A Evolução do Processamento de Stream Stateful Arbitrário no Spark
Explorando as vantagens únicas do transformWithStateInPandas
por Sol Ackerman, Anish Shrigondekar, Eric Marnadi, Jing Zhan, Bo Gao, Jungtaek Lim e Karthik Ramasamy
- Evolução do processamento com estado: Comparando applyInPandasWithState e transformWithStateInPandas no Spark™ 4.0 para maior flexibilidade e funcionalidade.
- Novos recursos: transformWithStateInPandas oferece múltiplos tipos de estado, temporizadores, TTL e evolução de esquema para pipelines de streaming complexos.
- Desenvolvimento simplificado: transformWithStateInPandas simplifica o manuseio do estado e melhora o processo de depuração com controle mais granular e integração mais fácil com leitores de fonte de dados de estado.
Introdução
O processamento com estado no Apache Spark™ Structured Streaming evoluiu significativamente para atender às crescentes demandas de aplicações de streaming complexas. Inicialmente, a API applyInPandasWithState permitia que os desenvolvedores realizassem operações arbitrárias com estado em dados de streaming. No entanto, à medida que a complexidade e sofisticação das aplicações de streaming aumentaram, a necessidade de uma API mais flexível e rica em recursos tornou-se aparente. Para atender a essas necessidades, a comunidade Spark introduziu a API muito melhorada transformWithStateInPandas, disponível no Apache Spark™ 4.0, que agora pode substituir totalmente o operador applyInPandasWithState existente. transformWithStateInPandas oferece uma funcionalidade muito maior, como modelagem de dados flexível e tipos compostos para definir estado, temporizadores, TTL no estado, encadeamento de operadores e evolução de esquema.
Neste blog, vamos nos concentrar em Python para comparar transformWithStateInPandas com a API mais antiga applyInPandasWithState e usar exemplos de código para mostrar como transformWithStateInPandas pode expressar tudo o que applyInPandasWithState pode e mais.
Ao final deste blog, você entenderá as vantagens de usar transformWithStateInPandas em vez de applyInPandasWithState, como um pipeline applyInPandasWithState pode ser reescrito como um pipeline transformWithStateInPandas, e como transformWithStateInPandas pode simplificar o desenvolvimento de aplicações de streaming com estado no Apache Spark™.
Visão geral de applyInPandasWithState
applyInPandasWithState é uma poderosa API no Apache Spark™ Structured Streaming que permite operações stateful arbitrárias em dados de streaming. Esta API é particularmente útil para aplicações que requerem lógica personalizada de gerenciamento de estado. applyInPandasWithState permite aos usuários manipular dados de streaming agrupados por uma chave e aplicar operações stateful em cada grupo.
A maior parte da lógica de negócios ocorre na func, que tem a seguinte assinatura de tipo.
Por exemplo, a seguinte função realiza uma contagem contínua do número de valores para cada chave. Vale a pena notar que essa função quebra o princípio da responsabilidade única: ela é responsável por lidar com a chegada de novos dados, bem como quando o estado expira.
Uma implementação completa de exemplo é a seguinte:
Visão geral do transformWithStateInPandas
transformWithStateInPandas é um novo operador de processamento com estado personalizado introduzido no Apache Spark™ 4.0. Comparado com applyInPandasWithState, você notará que sua API é mais orientada a objetos, flexível e rica em recursos. Suas operações são definidas usando um objeto que estende StatefulProcessor, ao contrário de uma função com uma assinatura de tipo. transformWithStateInPandas orienta você, fornecendo uma definição mais concreta do que precisa ser implementado, tornando o código muito mais fácil de entender.
A classe tem cinco métodos principais:
init: Este é o método de configuração onde você inicializa as variáveis etc. para sua transformação.handleInitialState: Esta etapa opcional permite que você pré-popule seu pipeline com dados de estado inicial.handleInputRows: Esta é a etapa central de processamento, onde você processa as linhas de dados recebidas.handleExpiredTimers: Esta etapa permite que você gerencie temporizadores que expiraram. Isso é crucial para operações com estado que precisam rastrear eventos baseados em tempo.close: Esta etapa permite que você realize quaisquer tarefas de limpeza necessárias antes que a transformação termine.
Com esta classe, um operador equivalente de contagem de frutas é mostrado abaixo.
E isso pode ser implementado em um pipeline de streaming da seguinte maneira:
Trabalhando com estado
Número e tipos de estado
applyInPandasWithState e transformWithStateInPandas diferem em termos de capacidades de manipulação de estado e flexibilidade. applyInPandasWithState suporta apenas uma única variável de estado, que é gerenciada como um GroupState. Isso permite um gerenciamento de estado simples, mas limita o estado a uma estrutura de dados e tipo de valor único. Em contraste, transformWithStateInPandas é mais versátil, permitindo múltiplas variáveis de estado de diferentes tipos. Além do tipo ValueState de transformWithStateInPandas(análogo ao GroupState de applyInPandasWithState), ele suporta ListState e MapState, oferecendo maior flexibilidade e possibilitando operações de estado mais complexas. Esses tipos de estado adicionais em transformWithStateInPandas também trazem benefícios de desempenho: ListState e MapState permitem atualizações parciais sem exigir que toda a estrutura de estado seja serializada e desserializada a cada operação de leitura e gravação. Isso pode melhorar significativamente a eficiência, especialmente com estados grandes ou complexos.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| Número de objetos de estado | 1 | muitos |
| Tipos de objetos de estado | GroupState (Semelhante a ValueState) | ValueStateListStateMapState |
Operações CRUD
Para fins de comparação, vamos comparar apenas o GroupState do applyInPandasWithState com o ValueState do transformWithStateInPandas, pois ListState e MapState não têm equivalentes. A maior diferença ao trabalhar com estado é que com applyInPandasWithState, o estado é passado para uma função; enquanto com transformWithStateInPandas, cada variável de estado precisa ser declarada na classe e instanciada em uma função init. Isso torna a criação/configuração do estado mais verbosa, mas também mais configurável. As outras operações CRUD ao trabalhar com estado permanecem praticamente inalteradas.
GroupState (applyInPandasWithState) | ValueState (transformWithStateInPandas) | |
|---|---|---|
| criar | A criação do estado é implícita. O estado é passado para a função através da variável de estado. | self._state é uma variável de instância na classe. Ela precisa ser declarada e instanciada. |
def func(
key: _,
pdf_iter: _,
state: GroupState
) -> Iterator[pandas.DataFrame]
| class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state = handle.getValueState("state", schema)
| |
| ler | state.get # ou gera PySparkValueError state.getOption # ou retorna None | self._state.get() # ou retorna None |
| atualizar | state.update(v) | self._state.update(v) |
| delete | state.remove() | self._state.clear() |
| existem | state.exists | self._state.exists() |
Vamos nos aprofundar um pouco em algumas das funcionalidades que essa nova API torna possível. Agora é possível
- Trabalhe com mais de um objeto de estado, e
- Crie objetos de estado com um tempo de vida (TTL). Isso é especialmente útil para casos de uso com requisitos regulatórios
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| Trabalhe com vários objetos de estado | Não é possível | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state1 = handle.getValueState("state1", schema1)
self._state2 = handle.getValueState("state2", schema2)
|
| Crie objetos de estado com um TTL | Não é possível | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state = handle.getValueState(
state_name="state",
schema="c LONG",
ttl_duration_ms=30 * 60 * 1000 # 30 min
)
|
Lendo Estado Interno
Depurar uma operação com estado costumava ser desafiador porque era difícil inspecionar o estado interno de uma consulta. Tanto applyInPandasWithState quanto transformWithStateInPandas facilitam isso, integrando-se perfeitamente com o leitor de fonte de dados de estado. Este recurso poderoso torna a resolução de problemas muito mais simples, permitindo que os usuários consultem variáveis de estado específicas, juntamente com uma variedade de outras opções suportadas.
Abaixo está um exemplo de como cada tipo de estado é exibido quando consultado. Note que todas as colunas, exceto para partition_id, são do tipo STRUCT. Para applyInPandasWithState todo o estado é agrupado como uma única linha. Então, cabe ao usuário separar as variáveis e explodir para obter uma boa decomposição. transformWithStateInPandas fornece uma divisão mais detalhada de cada variável de estado, e cada elemento já está explodido em sua própria linha para fácil exploração de dados.
| Operador | Classe de Estado | Ler statestore |
|---|---|---|
applyInPandasWithState | GroupState | display(
spark.read.format("statestore")
.load("/Volumes/foo/bar/baz")
)
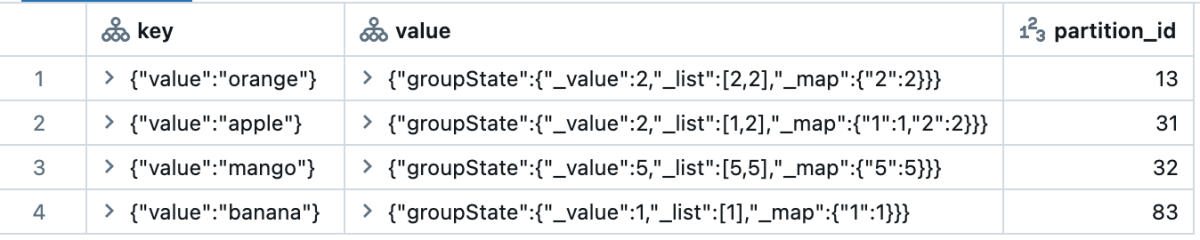 |
transformWithStateInPandas | ValueState | display(
spark.read.format("statestore")
.option("stateVarName", "valueState")
.load("/Volumes/foo/bar/baz")
)
 |
ListState | display(
spark.read.format("statestore")
.option("stateVarName", "listState")
.load("/Volumes/foo/bar/baz")
)
 | |
MapState | display(
spark.read.format("statestore")
.option("stateVarName", "mapState")
.load("/Volumes/foo/bar/baz")
)
 |
Configurando o estado inicial
applyInPandasWithState não fornece uma maneira de iniciar o pipeline com um estado inicial. Isso tornou as migrações de pipeline extremamente difíceis porque o novo pipeline não podia ser preenchido. Por outro lado, transformWithStateInPandas tem um método que facilita isso. A função de classe handleInitialState permite que os usuários personalizem a configuração do estado inicial e mais. Por exemplo, o usuário pode usar handleInitialState para configurar temporizadores também.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| Passando o estado inicial | Não é possível | .transformWithStateInPandas(
MySP(),
"fruit STRING, count LONG",
"append",
"processingtime",
grouped_df
)
|
| Personalizando o estado inicial | Não é possível | class MySP(StatefulProcessor):
def init(self, handle: StatefulProcessorHandle) -> None:
self._state = handle.getValueState("countState", "count LONG")
self.handle = handle
def handleInitialState(
self,
key: Tuple[str],
initialState: pd.DataFrame,
timerValues: TimerValues
) -> None:
self._state.update((initialState.at[0, "count"],))
self.handle.registerTimer(
timerValues.getCurrentProcessingTimeInMs() + 10000
)
|
Então, se você está interessado em migrar seu pipeline applyInPandasWithState para usar transformWithStateInPandas, você pode facilmente fazer isso usando o leitor de estado para migrar o estado interno do antigo pipeline para o novo.
Evolução do Esquema
A evolução do esquema é um aspecto crucial para gerenciar pipelines de dados em streaming, pois permite a modificação de estruturas de dados sem interromper o processamento de dados.
Com applyInPandasWithState, uma vez que uma consulta é iniciada, alterações no esquema de estado não são permitidas. applyInPandasWithState verifica a compatibilidade do esquema verificando a igualdade entre o esquema armazenado e o esquema ativo. Se um usuário tenta alterar o esquema, uma exceção é lançada, resultando na falha da consulta. Consequentemente, quaisquer alterações devem ser gerenciadas manualmente pelo usuário.
Os clientes geralmente recorrem a uma de duas soluções alternativas: ou eles iniciam a consulta a partir de um novo diretório de checkpoint e reprocessam o estado, ou eles encapsulam o esquema de estado usando formatos como JSON ou Avro e gerenciam o esquema explicitamente. Nenhuma dessas abordagens é particularmente favorecida na prática.
Por outro lado, transformWithStateInPandas oferece suporte mais robusto para evolução de esquema. Os usuários simplesmente precisam atualizar seus pipelines, e desde que a mudança de esquema seja compatível, o Apache Spark™ detectará e migrará automaticamente os dados para o novo esquema. As consultas podem continuar a ser executadas a partir do mesmo diretório de checkpoint, eliminando a necessidade de reconstruir o estado e reprocessar todos os dados do zero. A API permite definir novas variáveis de estado, remover as antigas e atualizar as existentes com apenas uma mudança de código.
Em resumo, o suporte do transformWithStateInPandas para a evolução do esquema simplifica significativamente a manutenção de pipelines de streaming de longa duração.
| Mudança de esquema | applyInPandasWithState | transformWithStateInPandas |
|---|---|---|
| Adicionar colunas (incluindo colunas aninhadas) | Não Suportado | Suportado |
| Remova colunas (incluindo colunas aninhadas) | Não Suportado | Suportado |
| Reordenar colunas | Não Suportado | Suportado |
| Alargamento de tipo (por exemplo, Int → Long) | Não Suportado | Suportado |
Trabalhando com dados em streaming
applyInPandasWithState tem uma única função que é acionada quando novos dados chegam ou um temporizador é disparado. É responsabilidade do usuário determinar a razão para a chamada da função. A maneira de determinar que novos dados de streaming chegaram é verificar se o estado não expirou. Portanto, é uma boa prática incluir um ramo de código separado para lidar com timeouts, ou há o risco de seu código não funcionar corretamente com timeouts.
Em contraste, transformWithStateInPandas usa funções diferentes para eventos diferentes:
handleInputRowsé chamado quando novos dados de streaming chegam, ehandleExpiredTimeré chamado quando um temporizador dispara.
Como resultado, não são necessárias verificações adicionais; a API gerencia isso para você.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| Trabalhar com novos dados | def func(key, rows, state):
if not state.hasTimedOut:
...
| classe MySP(StatefulProcessor):
def handleInputRows(self, key, rows, timerValues):
...
|
Trabalhando com temporizadores
Temporizadores vs. Timeouts
transformWithStateInPandas introduz o conceito de temporizadores, que são muito mais fáceis de configurar e entender do que os tempos limite de applyInPandasWithState’s.
Os timeouts só são acionados se nenhum dado novo chegar até um determinado momento. Além disso, cada chave applyInPandasWithState pode ter apenas um timeout, e o timeout é automaticamente excluído toda vez que a função é executada.
Em contraste, os temporizadores disparam em um determinado momento sem exceção. Você pode ter vários temporizadores para cada chave transformWithStateInPandas, e eles só são excluídos automaticamente quando o tempo designado é atingido.
Timeouts (applyInPandasWithState) | Temporizadores (transformWithStateInPandas) | |
|---|---|---|
| Número por chave | 1 | Muitos |
| Evento de gatilho | Se nenhum dado novo chegar até o tempo x | No momento x |
| Excluir evento | Em cada chamada de função | No momento x |
Essas diferenças podem parecer sutis, mas tornam o trabalho com o tempo muito mais simples. Por exemplo, digamos que você queria acionar uma ação às 9 da manhã e novamente às 5 da tarde. Com applyInPandasWithState, você precisaria criar primeiro o timeout das 9 AM, salvar o das 5 PM para mais tarde, e resetar o timeout toda vez que novos dados chegam. Com transformWithState, isso é fácil: registre dois temporizadores, e está feito.
Detectando que um timer foi acionado
Em applyInPandasWithState, estado e timeouts são unificados na classe GroupState, o que significa que os dois não são tratados separadamente. Para determinar se uma invocação de função é devido a um timeout expirado ou a uma nova entrada, o usuário precisa chamar explicitamente o método state.hasTimedOut e implementar a lógica if/else de acordo.
Com transformWithState, essas ginásticas não são mais necessárias. Temporizadores são desacoplados do estado e tratados como distintos uns dos outros. Quando um temporizador expira, o sistema aciona um método separado, handleExpiredTimer, dedicado exclusivamente ao tratamento de eventos de temporizador. Isso remove a necessidade de verificar se state.hasTimedOut ou não - o sistema faz isso por você.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| O temporizador disparou? | def func(chave, linhas, estado):
if estado.hasTimedOut:
# sim
...
else:
# não
...
| class MySP(StatefulProcessor):
def handleExpiredTimer(self, key, expiredTimerInfo, timerValues):
when = expiredTimerInfo.getExpiryTimeInMs()
...
|
CRUDing com Event Time vs. Processing Time
Uma peculiaridade na API applyInPandasWithState é a existência de métodos distintos para definir timeouts com base no tempo de processamento e no tempo do evento. Ao usar GroupStateTimeout.ProcessingTimeTimeout, o usuário define um tempo limite com setTimeoutDuration. Em contraste, para EventTimeTimeout, o usuário chama setTimeoutTimestamp em vez disso. Quando um método funciona, o outro gera um erro, e vice-versa. Além disso, para ambos os tempos de evento e de processamento, a única maneira de excluir um timeout é também excluir seu estado.
Em contraste, transformWithStateInPandas oferece uma abordagem mais direta para operações de timer. Sua API é consistente tanto para o tempo do evento quanto para o tempo de processamento; e fornece métodos para criar (registerTimer), ler (listTimers), e deletar (deleteTimer) um timer. Com transformWithStateInPandas, é possível criar vários timers para a mesma chave, o que simplifica muito o código necessário para emitir dados em vários momentos.
applyInPandasWithState | transformWithStateInPandas | |
|---|---|---|
| Criar um | state.setTimeoutTimestamp(tsMilli) | self.handle.registerTimer(tsMilli) |
| Criar muitos | Não é possível | self.handle.registerTimer(tsMilli_1) self.handle.registerTimer(tsMilli_2) |
| ler | state.oldTimeoutTimestamp | self.handle.listTimers() |
| atualizar | estado.setTimeoutTimestamp(tsMilli) # para EventTime estado.setTimeoutDuration(durationMilli) # para ProcessingTime | self.handle.deleteTimer(oldTsMilli) self.handle.registerTimer(newTsMilli) |
| delete | state.remove() # mas isso deleta o timeout e o estado | self.handle.deleteTimer(oldTsMilli) |
Trabalhando com Múltiplos Operadores com Estado
Encadear operadores stateful em um único pipeline tradicionalmente apresentou desafios. O operador applyInPandasWithState não permite que os usuários especifiquem qual coluna de saída está associada ao watermark. Como resultado, operadores stateful não podem ser colocados após um operador applyInPandasWithState. Consequentemente, os usuários tiveram que dividir seus cálculos com estado em vários pipelines, exigindo Kafka ou outras camadas de armazenamento como intermediários. Isso aumenta tanto o custo quanto a latência.
Em contraste, transformWithStateInPandas pode ser encadeado com segurança com outros operadores com estado. Os usuários simplesmente precisam especificar a coluna de tempo do evento ao adicioná-la ao pipeline, conforme ilustrado abaixo:
Esta abordagem permite que as informações de marca d'água passem para os operadores downstream, permitindo a filtragem de registros atrasados e a remoção de estado sem a necessidade de configurar um novo pipeline e armazenamento intermediário.
Conclusão
O novo operador transformWithStateInPandas no Apache Spark™ Structured Streaming oferece vantagens significativas sobre o antigo operador applyInPandasWithState. Ele oferece maior flexibilidade, capacidades aprimoradas de gerenciamento de estado e uma API mais amigável ao usuário. Com recursos como múltiplos objetos de estado, inspeção de estado e temporizadores personalizáveis, transformWithStateInPandas simplifica o desenvolvimento de aplicações de streaming complexas e com estado.
Embora applyInPandasWithState ainda possa ser familiar para usuários experientes, a funcionalidade e versatilidade melhoradas de transformWithState's o tornam a melhor escolha para cargas de trabalho de streaming modernas. Ao adotar transformWithStateInPandas, os desenvolvedores podem criar pipelines de streaming mais eficientes e sustentáveis. Experimente por si mesmo no Apache Spark™ 4.0, e Databricks Runtime 16.2 e acima.
| Recurso | applyInPandasWithState (Estado v1) | transformWithStateInPandas (Estado v2) |
|---|---|---|
| Idiomas Suportados | Scala, Java e Python | Scala, Java e Python |
| Modelo de Processamento | Baseado em Função | Orientado a Objetos |
| Processamento de Entrada | Processa linhas de entrada por chave de agrupamento | Processa linhas de entrada por chave de agrupamento |
| Processamento de Saída | Pode gerar saída opcionalmente | Pode gerar saída opcionalmente |
| Modos de Tempo Suportados | Tempo de Processamento & Tempo de Evento | Tempo de Processamento & Tempo de Evento |
| Modelagem de Estado de Grão Fino | Não suportado (apenas um único objeto de estado é passado) | Suportado (os usuários podem criar quaisquer variáveis de estado conforme necessário) |
| Tipos Compostos | Não suportado | Suportado (atualmente suporta Value, List e Map types) |
| Temporizadores | Não suportado | Suportado |
| Limpeza de Estado | Manual | Automatizado com suporte para TTL de estado |
| Inicialização de Estado | Suporte Parcial (disponível apenas em Scala) | Suportado em todas as linguagens |
| Encadeando Operadores no Modo de Tempo de Evento | Não Suportado | Suportado |
| Suporte ao Leitor de Fonte de Dados de Estado | Suportado | Suportado |
| Evolução do Modelo de Estado | Não Suportado | Suportado |
| Evolução do Esquema de Estado | Não Suportado | Suportado |
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.