De PDFs à produção: anunciando a inteligência de documentos de última geração no Databricks
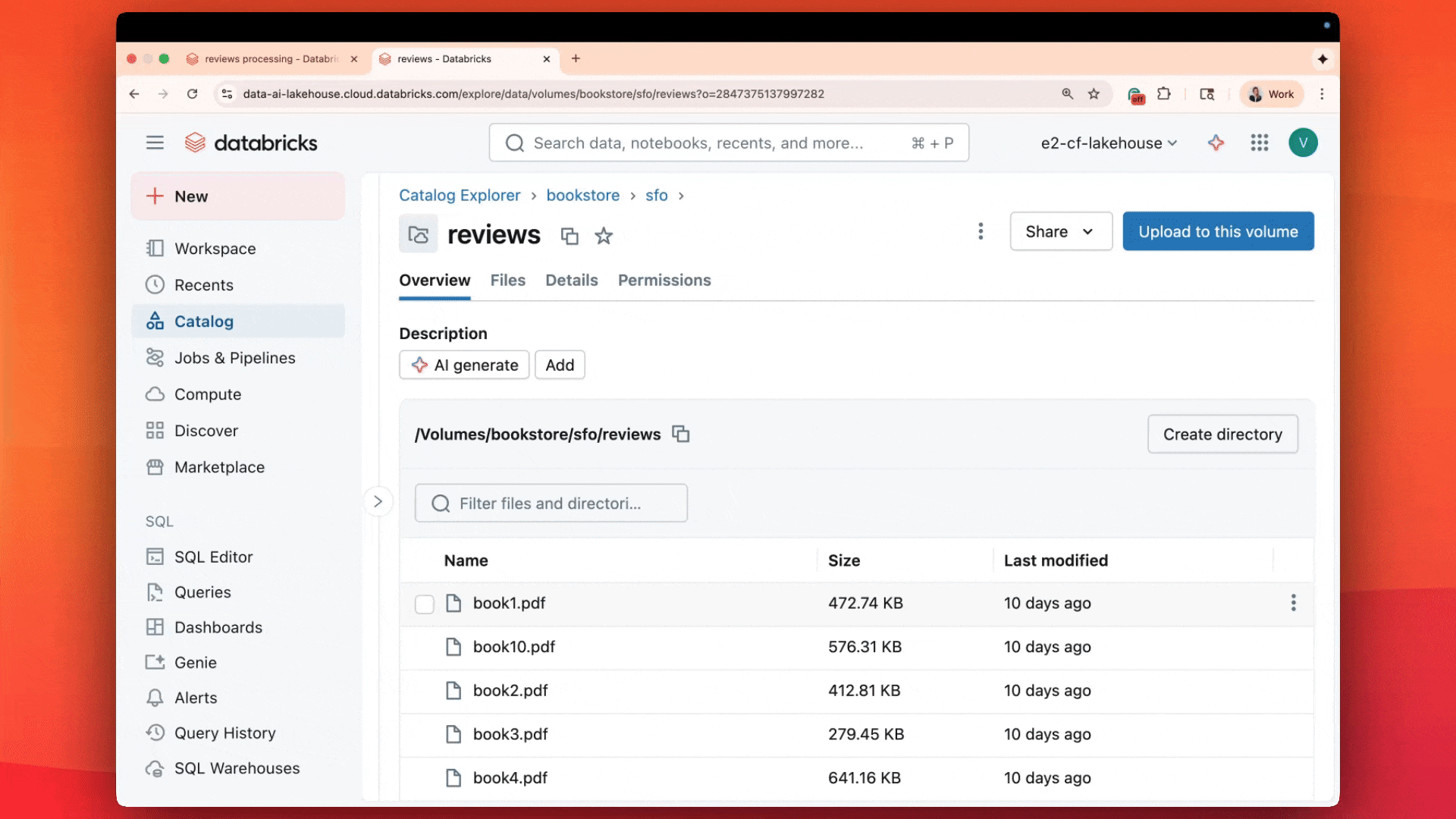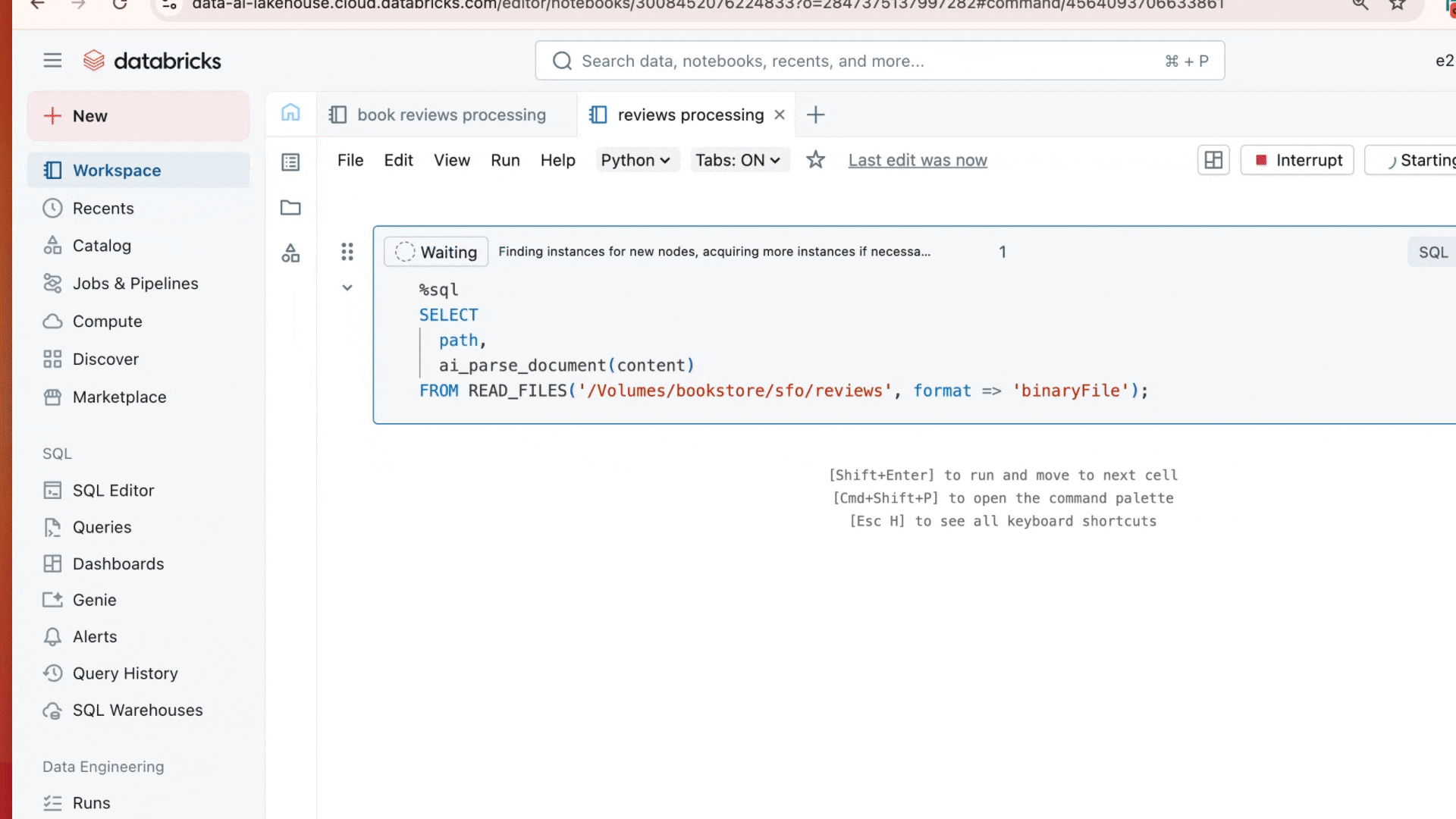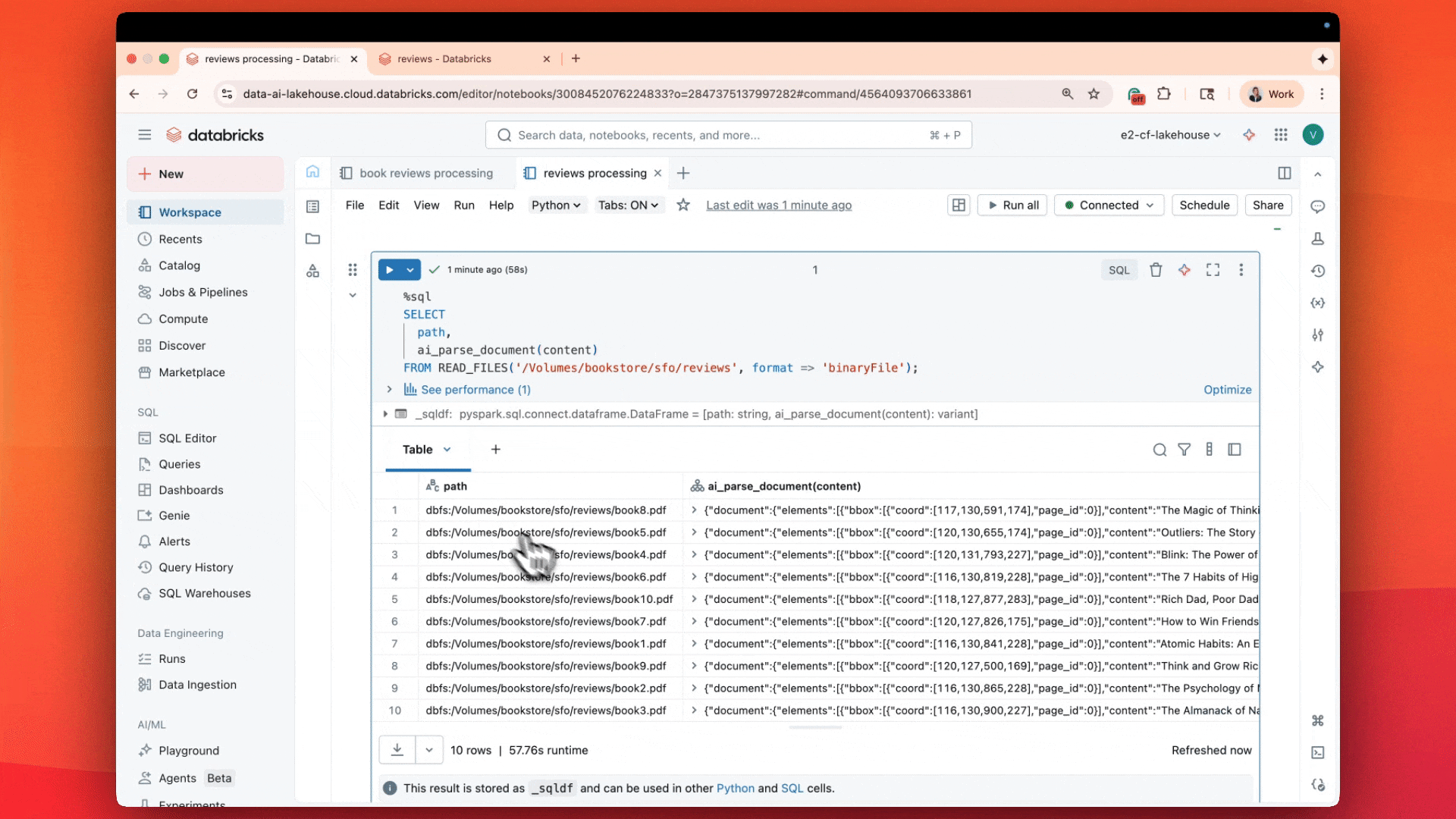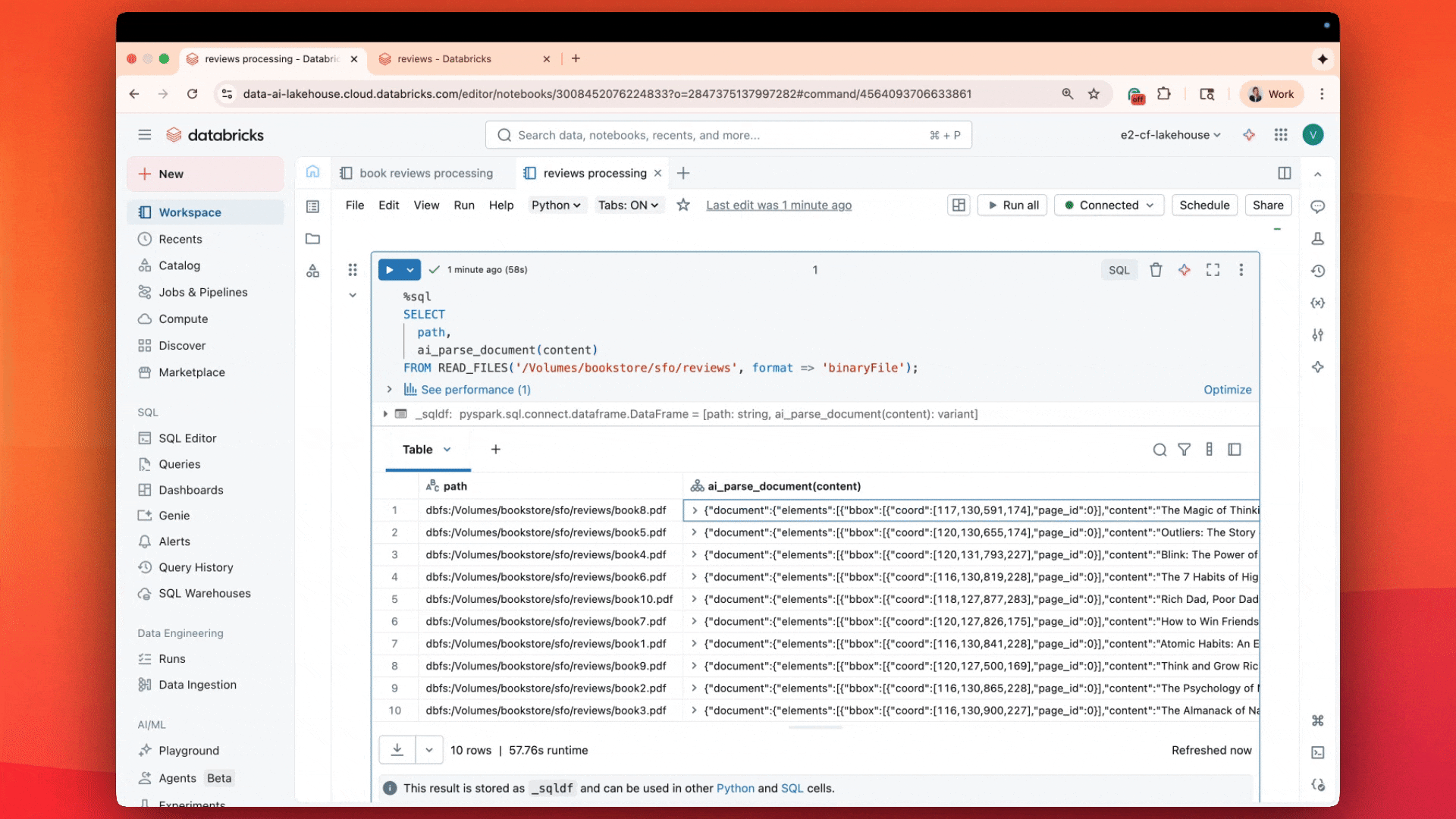
Com o ai_parse_document, analise e entenda PDFs diretamente em SQL com qualidade de ponta e um custo de 3 a 5 vezes menor
- Hoje, estamos apresentando a mais nova adição ao Agent Bricks: ai_parse_document (Visualização Pública): com a tecnologia do sistema agêntico da nossa equipe de pesquisa para compreensão multimodal em larga escala.
- Extraia valor de 80% dos seus dados corporativos com o processamento inteligente de documentos de última geração: processe milhões de documentos complexos (tabelas, figuras, diagramas) com o poder da pesquisa inovadora em AI em uma única função SQL.
- Qualidade e custo líderes: desenvolvemos um sistema de inteligência de documentos competitivo em qualidade com as melhores ofertas da concorrência, com um custo de 3 a 5 vezes menor.
- Integração total com a plataforma: processamento incremental automático com Spark Declarative Pipelines, governança com o Unity Catalog e uso integrado no Agent Bricks, no AI Search e na AIBI.
Durante a Week of Agents, estamos expandindo o Agent Bricks, a plataforma da Databricks para criar agentes de AI governados e prontos para produção que raciocinam com precisão sobre seus dados. Um dos maiores desafios que as empresas enfrentam ao escalar agentes é o acesso a dados não estruturados. Quase 80% do conhecimento empresarial está preso em PDFs, relatórios e diagramas que os agentes não conseguem ler, entender ou analisar. Esses documentos contêm um contexto essencial, mas a maioria dos agentes de AI não conseguia lê-los. Até agora.
As ferramentas de análise existentes se limitam à extração de texto. Elas não capturam as disposições, elementos visuais e relações que carregam significado em documentos reais. As equipes passam meses escrevendo códigos personalizados e frágeis que ainda falham com dados do mundo real. ai_parse_document elimina essa complexidade. Ele traz o entendimento completo de documentos diretamente para a Databricks Data Intelligence Platform, dando a cada agente acesso à fidelidade total do seu contexto de negócios — com precisão, segurança e em escala.
Com um único comando SQL, as organizações podem transformar documentos em dados estruturados, governados e consultáveis:
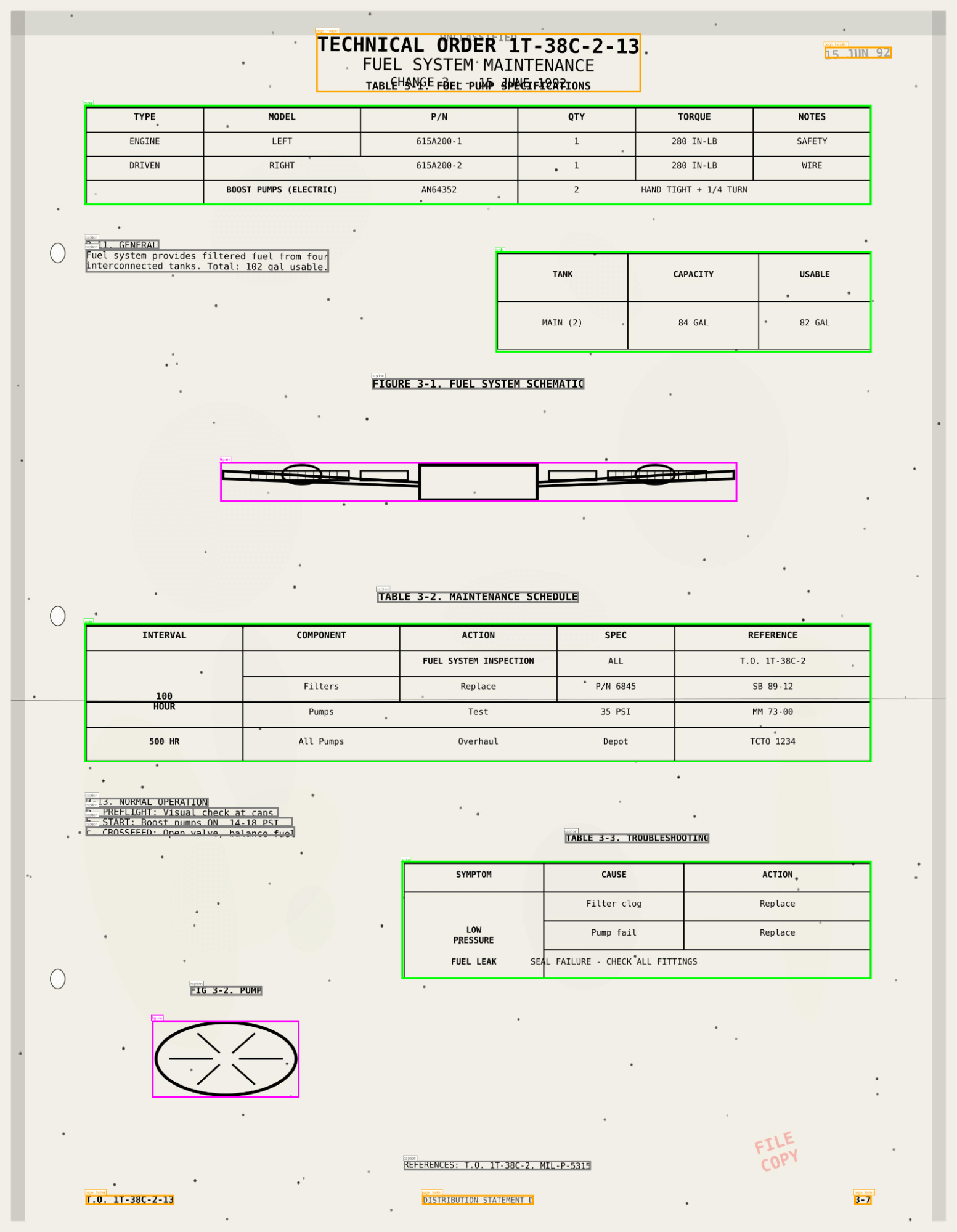
O resultado não é apenas o texto do PDF, mas também disposição de informação, tabelas analisadas, caixas delimitadoras, figuras e imagens com legendas – uma descrição abrangente do documento, como informação estruturada.
"O ai_parse_document da Databricks reduz a sobrecarga de configuração, permitindo que os cientistas de dados gastem menos tempo na configuração e mais tempo no avanço de soluções complexas e focadas no cliente."—Meiling He, Gerente Sênior de Ciência de Dados, Rockwell Automation
Preço-desempenho de ponta
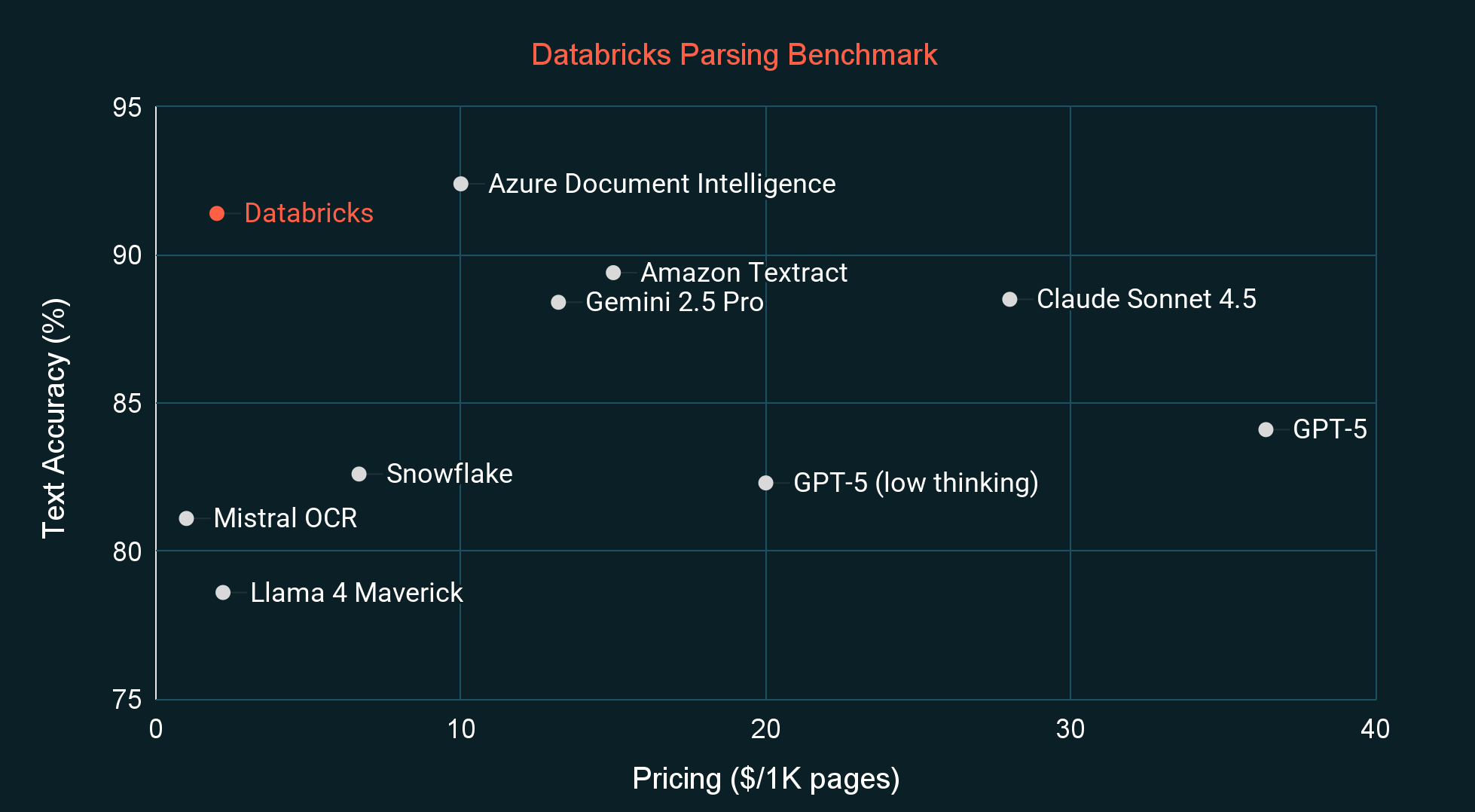
Quando comparado a outros sistemas de análise de ponta e modelos de linguagem de visão (VLMs), o ai_parse_document tem a mais alta qualidade em sua categoria de preço, medida tanto por um benchmark externo comum (OmniOCR) quanto por nosso benchmark interno privado (veja as figuras abaixo). O benchmark interno está mais alinhado com a distribuição de documentos que vimos de clientes e também é improvável que faça parte dos dados de treinamento de qualquer modelo. Nas próximas semanas, também lançaremos nossos novos rótulos OmniOCR, que corrigem alguns erros de rotulagem e introduzem caixas delimitadoras e informação de hierarquia.

Como funciona
O ai_parse_document captura tabelas, figuras e diagramas com descrições geradas por AI e metadados espaciais, armazenando os resultados no Unity Catalog. Seus documentos agora se comportam como tabelas — pesquisáveis pelo AI Search e acionáveis em fluxos de trabalho do Agent Bricks.
“Extrair tabelas, texto e metadados de PDFs ou imagens costumava ser um processo complexo e com muito código. O Databricks condensou isso em uma única função SQL, a ai_parse_document, simplificando radicalmente o processamento de dados não estruturados em escala e colocando-o nas mãos de todas as equipes de dados, não apenas dos cientistas de dados.”—Rajesh Balakrishnan, Cientista de Dados Principal, TE Connectivity
Com uma única instrução SQL, os clientes já estão processando milhões de documentos em paralelo:
Cada resultado inclui:
- Tabelas preservadas exatamente como aparecem, incluindo células merge e estruturas aninhadas.
- Figuras e diagramas descritos automaticamente com legendas geradas por AI.
- Metadados espaciais e caixas delimitadoras para citações e validação.
- Saídas de imagem opcionais armazenadas nos volumes do Unity Catalog para pesquisa multimodal ou visualização.
Como tudo permanece dentro do Databricks, você mantém governança, linhagem e observabilidade consistentes.
Substitua sua pilha de analisadores externos por uma única função SQL que funciona como qualquer outra operação do Databricks. Embora as equipes normalmente exportem documentos para serviços de OCR, APIs de detecção de disposição e ferramentas de legendagem de figuras, ai_parse_document os processa sem sair do seu ambiente Databricks:
"A função ai_parse_document torna o RAG r�ápido e simples no Databricks, permitindo a análise paralela de documentos diretamente nas Delta tables que você já usa"—Hunter Johnson, Cientista de Dados Líder, Emerson Electric Co.
Da análise à ação com o Agent Bricks
Depois de analisados, os dados dos documentos fluem naturalmente pelo restante do Agent Bricks ecossistema:
- AI Search indexa cada elemento para aplicações de RAG multimodais que entendem tanto texto quanto elementos visuais.
- Agentes Declarativos otimizam a extração, a classificação e a sumarização com linguagem natural para obter melhor throughput e menores custos
- AI Functions extraia entidades, classifique conteúdo e resuma textos, tudo com SQL.
- Supervisor Agent coordena agentes de análise de documentos com outros agentes especializados, permitindo fluxos de trabalho complexos e de várias etapas.
- Dashboards de AI/BI e Pipelines Declarativos do Spark usam os mesmos dados analisados para analítica e processamento contínuo.
Em conjunto, esses recursos tornam os dados não estruturados uma parte totalmente integrada da plataforma Agent Bricks.
Desenvolvido para escala de produção e confiabilidade
Muitas empresas têm milhões de documentos não estruturados para analisar, e algumas até recebem milhões por dia. É fundamental ter uma solução que possa ser dimensionada de forma confiável para processar esses dados sem levar dias. O Databricks integra ai_parse_document com o Spark Declarative Pipelines, fornecendo processamento de documentos automático e incremental em escala. Quando novos documentos chegam, seja do SharePoint, S3 ou ADLS, eles são analisados automaticamente. O Lakeflow lida com novas tentativas, checkpointing e dimensionamento, para que você nunca precise reprocessar dados existentes ou escrever um código de orquestração personalizado.
Tudo é governado pelo Unity Catalog, o que permite gerenciar permissões, auditar o acesso e rastrear a linhagem do conteúdo analisado exatamente como você faz com dados estruturados.
Desbloqueie dados não estruturados com Agent Bricks
ai_parse_document é a adição mais recente às Agent Bricks AI Functions, juntando-se a recursos como ai_extract, ai_classify, ai_summarize e ai_query. Juntas, essas funções dão a todas as equipes a capacidade de raciocinar sobre todos os dados corporativos diretamente na plataforma Databricks. Ao combinar a inteligência de documentos com governança, observabilidade e orquestração integrada, a Databricks permite que as empresas criem agentes de AI que realmente entendem o contexto de seus negócios e agem com base nele com confiança.
Pronto para extrair o valor de seus dados não estruturados?
- Leia a documentação para começar a usar o ai_parse_document hoje
- Crie pipelines de documentos incrementais com nossa solução de referência
Autores da pesquisa (contribuição igual): Ziyi Yang, Jasmine Collins, Adyasha Maharana, Cory Stephenson, Erich Elsen, Adam Gurary, Ethan Tang
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.