Criando um Assistente de Conhecimento sobre Código
Avaliando Estratégias de Chunking com MLflow
por Daniel Liden
- RAG sobre código tem desafios únicos de chunking: dividir funções no meio do corpo ou descartar o contexto estrutural degrada a recuperação, mesmo quando você encontra o arquivo certo.
- Usamos o framework de avaliação GenAI do MLflow com juízes LLM integrados e personalizados para comparar sistematicamente três estratégias de chunking usadas com o Databricks Knowledge Assistant.
- O próprio processo de avaliação foi a principal lição: datasets de avaliação estruturados, resultados rastreáveis e juízes LLM personalizados alinhados com o que você realmente se importa são o que tornam a iteração de RAG prática.
Quando desenvolvedores entram em um novo projeto ou precisam trabalhar em uma base de código desconhecida, assistentes de conhecimento como o Databricks Knowledge Assistant os ajudam a se familiarizar rapidamente, respondendo a perguntas em linguagem natural sobre o código. Mas a qualidade da resposta depende muito de como o código-fonte e o contexto circundante foram preparados e adicionados. Um fator chave é o chunking: como você divide os arquivos-fonte em pedaços para indexação e recuperação. O código torna isso complicado. Se você quebrar uma função no meio do corpo ou remover seu contexto de classe, mesmo um assistente capaz terá dificuldade em responder perguntas sobre ela.
Construímos três Assistentes de Conhecimento em nosso repositório GitHub de demonstração Casper’s Kitchens, cada um usando uma estratégia de chunking diferente, desde uma linha de base simples de tamanho fixo até uma abordagem ciente da estrutura que analisa o código em seus componentes sintáticos. O repositório simula um negócio de ghost kitchen no Databricks, usando uma ampla gama de recursos, incluindo pipelines Lakeflow, agentes DSPy e Databricks Asset Bundles (DABs), com documentação em arquivos markdown e células de notebook. As dependências entre arquivos, os formatos de arquivo mistos e os padrões específicos do domínio o tornam o tipo de projeto onde um assistente de conhecimento capaz seria uma grande ajuda.
Este post detalha o que torna o trabalho com código diferente do trabalho com documentos de negócios típicos, como implantamos cada estratégia de chunking como um Databricks Knowledge Assistant e como usamos a estrutura de avaliação do MLflow para compará-los. Você pode encontrar todo o código aqui.
Como os Assistentes de Conhecimento Funcionam (e Por Que Código é Diferente)
Por baixo dos panos, os assistentes de conhecimento usam várias formas de geração aumentada por recuperação (RAG). Eles recuperam pedaços relevantes dos dados de origem, muitas vezes de um índice de busca vetorial, e os passam para um modelo de linguagem grande como contexto para gerar uma resposta para a consulta do usuário.
O Databricks Knowledge Assistant se baseia nessa fundação com técnicas sofisticadas de recuperação, incluindo o Instructed Retriever, que incorpora decomposição de consulta, reclassificação informada pelo contexto e raciocínio sobre metadados de documentos. Essas capacidades ajudam muito a lidar com a complexidade de bases de código do mundo real, e funcionam melhor quando os pedaços subjacentes preservam limites semânticos significativos.
Assistentes de conhecimento são mais comumente construídos e avaliados sobre coleções de documentos de negócios, que tendem a fluir linearmente, com parágrafos e seções. Código tem hierarquias aninhadas: arquivos contêm classes, classes contêm métodos, métodos contêm blocos de lógica. A unidade semântica em código é frequentemente uma função completa, não um parágrafo.
Isso cria desafios específicos, incluindo:
- Limites semânticos: Dividir uma função no meio do corpo perde o contexto necessário para entender o que ela faz. Um pedaço contendo
deletion_order = ['experiments', 'jobs'...é menos útil se não mostrar que essa variável está dentro deUCState.clear_all(). - Dependências entre arquivos: Código referencia outro código. Entender uma função muitas vezes requer contexto de sua classe, suas importações ou funções relacionadas.
- Tipos de arquivo mistos: Nossa base de código tem arquivos
.py, notebooks.ipynb(JSON com células de código/Markdown), documentação.mde configuração.yaml, cada um exigindo abordagens de análise diferentes.
Como o Databricks Knowledge Assistant permite que você use seu próprio índice vetorial, você pode preparar os pedaços como quiser e apenas apontar o Knowledge Assistant para o resultado. Isso nos permitiu comparar diferentes abordagens para preparar nossa base de código para RAG e escolher a melhor.
Estratégias de Chunking
Para ver como as estratégias de chunking diferem na prática, considere o que acontece quando você pergunta: “Em que ordem a limpeza de recursos ocorre?” A resposta está em uma classe utilitária que rastreia experimentos, trabalhos e pipelines. Sua lógica abrange inicialização, uma lista de ordem de exclusão e métodos de limpeza. Veja como cada método funciona e como ele afeta o contexto recuperado sobre a classe de limpeza de recursos, UCState.
Linha de Base Ingênua: Pedaços de Caracteres de Tamanho Fixo
A abordagem mais simples é dividir os arquivos-fonte em intervalos de caracteres fixos com sobreposição, tratando o código como texto puro. Isso não é o que você escolheria para um sistema RAG pronto para produção hoje. Ele ignora a sintaxe e os limites semânticos, portanto, falha exatamente nas maneiras que as consultas de código importam. Mas também é extremamente fácil de implementar, muitas vezes “bom o suficiente” para experimentos rápidos ou repositórios com muitos documentos, e comum como uma primeira passagem, então é uma linha de base útil.
Veja o que o chunking ingênuo produz para uma busca por deletion_order em nossa base de código:
O nome da variável foi cortado em dois (eletion em vez de deletion), e o pedaço não inclui o nome do método. Se alguém procurar por “UCState deletion order”, este pedaço não corresponderá bem. Além disso, a lista deletion_order no método foi cortada.
Ciente da Linguagem: Divisores Heurísticos do LangChain
O RecursiveCharacterTextSplitter.from_language() do LangChain usa separadores específicos da linguagem (como \nclass e \ndef para Python) para preferir dividir em limites lógicos. Ele tenta manter as funções intactas, mas ainda impõe limites de tamanho rigorosos. Conceitualmente, isso melhora o chunking ingênuo ao priorizar divisões em limites semânticos prováveis (como def e class) em vez de contagens arbitrárias de caracteres, então os pedaços são mais propensos a conter unidades completas de lógica.
Veja o que essa abordagem produziu para a mesma busca:
O pedaço começa em um limite mais natural, mas ainda carece de contexto mostrando de qual arquivo ou função ele pertence, e é cortado logo após o início de um loop for.
Baseado em AST: Tree-Sitter com Cabeçalhos de Metadados
A divisão baseada em árvore de sintaxe abstrata (AST) usa um parser como o Tree-sitter para entender a estrutura real do código. Uma AST é uma representação em árvore do código que captura sua estrutura sintática — como o código é organizado de acordo com as regras gramaticais de uma linguagem. Em vez de dividir em limites de caracteres ou usar padrões heurísticos, uma estratégia de divisão baseada em AST analisa o código em uma árvore de sintaxe e divide em limites semânticos, como funções, classes ou blocos de instrução. Ela também pode exceder os limites de tamanho quando necessário para manter uma unidade completa junta, em vez de dividir no meio de uma função.
Usamos a biblioteca Python ASTChunk para lidar com a divisão baseada em AST. A biblioteca inclui uma opção de expansão de chunk que faz com que cada chunk seja precedido por um cabeçalho de metadados mostrando o caminho do arquivo e a hierarquia de classe/função. Esse contexto se torna parte do embedding, ajudando a recuperação a corresponder consultas a códigos relevantes, mesmo quando os termos da consulta não aparecem no corpo do chunk.
Aqui está o chunk que essa abordagem produziu para nossa consulta:
O cabeçalho nos diz exatamente onde esse código está localizado: utils/uc_state/state_manager.py → class UCState: → def clear_all(...). Quando incorporado, este chunk tem uma conexão semântica mais forte com consultas sobre “UCState,” “clear_all,” ou “deletion order.”
Nesta fase, tínhamos algumas intuições sobre quais métodos provavelmente funcionariam melhor em nosso Knowledge Assistant. Mas para ter certeza, precisávamos realizar uma avaliação sistemática.
Configuração de Avaliação com MLflow
O framework de avaliação GenAI do MLflow fornece um conjunto completo de ferramentas para comparar LLMs, agentes e sistemas de recuperação. Você fornece um conjunto de dados de avaliação, uma função de predição e juízes de LLM, e ele executa cada pergunta através do seu pipeline e pontua os resultados. Veja como o usamos para comparar os três métodos de chunking.
O Conjunto de Dados de Avaliação
Criamos 46 perguntas em um conjunto diversificado de categorias, variando de tópicos conceituais amplos a consultas detalhadas sobre o código.
| Category | Count | Example |
|---|---|---|
| Pinpointing specific values | 7 | "What is the exact deletion order in UCState.clear_all()?" |
| Retrieving complete definitions | 8 | "List all fields and validators in the ComplaintResponse model." |
| Understanding system flows | 6 | "How does the complaint pipeline work end-to-end, from generation to Lakebase sync?" |
| Comparing app implementations | 13 | "How does parse_agent_response differ between complaints-manager and refund-manager?" |
| Comparing frameworks & patterns | 12 | "What ML framework does each agent use? How do their error handling and streaming patterns differ?" |
Nós deliberadamente ponderamos o conjunto de dados em direção a perguntas de desambiguação onde a base de código tem código estruturalmente semelhante em contextos diferentes, como dois aplicativos com nomes de funções sobrepostos, esquemas de banco de dados paralelos ou arquivos de configuração que diferem em maneiras sutis. Estas são as consultas que expõem as fraquezas do chunking com mais clareza. Se seus chunks carecem de metadados sobre onde o código está localizado, o sistema de recuperação terá dificuldade em diferenciar entre classes e funções semelhantes que existem em contextos diferentes.
Os Juízes de LLM
Usamos três juízes principais de LLM, cada um capturando um aspecto diferente da qualidade:
RetrievalSufficiency(embutido): Os chunks recuperados contêm informações suficientes para responder à pergunta? Esta é a métrica chave para comparar estratégias de chunking porque mede a qualidade da recuperação independentemente da geração.RetrievalGroundedness(embutido): A resposta está fundamentada no contexto recuperado, ou introduz informações não presentes nos chunks?answer_correctness(personalizado): Este scorer personalizado classifica cada resposta como correta, parcialmente correta ou incorreta, tornando-a um pouco mais sutil do que um juiz de correção estrito sim/não. Dada a possibilidade de contexto fragmentado ou incompleto, queremos observar respostas que possam estar faltando detalhes ou ter pequenas imprecisões.
Executando a Avaliação
Para manter a comparação justa, todas as estratégias usaram o mesmo tamanho de chunk alvo (1.000 caracteres), sobreposição (200 caracteres) e modelo de embedding (databricks-gte-large-en). Na prática, os tamanhos finais dos chunks ainda diferem (por exemplo, a divisão baseada em AST pode expandir para preservar uma unidade semântica completa, enquanto arquivos muito pequenos naturalmente produzem chunks pequenos).
Para cada estratégia de chunking, escrevemos os chunks em uma tabela Delta, criamos um índice de AI Search com embeddings gerenciados (usando o modelo de embedding databricks-gte-large-en, conforme exigido pelo Databricks Knowledge Assistant) e anexamos o índice a um endpoint do Knowledge Assistant. A documentação cobre a configuração completa.
Avaliamos cada estratégia de chunking consultando diretamente seu endpoint do Knowledge Assistant. A função to_predict_fn() do MLflow encapsula um endpoint de serviço como uma função de predição, e como os Knowledge Assistants produzem rastros completos do MLflow, incluindo spans de recuperação, os juízes embutidos podem inspecionar tanto os chunks recuperados quanto a resposta final.
Os juízes de LLM chamam um juiz de LLM através do Databricks Model Serving. Usamos databricks-claude-opus-4-6:
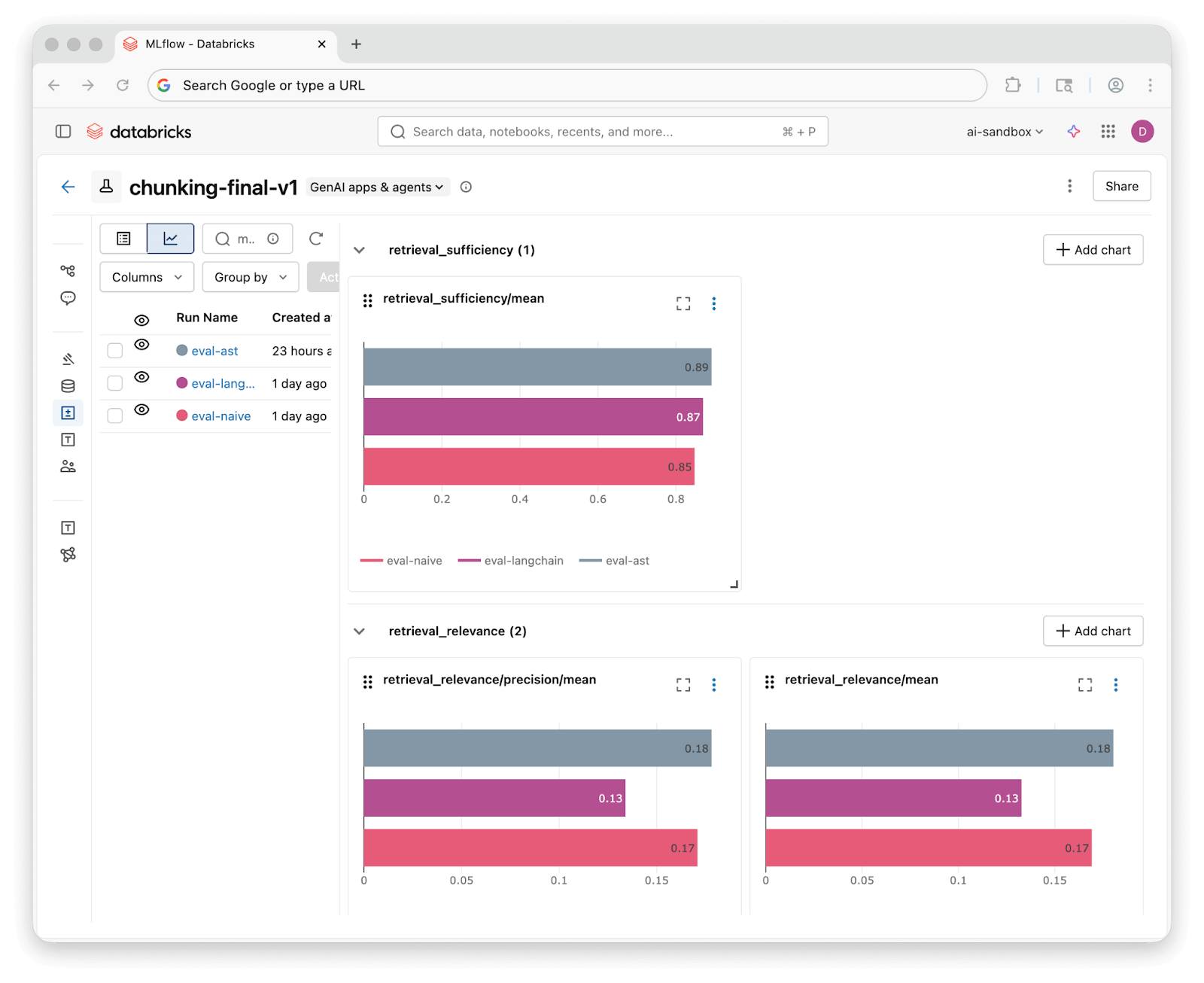
Assim que as execuções de avaliação são concluídas, a interface de experimentos do MLflow permite comparar os resultados entre as três estratégias lado a lado:
Resultados e Lições Aprendidas
Executamos todas as 46 perguntas em cada Knowledge Assistant e pontuamos os resultados com nossos três juízes. Eis o que descobrimos:
| Juiz | Ingênuo | Divisor de Linguagem | AST |
|---|---|---|---|
| Suficiência da Recuperação | 85% | 87% | 89% |
| Fundamentação da Recuperação | 76% | 72% | 76% |
| Correção da Resposta (personalizado) | 59% totalmente correto (37% parcial) | 61% totalmente correto (37% parcial) | 70% totalmente correto (28% parcial) |
Todas as três estratégias atingem mais de 85% de suficiência na recuperação, o que significa que as técnicas de recuperação do Assistente de Conhecimento encontram contexto relevante, independentemente de como o código foi dividido. As diferenças no nível de recuperação são modestas.
Os resultados personalizados de correção contam a história mais interessante. A divisão baseada em AST produz uma resposta totalmente correta em 70% das vezes, em comparação com 59% para Ingênuo e 61% para Ciente de Linguagem. Todas as três estratégias produzem pelo menos uma resposta parcialmente correta em quase todos os casos. Melhores divisões ajudam o assistente de conhecimento a responder perguntas de forma mais completa.
A vantagem se concentra em tipos específicos de perguntas. A divisão baseada em AST se destacou em perguntas de desambiguação, onde existe código estruturalmente semelhante entre os módulos, devido aos metadados pré-anexados (caminho do arquivo, classe, nome da função) fornecendo o contexto necessário. Todas as três estratégias foram comparáveis para consultas de valores e recuperação de definição completa.
Os rastros do MLflow facilitam a análise de perguntas individuais e a visualização exata de quais trechos foram recuperados e onde as respostas divergiram:
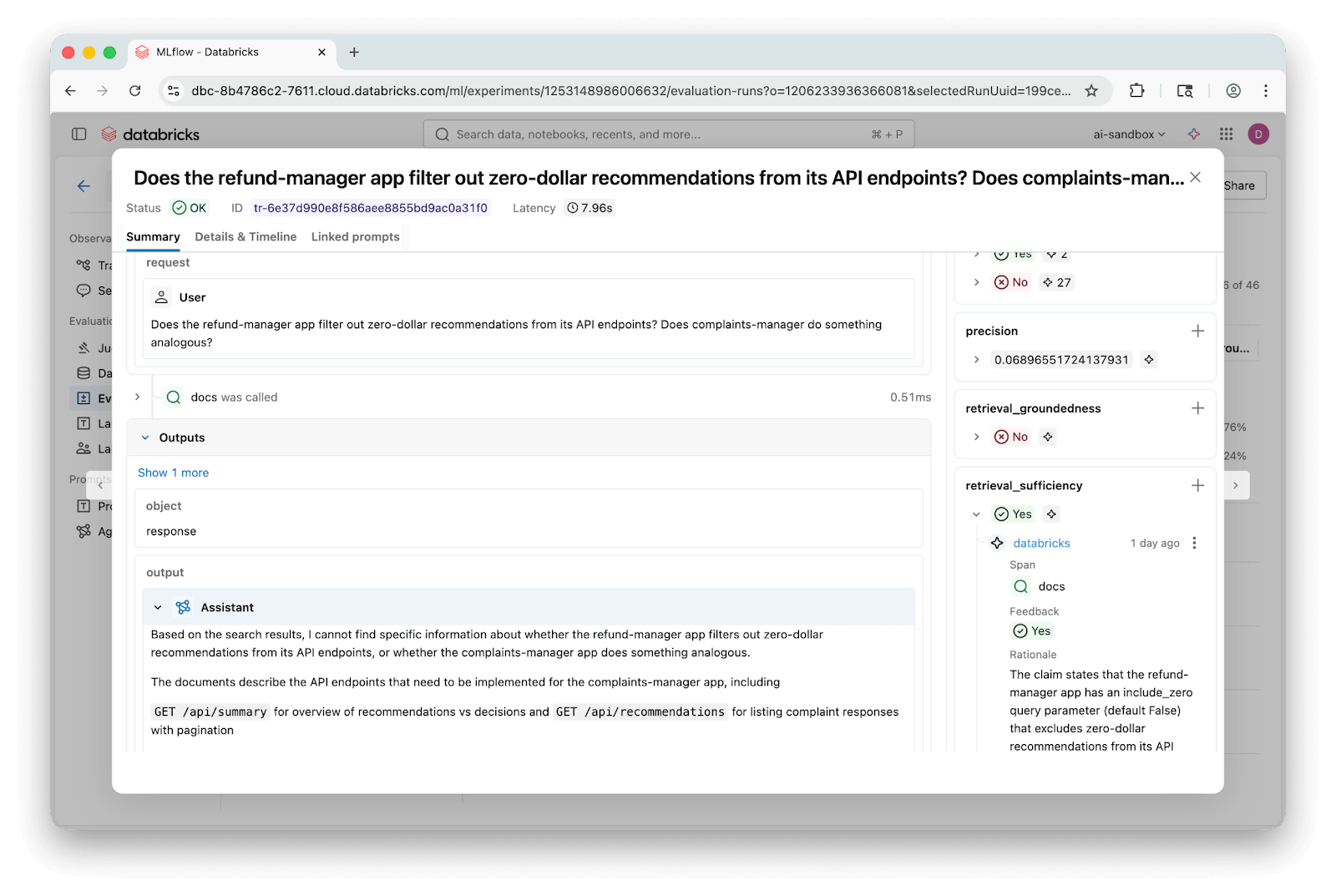
Essa investigação deixou algumas perguntas sem resposta: as melhorias que vimos usando a divisão baseada em AST foram principalmente uma consequência dos tamanhos médios maiores dos trechos? Quão dependentes foram os resultados da escolha do modelo que alimenta os juízes de LLM? Nossas perguntas de avaliação perderam categorias importantes que os usuários reais fariam?
Lições Aprendidas
O Databricks Knowledge Assistant é altamente capaz desde o início. A suficiência da recuperação foi alta em todas as três estratégias, e quase todas as perguntas obtiveram pelo menos uma resposta parcialmente correta.
A preparação de dados ainda importa. A divisão baseada em AST melhorou a fundamentação e a correção nesta avaliação, particularmente para perguntas que envolviam a desambiguação de código semelhante. Mesmo melhorias marginais na recuperação e na qualidade da resposta se acumulam em uma equipe de desenvolvedores que fazem dezenas de perguntas por dia.
Juízes de LLM personalizados ajudam a medir o que realmente nos importa. A API make_judge() do MLflow facilita a criação de juízes de LLM específicos para casos de uso. Nosso juiz personalizado answer_correctness foi capaz de fornecer uma visão mais nuançada sobre a correção do que um juiz de correção simples de aprovação/reprovação.
Os rastros do MLflow simplificam o loop de avaliação. Você pode investigar perguntas individuais para ver exatamente quais trechos foram recuperados e onde a resposta deu errado. Como os rastros persistem, você pode reavaliar com juízes diferentes sem reconsultar o endpoint.
Referências
- Databricks Agent Bricks: Knowledge Assistant—Guia de configuração para criar um Assistente de Conhecimento com índices de pesquisa vetorial personalizados.
- Framework de avaliação GenAI do MLflow—Documentação para
mlflow.genai.evaluate(), juízes de LLM integrados e API de pontuação personalizada. - cAST: Enhancing Code Retrieval-Augmented Generation with Structural Chunking via Abstract Syntax Tree—O artigo que motivou nossa abordagem de divisão AST, com benchmarks em várias tarefas de RAG de código. Usamos a implementação da biblioteca Python ASTChunk.
- LangChain
RecursiveCharacterTextSplitter—Referência de API para o divisor de texto ciente de linguagem que usamos na comparação.
Experimente Você Mesmo
Você pode acompanhar esta demonstração no repositório Casper’s Kitchens. Se você está avaliando estratégias de divisão para seu próprio codebase ou explorando outras melhorias de RAG, este framework de avaliação oferece uma maneira reproduzível de comparar abordagens.
- Crie um conjunto de dados de avaliação com perguntas e respostas esperadas.
- Implemente estratégias de divisão (ou use as nossas como ponto de partida).
- Configure juízes de LLM do MLflow — comece com as opções integradas e adicione personalizadas conforme encontrar lacunas.
- Execute avaliações com índices atualizados para cada estratégia.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.