Databricks at SIGMOD 2026
by Indrajit Roy
- Discover how Databricks is pioneering the next generation of data engineering with Spark Declarative Pipelines (SDP), simplifying complex ETL and streaming workloads.
- Get a deep dive into Enzyme, our incremental view maintenance engine, which won an honorable mention at SIGMOD conference.
- Meet our engineers at the conference to discuss these industry-leading innovations.
Databricks continues to lead the way in engineering innovation, consistently pushing the boundaries of what’s possible in the Data and AI space. We are thrilled to announce that our work on Spark Declarative Pipelines will be featured at SIGMOD 2026, and has received an honorable mention award at the conference. We’re headed to SIGMOD, this upcoming June 1-5 as a Platinum Sponsor. SIGMOD will take place in Bangalore, India which is also a large Databricks R&D hub.
Our upcoming papers on data engineering show how Databricks has simplified incremental processing for customers. There are two ways to write incremental programs in Spark Declarative Pipelines (SDP), and customers can mix-and-match these within a pipeline:
- Data engineers can specify Materialized Views for transformations. The Enzyme engine incrementally maintains them as new data arrives. All the complexity of incremental processing is completely hidden from the creators of the materialized views. The SIGMOD 2026 paper “Enzyme: Incremental View Maintenance for Data Engineering” discusses some of these ideas.
- Data engineers who are well versed in stream processing can instead use SDP’s streaming engine to incrementally process data. The streaming APIs provide a wide variety of constructs– from stateful operators to watermarks, making it easy to express complicated business logic like custom aggregations. Key ideas in our streaming product will appear in the VLDB 2026 paper “A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs”.
Here’s a sneak peak at the Enzyme paper and what the team has been working on:
Enzyme at SIGMOD 2026
Incremental View Maintenance
Let’s say you are an analyst in a company and want to analyze the total number of orders sold in a region. The materialized view below provides the answer.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
As new orders are added, you expect the materialized view to remain up to date. This data maintenance is essentially the incremental view maintenance problem. While keeping the above toy MV updated seems simple, imagine if the MV needed to join data across multiple tables or had window functions or made calls to LLM functions.
Enzyme Innovations
Materialized views (MVs) are popular for query acceleration– speeding up dashboards on data residing in data warehouses. When creating Spark Declarative Pipelines, we decided to go beyond query acceleration and apply materialized views to the extract-transform-load (ETL) use cases. Our key observation is that if MVs can be efficiently and incrementally maintained, it will significantly simplify ETL workloads which otherwise require writing complex custom code.
Enzyme adds to the rich literature on incrementally maintaining materialized views and demonstrates how to scale these techniques on production workloads. Some of the innovations that the team worked on are:
- Support for extensive MV patterns: Enzyme incrementally maintains complex MVs in production including those with joins, window functions, aggregations, and their combinations. Unlike other industry solutions, Enzyme also supports non-deterministic functions such as current_date() and AI specific functions.
- Multi-language support: While most industry solutions just focus on SQL, Enzyme supports MVs specified in Python as well. Python is now the language of choice for most data engineering and AI workloads. Enzyme solves many interesting challenges that multi-language support entails such as accurately detecting changes in MV definition.
- Performance optimizations: Enzyme has multiple optimizations to reduce the amount of data that needs to be processed including techniques that automatically determine if updates should be applied at partition level instead of row level thus reducing rewrite overheads. It selectively caches intermediate results to reduce IO costs. It uses a cost model that leverages plan information and prior executions to determine the most efficient incrementalization strategy.
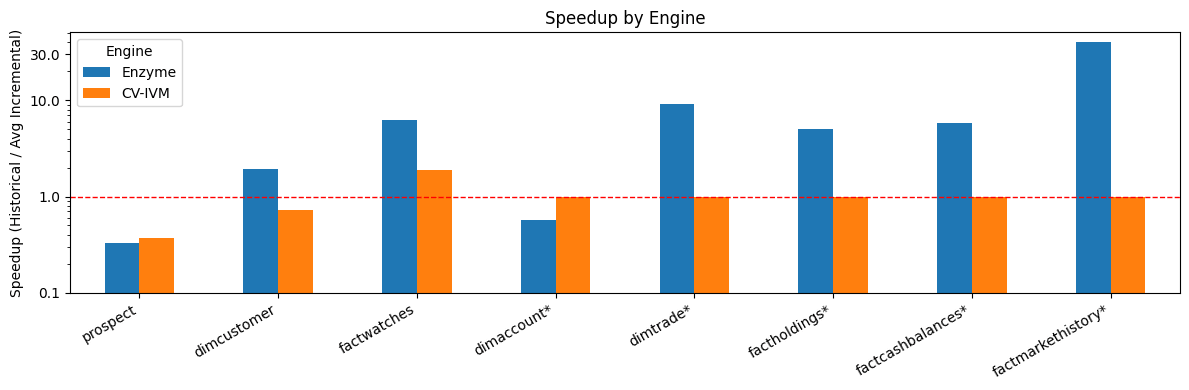
Figure 1: Enzyme has significantly better performance than another competing industry solution (name anonymized to CV-IVM due to licensing restrictions).
Interested in learning more? Check out the paper and if you're at SIGMOD, attend our talk for more details.
Meet the team at SIGMOD:
Stop by our booth to meet the team and learn more about the innovation that is happening at Databricks. Plus, don’t miss the chance to hear directly from Ritwik Yadav, during his presentation at SIGMOD!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.