Experimentamos usar o ai_parse_document da Databricks para analisar o corpus de PDFs do OfficeQA e descobrimos que isso proporciona ganhos significativos. Mesmo com essas melhorias, vemos que todos os sistemas ainda ficam abaixo de 70% de precisão no benchmark completo e atingem apenas cerca de 40% de precisão na divisão mais difícil, o que indica que há bastante espaço para melhorias nesta tarefa. Por fim, anunciamos a Databricks Grounded Reasoning Cup, uma competição na primavera de 2026 em que agentes de AI competirão com equipes humanas para impulsionar a inovação nesta área.
Desiderata do Dataset
Tivemos vários objetivos chave ao construir o OfficeQA. Primeiro, as perguntas devem ser desafiadoras porque exigem um trabalho cuidadoso — precisão, diligência e tempo — não porque exigem conhecimento de nível de doutorado. Segundo, cada pergunta deve ter uma única resposta claramente correta que possa ser verificada automaticamente em relação à verdade fundamental, para que os sistemas possam ser treinados e avaliados sem nenhum julgamento humano ou de LLM. Finalmente, e mais importante, o benchmark deve refletir com precisão os problemas comuns que os clientes corporativos enfrentam.
Destilamos os problemas comuns das empresas em três componentes principais:
- Complexidade do documento: As empresas têm grandes acervos de materiais de origem — como digitalizações, PDFs ou fotografias — que costumam conter uma quantidade substancial de dados numéricos ou tabulares.
- Recuperação e agregação de informações: Eles precisam pesquisar, extrair e combinar informações de maneira eficiente em vários desses documentos.
- Raciocínio analítico e resposta a perguntas: Eles exigem sistemas capazes de responder a perguntas e realizar análises fundamentadas nesses documentos, às vezes envolvendo cálculos ou conhecimento externo.
Também observamos que muitas empresas exigem precisão extremamente alta ao realizar essas tarefas. Chegar perto não é o suficiente. Errar por um no número de um produto ou de uma fatura pode ter resultados catastróficos subsequentes. Prever a receita e errar em 5% pode levar a decisões de negócios drasticamente incorretas.
Os benchmarks existentes não atendem às nossas necessidades: | ||
|
| Exemplo |
GDPVal | As tarefas são exemplos claros de tarefas economicamente valiosas, mas a maioria não testa especificamente o que é importante para nossos clientes. Recomenda-se a avaliação por especialistas humanos. Este benchmark também fornece apenas o conjunto de documentos necessários para responder a cada pergunta diretamente, o que não permite a avaliação das capacidades de recuperação do agente em um corpus grande. | “Você é um produtor musical em Los Angeles em 2024. Você foi contratado por um cliente para criar uma faixa instrumental para o videoclipe de uma música chamada 'Deja Vu'” |
ARC-AGI-2 | As tarefas são tão abstratas que perdem a conexão com tarefas de valor econômico no mundo real — elas envolvem a manipulação visual abstrata de grades coloridas. Modelos muito pequenos e especializados são capazes de igualar o desempenho de LLMs de uso geral muito maiores (1000x). | 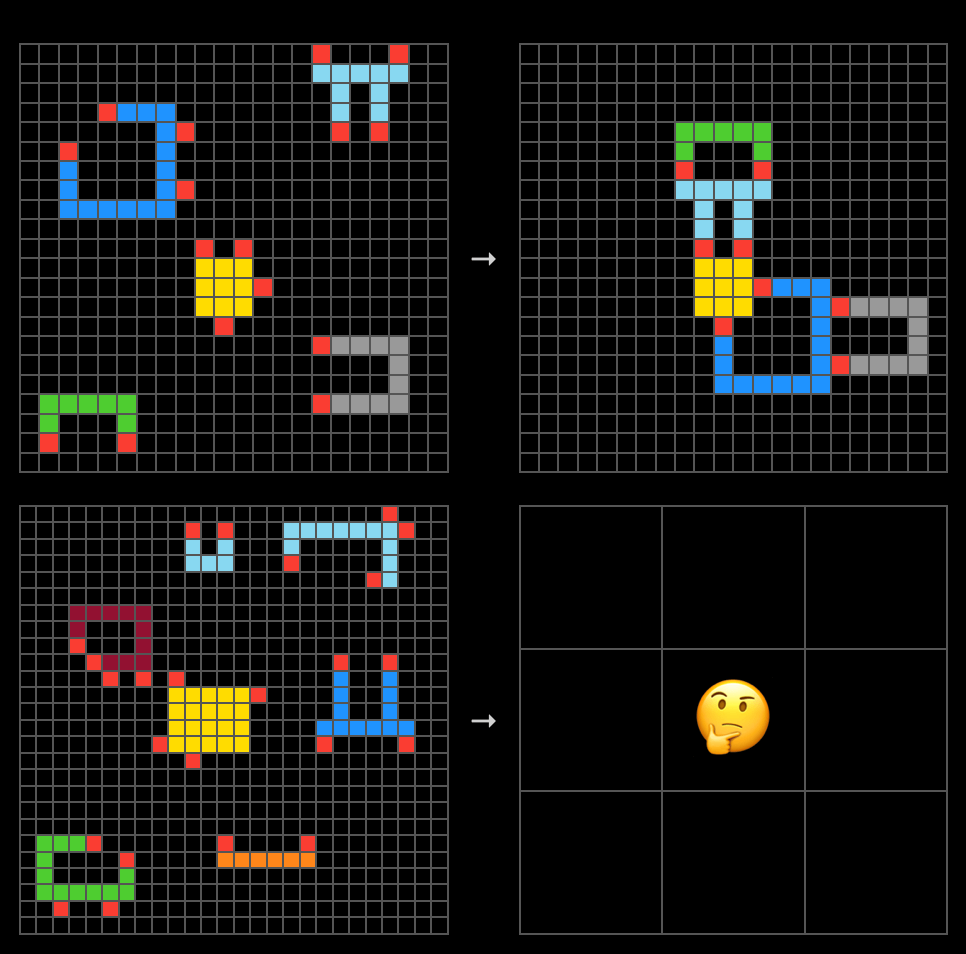
|
O Último Exame da Humanidade (HLE) | Obviamente, isso não representa o trabalho mais valioso do ponto de vista econômico e, certamente, não representa as cargas de trabalho dos clientes da Databricks. As perguntas exigem conhecimento em nível de doutorado e é provável que nenhum ser humano seja capaz de responder a todas as perguntas. | “Compute o bordismo de Spin reduzido de 12ª dimensão do espaço de classificação do grupo de Lie G2. "Reduzido" significa que você pode ignorar quaisquer classes de bordismo que possam ser representadas por variedades com fibrado principal G2 trivial.” |
Apresentando o Benchmark OfficeQA
Apresentamos o OfficeQA, um dataset que se aproxima de corpora corporativos proprietários, mas que está disponível gratuitamente e contém uma variedade de perguntas diversas e interessantes. Para criar este benchmark, utilizamos os Boletins do Tesouro dos EUA, historicamente publicados mensalmente por cinco décadas a partir de 1939 e trimestralmente depois disso. Cada boletim tem de 100 a 200 páginas e consiste em texto, muitas tabelas complexas, gráficos e figuras que descrevem as operações do Tesouro dos EUA – de onde o dinheiro veio, onde está, para onde foi e como financiou as operações. O conjunto de dados total tem aproximadamente 89.000 páginas. Até 1996, os boletins eram digitalizações de documentos físicos e, depois disso, PDFs produzidos digitalmente.
Também vemos valor em tornar esses dados históricos do Tesouro mais acessíveis ao público, a pesquisadores e a acadêmicos. USAFacts é uma organização que, naturalmente, compartilha essa visão, já que sua missão principal é "tornar os dados governamentais mais fáceis de acessar e entender". Eles foram nossos parceiros para desenvolver este benchmark, identificando os Boletins do Tesouro como um dataset ideal e garantindo que nossas perguntas refletissem casos de uso realistas para esses documentos.
Mantendo nosso objetivo de que as perguntas possam ser respondidas por pessoas não especialistas, nenhuma das perguntas exige mais do que operações matemáticas do ensino médio. Esperamos que a maioria das pessoas precise pesquisar alguns dos termos financeiros ou estatísticos na internet.
Visão geral do conjunto de dados
O OfficeQA consiste em 246 perguntas organizadas em dois níveis de dificuldade (fácil e difícil) com base no desempenho dos sistemas de AI existentes nas perguntas. Perguntas "fáceis" são definidas como aquelas que ambos os sistemas de agentes de ponta (detalhados abaixo) acertaram, e perguntas "difíceis" são aquelas que pelo menos um dos agentes respondeu incorretamente.
Em média, as perguntas exigem informações de aproximadamente 2 documentos diferentes do Treasury Bulletin. Em uma amostra representativa do benchmark, os solucionadores humanos levaram em média 50 minutos para concluir cada pergunta. A maior parte desse tempo foi gasta localizando as informações necessárias para responder à pergunta em várias tabelas e figuras dentro do corpus.
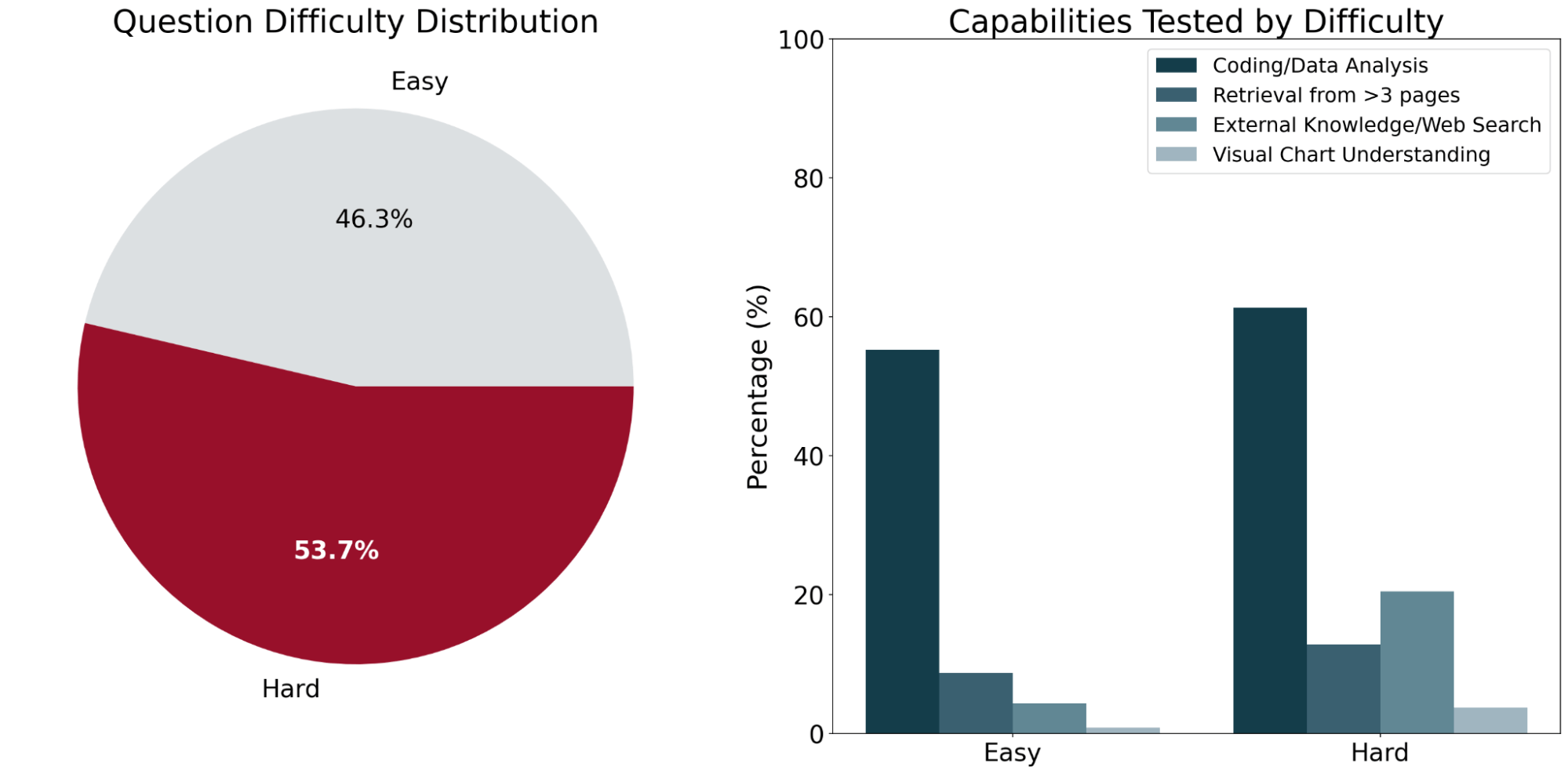
Para garantir que as perguntas do OfficeQA exigissem recuperação com base em documentos, fizemos o possível para filtrar todas as perguntas que os LLMs pudessem responder corretamente sem acesso aos documentos de origem (ou seja, que pudessem ser respondidas por meio do conhecimento paramétrico de um modelo ou de pesquisa na Web). A maioria dessas perguntas filtradas tendia a ser mais simples ou a perguntar sobre fatos mais gerais, como "No ano fiscal em que George H.W. Bush se tornou presidente, qual fundo federal dos EUA teve o maior aumento de investimento?"
Curiosamente, houve algumas perguntas aparentemente mais complexas que os modelos conseguiram responder apenas com conhecimento paramétrico, como “Realize um teste t de duas amostras para determinar se a taxa de juros média dos títulos do Tesouro dos EUA mudou entre 1942–1945 (antes do fim da Segunda Guerra Mundial) e 1946–1949 (depois do fim da Segunda Guerra Mundial) no nível de significância de 5%. Qual é a estatística t calculada, arredondada para o centésimo mais próximo?” Nesse caso, o modelo utiliza registros financeiros históricos que foram memorizados durante o pré-treinamento e, em seguida, calcula o valor final corretamente. Exemplos como estes foram filtrados do benchmark final.
Exemplos de perguntas do OfficeQA
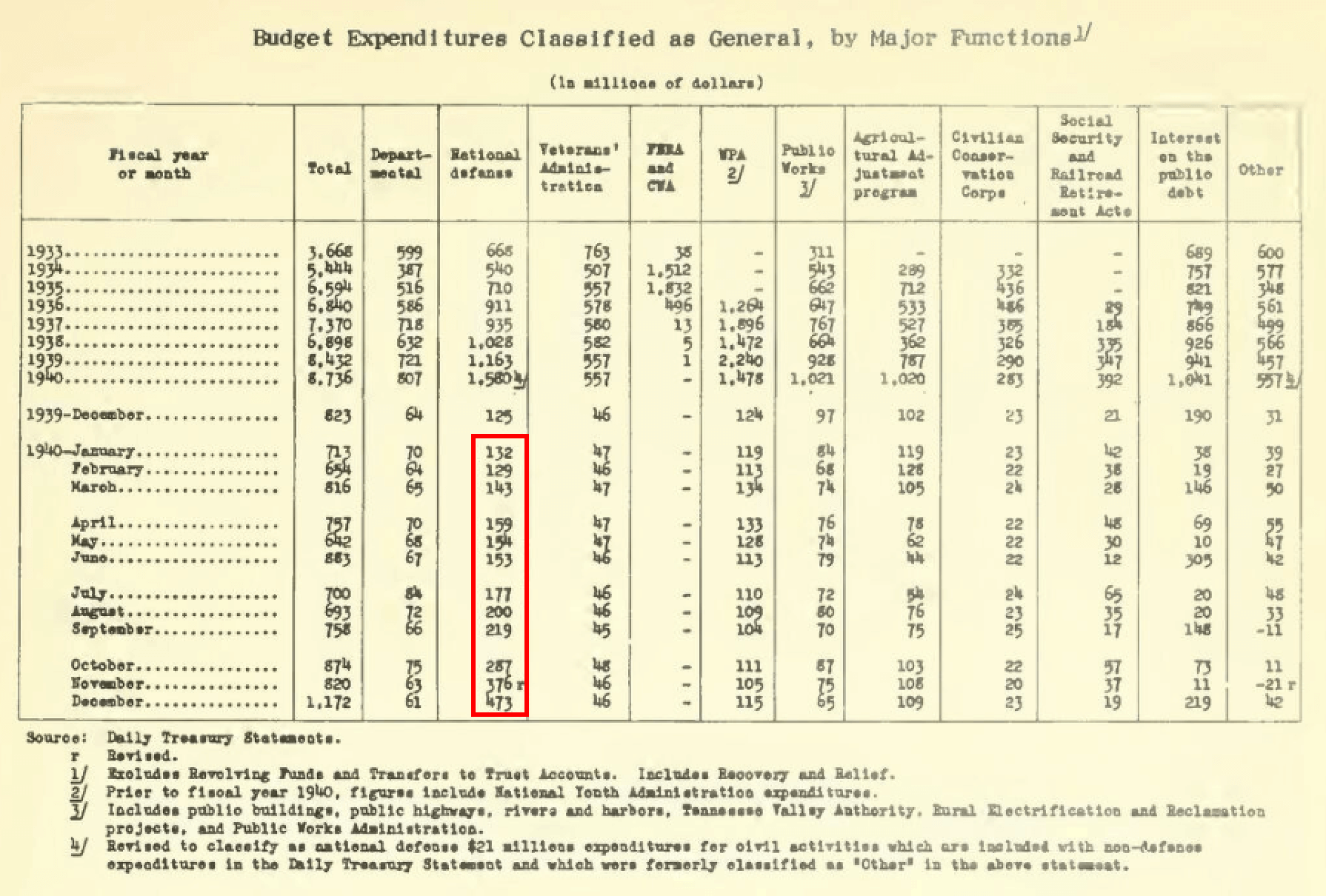
Fácil: “Quais foram os gastos totais (em milhões de dólares nominais) para a defesa nacional dos EUA no ano civil de 1940?”
Isso requer uma consulta de valor básica, e a soma dos valores para os meses do ano civil especificado em uma única tabela (destacada em vermelho). Observe que os totais dos anos anteriores são para anos fiscais e não civis.
Difícil: "Preveja os gastos totais do Departamento de Agricultura dos EUA em 1999 usando dados anuais de 1990 a 1998 (inclusive). Use um ajuste de regressão linear básica para produzir a inclinação e a intersecção y. Considere 1990 como o ano "0" para a variável de tempo. Realize todos os cálculos em dólares nominais. Você não precisa levar em conta os ajustes pós-ano. Informe todos os valores entre colchetes, separados por vírgulas, com o primeiro valor sendo a inclinação arredondada para o centésimo mais próximo, o segundo valor como a intersecção y arredondada para o número inteiro mais próximo e o terceiro valor como o valor previsto arredondado para o número inteiro mais próximo."
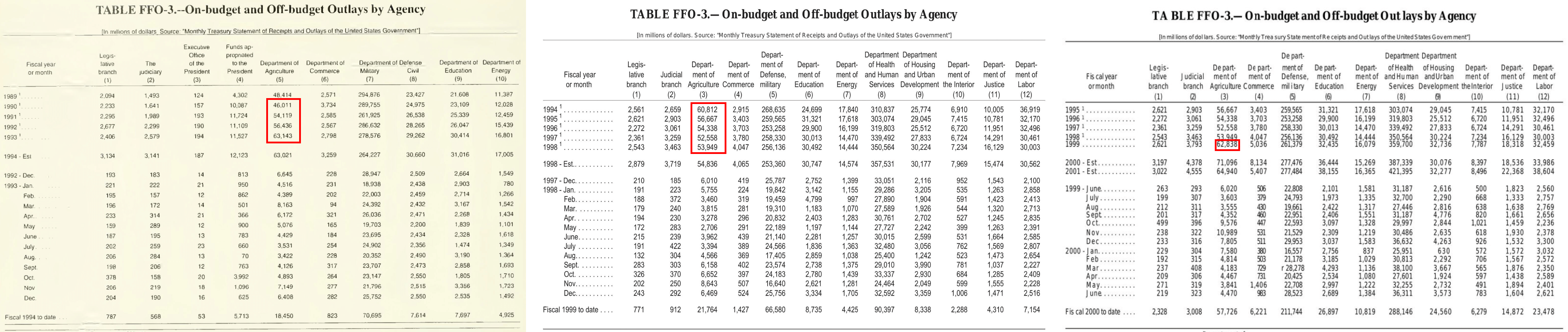
Isso exige que você encontre informações enquanto navega por vários documentos (foto acima) e envolve raciocínio mais avançado e cálculo estatístico com diretrizes de resposta detalhadas.
Agentes de Baseline: Implementação e Desempenho
Avaliamos os seguintes modelos de referência1:
- Agente GPT-5.1 com File Search: Usamos o GPT-5.1, configurado com reasoning_effort=high, por meio da API de Respostas da OpenAI e damos a ele acesso a ferramentas como busca de arquivos e pesquisa na web. Os PDFs são upload no OpenAI Vector Store, onde são automaticamente analisados e indexados. Também experimentamos fornecer ao Vector Store documentos pré-analisados usando ai_parse_document.
- Agente Claude Opus 4.5: Usamos o SDK Python do Agente da Claude com o Claude Opus 4.5 como backend (default thinking=high) e configuramos este agente com as capacidades autônomas oferecidas pelo SDK, como gerenciamento de contexto e um ecossistema de ferramentas integrado contendo ferramentas como pesquisa de arquivos (read, grep, glob, etc.), pesquisa na web, execução de programação e outras funcionalidades de ferramentas. Como o SDK do Agente da Claude não fornecia sua própria solução de análise (parsing) integrada, experimentamos (1) fornecer ao agente os PDFs armazenados em um sandbox de pasta local e a capacidade de instalar pacotes de leitura de PDF como
pdftotextepdfplumber, e (2) fornecer ao agente documentos pré-analisados usando ai_parse_document. - LLM com Página(s) de PDF Oráculo: Avaliamos o Claude Opus 4.5 e o GPT 5.1 fornecendo diretamente ao modelo a(s) página(s) exata(s) do PDF oráculo necessárias para responder à pergunta. Este é um baseline não agentivo que mede o quão bem os LLMs podem performar com o material de origem necessário para raciocinar e derivar a resposta correta, representando um limite superior de desempenho, assumindo um sistema de recuperação oráculo.
- LLM com página(s) de PDF analisada(s) por oráculo: também testamos fornecer ao Claude Opus 4.5 e ao GPT-5.1 diretamente a(s) página(s) de PDF pré-analisada(s) pelo oráculo, necessárias para responder à pergunta, que foram analisadas com o ai_parse_document.
Em todos os experimentos, removemos qualquer camada de OCR existente dos PDFs do U.S. Treasury Bulletin devido à sua baixa precisão. Isso garante uma avaliação justa da capacidade de cada agente de extrair e interpretar informações diretamente dos documentos digitalizados.
Abaixo, graficamos a exatidão de todos os agentes no eixo y, enquanto o eixo x representa o erro relativo absoluto permitido para que a resposta seja considerada correta. Por exemplo, se a resposta para uma pergunta for '5,2 milhões' e o agente responder '5,1 milhões' (1,9% de diferença da resposta original), o agente seria pontuado como correto para qualquer valor acima de um erro relativo absoluto permitido de 1,9%, e incorreto para qualquer valor <1,9%.
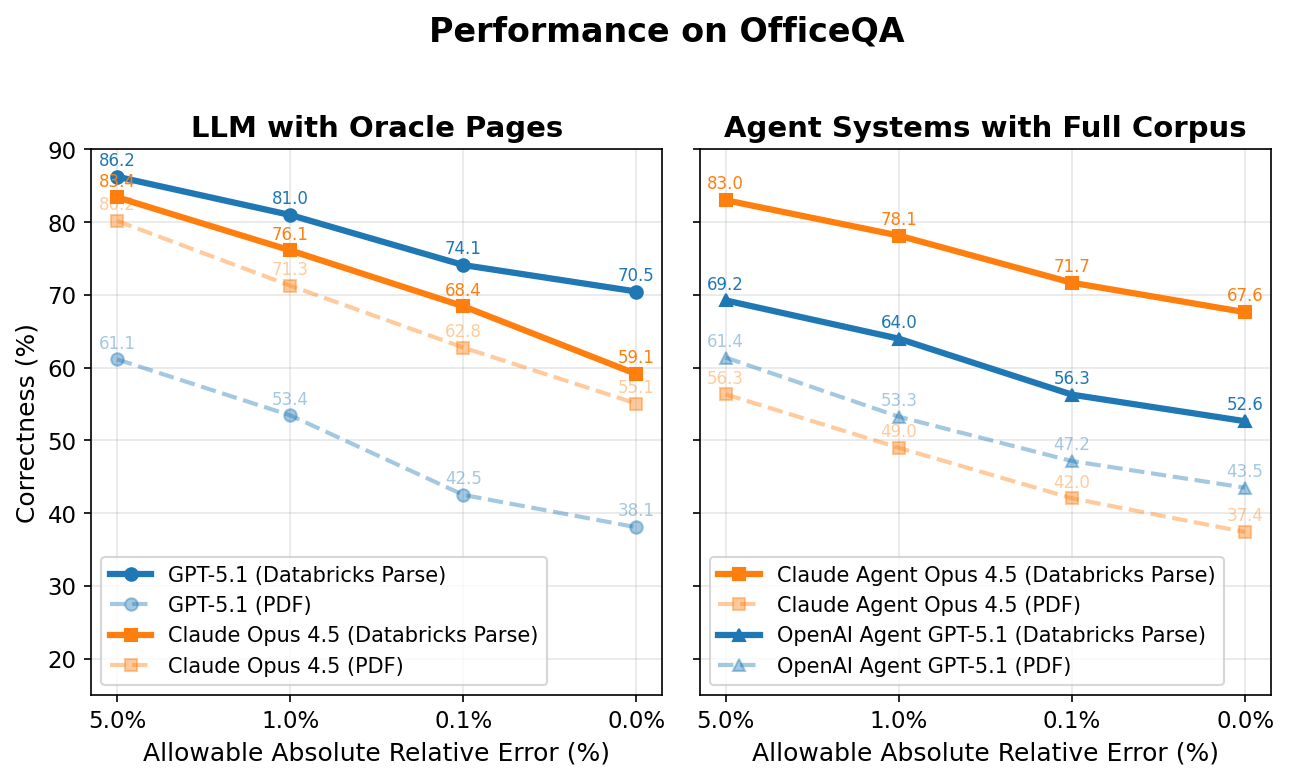
LLM com Oracle Page(s)
É interessante notar que tanto o Claude Opus 4.5 quanto o GPT 5.1 têm um desempenho ruim, mesmo quando fornecidos diretamente com a(s) página(s) em PDF do Oracle necessárias para cada pergunta. No entanto, quando essas mesmas páginas são pré-processadas usando o Databricks ai_parse_document, o desempenho aumenta significativamente - +4,0 e +32,4 pontos percentuais para o Claude Opus 4.5 e o GPT 5.1, respectivamente (representando +7,5% e +85,0% aumentos relativos).
Com a análise, o modelo com melhor desempenho (GPT-5.1) atinge aproximadamente 70% precisão. A lacuna restante de ~30% decorre de vários fatores: (1) essas linhas de base sem agentes não têm acesso a ferramentas como a pesquisa na Web, que ~13% das perguntas exigem; (2) ocorrem erros de análise e extração de tabelas e gráficos; e (3) permanecem erros de raciocínio computacional.
Sistemas de Agente com Corpus Completo
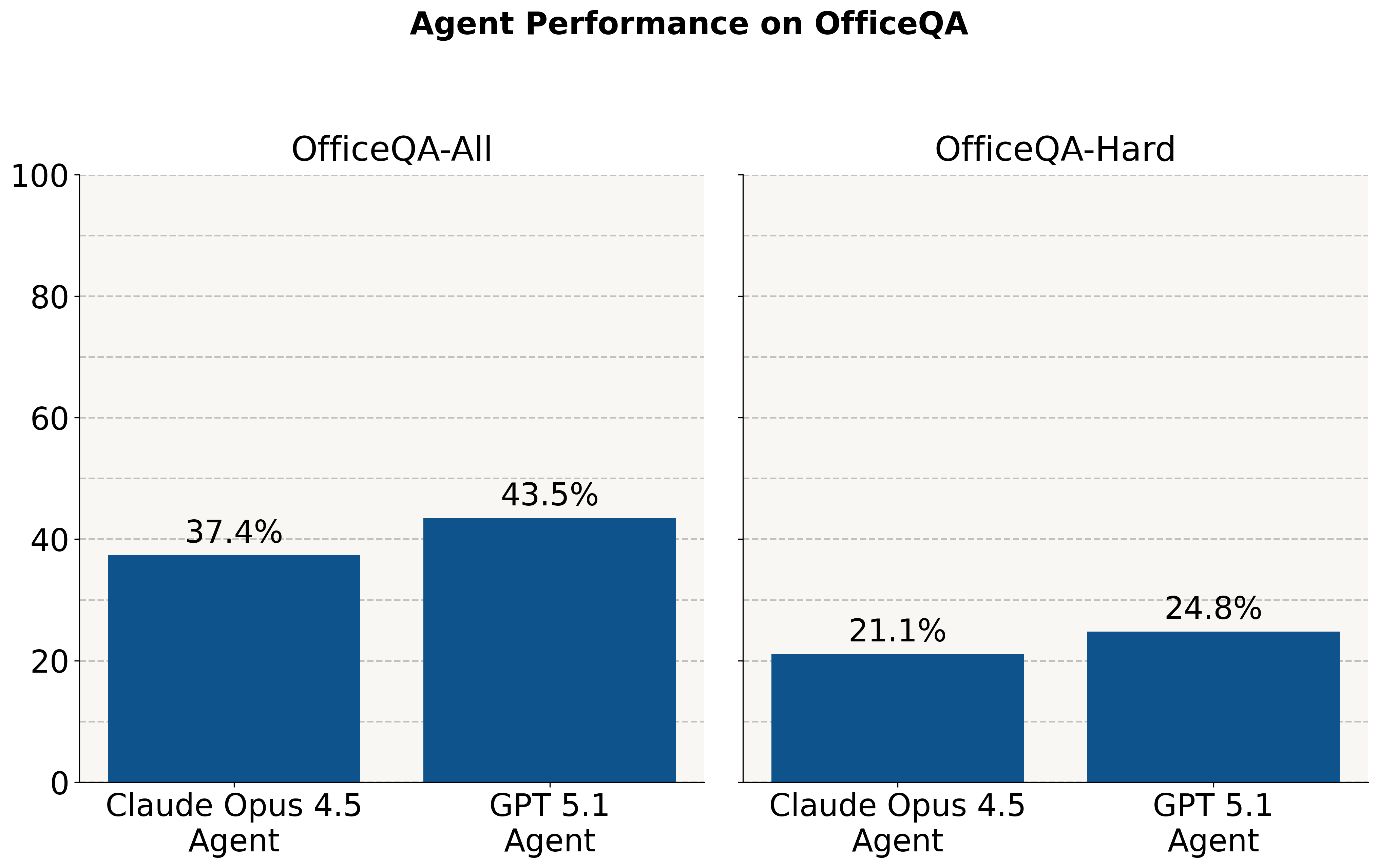
Quando recebem o corpus do OfficeQA diretamente, ambos os agentes respondem incorretamente a mais da metade das perguntas do OfficeQA, atingindo um desempenho máximo de 43,5% com 0% de erro permitido. Fornecer aos agentes documentos analisados com o ai_parse_document da Databricks melhora o desempenho novamente: o Agente Claude 4.5 Opus melhora em +30,2 pontos percentuais e o Agente GPT 5.1 em +9,1 pontos percentuais (aumentos relativos de 81,7% e 20,9%, respectivamente).
No entanto, mesmo o melhor agente – Claude Agent com Claude Opus 4.5 – ainda atinge menos de 70% de exatidão com 0% de erro permitido em documentos analisados, destacando a dificuldade dessas tarefas para os sistemas de AI de ponta. Alcançar esse desempenho superior também requer maior latência e custo associado. Em média, o Claude Agent leva cerca de 5 minutos para responder a cada pergunta, enquanto que o agente OpenAI de pontuação mais baixa leva cerca de 3 minutos.
Como esperado, os escores de correção aumentam gradualmente quando se permitem erros relativos absolutos maiores. Essas discrepâncias surgem da divergência de precisão, em que os agentes podem usar valores de origem com pequenas diferenças que drift em operações em cascata e produzem pequenos desvios na resposta final. Os erros incluem análise incorreta (ler '508' como '608', por exemplo), interpretação incorreta de valores estatísticos ou a incapacidade de um agente de recuperar informações relevantes e precisas do corpus. Por exemplo, um agente produz uma resposta incorreta, mas próxima da resposta de referência (ground truth), para esta pergunta: “Qual é a soma do total de títulos da dívida pública em circulação detidos por contas do governo dos EUA de cada ano, em milhões de dólares nominais, registrados no final dos anos fiscais de 2005 a 2009, inclusive, retornada como um valor único?” O agente acaba recuperando informações do boletim de junho de 2010, mas os valores relevantes e corretos são encontrados na publicação de setembro de 2010 (após as revisões relatadas), resultando em uma diferença de 21 milhões de dólares (0,01% de diferença em relação à resposta de referência (ground truth)).
Outro exemplo que resulta em uma diferença maior está nesta pergunta: “Faça uma análise de série temporal sobre os valores totais de superávit/déficit relatados para os anos civis de 1989-2013, tratando todos os valores como valores nominais em milhões de dólares americanos e, em seguida, ajuste um modelo de regressão polinomial cúbica para estimar o superávit ou déficit esperado para o ano civil de 2025 e relate a diferença absoluta em relação à estimativa relatada pelo Tesouro dos EUA, arredondada para o número inteiro mais próximo em milhões de dólares.”, um agente recupera incorretamente os valores do ano fiscal em vez dos valores do ano civil para 8 anos, o que altera a série de entrada usada para a regressão cúbica e leva a uma previsão diferente para 2025 e a um resultado de diferença absoluta que está errado em US$ 286.831 milhões (31,6% de diferença em relação ao valor de referência).
Modos de falha
Ao desenvolver o OfficeQA, observamos vários modos de falha comuns dos sistemas de AI existentes:
- Erros de análise continuam sendo um desafio fundamental — tabelas complexas com hierarquias de colunas aninhadas, células merge e formatação incomum muitas vezes resultam em valores desalinhados ou extraídos incorretamente. Por exemplo, observamos casos em que deslocamentos de coluna durante a extração automatizada fizeram com que valores numéricos fossem atribuídos a cabeçalhos completamente errados.
- A ambiguidade nas respostas também apresenta dificuldades: documentos financeiros como o Boletim do Tesouro dos EUA são frequentemente revisados e reeditados, o que significa que podem existir vários valores legítimos para o mesmo ponto de dados, dependendo da data de publicação que o agente usa como referência. Muitas vezes, os agentes param de pesquisar assim que encontram uma resposta plausível, deixando passar a fonte mais oficial ou atualizada, apesar de serem instruídos a encontrar os valores mais recentes.
- Compreensão visual representa outra lacuna significativa. Aproximadamente 3% das perguntas do OfficeQA fazem referência a gráficos, diagramas ou figuras que exigem raciocínio visual. Os agentes atuais frequentemente falham nessas tarefas, conforme mostrado no exemplo abaixo.
Esses modos de falha restantes mostram que a pesquisa ainda precisa avançar para que os agentes AI possam lidar com todo o espectro de tarefas de raciocínio de domínio específico da empresa.
Competição de Raciocínio Fundamentado da Databricks
Vamos colocar Agentes AI para competir com equipes de humanos na primavera de 2026 para ver quem alcança os melhores resultados no benchmark OfficeQA.
- Cronograma: Estamos planejando o evento principal para São Francisco, provavelmente entre o final de março e o final de abril. As datas exatas serão divulgadas em breve para quem se inscrever para receber as atualizações.
- Final Presencial: As melhores equipes serão convidadas para São Francisco para a competição final.
Estamos abrindo uma lista de interessados. Acesse o link para ser notificado assim que as regras oficiais, as datas e os Pools forem anunciados. (Em breve!)
Conclusão
O benchmark OfficeQA representa o passo significativo para avaliar agentes de AI em tarefas de raciocínio economicamente valiosas e baseadas no mundo real. Ao basear nosso benchmark nos Boletins do Tesouro dos EUA, um corpus de quase 89.000 páginas que abrange mais de oito décadas, criamos um testbed desafiador que exige que os agentes analisem tabelas complexas, recuperem informações de vários documentos e realizem raciocínio analítico com alta precisão.
O benchmark OfficeQA está disponível gratuitamente para a comunidade de pesquisa e pode ser encontrado aqui. Incentivamos as equipes a explorar o OfficeQA e apresentar soluções no benchmark como parte da Databricks Grounded Reasoning Cup.
Autores: Arnav Singhvi, Krista Opsahl-Ong, Jasmine Collins, Ivan Zhou, Cindy Wang, Ashutosh Baheti, Jacob Portes, Sam Havens, Erich Elsen, Michael Bendersky, Matei Zaharia, Xing Chen.
Gostaríamos de agradecer a Dipendra Kumar Misra, Owen Oertell, Andrew Drozdov, Jonathan Chang, Simon Favreau-Lessard, Erik Lindgren, Pallavi Koppol, Veronica Lyu, bem como a SuperAnnotate e Turing por ajudarem a criar as perguntas no OfficeQA.
Por fim, gostaríamos também de agradecer à USAFacts por sua orientação na identificação dos Boletins do Tesouro dos EUA e por fornecer feedback para garantir que as perguntas fossem atuais e relevantes.
1 Tentamos avaliar a recém-lançada API Gemini File Search Tool como parte de um baseline representativo do Gemini Agent com o Gemini 3. No entanto, cerca de 30% dos PDFs e dos PDFs analisados (parsed) no corpus do OfficeQA falharam na ingestão, e a File Search Tool é incompatível com a Google Search Tool. Como isso limitaria a capacidade do agente de responder a perguntas do OfficeQA que exigem conhecimento externo, excluímos essa configuração da nossa avaliação de baseline. Analisaremos novamente quando a ingestão funcionar de forma confiável para que possamos medir seu desempenho com precisão.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.