Boas Práticas de Modelagem de Dados e Implementação em um Lakehouse Moderno
por Leo Mao, Abhishek Dey, Justin Breese e Soham Bhatt
Muitos dos nossos clientes estão migrando seus data warehouses legados para o Databricks Lakehouse, pois isso permite que eles modernizem não apenas seus Data Warehouses, mas também obtenham acesso instantâneo a uma plataforma madura de Streaming e Análise Avançada. O Lakehouse pode fazer tudo, pois é uma única plataforma para todas as suas necessidades de streaming, ETL, BI e IA - e ajuda suas equipes de negócios e de dados a colaborar em uma única plataforma.
Ao ajudar os clientes em campo, descobrimos que muitos procuram as melhores práticas em modelagem de dados adequada e implementações de modelos de dados físicos no Databricks.
Neste artigo, pretendemos aprofundar a melhor prática de modelagem dimensional na Databricks Lakehouse Platform e fornecer um exemplo prático de implementação de um modelo de dados físico usando nossas práticas recomendadas de criação de tabelas e DDL.
Aqui estão os tópicos de alto nível que abordaremos neste blog:
- A Importância da Modelagem de Dados
- Técnicas Comuns de Modelagem de Dados
- Implementação de DDL de Modelagem de Data Warehouse
- Melhores práticas e Recomendações para Modelagem de Dados no Databricks Lakehouse
A importância da Modelagem de Dados para Data Warehouse
Modelos de Dados são o ponto central na construção de um Data Warehouse. Normalmente, o processo começa com a defesa do Modelo de Informações Semânticas de Negócios, depois um Modelo de Dados Lógico e, finalmente, um Modelo de Dados Físico (PDM). Tudo começa com uma fase adequada de Análise e Design de Sistemas, onde um Modelo de Informações de Negócios e fluxos de processos são criados primeiro, e as principais entidades de negócios, atributos e suas interações são capturados de acordo com os processos de negócios dentro da organização. O Modelo de Dados Lógico é então criado descrevendo como as entidades se relacionam entre si e este é um modelo agnóstico de tecnologia. Finalmente, um PDM é criado com base na plataforma de tecnologia subjacente para garantir que as escritas e leituras possam ser realizadas de forma eficiente. Como todos sabemos, para Data Warehousing, estilos de modelagem amigáveis para análise como Star-schema e Data Vault são bastante populares.
Melhores práticas para criar um Modelo de Dados Físico no Databricks
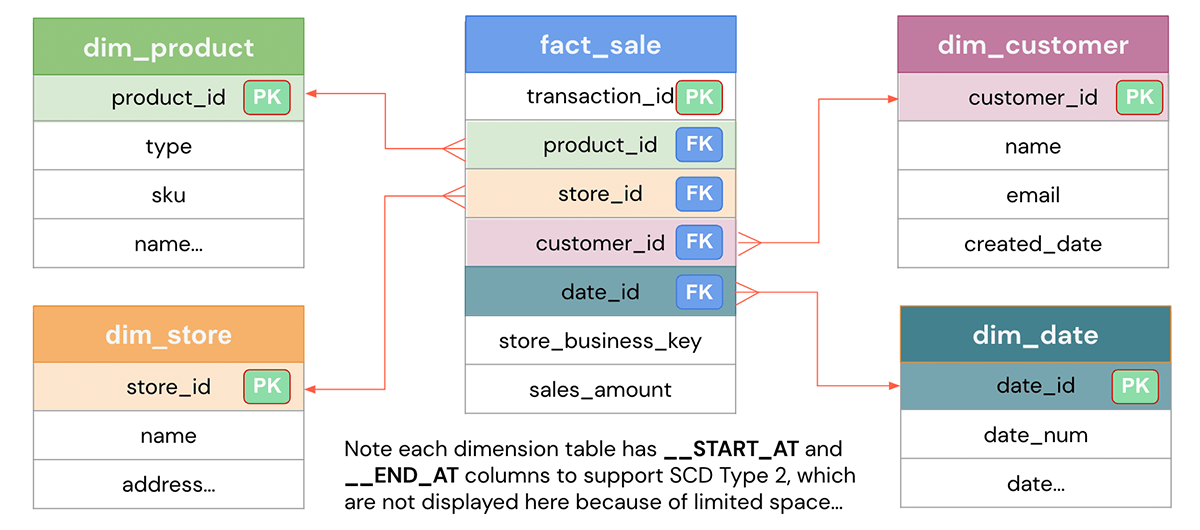
Com base no problema de negócios definido, o objetivo do design do modelo de dados é representar os dados de forma fácil para reutilização, flexibilidade e escalabilidade. Aqui está um modelo de dados típico de star-schema que mostra uma tabela de fatos de Vendas que contém cada transação e várias tabelas de dimensão, como clientes, produtos, lojas, data etc., pelas quais você pode fatiar e analisar os dados. As dimensões podem ser unidas à tabela de fatos para responder a perguntas de negócios específicas, como quais são os produtos mais populares para um determinado mês ou quais lojas estão tendo o melhor desempenho no trimestre. Vamos ver como implementá-lo no Databricks.
Implementação de DDL de Modelagem de Data Warehouse no Databricks
Nas seções a seguir, demonstraremos o abaixo usando nossos exemplos.
- Criação de Catálogo, Banco de Dados e Tabela de 3 níveis
- Definições de Chave Primária, Chave Estrangeira
- Colunas de Identidade para Chaves Substitutas
- Restrições de Coluna para Qualidade de Dados
- Indexar, otimizar e analisar
- Técnicas avançadas
1. Unity Catalog - Namespace de 3 níveis
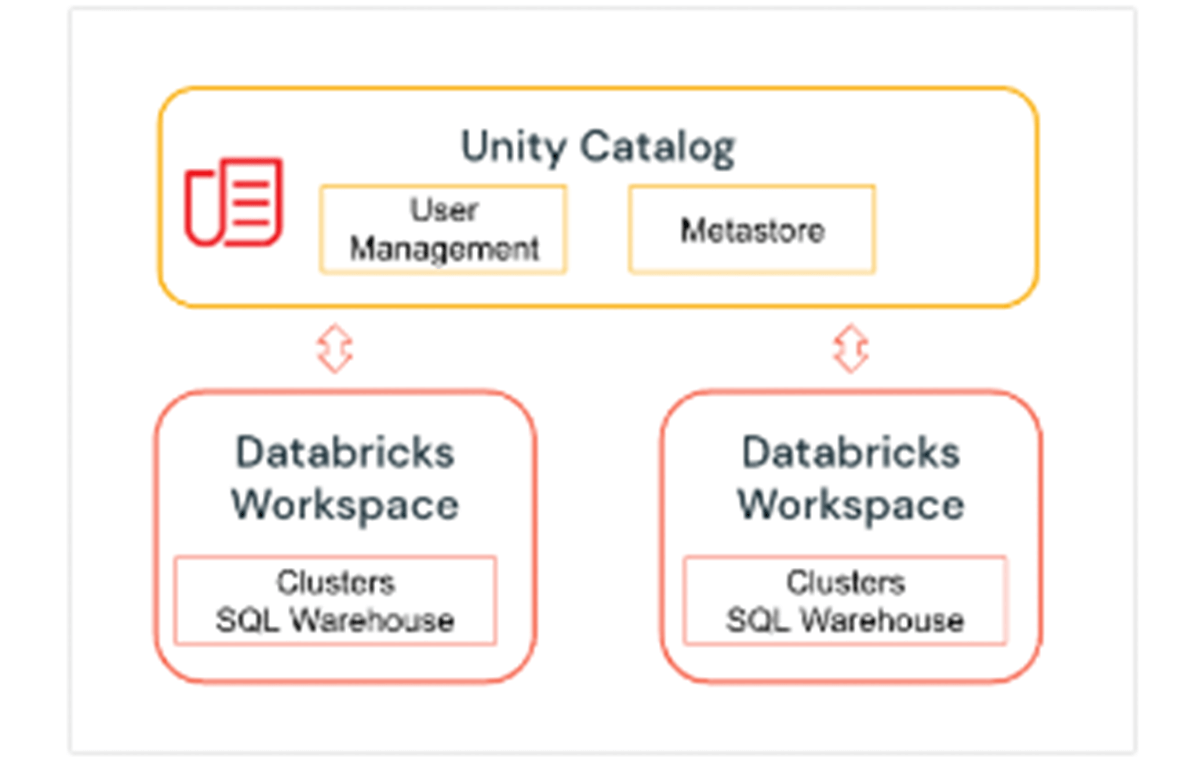
Unity Catalog é uma camada de Governança do Databricks que permite aos administradores e curadores de dados do Databricks gerenciar usuários e seu acesso a dados centralmente em todos os espaços de trabalho em uma conta Databricks usando um único Metastore. Usuários em diferentes espaços de trabalho podem compartilhar acesso aos mesmos dados, dependendo dos privilégios concedidos centralmente no Unity Catalog. O Unity Catalog tem um Namespace de 3 níveis (catalog.schema(database).table) que organiza seus dados. Saiba mais sobre o Unity Catalog aqui.
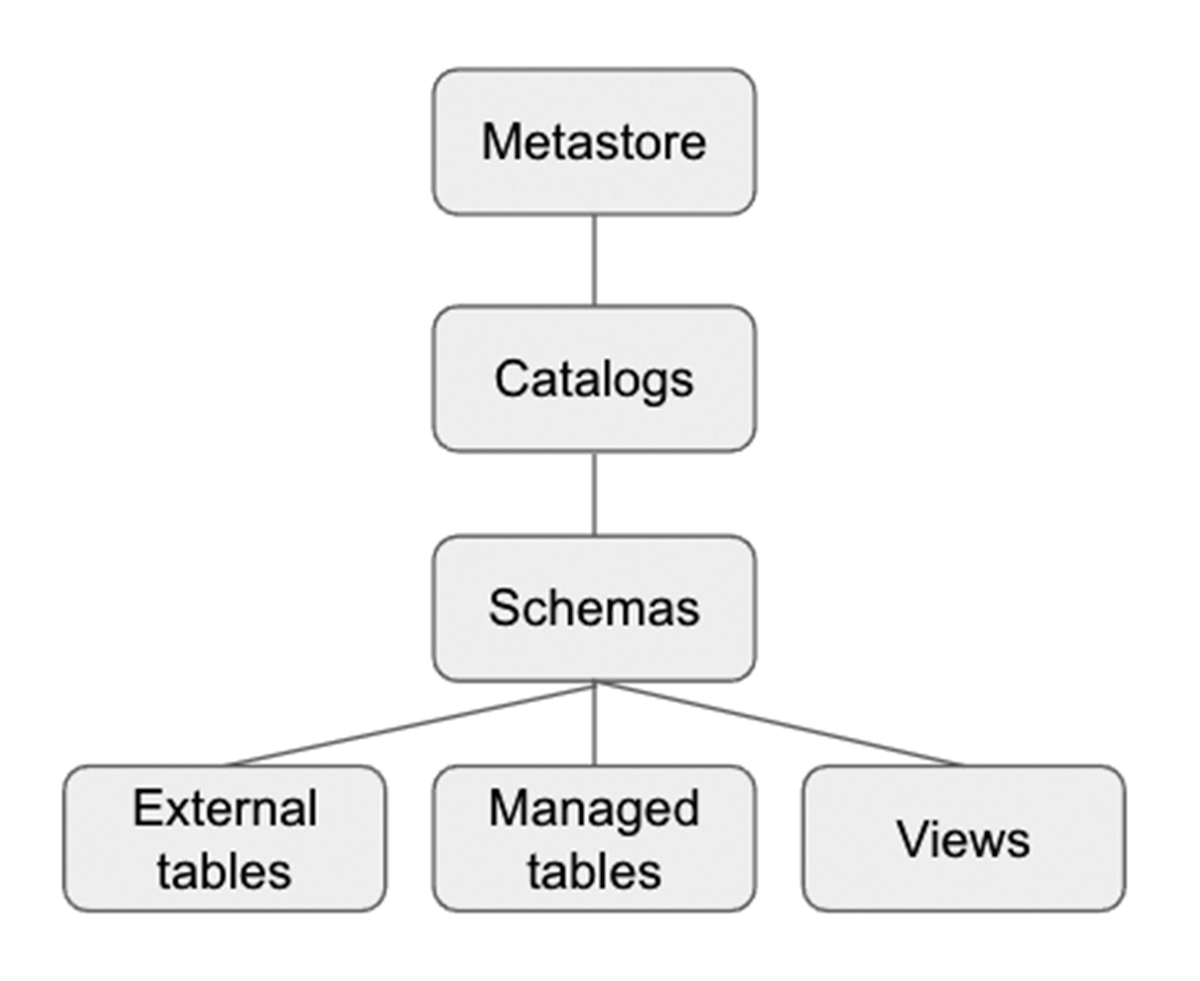
Veja como configurar o catálogo e o esquema antes de criarmos tabelas dentro do banco de dados. Para nosso exemplo, criamos um catálogo US_Stores e um esquema (banco de dados) Sales_DW como abaixo, e os usamos para a parte posterior da seção.
Configuração do Catálogo e Banco de Dados
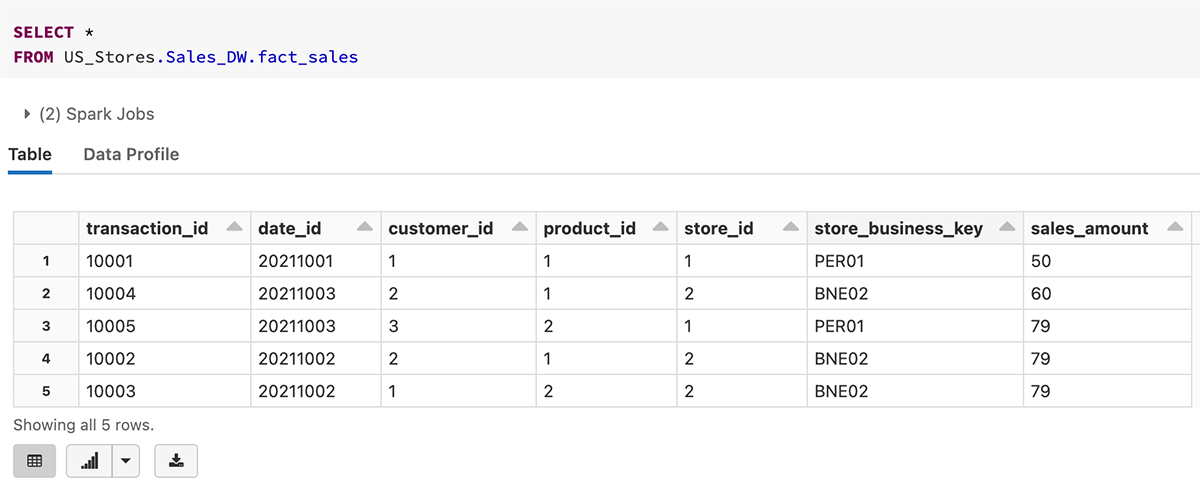
Aqui está um exemplo de consulta à tabela fact_sales com um namespace de 3 níveis.
2. Definições de Chave Primária, Chave Estrangeira
As definições de Chave Primária e Chave Estrangeira são muito importantes ao criar um modelo de dados. Ter a capacidade de suportar a definição de PK/FK torna a definição do modelo de dados super fácil no Databricks. Também ajuda os analistas a entenderem rapidamente os relacionamentos de junção no Databricks SQL Warehouse, para que possam escrever consultas de forma eficaz. Como a maioria dos outros Data Warehouses Massively Parallel Processing (MPP), EDW e Cloud Data Warehouses, as restrições de PK/FK são apenas informativas. O Databricks não suporta a imposição do relacionamento PK/FK, mas oferece a capacidade de defini-lo para facilitar o design do Modelo de Dados Semântico.
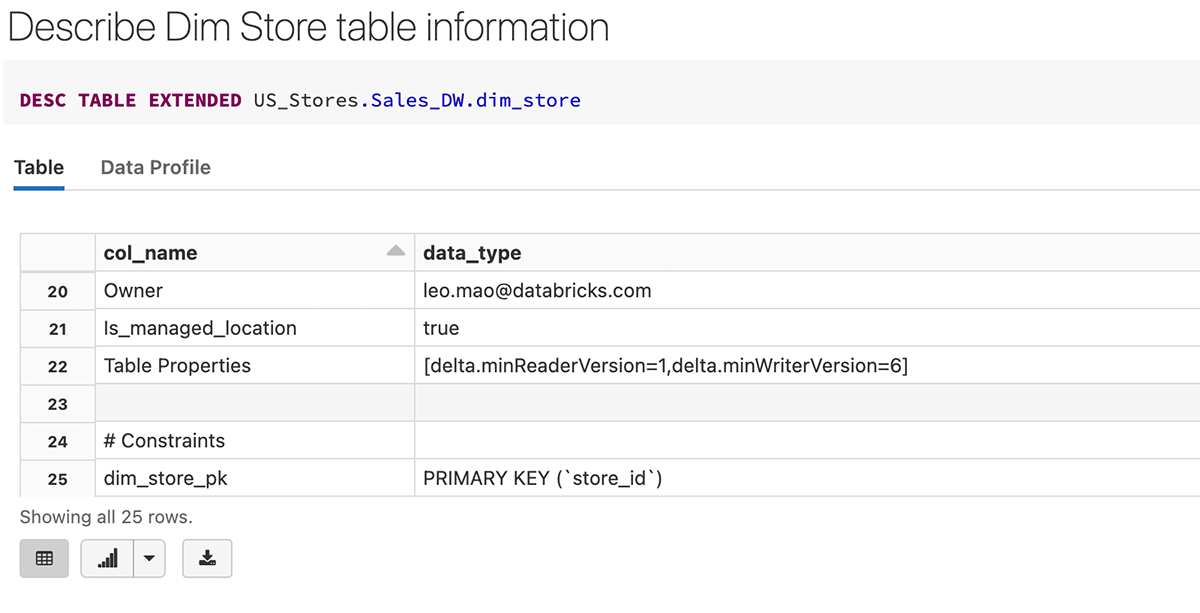
Aqui está um exemplo de criação da tabela dim_store com store_id como uma Coluna de Identidade e também definida como Chave Primária ao mesmo tempo.
Implementação de DDL para criação de dimensão de loja com Definições de Chave Primária
Após a criação da tabela, podemos ver que a chave primária (store_id) é criada como uma restrição na definição da tabela abaixo.
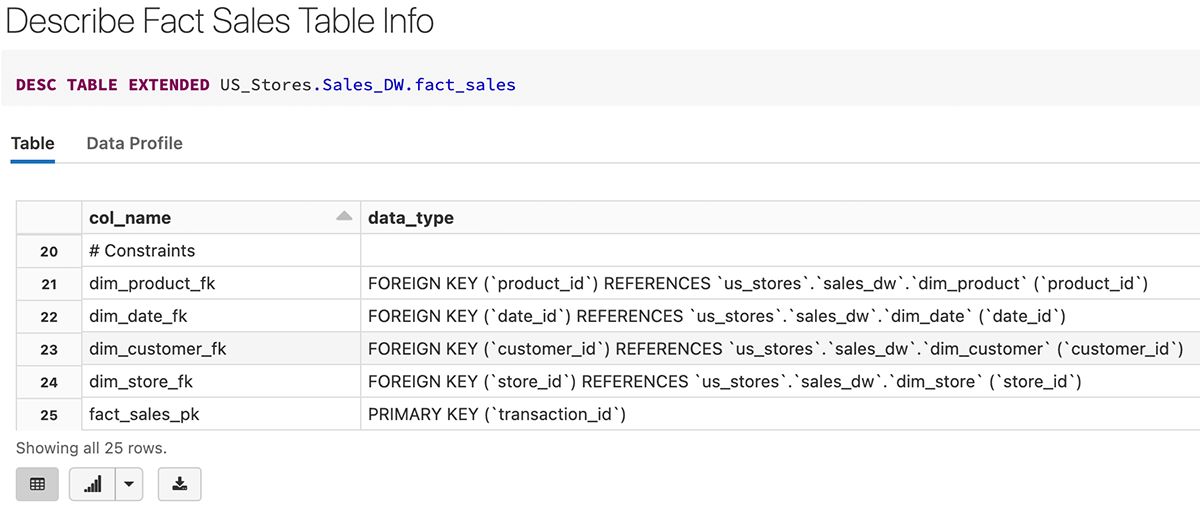
Aqui está um exemplo de criação da tabela fact_sales com transaction_id como Chave Primária, bem como chaves estrangeiras que referenciam as tabelas de dimensão.
Implementação de DDL para criação de fato de vendas com definições de Chave Estrangeira
Após a criação da tabela de fatos, poderíamos ver que a chave primária (transaction_id) e as chaves estrangeiras são criadas como restrições na definição da tabela abaixo.
3. Colunas de Identidade para Chaves Substitutas
Uma coluna de identidade é uma coluna em um banco de dados que gera automaticamente um número de ID exclusivo para cada nova linha de dados. Estes são comumente usados para criar chaves substitutas em data warehouses. Chaves substitutas são chaves sem significado, geradas pelo sistema, para que não tenhamos que depender de várias Chaves Primárias Naturais e concatenações em vários campos para identificar a exclusividade da linha. Normalmente, essas chaves substitutas são usadas como chaves primárias e estrangeiras em data warehouses. Detalhes sobre colunas de identidade são discutidos neste blog. Abaixo está um exemplo de criação de uma coluna de identidade customer_id, com valores atribuídos automaticamente começando em 1 e incrementando em 1.
Implementação DDL para criar a dimensão do cliente com coluna de identidade
4. Restrições de coluna para Qualidade de Dados
Além das restrições informacionais de chave primária e estrangeira, o Databricks também suporta restrições de Verificação de Qualidade de Dados em nível de coluna, que são aplicadas para garantir a qualidade e a integridade dos dados adicionados a uma tabela. As restrições são verificadas automaticamente. Bons exemplos são restrições NOT NULL e restrições de valor de coluna. Diferente de outros Data Warehouses na nuvem, o Databricks foi além para fornecer restrições de verificação de valor de coluna, que são muito úteis para garantir a qualidade dos dados de uma determinada coluna. Como podemos ver abaixo, a restrição de verificação valid_sales_amount verificará se todas as linhas existentes satisfazem a restrição (ou seja, sales amount > 0) antes de adicioná-la à tabela. Mais informações podem ser encontradas aqui.
Aqui estão exemplos para adicionar restrições para dim_store e fact_sales, respectivamente, para garantir que store_id e sales_amount tenham valores válidos.
Adicionar restrição de coluna a tabelas existentes para garantir a qualidade dos dados
5. Index, Optimize e Analyze
Bancos de dados tradicionais possuem índices b-tree e bitmap, o Databricks possui uma forma muito mais avançada de indexação - indexação clusterizada Z-order multidimensional e também suportamos indexação Bloom filter. Em primeiro lugar, o formato de arquivo Delta usa o formato de arquivo Parquet, que é um formato de arquivo comprimido colunar, então ele já é muito eficiente em poda de colunas e, além disso, usar a indexação z-order oferece a capacidade de analisar dados em escala de petabytes em segundos. Tanto o Z-order quanto a indexação Bloom filter reduzem drasticamente a quantidade de dados que precisam ser escaneados para responder a consultas altamente seletivas em grandes tabelas Delta, o que geralmente se traduz em melhorias de tempo de execução de ordens de magnitude e economia de custos. Use Z-order em suas chaves primárias e chaves estrangeiras que são usadas para os joins mais frequentes. E use indexação Bloom filter adicional conforme necessário.
Otimizar fact_sales em customer_id e product_id para melhor desempenho
Criar um índice Bloomfilter para habilitar o data skipping em uma determinada coluna
E assim como qualquer outro Data Warehouse, você pode ANALYZE TABLE para atualizar estatísticas e garantir que o otimizador de consulta tenha as melhores estatísticas para criar o melhor plano de consulta.
Coletar estatísticas para todas as colunas para um melhor plano de execução de consulta
6. Técnicas Avançadas
Embora o Databricks suporte técnicas avançadas como Table Partitioning, por favor, use esses recursos com moderação, apenas quando você tiver muitos Terabytes de dados comprimidos - porque na maioria das vezes nossos índices OPTIMIZE e Z-ORDER lhe darão a melhor poda de arquivos e dados, o que torna o particionamento de uma tabela por data ou mês quase uma má prática. No entanto, é uma boa prática garantir que seus DDLs de tabela estejam configurados para otimização automática e compactação automática. Isso garantirá que seus dados frequentemente gravados em arquivos pequenos sejam compactados em formatos colunares comprimidos maiores do Delta.
Você está procurando alavancar uma ferramenta visual de modelagem de dados? Nosso parceiro erwin Data Modeler da Quest pode ser usado para engenharia reversa, criar e implementar Star-schema, Data Vaults e qualquer Modelo de Dados da Indústria no Databricks com apenas alguns cliques.
Exemplo de Notebook Databricks
Com a plataforma Databricks, é fácil projetar e implementar vários modelos de dados com facilidade. Para ver todos os exemplos acima em um fluxo de trabalho completo, consulte este exemplo.
Por favor, confira também nosso blog relacionado - Cinco Passos Simples para Implementar um Star Schema no Databricks com Delta Lake.
Comece a construir seus Modelos Dimensionais no Lakehouse
Experimente o Databricks gratuitamente por 14 dias.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.