Do Caos ao Controle: Uma Jornada de Maturidade de Custos com Databricks
Use um processo estruturado para avaliar a maturidade do controle de custos do Databricks, identificar padrões de uso, impor orçamentos, otimizar cargas de trabalho e reduzir gastos desnecessários.
por Zach King e Rajneesh Arora
- As organizações enfrentam pressão crescente para equilibrar os custos de nuvem e plataforma com a alta demanda por cargas de trabalho intensivas em dados e IA.
- Databricks fornece controles eficientes de gerenciamento de custos para apoiar a maturidade incremental entre as equipes de FinOps, alinhando-se com as crenças fundamentais de FinOps do padrão da indústria.
- Este blog fornece orientação de implementação para alocação de custos, controle e otimizações na Databricks para ambientes de produção.
Introdução: A Importância do FinOps em Ambientes de Dados e IA
Empresas de todos os setores continuam a priorizar a otimização e o valor de fazer mais com menos. Isso é especialmente verdade para empresas nativas digitais na paisagem de dados de hoje, que geram uma demanda cada vez maior por IA e cargas de trabalho intensivas em dados. Essas organizações gerenciam milhares de recursos em vários ambientes de nuvem e plataforma. Para inovar e iterar rapidamente, muitos desses recursos são democratizados entre equipes ou unidades de negócios; no entanto, uma maior velocidade para os profissionais de dados pode levar ao caos, a menos que seja equilibrada com um cuidadoso gerenciamento de custos.
Organizações nativas digitais frequentemente empregam equipes de plataforma central, DevOps ou FinOps para supervisionar os custos e controles para recursos de nuvem e plataforma. A prática formal de controle de custos e supervisão, popularizada pela The FinOps Foundation™, também é suportada pela Databricks com recursos como marcação, orçamentos, políticas de computação e mais. No entanto, a decisão de priorizar a gestão de custos e estabelecer uma propriedade estruturada não cria maturidade de custos da noite para o dia. As metodologias e recursos abordados neste blog permitem que as equipes amadureçam incrementalmente a gestão de custos dentro da Plataforma de Inteligência de Dados.
O que vamos abordar:
- Atribuição de Custos: Revisando as principais considerações para alocar custos com políticas de marcação e orçamento.
- Relatório de Custos: Monitorando custos com os painéis de AI/BI da Databricks.
- Controle de Custos: Aplicando automaticamente controles de custos com Terraform, Políticas de Computação e Pacotes de Ativos Databricks.
- Otimização de Custos: Itens comuns na lista de otimizações do Databricks.
Se você é um engenheiro, arquiteto ou profissional de FinOps, este blog ajudará você a maximizar a eficiência minimizando os custos, garantindo que seu ambiente Databricks permaneça de alto desempenho e custo-efetivo.
Desmembramento da Solução Técnica
Agora, adotaremos uma abordagem incremental para implementar práticas maduras de gerenciamento de custos na Plataforma Databricks. Pense nisso como a jornada "Rastejar, Andar, Correr" para ir do caos ao controle. Explicaremos como implementar essa jornada passo a passo.
Passo 1: Atribuição de Custo
O primeiro passo é atribuir corretamente as despesas às equipes, projetos ou cargas de trabalho certas. Isso envolve a marcação eficiente de todos os recursos (incluindo computação sem servidor) para obter uma visão clara de onde os custos estão sendo incorridos. A atribuição correta permite um orçamento preciso e responsabilidade entre as equipes.
A atribuição de custos pode ser feita para todos os SKUs de computação com uma estratégia de marcação, seja para um modelo de computação clássico ou sem servidor. A computação clássica (fluxos de trabalho, Pipelines Declarativas, SQL Warehouse, etc.) herda as tags na definição do cluster, enquanto a sem servidor adere às Políticas de Orçamento Sem Servidor (AWS | Azure | GCP).
Em geral, você pode adicionar tags a dois tipos de recursos:
- Recursos de Computação: Inclui SQL Warehouse, jobs, pools de instâncias, etc.
- Unity Catalog Securables: Inclui catálogo, esquema, tabela, visualização, etc.
A marcação para ambos os tipos de recursos contribuiria para uma governança e gestão eficazes:
- A marcação dos recursos de computação tem um impacto direto na gestão de custos.
- A marcação de securáveis do Catálogo Unity ajuda na organização e busca desses objetos, mas isso está fora do escopo deste blog.
Consulte este artigo (AWS | AZURE | GCP) para detalhes sobre a marcação de diferentes recursos de computação, e este artigo (AWS | Azure | GCP) para detalhes sobre a marcação de securáveis do Catálogo Unity.
Marcação de Computação Clássica
Para computação clássica, as tags podem ser especificadas nas configurações ao criar a computação. Abaixo estão alguns exemplos de diferentes tipos de cálculos para mostrar como as tags podem ser definidas para cada um, usando tanto a interface do usuário quanto o SDK do Databricks.
Computação SQL Warehouse:
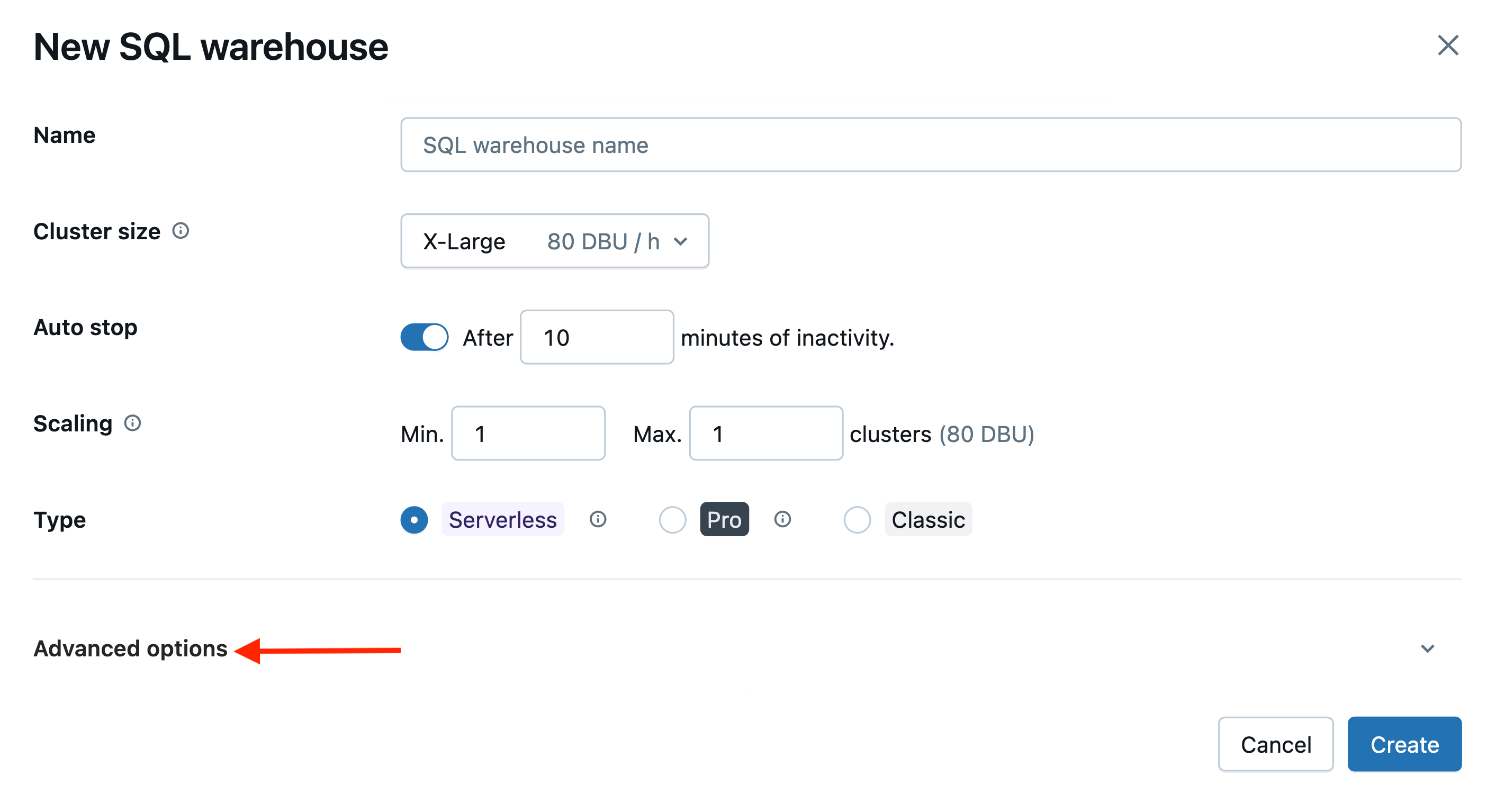
Você pode definir as tags para um Armazém SQL na seção Opções Avançadas.
Com Databricks SDK:
Compute All-Purpose
Com Databricks SDK:
Computação de Jobs:
Com Databricks SDK:
Pipelines Declarativos:
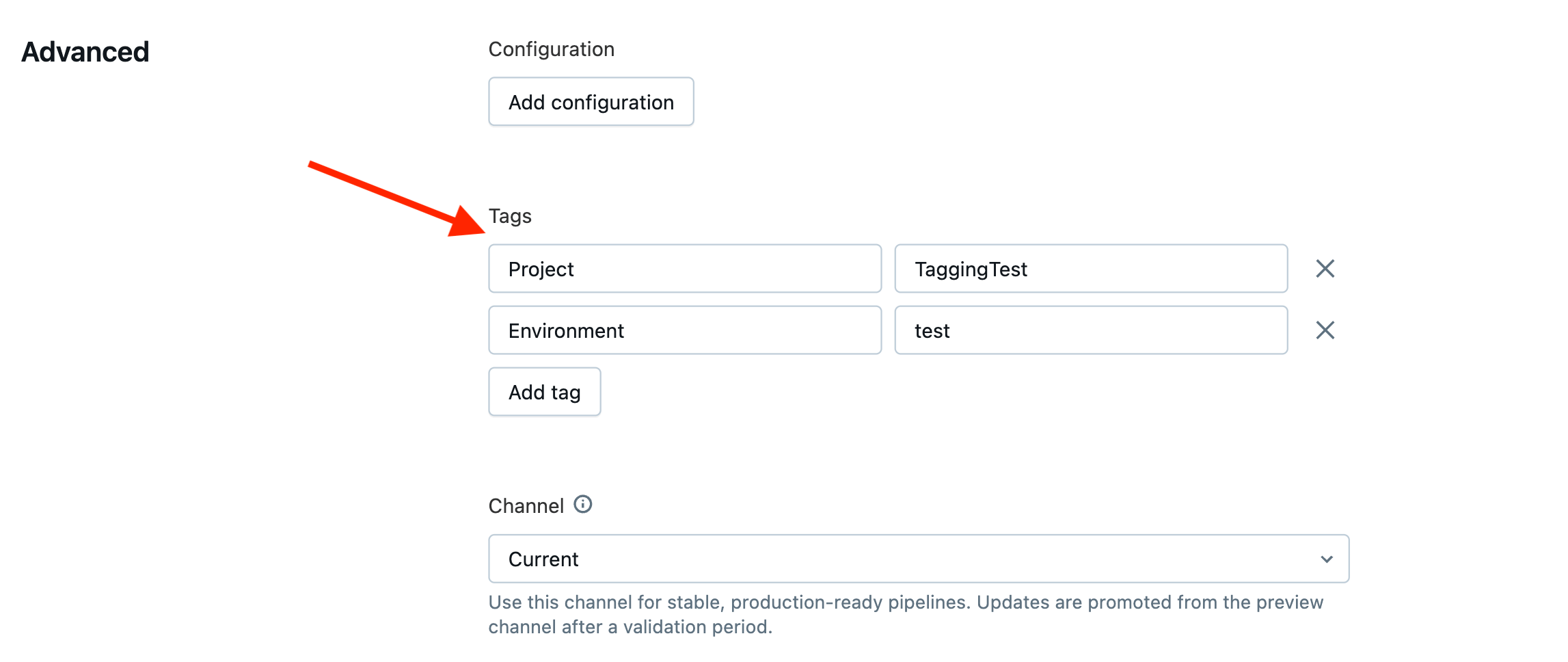
Marcação de Computação Serverless
Para computação sem servidor, você deve atribuir tags com uma política de orçamento. Criar uma política permite que você especifique um nome de política e tags de chaves e valores em string.
É um processo de 3 etapas:
- Etapa 1: Crie uma política de orçamento (os administradores do Workspace podem criar uma, e os usuários com acesso de gerenciamento podem gerenciá-las)
- Etapa 2: Atribua a Política de Orçamento aos usuários, grupos e principais de serviço
- Etapa 3: Uma vez que a política é atribuída, o usuário é obrigado a selecionar uma política ao usar a computação sem servidor. Se o usuário tiver apenas uma política atribuída, essa política é selecionada automaticamente. Se o usuário tiver várias políticas atribuídas, ele tem a opção de escolher uma delas.
Você pode se referir a detalhes sobre Políticas de Orçamento sem servidor (BP) nestes artigos (AWS/AZURE/GCP).
Alguns aspectos a ter em mente sobre Políticas de Orçamento:
- Uma Política de Orçamento é muito diferente de Orçamentos (AWS | Azure | GCP). Vamos abordar Orçamentos na Etapa 2: Relatório de Custos.
- As Políticas de Orçamento existem no nível da conta, mas podem ser criadas e gerenciadas a partir de um espaço de trabalho. Os administradores podem restringir a quais espaços de trabalho uma política se aplica, vinculando-a a espaços de trabalho específicos.
- Uma Política de Orçamento só se aplica a cargas de trabalho sem servidor. Atualmente, no momento da escrita deste blog, ela se aplica a notebooks, jobs, pipelines, pontos de serviço, aplicativos e pontos de pesquisa de vetor.
- Vamos pegar um exemplo de trabalhos que têm algumas tarefas. Cada tarefa pode ter seu próprio cálculo, enquanto as tags BP são atribuídas no nível do trabalho (e não no nível da tarefa). Portanto, existe a possibilidade de uma tarefa ser executada em serverless enquanto a outra é executada em um computador não serverless geral. Vamos ver como as tags da Política de Orçamento se comportariam nos seguintes cenários:
- Caso 1: Ambas as tarefas são executadas em serverless
- Neste caso, as tags BP se propagariam para as tabelas do sistema.
- Caso 2: Apenas uma tarefa é executada em serverless
- Neste caso, as tags BP também se propagariam para tabelas de sistema para o uso de computação sem servidor, enquanto o registro de faturamento de computação clássica herda tags da definição do cluster.
- Caso 3: Ambas as tarefas são executadas em computação não sem servidor
- Neste caso, as tags BP não se propagariam para as tabelas do sistema.
- Caso 1: Ambas as tarefas são executadas em serverless
Com Terraform:
Melhores Práticas Relacionadas a Tags:

- É recomendado que todos apliquem Chaves Gerais, e para organizações que desejam insights mais granulares, elas devem aplicar chaves de alta especificidade que são adequadas para sua organização.
- Uma política de negócios deve ser desenvolvida e compartilhada entre todos os usuários em relação às chaves e valores fixos que você deseja impor em toda a sua organização. No Passo 4, veremos como as Políticas de Computação são usadas para controlar sistematicamente os valores permitidos para tags e exigir tags nos lugares certos.
- As tags diferenciam maiúsculas de minúsculas. Use estilos de caixa consistentes e legíveis, como Title Case, PascalCase ou kebab-case.
- Para conformidade inicial de marcação, considere construir um trabalho agendado que consulta tags e relata quaisquer desalinhamentos com a política da sua organização.
- É recomendado que cada usuário tenha permissão para pelo menos uma política de orçamento. Dessa forma, sempre que o usuário cria um notebook/trabalho/pipeline/etc., usando computação sem servidor, a BP atribuída é aplicada automaticamente.
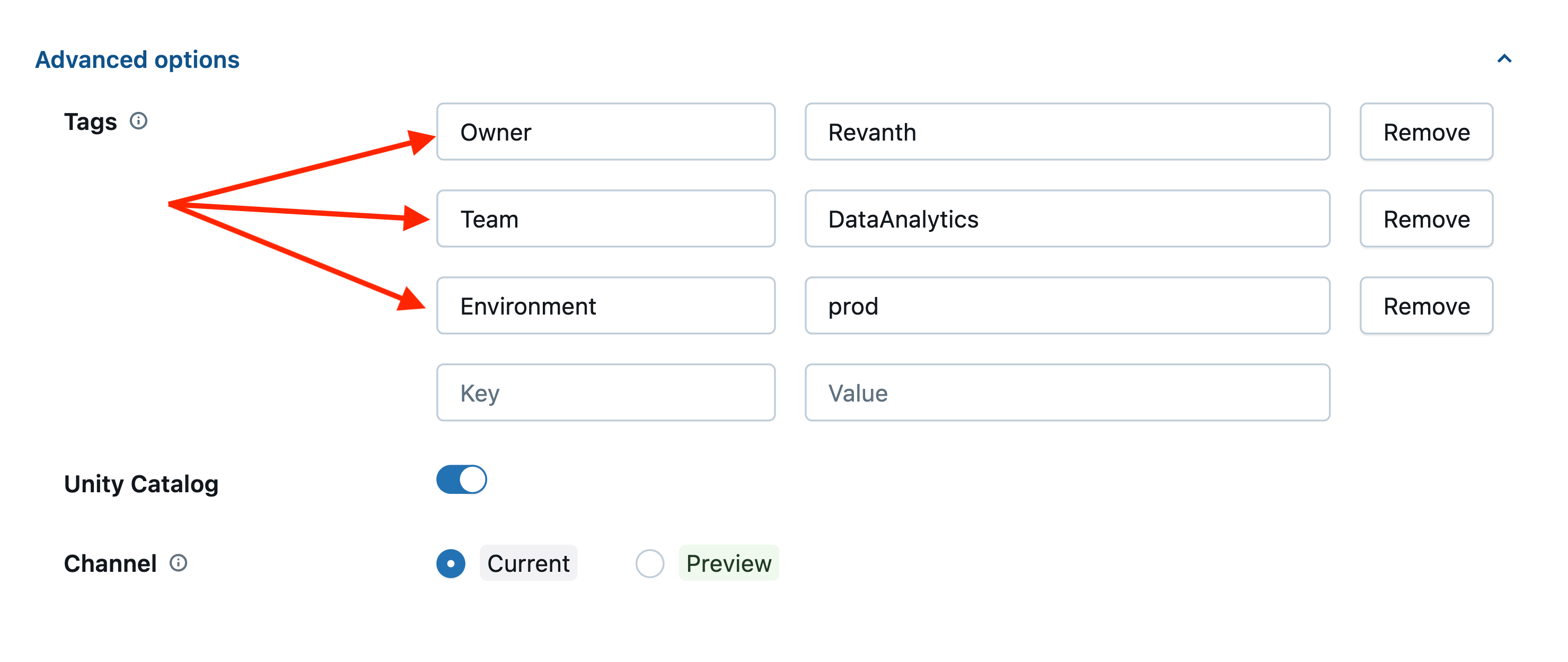
Exemplo de Tag - Pares Chave: Valor
Passo 2: Relatório de Custos
Tabelas do sistema
A seguir, temos o relatório de custos, ou a capacidade de monitorar custos com o contexto fornecido pela Etapa 1. A Databricks fornece tabelas de sistema integradas, como system.billing.usage, que é a base para o relatório de custos. As tabelas de sistema também são úteis quando os clientes desejam personalizar sua solução de relatório.
Por exemplo, o painel de uso da conta que você verá a seguir é um painel de AI/BI do Databricks, então você pode visualizar todas as consultas e personalizar o painel para atender às suas necessidades facilmente. Se você precisa escrever consultas ad hoc contra seu uso do Databricks, com filtros muito específicos, isso está à sua disposição.
O Painel de Uso da Conta
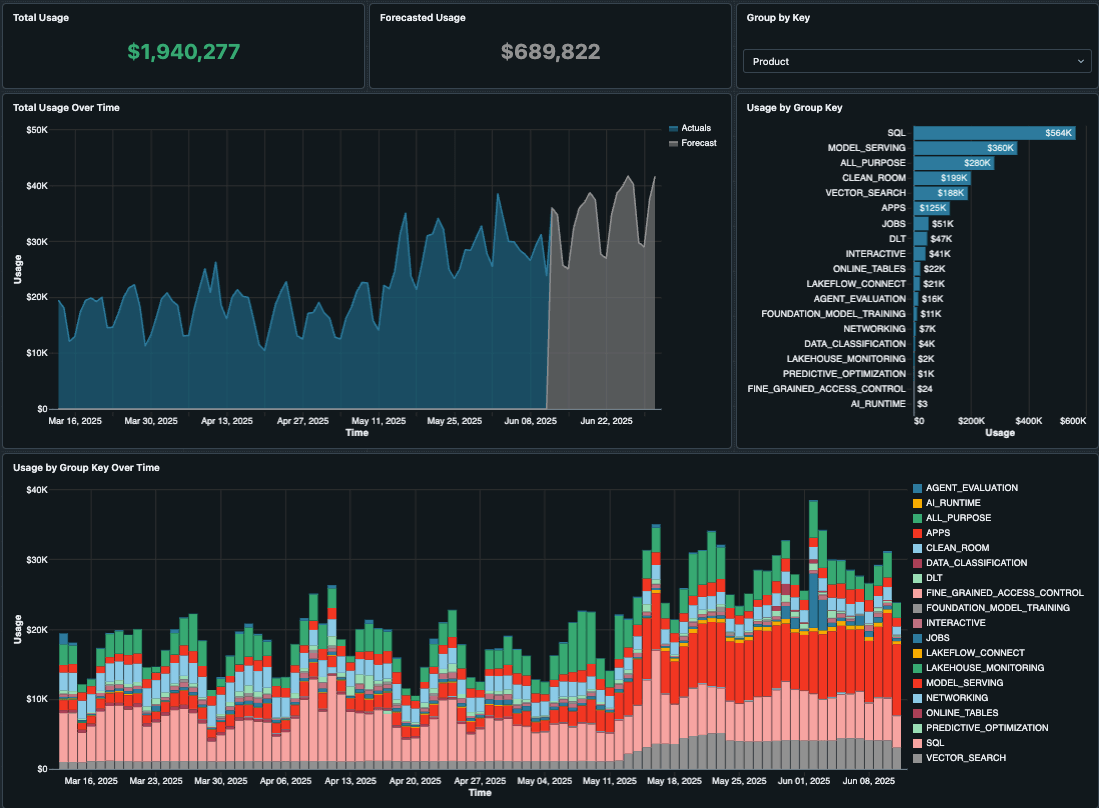
Uma vez que você começou a marcar seus recursos e atribuir custos aos seus centros de custo, equipes, projetos ou ambientes, você pode começar a descobrir as áreas onde os custos são mais altos. Databricks fornece um Painel de Uso que você pode simplesmente importar para o seu próprio espaço de trabalho como um painel de AI/BI, fornecendo relatórios de custos imediatos.
Uma nova versão versão 2.0 deste painel está disponível para visualização com várias melhorias mostradas abaixo. Mesmo que você já tenha importado o painel de uso da conta, por favor, importe a nova versão do GitHub hoje!
Este painel fornece uma tonelada de informações úteis e visualizações, incluindo dados como:
- Visão geral do uso, destacando as tendências totais de uso ao longo do tempo e por grupos como SKUs e workspaces.
- Top N de uso que classifica o uso superior por objetos faturáveis selecionados, como job_id, warehouse_id, cluster_id, endpoint_id, etc.
- Análise de uso baseada em tags (quanto mais marcação você fizer na Etapa 1, mais útil será).
- Previsões de IA que indicam o que serão seus gastos nas próximas semanas e meses.
O painel também permite que você filtre por intervalos de datas, espaços de trabalho, produtos e até insira descontos personalizados para taxas privadas. Com tanto conteúdo neste painel, ele realmente é sua principal parada única para a maioria de suas necessidades de relatórios de custos.
Painel de Monitoramento de Trabalhos
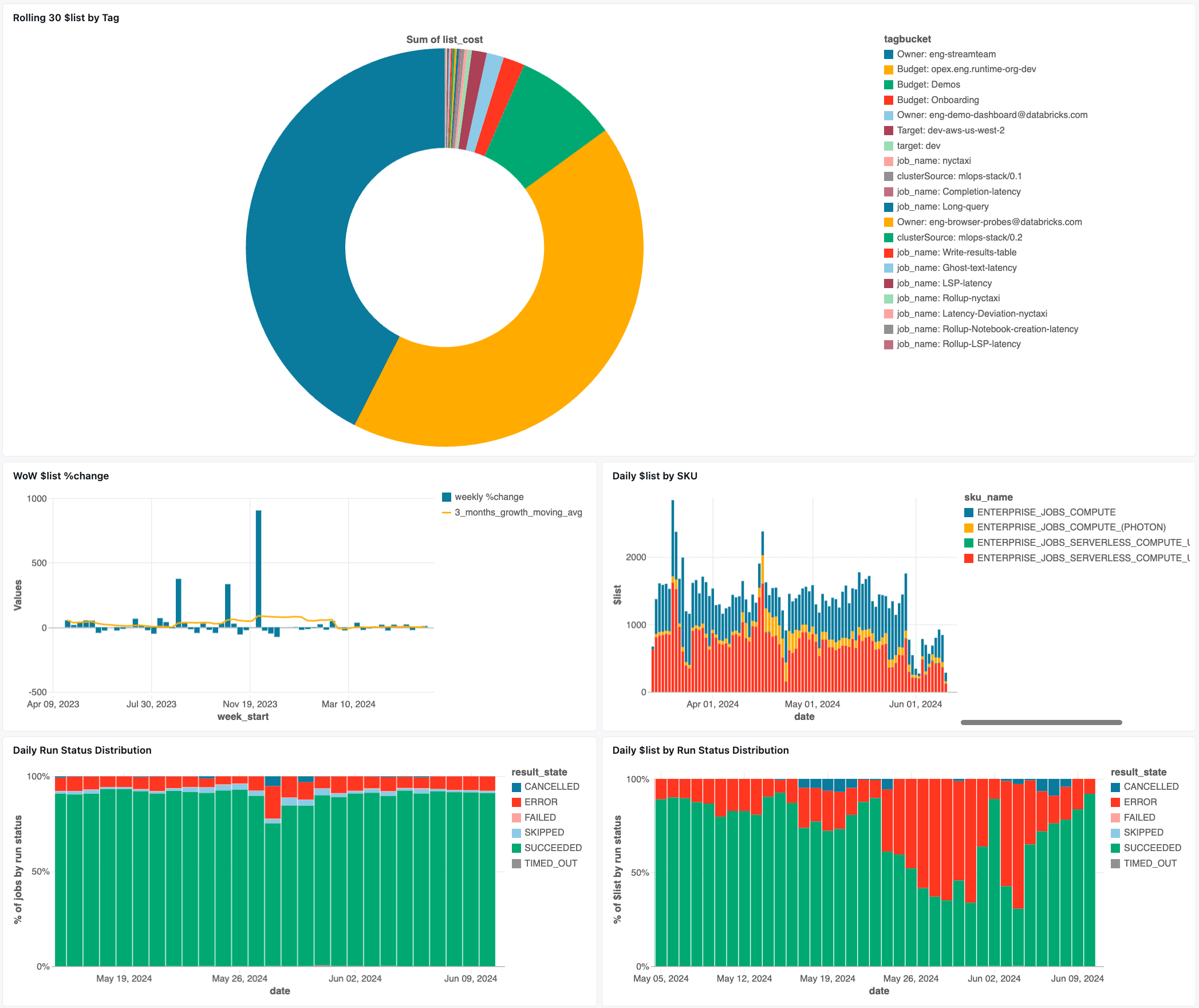
Para trabalhos Lakeflow, recomendamos o Painel de AI/BI de Tabelas de Sistema de Trabalhos para ver rapidamente os custos potenciais baseados em recursos, bem como oportunidades de otimização, como:
- Top 25 Empregos por Economia Potencial por Mês
- Top 10 Jobs com Menor Utilização Média de CPU
- Top 10 Jobs com Maior Utilização Média de Memória
- Trabalhos com Número Fixo de Trabalhadores Últimos 30 Dias
- Trabalhos Executados em Versão DBR Desatualizada Últimos 30 Dias
Monitoramento DBSQL
Para um monitoramento aprimorado do Databricks SQL, consulte nosso blog de especialistas em SQL aqui. Neste guia, nossos especialistas em SQL irão guiá-lo através do painel de Monitoramento de Custos Granular que você pode configurar hoje para ver os custos do SQL por usuário, fonte e até custos por consulta.
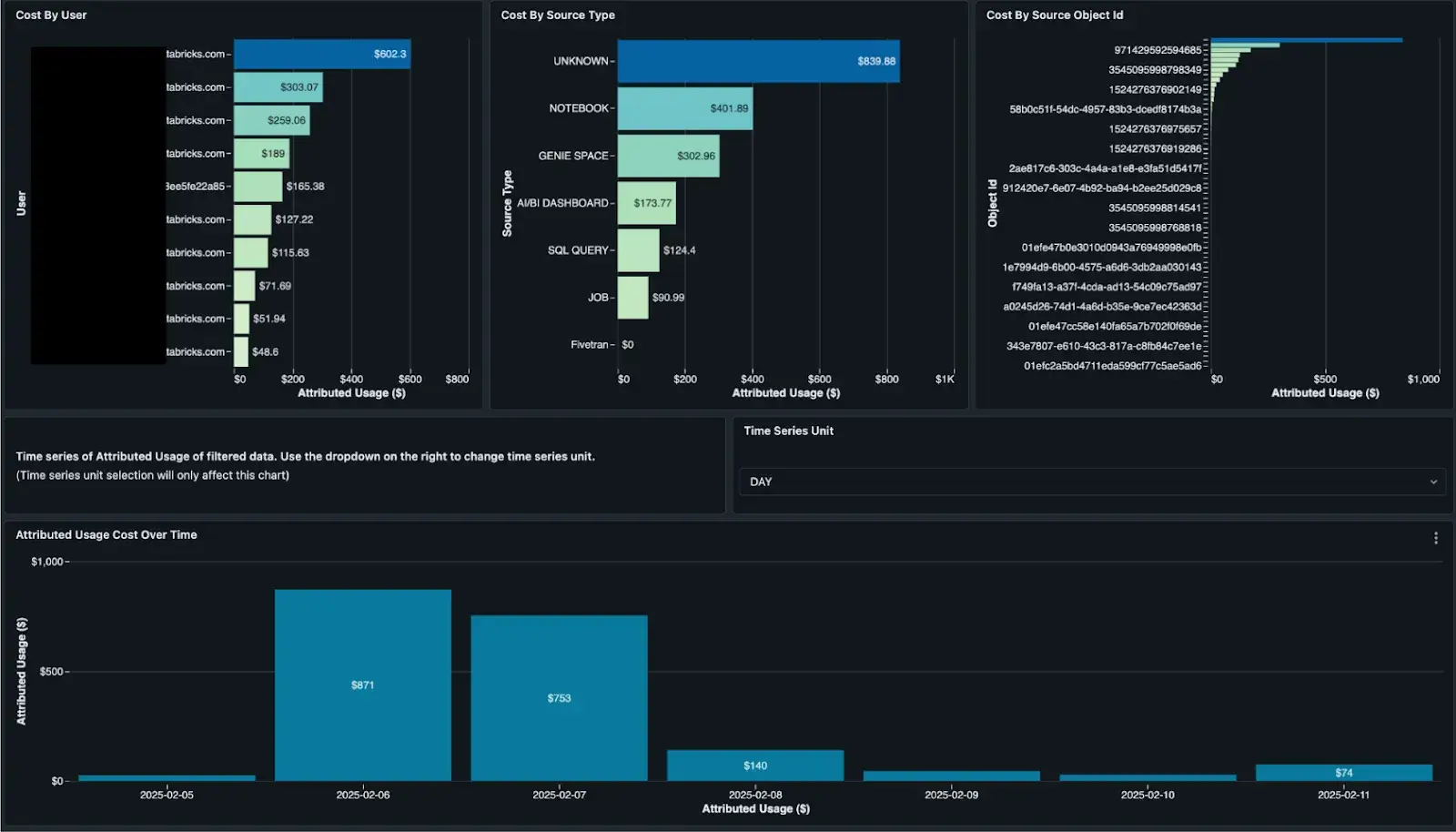
Servindo modelo
Da mesma forma, temos um painel especializado para monitorar o custo do Model Serving! Isso é útil para relatórios mais granulares sobre inferência em lote, uso por token, pontos de acesso provisionados e mais. Para mais informações, veja este blog relacionado.
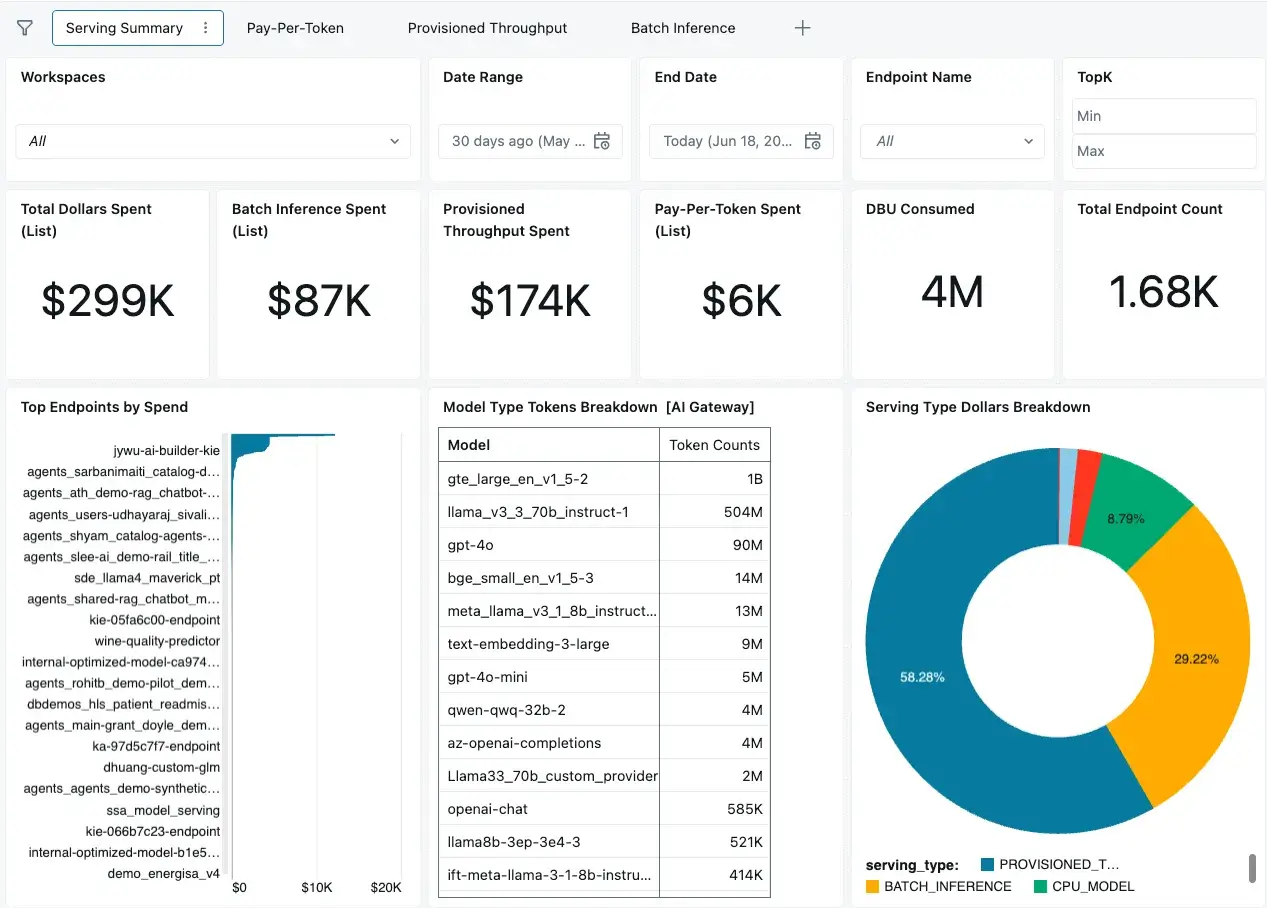
Alertas de Orçamento
Falamos sobre Políticas de Orçamento Sem Servidor anteriormente como uma maneira de atribuir ou marcar o uso de computação sem servidor, mas o Databricks também tem apenas um Orçamento (AWS | Azure | GCP), que é um recurso separado. Os orçamentos podem ser usados para rastrear gastos em toda a conta, ou aplicar filtros para rastrear os gastos de equipes, projetos ou espaços de trabalho específicos.
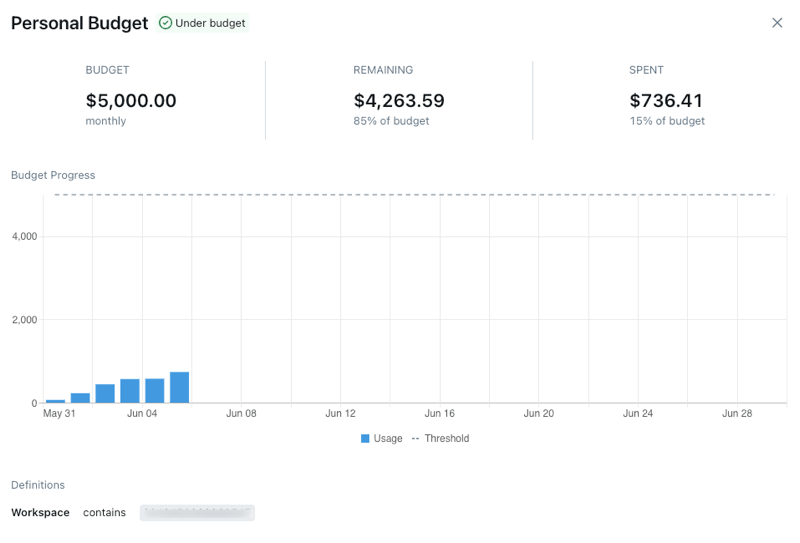
Com orçamentos, você especifica os espaços de trabalho e/ou tags que deseja que o orçamento corresponda, em seguida, define um valor (em USD), e você pode fazer com que ele envie um e-mail para uma lista de destinatários quando o orçamento for excedido. Isso pode ser útil para alertar reativamente os usuários quando seus gastos excederem um determinado valor. Por favor, note que os orçamentos usam o preço de lista do SKU.
Passo 3: Controles de Custos
Em seguida, as equipes devem ter a capacidade de estabelecer limites para que as equipes de dados sejam autossuficientes e conscientes dos custos ao mesmo tempo. Databricks simplifica isso para administradores e profissionais com Políticas de Computação (AWS | Azure | GCP).
Vários atributos podem ser controlados com políticas de computação, incluindo todos os atributos do cluster, bem como atributos virtuais importantes, como dbu_per_user. Vamos revisar alguns dos principais atributos para governar especificamente para o controle de custos:
Limitando DBU Por Usuário e Máximo de Clusters Por Usuário
Muitas vezes, ao criar políticas de computação para permitir a criação de clusters de autoatendimento para equipes, queremos controlar o gasto máximo desses usuários. Aqui é onde se aplica um dos atributos de política mais importantes para o controle de custos: dbus_per_hour.
dbus_per_hour pode ser usado com um tipo de política range para definir limites inferior e superior no custo DBU dos clusters que os usuários podem criar. No entanto, isso só impõe o máximo de DBU por cluster que usa a política, então um único usuário com permissão para esta política ainda poderia criar muitos clusters, e cada um é limitado ao DBU especificado.
Para levar isso adiante, e prevenir um número ilimitado de clusters sendo criados por cada usuário, podemos usar outra configuração, max_clusters_by_user, que é na verdade uma configuração na política de computação de nível superior em vez de um atributo que você encontraria na definição da política.
Controle Clusters All-Purpose vs. Job
As políticas devem impor qual tipo de cluster pode ser usado, usando o atributo virtual cluster_type, que pode ser um dos seguintes: “all-purpose”, “job”, ou “dlt”. Recomendamos o uso do tipo fixed para impor exatamente o tipo de cluster que a política foi projetada para quando a escrever:
Um padrão comum é criar políticas separadas para jobs e pipelines versus clusters de propósito geral, definindo max_clusters_by_user como 1 para clusters de propósito geral (por exemplo, como a política padrão do Databricks Personal Compute é definida) e permitindo um número maior de clusters por usuário para jobs.
Impor Tipos de Instância
Os tipos de instância VM podem ser convenientemente controlados com allowlist ou tipo regex. Isso permite aos usuários criar clusters com alguma flexibilidade no tipo de instância sem poder escolher tamanhos que possam ser muito caros ou fora do seu orçamento.
Aplicar Últimas Runtimes Databricks
É importante manter-se atualizado com os novos Runtimes do Databricks (DBRs), e para períodos de suporte estendidos, considere as versões de Suporte de Longo Prazo (LTS). As políticas de computação têm vários valores especiais para aplicar facilmente isso no atributo spark_version, e aqui estão apenas alguns deles para você estar ciente:
auto:latest-lts:Mapeia para a versão mais recente de suporte de longo prazo (LTS) do Databricks Runtime.auto:latest-lts-ml:Mapeia para a última versão LTS do Databricks Runtime ML.- Ou
auto:latesteauto:latest-mlpara a última versão do Databricks runtime disponível geralmente (ou ML, respectivamente), que pode não ser LTS.- Nota: Essas opções podem ser úteis se você precisar de acesso aos recursos mais recentes antes de chegarem ao LTS.
Recomendamos controlar o spark_version em sua política usando um tipo allowlist:
Instâncias Spot
Os atributos da nuvem também podem ser controlados na política, como a imposição da disponibilidade de instâncias spot com fallback para on-demand. Note que sempre que usar instâncias spot, você deve sempre configurar o “first_on_demand” para pelo menos 1, para que o nó driver do cluster esteja sempre sob demanda.
No AWS:
No Azure:
No GCP (nota: o GCP atualmente não pode suportar o atributo first_on_demand):
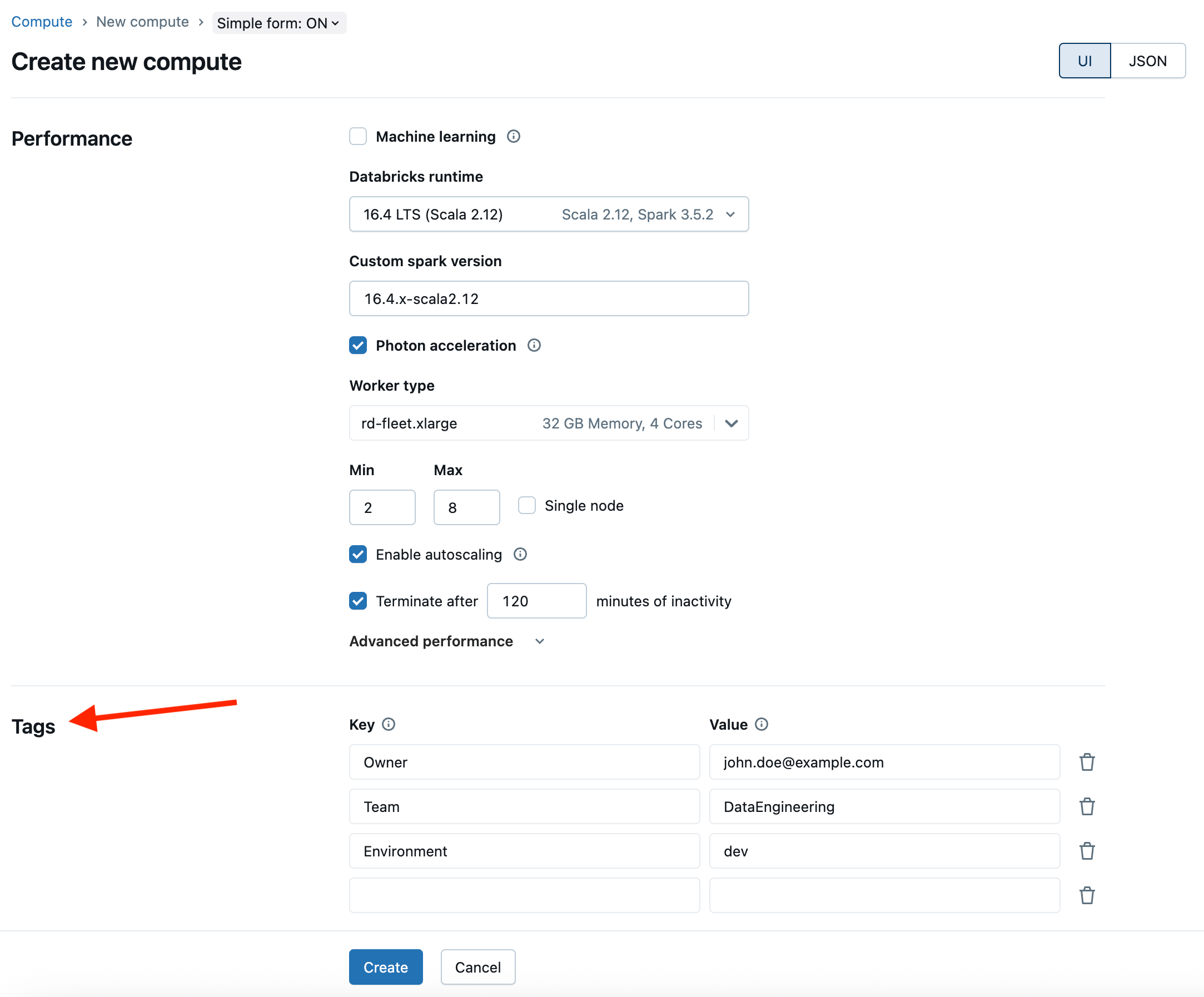
Impor Marcação
Como visto anteriormente, tagging é crucial para a capacidade de uma organização de alocar custos e reportá-los em níveis granulares. Há duas coisas a considerar ao impor tags consistentes no Databricks:
- Política de computação controlando os
custom_tags.atributo. - Para serverless, use Políticas de Orçamento Serverless Budget Policies como discutimos na Etapa 1.
Na política de computação, podemos controlar várias tags personalizadas adicionando-as com o nome da tag. É recomendado usar o máximo de tags fixas possível para reduzir a entrada manual dos usuários, mas a lista de permissões é excelente para permitir várias escolhas, mantendo os valores consistentes.
Tempo Limite de Consulta para Armazéns
Consultas SQL de longa duração podem ser muito caras e até interromper outras consultas se muitas começarem a se acumular. Consultas SQL de longa duração geralmente são devido a consultas não otimizadas (filtros ruins ou mesmo sem filtros) ou tabelas não otimizadas.
Os administradores podem controlar isso configurando o Tempo Limite de Declaração no nível do workspace. Para definir um tempo limite no nível do workspace, vá para as configurações de administração do workspace, clique em Compute, depois clique em Gerenciar ao lado de armazéns SQL. Na configuração de Parâmetros de Configuração SQL, adicione um parâmetro de configuração onde o valor do tempo limite está em segundos.
Limites de Taxa do Modelo
Modelos de ML e LLMs também podem ser abusados com muitas solicitações, incorrendo em custos inesperados. Databricks fornece rastreamento de uso e limites de taxa com um fácil de usar AI Gateway em pontos de serviço de modelo.
Você pode definir limites de taxa no endpoint como um todo, ou por usuário. Isso pode ser configurado com a interface de usuário do Databricks, SDK, API, ou Terraform; por exemplo, podemos implantar um endpoint do Modelo de Fundação com um limite de taxa usando Terraform:
Exemplos Práticos de Política de Computação
Para mais exemplos de políticas de computação do mundo real, veja nosso Acelerador de Soluções aqui: https://github.com/databricks-industry-solutions/cluster-policy
Etapa 4: Otimização de Custos
Por fim, vamos olhar para algumas das otimizações que você pode verificar em seu espaço de trabalho, clusters e camadas de armazenamento. A maioria dessas verificações pode ser feita e/ou implementada automaticamente, o que exploraremos. Várias otimizações ocorrem no nível de computação. Estas incluem ações como dimensionar corretamente o tipo de instância VM, saber quando usar o Photon ou não, seleção apropriada do tipo de computação e mais.
Escolhendo Recursos Ótimos
- Use a computação de trabalho em vez de all-purpose (vamos abordar isso mais a fundo a seguir).
- Use armazéns SQL para cargas de trabalho apenas SQL para a melhor eficiência de custo.
- Use runtimes atualizados para receber os patches mais recentes e melhorias de desempenho. Por exemplo, o DBR 17.0 dá o salto para o Spark 4.0 (Blog) que inclui muitas otimizações de desempenho.
- Use Serverless para inicialização mais rápida, término e melhor custo total de propriedade (TCO).
- Use trabalhadores de autoescala, a menos que esteja usando streaming contínuo ou o gatilho AvailableNow.
- Escolha o tipo de instância VM correto:
- Os tipos de instância de geração mais recente e as arquiteturas de processador modernas geralmente apresentam melhor desempenho e muitas vezes a um custo menor. Por exemplo, no AWS, o Databricks prefere VMs habilitadas para Graviton (por exemplo, c7g.xlarge em vez de c7i.xlarge); estes podem render até 3x melhor preço-desempenho (Blog).
- Otimizado para memória para a maioria das cargas de trabalho de ML. Por exemplo, r7g.2xlarge
- Otimizado para computação para cargas de trabalho de streaming. Por exemplo, c6i.4xlarge
- Otimizado para armazenamento para cargas de trabalho que se beneficiam do cache de disco (análise de dados ad hoc e interativa). Por exemplo, i4g.xlarge e c7gd.2xlarge.
- Use apenas instâncias de GPU para cargas de trabalho que usam bibliotecas aceleradas por GPU. Além disso, a menos que esteja realizando treinamento distribuído, os clusters devem ser nó único.
- Propósito geral, caso contrário. Por exemplo, m7g.xlarge.
- Use instâncias Spot ou Spot Fleet em ambientes inferiores como Dev e Stage.
Evite executar trabalhos em computação de propósito geral
Como mencionado em Controles de Custos, os custos do cluster podem ser otimizados executando trabalhos automatizados com Job Compute, não com All-Purpose Compute. O preço exato pode depender de promoções e descontos ativos, mas o Job Compute é tipicamente 2-3x mais barato do que o All-Purpose.
Job Compute também fornece novas instâncias de computação cada vez, isolando cargas de trabalho umas das outras, enquanto ainda permite que fluxos de trabalho multitarefa reutilizem os recursos de computação para todas as tarefas, se desejado. Veja como configurar a computação para jobs (AWS | Azure | GCP).
Usando as tabelas de sistema Databricks, a seguinte consulta pode ser usada para encontrar trabalhos em execução em clusters All-Purpose interativos. Isso também está incluído como parte do Painel de AI/BI de Tabelas de Sistema de Trabalhos que você pode facilmente importar para o seu workspace!
Monitorar Photon para Clusters de Propósito Geral e Trabalhos Contínuos
Photon é um motor otimizado vetorizado para Spark na Plataforma de Inteligência de Dados Databricks que oferece desempenho de consulta extremamente rápido. Photon aumenta a quantidade de DBUs que o cluster custa por um múltiplo de 2,9x para clusters de trabalho, e aproximadamente 2x para clusters All-Purpose. Apesar do multiplicador DBU, Photon pode resultar em um TCO geral mais baixo para trabalhos, reduzindo a duração do tempo de execução.
Clusters interativos, por outro lado, podem ter quantidades significativas de tempo ocioso quando os usuários não estão executando comandos; certifique-se de que todos os clusters all-purpose tenham a configuração de auto-terminação aplicada para minimizar esse custo de computação ocioso. Embora nem sempre seja o caso, isso pode resultar em custos mais altos com o Photon. Isso também torna os notebooks sem servidor uma ótima opção, pois minimizam os gastos ociosos, funcionam com Photon para o melhor desempenho e podem iniciar a sessão em apenas alguns segundos.
Da mesma forma, o Photon nem sempre é benéfico para trabalhos de streaming contínuo que estão ativos 24/7. Monitore se você consegue reduzir o número de nós de trabalho necessários ao usar Photon, pois isso reduz o TCO; caso contrário, Photon pode não ser adequado para trabalhos contínuos.
Nota: A seguinte consulta pode ser usada para encontrar clusters interativos que estão configurados com Photon:
Otimizando Armazenamento de Dados e Pipelines
Existem muitas estratégias para otimizar dados, armazenamento e Spark para cobrir aqui. Felizmente, a Databricks compilou essas informações no Guia Completo para Otimizar Cargas de Trabalho Databricks, Spark e Delta Lake, cobrindo tudo, desde layout de dados e skew até otimização de merges delta e mais. A Databricks também fornece o Grande Livro de Engenharia de Dados com mais dicas para otimização de desempenho.
Aplicação no Mundo Real
Melhores Práticas da Organização
As melhores práticas de estrutura e propriedade organizacional são tão importantes quanto as soluções técnicas que abordaremos a seguir.
Nativos digitais que executam práticas de FinOps altamente eficazes que incluem a Plataforma Databricks geralmente priorizam o seguinte dentro da organização:
- Propriedade clara para administração e monitoramento da plataforma.
- Consideração dos custos da solução antes, durante e após os projetos.
- Cultura de melhoria contínua - sempre otimizando.
Estas são algumas das estruturas organizacionais mais bem-sucedidas para FinOps:
- Centralizado (por exemplo, Centro de Excelência, Hub-and-Spoke)
- Isso pode assumir a forma de uma plataforma central ou equipe de dados responsável por FinOps e distribuição de políticas, controles e ferramentas para outras equipes a partir daí.
- Centros de Orçamento Híbridos / Distribuídos
- Dispersa o modelo centralizado para diferentes equipes específicas de domínio. Pode haver um ou mais administradores delegados para esse domínio/equipe para alinhar as práticas de plataforma e FinOps com processos e prioridades locais.
Exemplo de Centro de Excelência
Um centro de excelência tem muitos benefícios, como centralizar a administração da plataforma principal e capacitar as unidades de negócios com ativos seguros e reutilizáveis, como políticas e modelos de pacotes.
O centro de excelência geralmente coloca equipes como Data Platform, Platform Engineer ou Data Ops teams no centro, ou "hub", em um modelo de hub-and-spoke. Esta equipe é responsável por alocar e relatar custos com o Painel de Uso. Para fornecer um ambiente de autoatendimento otimizado e consciente dos custos para as equipes, a equipe de plataforma deve criar políticas de computação e políticas de orçamento que se adequem aos casos de uso e/ou unidades de negócios (os "spokes"). Embora não seja obrigatório, recomendamos gerenciar esses artefatos com Terraform e VCS para uma consistência forte, versionamento e capacidade de modularizar.
Principais Conclusões
Este tem sido um guia bastante exaustivo para ajudá-lo a controlar seus custos com o Databricks, então cobrimos várias coisas ao longo do caminho. Para recapitular, a jornada de rastejar-andar-correr é esta:
- Atribuição de Custo
- Relatório de Custos
- Controles de Custo
- Otimização de custos
Finalmente, para recapitular alguns dos pontos mais importantes:
- A marcação sólida é a base de toda boa atribuição e relatório de custos. Use Políticas de Computação para impor tags de alta qualidade.
- Importe o Painel de Uso para sua principal parada quando se trata de relatório e previsão de gastos da Databricks.
- Importe o Painel de AI/BI de Tabelas de Sistema de Jobs para monitorar e encontrar jobs com oportunidades de economia de custos.
- Use Políticas de Computação para impor controles de custos e limites de recursos na criação de clusters.
Passos seguintes
Comece hoje e crie sua primeira Política de Computação, ou use um dos nossos exemplos de políticas. Depois, importe o Painel de Uso como sua principal parada para relatórios e previsões de gastos do Databricks. Marque as otimizações do Passo 3 que compartilhamos anteriormente para seus clusters, espaços de trabalho e dados. Marque as otimizações do Passo 3 que compartilhamos anteriormente para seus clusters, espaços de trabalho e dados.
Os Arquitetos de Soluções de Entrega (DSAs) da Databricks aceleram as iniciativas de Dados e IA em organizações. Eles fornecem liderança arquitetônica, otimizam plataformas para custo e desempenho, aprimoram a experiência do desenvolvedor e conduzem a execução bem-sucedida do projeto. Os DSAs preenchem a lacuna entre a implantação inicial e as soluções de produção, trabalhando de perto com várias equipes, incluindo engenharia de dados, líderes técnicos, executivos e outros stakeholders para garantir soluções personalizadas e um tempo de valor mais rápido. Para se beneficiar de um plano de execução personalizado, orientação estratégica e suporte durante toda a sua jornada de dados e IA com um DSA, entre em contato com a sua Equipe de Conta Databricks.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.