Instructed Retriever: Desbloqueando o raciocínio em nível de sistema em agentes de busca
Os agentes baseados em recuperação estão no centro de muitos casos de uso empresariais de missão crítica. Os clientes corporativos esperam que eles executem tarefas de raciocínio que exijam o cumprimento de instruções específicas do usuário e operem de forma eficaz em diversas fontes de conhecimento heterogêneas. No entanto, na maioria das vezes, a geração aumentada por recuperação (RAG) tradicional falha em traduzir a intenção detalhada do usuário e as especificações da fonte de conhecimento em consultas de pesquisa precisas. A maioria das soluções existentes ignora esse problema, empregando ferramentas de pesquisa prontas para uso. Outras subestimam drasticamente o desafio, contando apenas com modelos personalizados para embedding e reclassificação, que são fundamentalmente limitados em sua expressividade. Neste blog, apresentamos o Instructed Retriever, uma nova arquitetura de recuperação que aborda as limitações da RAG e reinventa a pesquisa para a era dos agentes. Em seguida, ilustramos como essa arquitetura possibilita agentes baseados em recuperação mais capazes, incluindo sistemas como o Agent Bricks: Knowledge Assistant, que devem raciocinar sobre dados corporativos complexos e manter uma adesão estrita às instruções do usuário.
Por exemplo, considere um exemplo na Figura 1, em que um usuário pergunta sobre a expectativa de vida útil da bateria em um produto fictício da FooBrand. Além disso, as especificações do sistema incluem instruções sobre a atualidade, os tipos de documento a serem considerados e o tamanho da resposta. Para seguir corretamente as especificações do sistema, a solicitação do usuário primeiro precisa ser traduzida em consultas de pesquisa estruturadas que contenham os devidos filtros de coluna além das palavras-chave. Depois, uma resposta concisa e baseada nos resultados da consulta precisa ser gerada com base nas instruções do usuário. Esse acompanhamento complexo e deliberado de instruções não pode ser alcançado por um pipeline de recuperação simples que se concentra apenas na consulta do usuário.
![Figura 1. Exemplo do fluxo de trabalho de recuperação instruído para a query [What is the battery life expectancy for FooBrand products]. As instruções do usuário são traduzidas em (a) duas queries de recuperação estruturadas, recuperando tanto avaliações recentes quanto uma descrição oficial do produto, e (b) uma resposta curta, baseada nos resultados da pesquisa.](https://www.databricks.com/sites/default/files/inline-images/image7_24.png)
Os pipelines RAG tradicionais dependem da recuperação em uma única etapa usando apenas a query do usuário e não incorporam nenhuma especificação adicional do sistema, como instruções específicas, exemplos ou esquemas de fontes de conhecimento. No entanto, como mostramos na Figura 1, essas especificações são chaves para o seguimento bem-sucedido de instruções em sistemas de busca agênticos. Para lidar com essas limitações e concluir tarefas com sucesso, como a descrita na Figura 1, nossa arquitetura Instructed Retriever permite o fluxo de especificações do sistema para cada um dos componentes do sistema.
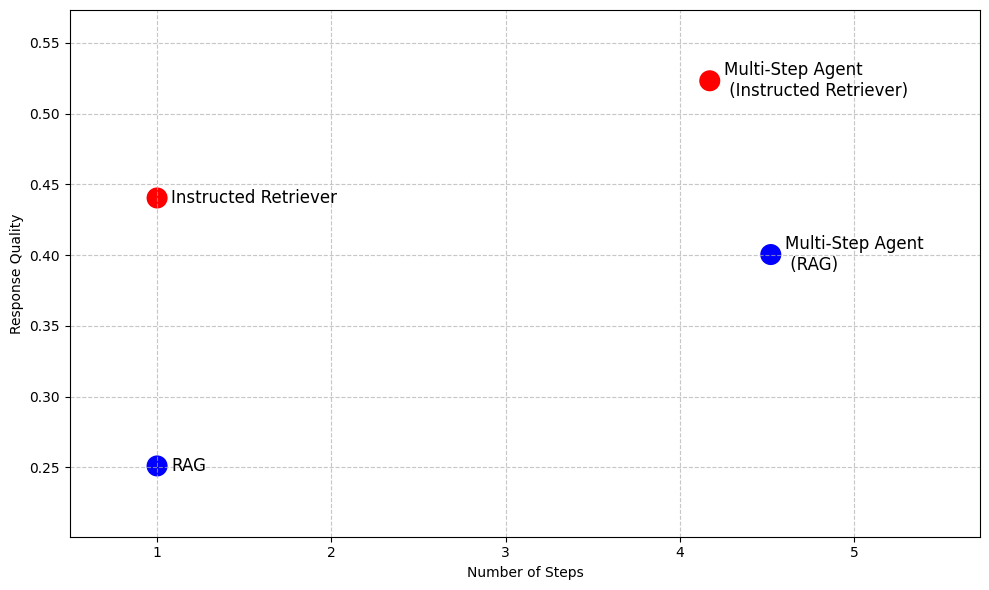
Mesmo além do RAG, em sistemas de busca agênticos mais avançados que permitem a execução de buscas iterativas, o seguimento de instruções e a compreensão do esquema da fonte de conhecimento subjacente são capacidades-chave que não podem ser desbloqueadas pela simples execução do RAG como uma ferramenta em vários passos, conforme ilustra a Tabela 1. Assim, a arquitetura Instructed Retriever oferece uma alternativa de alto desempenho ao RAG, quando é necessária baixa latência e um modelo pequeno, ao mesmo tempo que possibilita agentes de pesquisa mais eficazes para cenários como pesquisas aprofundadas.
Geração aumentada de recuperação (RAG)� | Retriever Instruído | Agente Multipasso (RAG) | Agente de múltiplos passos (Recuperador instruído) | |
Número de os passos | Único | Único | Vários | Vários |
Capacidade de seguir instruções | ✖️ | ✅ | ✖️ | ✅ |
Compreensão da fonte de conhecimento | ✖️ | ✅ | ✖️ | ✅ |
Baixa latência | ✅ | ✅ | ✖️ | ✖️ |
Modelo compacto | ✅ | ✅ | ✖️ | ✖️ |
Raciocínio sobre os resultados | ✖️ | ✖️ | ✅ | ✅ |
Tabela 1. Um resumo das capacidades do RAG tradicional, do Instructed Retriever e de um agente de busca de várias etapas implementado usando qualquer uma das abordagens como ferramenta
Para demonstrar as vantagens do Instructed Retriever, a Figura 2 apresenta seu desempenho em comparação com baselines baseados em RAG em um conjunto de datasets corporativos de perguntas e respostas1. Nesses benchmarks complexos, o Instructed Retriever aumenta o desempenho em mais de 70% em comparação com o RAG tradicional. O Instructed Retriever supera até mesmo um agente de várias etapas baseado em RAG em 10%. Incorporá-lo como uma ferramenta em um agente de várias etapas traz ganhos adicionais, ao mesmo tempo que reduz o número de passos de execução, em comparação com o RAG.
No restante desta postagem no blog, discutimos o design e a implementação dessa nova arquitetura de Instructed Retriever. Demonstramos que o instructed retriever leva a um acompanhamento de instruções preciso e robusto na etapa de geração de query, o que resulta em melhorias significativas no recall de recuperação. Além disso, mostramos que esses recursos de geração de queries podem ser desbloqueados até mesmo em modelos pequenos por meio de aprendizado por reforço offline. Por fim, analisamos mais detalhadamente o desempenho de ponta a ponta do instructed retriever, tanto em configurações de agente de etapa única quanto de várias etapas. Mostramos que ele consistentemente possibilita melhorias significativas na qualidade da resposta em comparação com as arquiteturas RAG tradicionais.
Arquitetura do Instructed Retriever
Para enfrentar os desafios do raciocínio em nível de sistema em sistemas agênticos de recuperação, propomos uma nova arquitetura de Instructed Retriever, mostrada na Figura 3. O Instructed Retriever pode ser chamado em um fluxo de trabalho estático ou exposto como uma ferramenta para um agente. A principal inovação é que essa nova arquitetura oferece uma maneira simplificada não apenas de responder à imediata do usuário, mas também de propagar a totalidade das especificações do sistema para os componentes do sistema de recuperação e de geração. Isso representa uma mudança fundamental em relação aos pipelines de RAG tradicionais, em que as especificações do sistema podem (na melhor das hipóteses) influenciar a inicial, mas depois são perdidas, forçando o retriever e o gerador de resposta a operar sem o contexto vital dessas especificações.
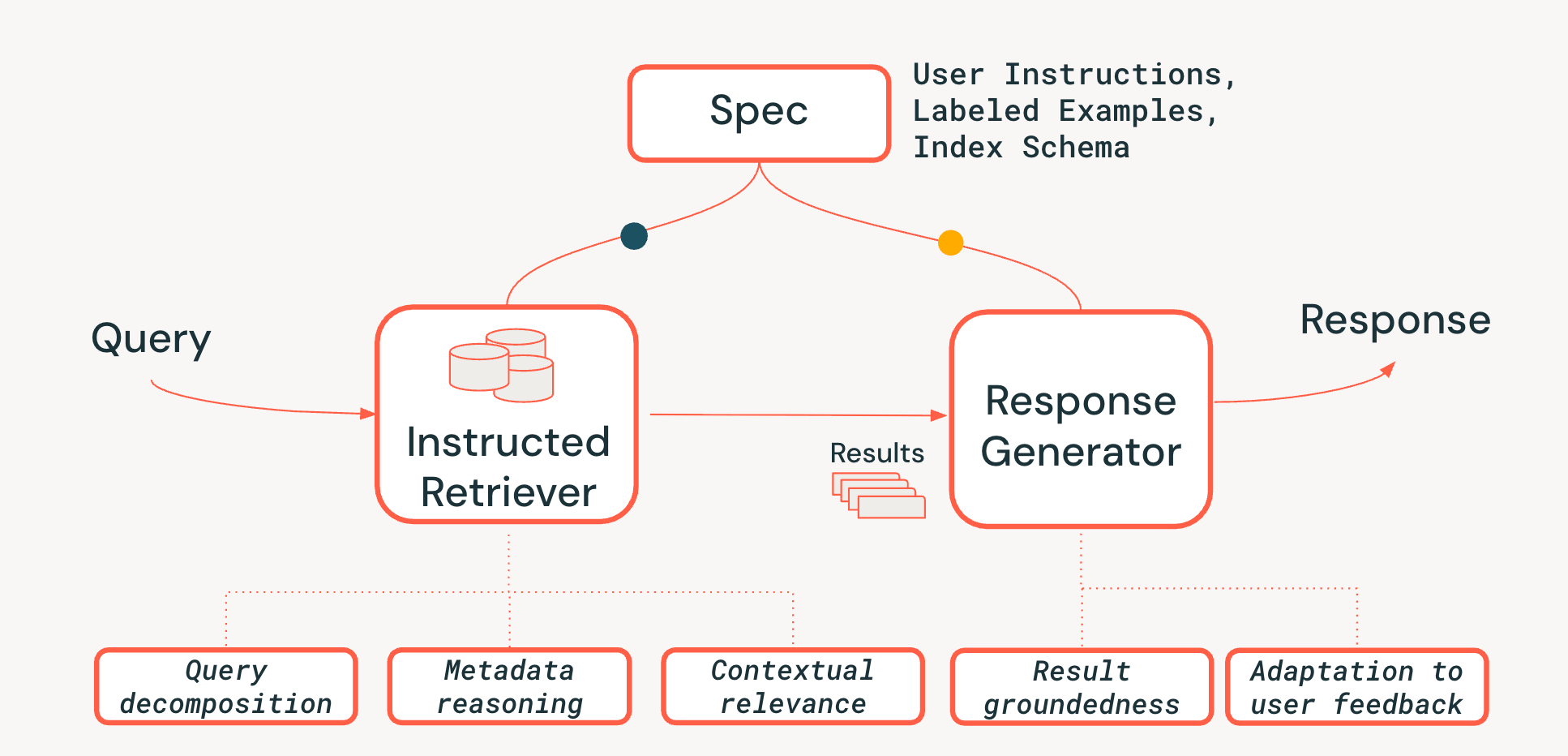
As especificações do sistema são, portanto, um conjunto de princípios orientadores e instruções que o agente deve seguir para atender fielmente à solicitação do usuário, que pode incluir:
- Instruções do usuário: preferências ou restrições gerais, como "focar em avaliações dos últimos anos" ou "não mostrar produtos da FooBrand nos resultados".
- Exemplos rotulados: Amostras concretas de pares <consulta, documento> relevantes/não relevantes que ajudam a definir como é uma recuperação de alta qualidade que segue instruções para uma tarefa específica.
- Descrições do índice: Um esquema que informa ao agente quais metadados estão realmente disponíveis para recuperação (por exemplo, product_brand, doc_timestamp, no exemplo da Figura 1).2
Para habilitar a persistência das especificações em todo o pipeline, adicionamos três recursos essenciais ao processo de recuperação:
- Decomposição de query: A capacidade de decompor uma solicitação complexa de várias partes ("Encontre um produto FooBrand, mas apenas do ano passado, e que não seja um modelo 'lite'") em um plano de pesquisa completo, contendo várias pesquisas por palavra-chave e instruções de filtro.
- Relevância contextual: Indo além da simples semelhança de texto para uma verdadeira compreensão da relevância no contexto da query e das instruções do sistema. Isso significa que o reclassificador, por exemplo, pode usar as instruções para impulsionar documentos que correspondem �à intenção do usuário (por exemplo, "recência"), mesmo que a correspondência das palavras-chave seja mais fraca.
- Raciocínio de metadados: um dos principais diferenciais da nossa arquitetura Instructed Retriever é a capacidade de traduzir instruções em linguagem natural ("do ano passado") em filtros de busca precisos e executáveis ("doc_timestamp > TO_TIMESTAMP('2024-11-01')").
Também garantimos que a etapa de geração de resposta seja condizente com os resultados recuperados, as especificações do sistema e qualquer história ou feedback anterior do usuário (conforme descrito com mais detalhes neste blog).
A aderência a instruções em agentes de busca é desafiadora, pois as necessidades de informação do usuário podem ser complexas, vagas ou até mesmo conflitantes, muitas vezes acumuladas ao longo de várias rodadas de feedback em linguagem natural. O recuperador também precisa ser ciente do esquema , ou seja, capaz de traduzir a linguagem do usuário em filtros, campos e metadados estruturados que de fato existem no índice. Por fim, os componentes devem trabalhar juntos de forma integrada para atender a essas restrições complexas e, por vezes, de várias camadas, sem descartar ou interpretar erroneamente nenhuma delas. Tal coordenação exige um raciocínio holístico no nível do sistema. Como demonstram nossos experimentos nas próximas duas seções, a arquitetura Instructed Retriever representa um grande avanço para habilitar essa capacidade nos fluxos de trabalho e agentes de busca.
Avaliando o seguimento de instruções na geração de queries
A maioria dos benchmarks de recuperação existentes ignora como os modelos interpretam e executam especificações de linguagem natural, principalmente aquelas que envolvem restrições estruturadas com base no esquema de índice. Portanto, para avaliar os recursos da nossa arquitetura de Instructed Retriever, estendemos o StaRK (Semi-Structured Retrieval Benchmark) dataset e criamos um novo benchmark de recuperação com acompanhamento de instruções, o StaRK-Instruct, usando seu subconjunto de e-commerce, o STaRK-Amazon.
Para nosso dataset, focamos em três tipos comuns de instruções do usuário que exigem que o modelo raciocine além da similaridade de texto simples:
- Instruções de inclusão – selecionando documentos que devem conter um determinado atributo (por exemplo, “encontre uma jaqueta da FooBrand que seja mais bem avaliada para o frio”).
- Instruções de exclusão – filtrando itens que não devem aparecer nos resultados (por exemplo, “recomende um SUV com baixo consumo de combustível, mas tive experiências negativas com a FooBrand, então evite qualquer coisa que eles fabriquem”).
- Impulso de recência – preferindo itens mais recentes quando metadados relacionados ao tempo estão disponíveis (por exemplo, “Quais notebooks FooBrand envelheceram bem? Priorize as avaliações dos últimos 2 a 3 anos—avaliações mais antigas importam menos devido a mudanças no SO”).
Para criar o StaRK-Instruct, e ao mesmo tempo poder reutilizar os julgamentos de relevância existentes do StaRK-Amazon, seguimos o trabalho anterior sobre o seguimento de instruções na recuperação de informações e sintetizamos as queries existentes em outras mais específicas, incluindo restrições adicionais que restringem as definições de relevância existentes. Os conjuntos de documentos relevantes são então filtrados programaticamente para garantir o alinhamento com as queries reescritas. Por meio desse processo, sintetizamos 81 queries do StaRK-Amazon (19,5 documentos relevantes por query) em 198 queries no StaRK-Instruct (11,7 documentos relevantes por query, entre os três tipos de instrução).
Para avaliar as capacidades de geração de query do Instructed Retriever usando o StaRK-Instruct, avaliamos os seguintes métodos (em uma configuração de recuperação em um único passo)
- Query bruta – como base de referência, usamos a consulta original do usuário para recuperação, sem nenhum estágio adicional de geração de consulta. Isso é semelhante a uma abordagem RAG tradicional.
- GPT5-nano, GPT5.2, Claude4.5-Sonnet – usamos cada um dos respectivos modelos para gerar queries de recuperação, usando as original user queries, as especificações do sistema, incluindo as instruções do usuário, e o esquema de índice.
- **InstructedRetriever-4B ** – Embora modelos de fronteira como GPT5.2 e Claude4.5-Sonnet sejam altamente eficazes, eles também podem ser muito caros para tarefas como geração de consultas e filtros, especialmente para implantações em grande escala. Portanto, aplicamos o mecanismo Test-time Adaptive Optimization (TAO), que aproveita a computação em tempo de teste e o aprendizado por reforço (RL) offline para ensinar um modelo a executar melhor uma tarefa com base em exemplos de entrada anteriores. Especificamente, usamos o subconjunto de consultas “sintetizadas”do StaRK-Amazon e geramos consultas adicionais que seguem instruções usando essas consultas sintetizadas. Usamos o recall diretamente como sinal de recompensa para fazer o ajuste fino de um modelo pequeno de 4B parâmetros, amostrando chamadas de ferramenta candidatas e reforçando aquelas que alcançam pontuações de recall mais altas.
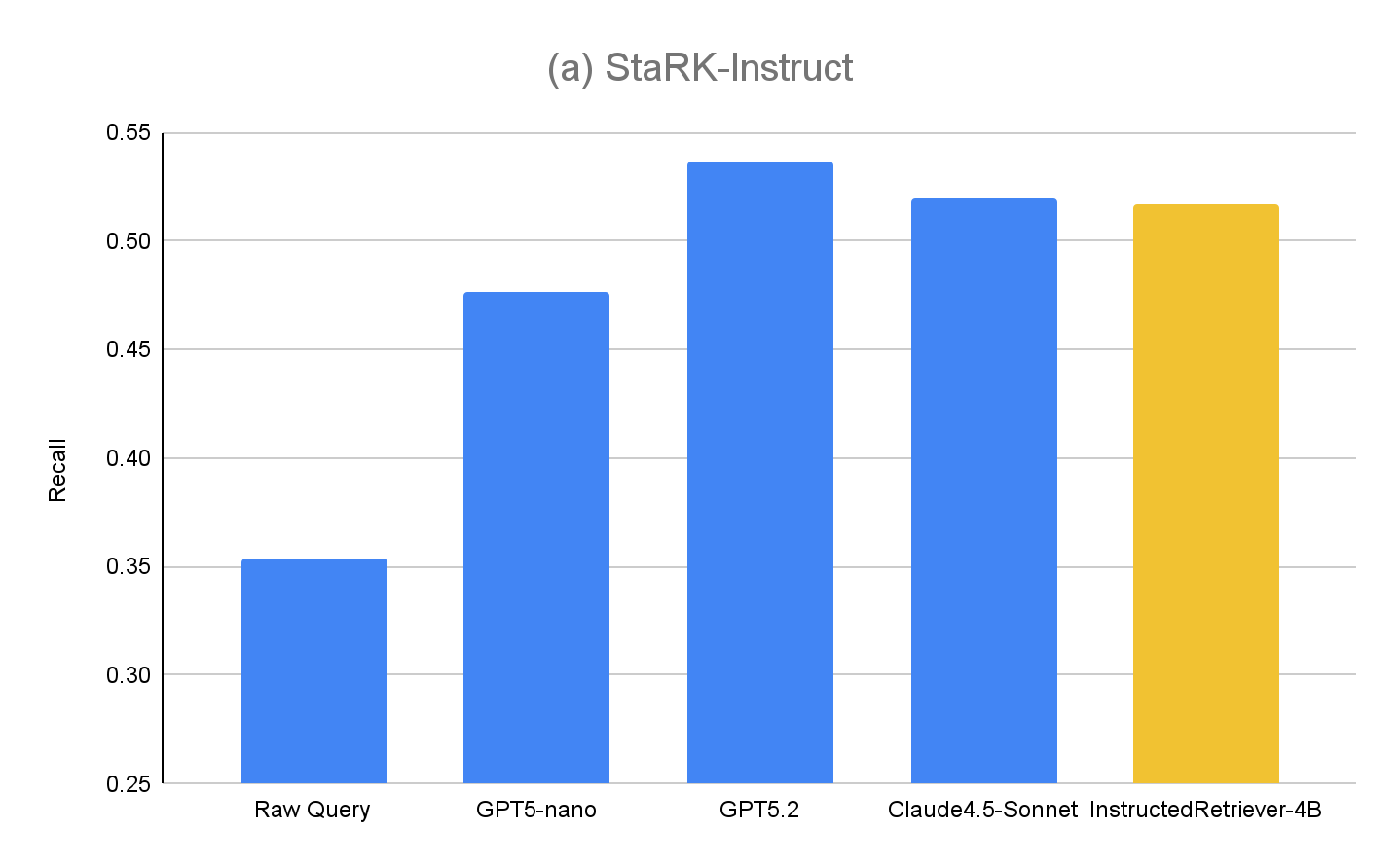
Os resultados para o StaRK-Instruct são mostrados na Figura 4(a). A geração de consulta instruída alcança um recall 35–50% maior no benchmark StaRK-Instruct em comparação com a linha de base de query bruta. Os ganhos são consistentes entre os tamanhos dos modelos, confirmando que a análise eficaz de instruções e a formulação de consultas estruturadas podem proporcionar melhorias mensuráveis mesmo com orçamentos computacionais apertados. Modelos maiores geralmente exibem ganhos ainda maiores, sugerindo a escalabilidade da abordagem com a capacidade do modelo. No entanto, nosso modelo InstructedRetriever-4B com ajuste fino quase iguala o desempenho de modelos de fronteira muito maiores e supera o desempenho do modelo GPT5-nano, demonstrando que o alinhamento pode aumentar substancialmente a eficácia do seguimento de instruções em sistemas de recuperação agênticos, mesmo com modelos menores.
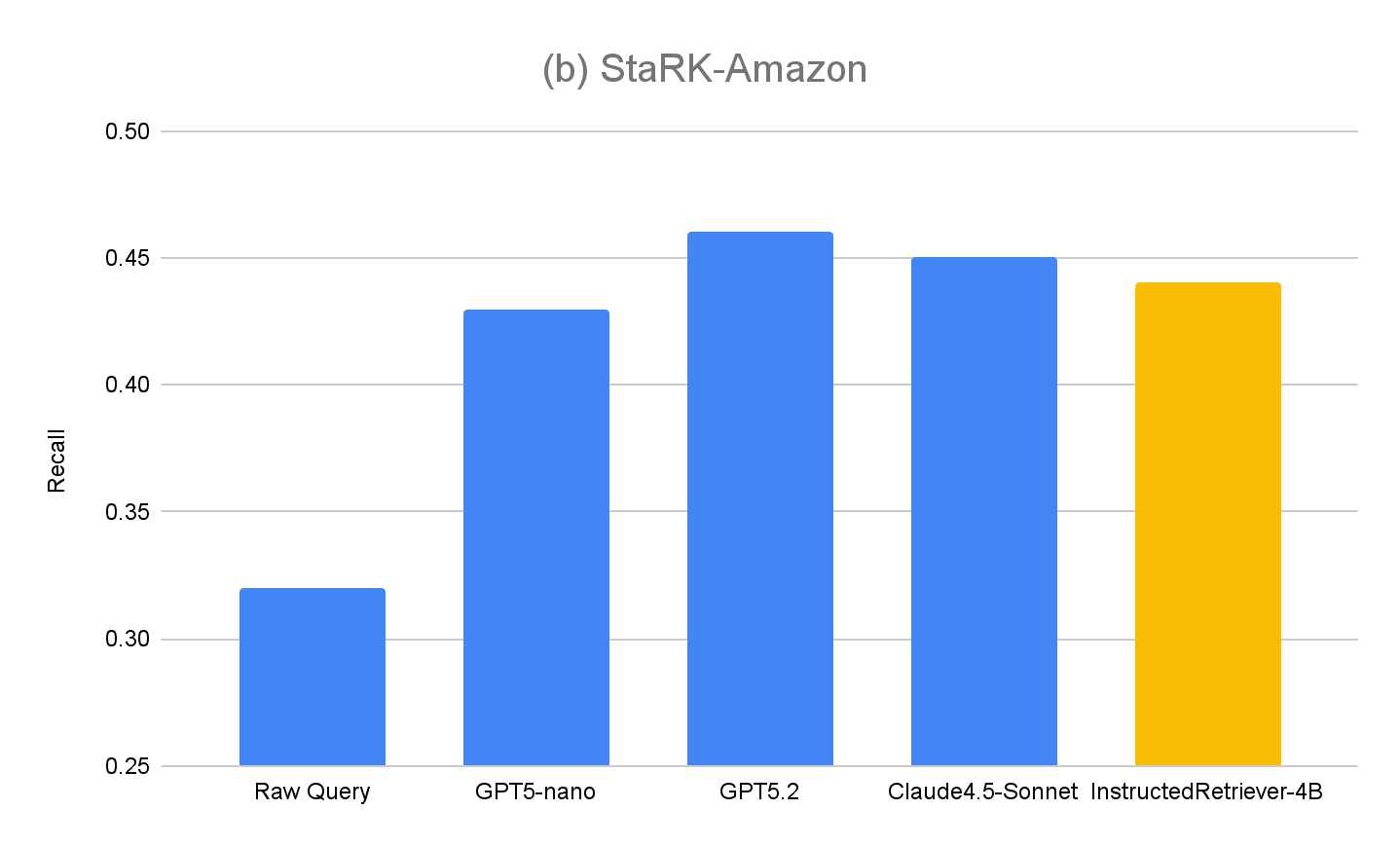
Para avaliar ainda mais a generalização da nossa abordagem, também medimos o desempenho no conjunto de avaliação original, o StaRK-Amazon, onde as consultas não têm instruções explícitas relacionadas a metadados. Conforme mostrado na Figura 4(b), todos os métodos de geração de query instruída superam o Raw Query recall no StaRK-Amazon em cerca de 10%, confirmando que o seguimento de instruções também é benéfico em cenários de geração de query não restritos. Também não vemos degradação no InstructedRetriever-4B desempenho em comparação com modelos que não passaram por ajuste fino, o que confirma que a especialização na geração de queries estruturadas não prejudica suas capacidades gerais de geração de query.
Implantando o Instructed Retriever no Agent Bricks
Na seção anterior, demonstramos os ganhos significativos na qualidade da recuperação que são alcançáveis usando a geração de query que segue instruções. Nesta seção, exploramos ainda mais a utilidade de um retriever instruído como parte de um sistema de recuperação agêntico de nível de produção. Em particular, o Instructed Retriever é implantado no Agent Bricks Knowledge Assistant, um chatbot de perguntas e respostas com o qual você pode fazer perguntas e receber respostas confiáveis com base no conhecimento especializado do domínio fornecido.
Consideramos duas soluções de RAG DIY como baselines:
- RAG Nós alimentamos os principais resultados recuperados da nossa busca vetorial de alto desempenho em um modelo de linguagem grande de ponta para geração.
- RAG + Rerank Após a etapa de recuperação, seguimos com uma etapa de reordenação, que demonstrou aumentar a precisão da recuperação em uma média de 15 pontos percentuais em testes anteriores. Os resultados reordenados são inseridos em um modelo de linguagem grande de ponta para geração.
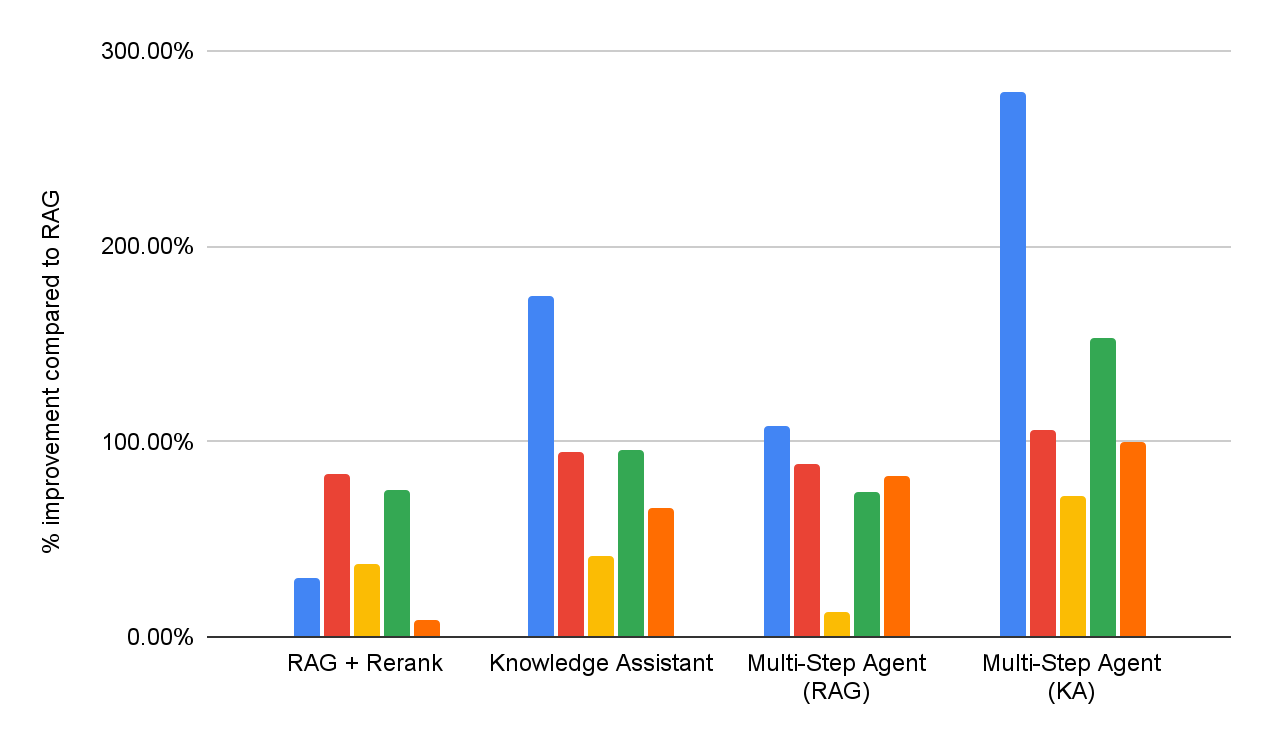
Para avaliar a eficácia das soluções DIY RAG e do Knowledge Assistant, realizamos uma avaliação da qualidade da resposta em todo o mesmo conjunto de benchmarks de perguntas e respostas empresariais, conforme relatado na Figura 1. Além disso, implementamos dois agentes multipasso que têm acesso ao RAG ou ao Knowledge Assistant como ferramenta de pesquisa, respectivamente. O desempenho detalhado de cada dataset é apresentado na Figura 5 (como uma melhoria de % em comparação com o RAG de referência).
No geral, podemos ver que todos os sistemas superam consistentemente o baseline RAG simples em todos os datasets, o que reflete sua incapacidade de interpretar e aplicar consistentemente especificações de várias partes. A adição de uma etapa de reclassificação melhora os resultados, demonstrando algum benefício da modelagem de relevância post-hoc. O Assistente de Conhecimento, implementado com a arquitetura Instructed Retriever, traz melhorias adicionais, indicando a importância de persistir as especificações do sistema – restrições, exclusões, preferências temporais e filtros de metadados – em todas as etapas de recuperação e geração.
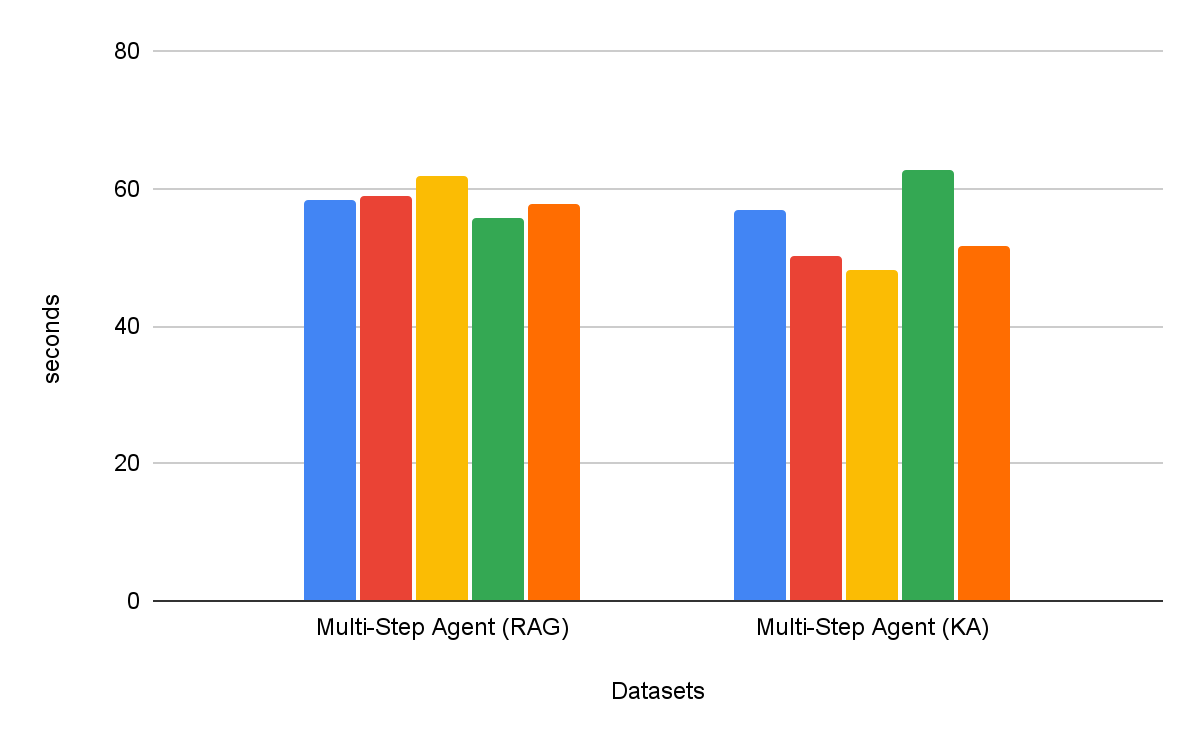
Agentes de pesquisa de várias etapas são consistentemente mais eficazes do que fluxos de trabalho de recuperação de etapa única. Além disso, a escolha da ferramenta é importante: o Knowledge Assistant como ferramenta supera o RAG como ferramenta em mais de 30%, com uma melhoria consistente em todos os datasets. Curiosamente, ele não apenas melhora a qualidade, mas também alcança um menor tempo para a conclusão da tarefa na maioria dos datasets, com uma redução média de 8% (Figura 6).
Conclusão
A criação de agentes empresariais confiáveis requer um seguimento de instruções abrangente e raciocínio em nível de sistema ao recuperar de fontes de conhecimento heterogêneas. Para este fim, neste blog, apresentamos a arquitetura Instructed Retriever, com a inovação principal de propagar especificações completas do sistema — de instruções a exemplos e esquema de índice — por todas as fases do pipeline de busca.
Também apresentamos um novo dataset StaRK-Instruct, que avalia a capacidade de um agente de recuperação de lidar com instruções do mundo real, como inclusão, exclusão e recência. Neste benchmark, a arquitetura do Instructed Retriever proporcionou ganhos substanciais de 35-50% no recall de recuperação, demonstrando empiricamente os benefícios de uma conscientização de instruções em todo o sistema para a geração de queries. Também mostramos que um modelo pequeno e eficiente pode ser otimizado para igualar o desempenho de modelos proprietários maiores no seguimento de instruções, tornando o Instructed Retriever uma arquitetura agêntica de bom custo-benefício, adequada para implantações empresariais no mundo real.
Quando integrada a um Agent Bricks Knowledge Assistant, a arquitetura Instructed Retriever se traduz diretamente em respostas de maior qualidade e mais precisas para o usuário final. Em nosso abrangente conjunto de benchmarks de alta dificuldade, ela proporciona ganhos superiores a 70% em comparação com uma solução RAG simplista, e um ganho de qualidade superior a 15% em comparação com soluções DIY mais sofisticadas que incorporam reranking. Além disso, quando integrado como uma ferramenta para um agente de busca de várias etapas, o Instructed Retriever pode não apenas aumentar o desempenho em mais de 30%, mas também diminuir o tempo para a conclusão da tarefa em 8%, em comparação com o RAG como ferramenta.
O Instructed Retriever, juntamente com muitas inovações publicadas anteriormente, como otimização de prompt, ALHF, TAO e RLVR, já está disponível no produto Agent Bricks. O princípio fundamental do Agent Bricks é ajudar as empresas a desenvolver agentes que raciocinam com precisão sobre seus dados proprietários, aprendem continuamente com o feedback e alcançam qualidade de ponta e eficiência de custos em tarefas específicas de domínio. Incentivamos os clientes a experimentar o Assistente de Conhecimento e outros produtos Agent Bricks para construir agentes direcionáveis e eficazes para seus próprios casos de uso empresariais.
Autores: Cindy Wang, Andrew Drozdov, Michael Bendersky, Wen Sun, Owen Oertell, Jonathan Chang, Jonathan Frankle, Xing Chen, Matei Zaharia, Elise Gonzales, Xiangrui Meng
1 Nossa suíte contém uma mistura de cinco benchmarks proprietários e acadêmicos que testam os seguintes recursos: seguimento de instruções, pesquisa específica de domínio, geração de relatórios, geração de listas e pesquisa em PDFs com disposições complexas. Cada benchmark está associado a um avaliador de qualidade personalizado, com base no tipo de resposta.
2 As descrições de índice podem ser incluídas na instrução especificada pelo usuário ou construídas automaticamente por meio de métodos de vinculação de esquema que são frequentemente empregados em sistemas para text-to-SQL, por exemplo, recuperação de valor.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.