Databricks na SIGMOD 2026
por Indrajit Roy
- Descubra como a Databricks está liderando a próxima geração de engenharia de dados com Spark Declarative Pipelines (SDP), simplificando cargas de trabalho complexas de ETL e streaming.
- Obtenha um mergulho profundo no Enzyme, nosso mecanismo de manutenção incremental de visualizações, que ganhou uma menção honrosa na conferência SIGMOD.
- Conheça nossos engenheiros na conferência para discutir essas inovações líderes do setor.
A Databricks continua na vanguarda da inovação em engenharia, expandindo constantemente os limites do que é possível no espaço de Dados e IA. Estamos empolgados em anunciar que nosso trabalho em Spark Declarative Pipelines será apresentado na SIGMOD 2026 e recebeu uma menção honrosa na conferência. Estaremos na SIGMOD, de 1 a 5 de junho, como Patrocinador Platina. A SIGMOD acontecerá em Bangalore, Índia, que também é um grande centro de P&D da Databricks.
Nossos próximos artigos sobre engenharia de dados mostram como a Databricks simplificou o processamento incremental para os clientes. Existem duas maneiras de escrever programas incrementais em Spark Declarative Pipelines (SDP), e os clientes podem combiná-las dentro de um pipeline:
- Engenheiros de dados podem especificar Visualizações Materializadas para transformações. O mecanismo Enzyme as mantém incrementalmente à medida que novos dados chegam. Toda a complexidade do processamento incremental é completamente oculta dos criadores das visualizações materializadas. O artigo da SIGMOD 2026 “Enzyme: Incremental View Maintenance for Data Engineering” discute algumas dessas ideias.
- Engenheiros de dados experientes em processamento de streaming podem, em vez disso, usar o mecanismo de streaming do SDP para processar dados incrementalmente. As APIs de streaming fornecem uma ampla variedade de construtos – de operadores com estado a watermarks, facilitando a expressão de lógica de negócios complexa, como agregações personalizadas. Ideias chave em nosso produto de streaming aparecerão no artigo da VLDB 2026 “A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs”.
Aqui está uma prévia do artigo do Enzyme e no que a equipe tem trabalhado:
Enzyme na SIGMOD 2026
Manutenção Incremental de Visualizações
Digamos que você seja um analista em uma empresa e queira analisar o número total de pedidos vendidos em uma região. A visualização materializada abaixo fornece a resposta.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
À medida que novos pedidos são adicionados, você espera que a visualização materializada permaneça atualizada. Essa manutenção de dados é essencialmente o problema de manutenção incremental de visualizações. Embora manter a MV de exemplo acima atualizada pareça simples, imagine se a MV precisasse juntar dados de várias tabelas, tivesse funções de janela ou fizesse chamadas para funções LLM.
Inovações do Enzyme
Visualizações materializadas (MVs) são populares para aceleração de consultas – acelerando dashboards em dados residindo em data warehouses. Ao criar Spark Declarative Pipelines, decidimos ir além da aceleração de consultas e aplicar visualizações materializadas aos casos de uso de extração-transformação-carga (ETL). Nossa observação chave é que, se as MVs puderem ser mantidas de forma eficiente e incremental, isso simplificará significativamente os fluxos de trabalho de ETL, que de outra forma exigiriam a escrita de código personalizado complexo.
O Enzyme adiciona à rica literatura sobre manutenção incremental de visualizações materializadas e demonstra como escalar essas técnicas em cargas de trabalho de produção. Algumas das inovações em que a equipe trabalhou são:
- Suporte para padrões extensivos de MV: O Enzyme mantém incrementalmente MVs complexas em produção, incluindo aquelas com joins, funções de janela, agregações e suas combinações. Ao contrário de outras soluções do setor, o Enzyme também suporta funções não determinísticas como current_date() e funções específicas de IA.
- Suporte multilíngue: Enquanto a maioria das soluções do setor foca apenas em SQL, o Enzyme também suporta MVs especificadas em Python. Python é agora a linguagem de escolha para a maioria das cargas de trabalho de engenharia de dados e IA. O Enzyme resolve muitos desafios interessantes que o suporte multilíngue acarreta, como a detecção precisa de alterações na definição da MV.
- Otimizações de desempenho: O Enzyme possui várias otimizações para reduzir a quantidade de dados que precisam ser processados, incluindo técnicas que determinam automaticamente se as atualizações devem ser aplicadas no nível da partição em vez do nível da linha, reduzindo assim os custos de reescrita. Ele armazena em cache seletivamente resultados intermediários para reduzir os custos de IO. Ele usa um modelo de custo que aproveita as informações do plano e execuções anteriores para determinar a estratégia de incrementalização mais eficiente.
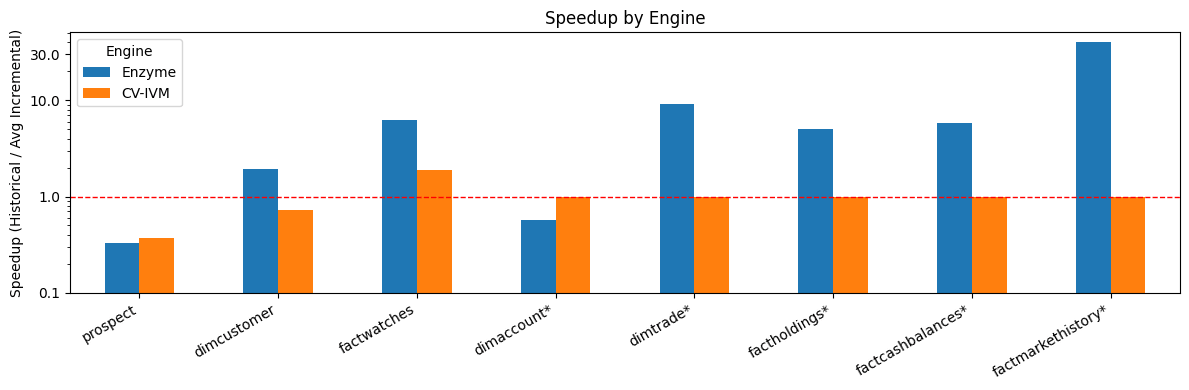
Figura 1: O Enzyme tem um desempenho significativamente melhor do que outra solução concorrente da indústria (nome anonimizado para CV-IVM devido a restrições de licenciamento).
Interessado em saber mais? Confira o artigo e, se estiver na SIGMOD, participe da nossa palestra para mais detalhes.
Conheça a equipe na SIGMOD:
Visite nosso estande para conhecer a equipe e saber mais sobre a inovação que está acontecendo na Databricks. Além disso, não perca a chance de ouvir diretamente de Ritwik Yadav, durante sua apresentação na SIGMOD!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.