Databricks faz parceria com OpenAI no GPT-5.5
GPT-5.5 estabelece o desempenho de ponta no benchmark OfficeQA da Databricks
por Hanlin Tang, Ahmed Bilal, Arnav Singhvi, Ivan Zhou e Harish Gaur
- Databricks está fazendo parceria com a OpenAI no GPT-5.5
- GPT-5.5 reduz os erros em quase metade no OfficeQA Pro
- OpenAI GPT-5.5 e Codex estarão disponíveis em breve na Databricks e serão governados através do Unity AI Gateway
A Databricks tem o prazer de fazer parceria com a OpenAI no GPT-5.5, o modelo de fronteira mais recente deles. O GPT-5.5 é o modelo de fronteira mais forte da OpenAI para trabalho agêntico em empresas, raciocínio complexo de documentos e agentes de codificação de longo prazo. O GPT-5.5 agora também potencializa o Codex, o agente de codificação da OpenAI.
Recursos e Benefícios do GPT-5.5
O GPT-5.5 é o modelo de fronteira mais inteligente até agora e o próximo passo em direção a uma nova forma de realizar o trabalho. Ele entende o que você está tentando fazer mais rapidamente e pode assumir mais do trabalho por conta própria. O Codex, o agente de codificação da OpenAI, agora é potencializado pelo GPT-5.5, com raciocínio mais forte e capacidades de execução para fluxos de trabalho de desenvolvedores.
As mesmas forças que tornam o GPT-5.5 ótimo em codificação também o tornam poderoso para o trabalho diário em um computador. Como o modelo é melhor em entender a intenção, ele pode se mover de forma mais natural por todo o ciclo de trabalho de conhecimento: encontrar informações, entender o que é importante, usar ferramentas, verificar a saída e transformar material bruto em algo útil.
Ele pode escrever e depurar código, pesquisar online, analisar dados, criar documentos e planilhas, operar software e transitar entre ferramentas até que uma tarefa seja concluída. Em vez de gerenciar cuidadosamente cada etapa, você pode dar ao GPT-5.5 uma tarefa confusa e de várias partes e confiar nele para planejar, usar ferramentas, verificar seu trabalho, se recuperar de ambiguidades e continuar.
GPT-5.5 estabelece o desempenho de ponta
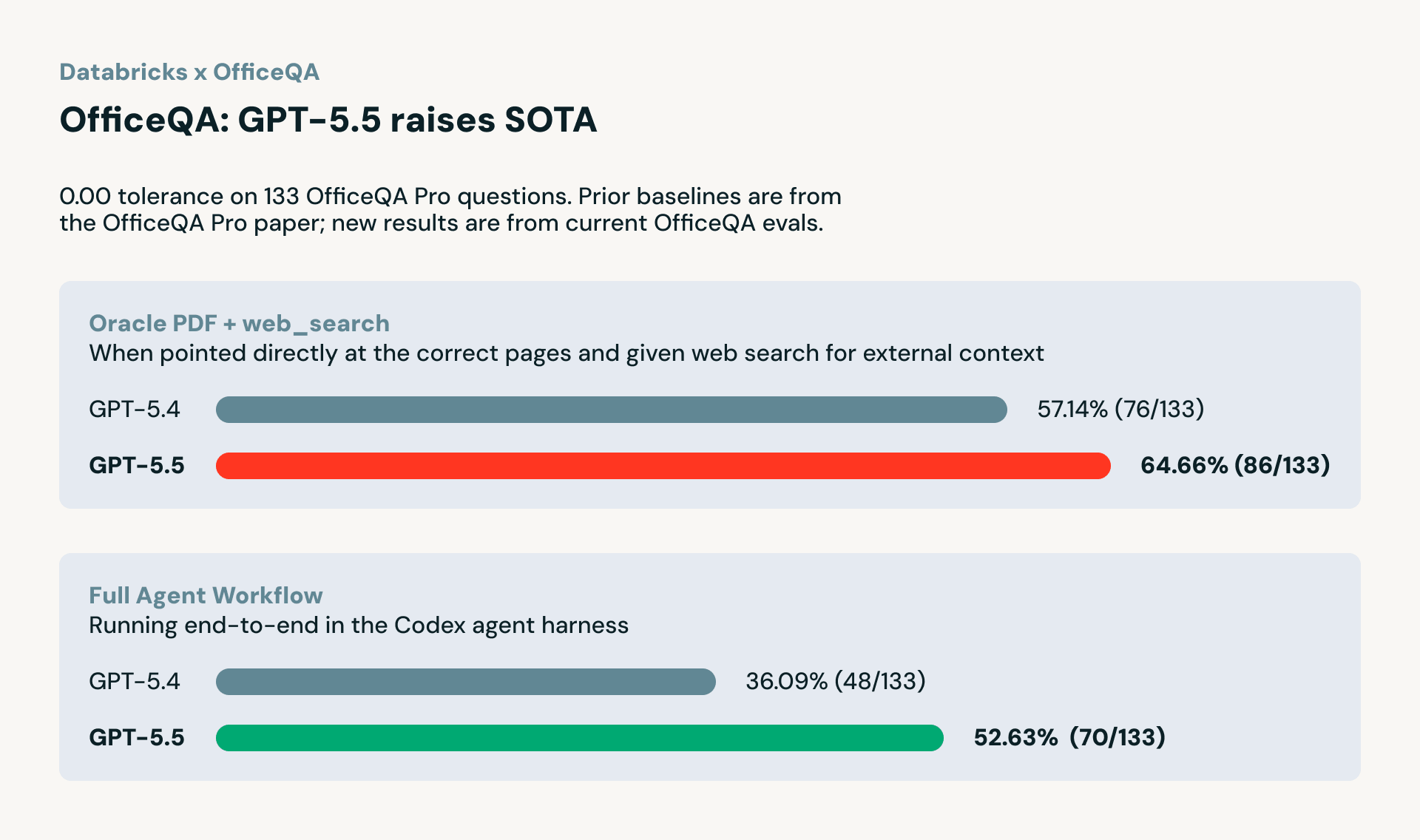
Para entender como essas melhorias se traduzem em cargas de trabalho empresariais reais, avaliamos o GPT-5.5 no OfficeQA, o benchmark da Databricks para tarefas analíticas complexas e com muitos documentos que os clientes realizam todos os dias. O OfficeQA, construído a partir de 89.000 páginas de boletins do Tesouro dos EUA, mede a capacidade de um modelo de recuperar informações em documentos, interpretar tabelas complexas e realizar cálculos precisos baseados em dados empresariais reais.
Quando fornecido com os documentos corretos (OfficeQA Pro LLM com Oracle PDF + Web Search), o GPT-5.5 obteve 64,66%, um salto decente em relação aos 57,14% do GPT-5.4, representando uma melhoria de ~13% e um novo estado da arte neste benchmark. Isso testa o limite do que o modelo pode fazer quando a recuperação já está tratada.
Em uma avaliação de fluxo de trabalho de agente completo (OfficeQA Pro Agent Harness), onde o modelo deve encontrar os documentos corretos, analisá-los e calcular as respostas por conta própria usando o harness do agente Codex, o GPT-5.5 obteve 52,63%, acima dos 36,10% do GPT-5.4. Isso é uma redução de 46% nos erros, mostrando que os ganhos do GPT-5.5 não são apenas teóricos; eles se sustentam em fluxos de trabalho empresariais realistas e de ponta a ponta.
O GPT-5.5 estará disponível em breve na Databricks. Traga raciocínio de ponta para seus dados empresariais, com segurança e em escala.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.