A Evolução da Engenharia de Dados: como a computação sem servidor está transformando notebooks, trabalhos do Lakeflow e pipelines declarativas do Apache Spark
Saiba como o computo serverless da Databricks está fornecendo simplicidade, desempenho e confiabilidade incomparáveis para Notebooks, Lakeflow Jobs e Spark Declarative Pipelines.
por Aaron Davidson, Ihor Leshko, Justin Breese, Piyush Singh, Vivek Narasimhan, Prashanth Babu Velanati Venkata, Roland Fäustlin, Hemant Saxena e Mostafa Mokhtar
- O computo Serverless para Notebooks, Lakeflow Jobs e Spark Declarative Pipelines elimina a necessidade de gerenciar a infraestrutura e as atualizações do Spark.
- O computo Serverless está aprimorando automaticamente as cargas de trabalho e melhorou o desempenho em 80% e a eficiência de custo em até 70% no último ano, sem a necessidade de intervenção do usuário.
- O computo Serverless agora é o produto de computo mais estável da Databricks, dimensionando automaticamente os clusters para ajustar os volumes de dados crescentes e protegendo as cargas de trabalho contra interrupções e falta de capacidade na nuvem, resultando em 89% mais execuções bem-sucedidas.
A engenharia de dados atingiu um ponto de inflexão. À medida que as organizações dependem cada vez mais de IA e machine learning para impulsionar as decisões de negócios, a complexidade de gerenciar a infraestrutura de computação se tornou um gargalo crítico. Os avanços na computação serverless do Databricks ajudam as equipes a economizar até 20% do seu tempo em tarefas de rotina, como atualizar as versões do Databricks Runtime (DBR), gerenciar as configurações do cluster e solucionar problemas de infraestrutura. Hoje, estamos animados para compartilhar vários lançamentos de recursos recentes para a computação serverless do Databricks e como ela transformou fundamentalmente o paradigma, fornecendo simplicidade, desempenho e confiabilidade incomparáveis para Notebooks, Lakeflow Jobs e Spark Declarative Pipelines (SDP, formalmente conhecido como DLT). Por exemplo, a computação serverless oferece 70% de economia de custos com o modo de desempenho Standard em comparação com as cargas de trabalho otimizadas para desempenho e mais de 50% de economia de custos para cargas de trabalho Non-Spark. Além disso, as cargas de trabalho otimizadas para desempenho iniciam em segundos e normalmente são executadas duas vezes mais rápido. Versionless executou 25 atualizações de DBR em mais de 4,5 bilhões de cargas de trabalho com uma extraordinária taxa de sucesso de 99,998% no último ano.
O desafio do gerenciamento de infraestrutura é real
Toda plataforma de engenharia de dados deve lidar com um amplo conjunto de responsabilidades operacionais para manter os clusters Apache Spark tradicionais, como:
- As redes precisam ser configuradas com VPCs, gateways, intervalos de endereços IP e endpoints privados.
- A segurança e a conformidade exigem atenção cuidadosa ao gerenciamento de vulnerabilidades, criptografia e proteção contra exfiltração de dados.
- Considerações de eficiência, como dimensionamento de instâncias, utilização, pools de instâncias e otimização Delta, são essenciais para executar um ambiente de dados robusto.
- Manter runtimes atualizados com todas as melhorias de desempenho mais recentes é outro aspecto importante das operações da plataforma. Com duas versões de suporte de longo prazo do DBR a cada ano, é normal que as equipes avaliem as atualizações cuidadosamente para garantir a estabilidade, o desempenho e a compatibilidade com suas cargas de trabalho.
A computação serverless oferece um modelo operacional diferente: tarefas fundamentais, como redes e intervalos de IP, proteção de segurança, gerenciamento de ciclo de vida e atualizações de runtime, são todas tratadas automaticamente e continuamente otimizadas. Isso permite que as equipes adotem as otimizações mais recentes mais cedo e dediquem mais tempo à criação de produtos de dados e à entrega de valor de negócios, em vez de gerenciar a infraestrutura.
Computação Serverless: simples, com bom desempenho e sem manutenção
A computação serverless do Databricks é automática, com otimização automática gerenciada pelo Databricks e aborda esses desafios por meio de três princípios básicos:
- Simples: você só precisa escolher se deseja que a carga de trabalho seja executada rapidamente (modo otimizado para desempenho) ou com baixo custo (modo padrão). O Databricks ajusta constantemente e automaticamente para atingir a meta selecionada. Não são necessários botões, tipos de instância ou seleção de fator de escala.
- Com bom desempenho: com o apoio da infraestrutura otimizada do Databricks e um novo autoescalador, a computação serverless é iniciada em segundos, carrega bibliotecas dependentes em segundos do cache e normalmente é executada duas vezes mais rápido do que os clusters clássicos.
- Sem manutenção: o Databricks serverless dimensiona automaticamente sua computação horizontal e verticalmente para evitar problemas de falta de memória, protege você contra interrupções na nuvem e faz failover para tipos de instância disponíveis, resultando em um alto grau de tolerância a falhas. Também não tem versão, atualizando você automaticamente para as melhorias de desempenho mais recentes, mantendo a total compatibilidade com versões anteriores.
Serverless é simples
Desempenho e eficiência prontos para uso
Com a computação serverless para Notebooks, Spark Declarative Pipelines e Lakeflow Jobs, o Databricks seleciona automaticamente a infraestrutura certa para sua carga de trabalho e, em seguida, a otimiza continuamente com base em informações históricas da carga de trabalho. Assim, os usuários não precisam mais selecionar tipos de instância específicos, configurações de autoescalador ou otimizações, como o Photon. Nossa IA detecta automaticamente qual infraestrutura e configurações beneficiariam mais a carga de trabalho e as habilita automaticamente, por exemplo, o Photon só é usado quando a carga de trabalho específica se beneficia da aceleração do Photon.
Para cargas de trabalho que não exigem Spark, nossa seleção automática de infraestrutura garante que, quando o Spark não for necessário, uma VM menor seja provisionada dinamicamente. Essa abordagem pode oferecer mais de 50% de economia de custos e uma inicialização mais de 33% mais rápida em comparação com os clusters clássicos, simplesmente usando apenas os recursos de que você realmente precisa.
A introdução de modos de desempenho para Lakeflow Jobs e Spark Declarative Pipelines representa um avanço significativo na otimização de computação, pois permite que os usuários expressem para o que o Databricks deve otimizar. O modo otimizado para desempenho é iniciado em segundos e é executado normalmente duas vezes mais rápido do que os clusters clássicos. Este modo aproveita os pools de máquinas aquecidas e o dimensionamento agressivo de recursos para minimizar o tempo de processamento, tornando-o ideal para cargas de trabalho interativas e sensíveis ao tempo.
O modo Standard, que está disponível desde julho, adota uma abordagem diferente. Ao otimizar a eficiência de custos em vez de velocidade pura, ele oferece até 70% de economia de custos em comparação com o modo otimizado para desempenho, mantendo um desempenho competitivo. Este modo é perfeito para cargas de trabalho em lote, trabalhos agendados e pipelines onde a latência de inicialização de 4 a 6 minutos é aceitável em troca de reduções de custo significativas.
Os modos de desempenho permitem que os usuários se concentrem em insights de dados e necessidades de negócios específicas para seu caso de uso, em vez de gerenciar a infraestrutura. Essa simplicidade permite que os usuários dediquem mais tempo à geração de insights a partir de dados. Lembre-se de que o serverless em notebooks interativos sempre é iniciado em segundos e é executado rapidamente para aproveitar ao máximo o tempo dos usuários.
| Modo de computação serverless | Desempenho típico | Principais benefícios |
|---|---|---|
| Modo interativo para Notebooks Melhor experiência serverless para ciência de dados, plataforma totalmente gerenciada para Databricks Notebooks | < 10 segundos de inicialização, dimensionamento rápido |
|
| Modo otimizado para desempenho para Lakeflow Jobs e SDP Melhor experiência serverless para engenharia de dados, com inicialização e execução rápidas para Lakeflow Jobs e SDP sensíveis ao tempo | < 1 minuto de inicialização, dimensionamento rápido |
|
| Modo Standard para Lakeflow Jobs e Pipelines Experiência serverless de menor custo, plataforma totalmente gerenciada para executar Jobs e SDP | 4 a 6 minutos de inicialização, dimensionamento conservador |
|
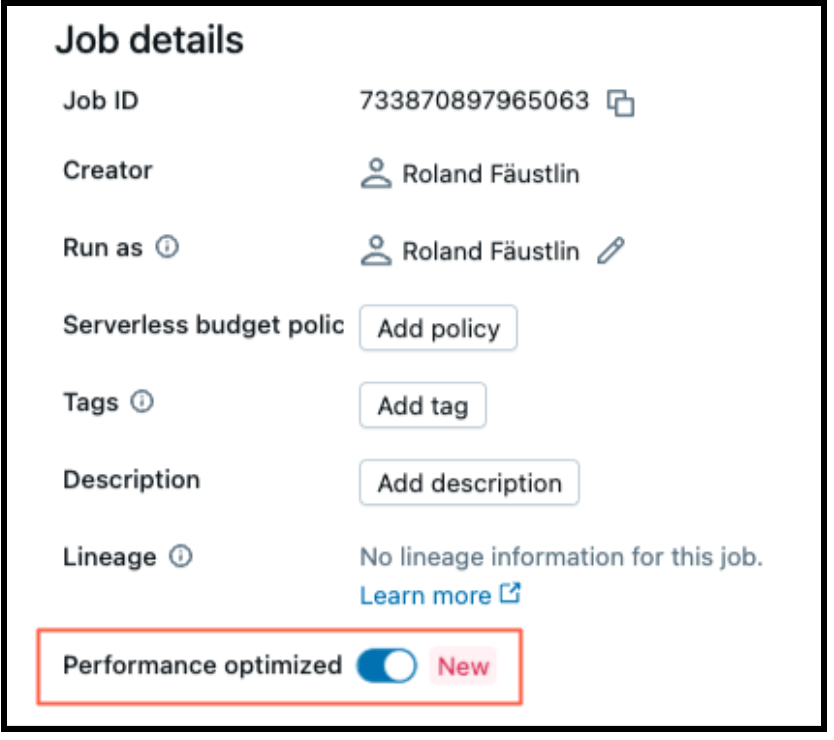
A computação serverless torna tão fácil ajustar o desempenho ou a eficiência quanto alternar uma opção. Quando "Otimizado para desempenho" está habilitado, suas cargas de trabalho serão iniciadas e executadas mais rapidamente. Quando está desabilitado, suas cargas de trabalho serão executadas no modo "Standard", otimizando a eficiência.
Gerenciamento e governança abrangentes de custos
O gerenciamento de custos de computação em equipes de engenharia de dados distribuídas tradicionalmente exigiu a junção de fontes de dados díspares e componentes de faturamento - um processo demorado que geralmente obscurece o verdadeiro custo total de propriedade. A computação serverless transforma essa complexidade em clareza por meio do faturamento unificado, consolidando todos os componentes de custo em uma única visualização compreensível. Os administradores obtêm visibilidade instantânea por meio de painéis de orçamento pré-construídos e consultas personalizáveis construídas em tabelas de sistema, eliminando assim a necessidade de trabalho manual de reconciliação entre diferentes provedores de serviços.
Para organizações que exigem chargebacks internos, as políticas de uso serverless permitem a aplicação de tags que agregam automaticamente os custos por equipe ou projeto, garantindo a atribuição e a responsabilidade precisas entre as unidades de negócios. A plataforma também oferece várias camadas de proteção contra gastos acidentais - timeouts inteligentes impedem que consultas descontroladas esgotem os orçamentos, enquanto as políticas de uso granulares dão aos administradores controle preciso sobre quem pode acessar a computação serverless e em que taxa eles podem consumir recursos, criando uma estrutura de governança abrangente que equilibra a inovação com a responsabilidade fiscal.
{kind=link}
Serverless: projetado para desempenho
O cache de ambiente elimina a sobrecarga de instalação de dependências
As configurações de computação tradicionais geralmente dependem de etapas de instalação para preparar o ambiente certo para cada execução, especialmente quando as equipes têm diversas necessidades de biblioteca. A computação serverless muda isso usando o cache de ambiente inteligente. Os usuários definem seu ambiente uma vez, e o Databricks analisa, baixa e instala automaticamente as bibliotecas necessárias, em seguida, cria um snapshot e o armazena em cache. As execuções futuras carregam o ambiente do cache em segundos - sem downloads ou instalações necessárias. Isso é especialmente útil para pequenas cargas de trabalho e é em média 2x mais rápido. Novos ambientes base padrão permitem que os administradores gerenciem centralmente ambientes pré-configurados para diferentes equipes, simplificando os fluxos de trabalho para analistas, cientistas de dados e engenheiros de ML.
A inicialização é uma prioridade para nós, e os Notebooks e Workflows serverless fizeram uma grande diferença. A computação serverless para notebooks torna isso fácil com apenas um clique. - Chiranjeevi Katta, engenheiro de dados da Airbus
O Spark Declarative Pipelines serverless reduz pela metade os tempos de execução sem comprometer os custos, aumenta a eficiência da engenharia e otimiza as operações de dados complexas, permitindo que as equipes se concentrem na inovação em vez da infraestrutura em ambientes de produção e desenvolvimento. - Cory Perkins, engenheiro sênior de dados e IA da Qorvo
Na prática, em todas as cargas de trabalho no Databricks, vemos que a computação serverless é em média 20% mais econômica do que as cargas de trabalho de cluster clássicas comparáveis e, embora os clientes paguem ao provedor de nuvem pela inicialização de clusters clássicos, o Databricks não cobra pela inicialização.
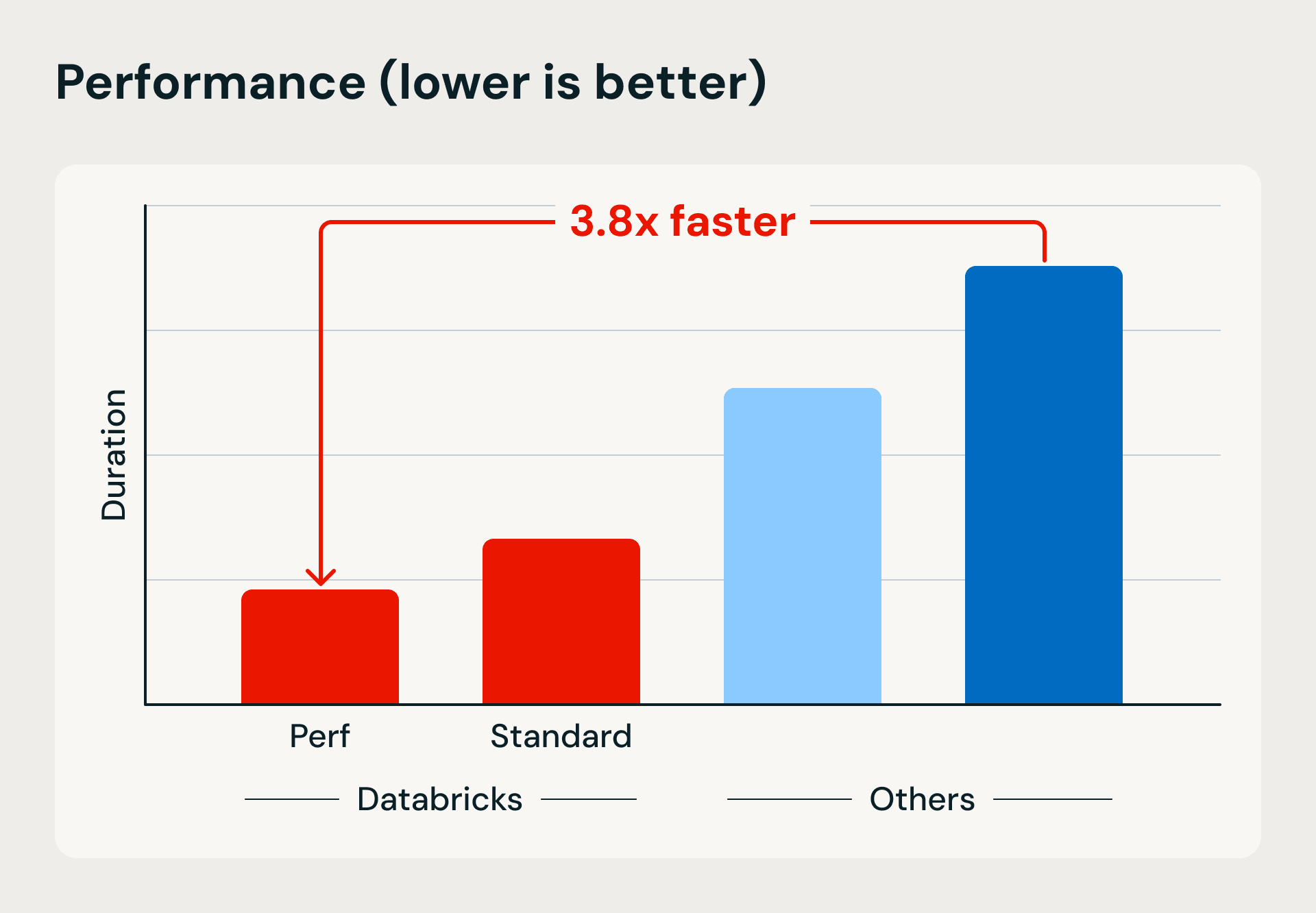
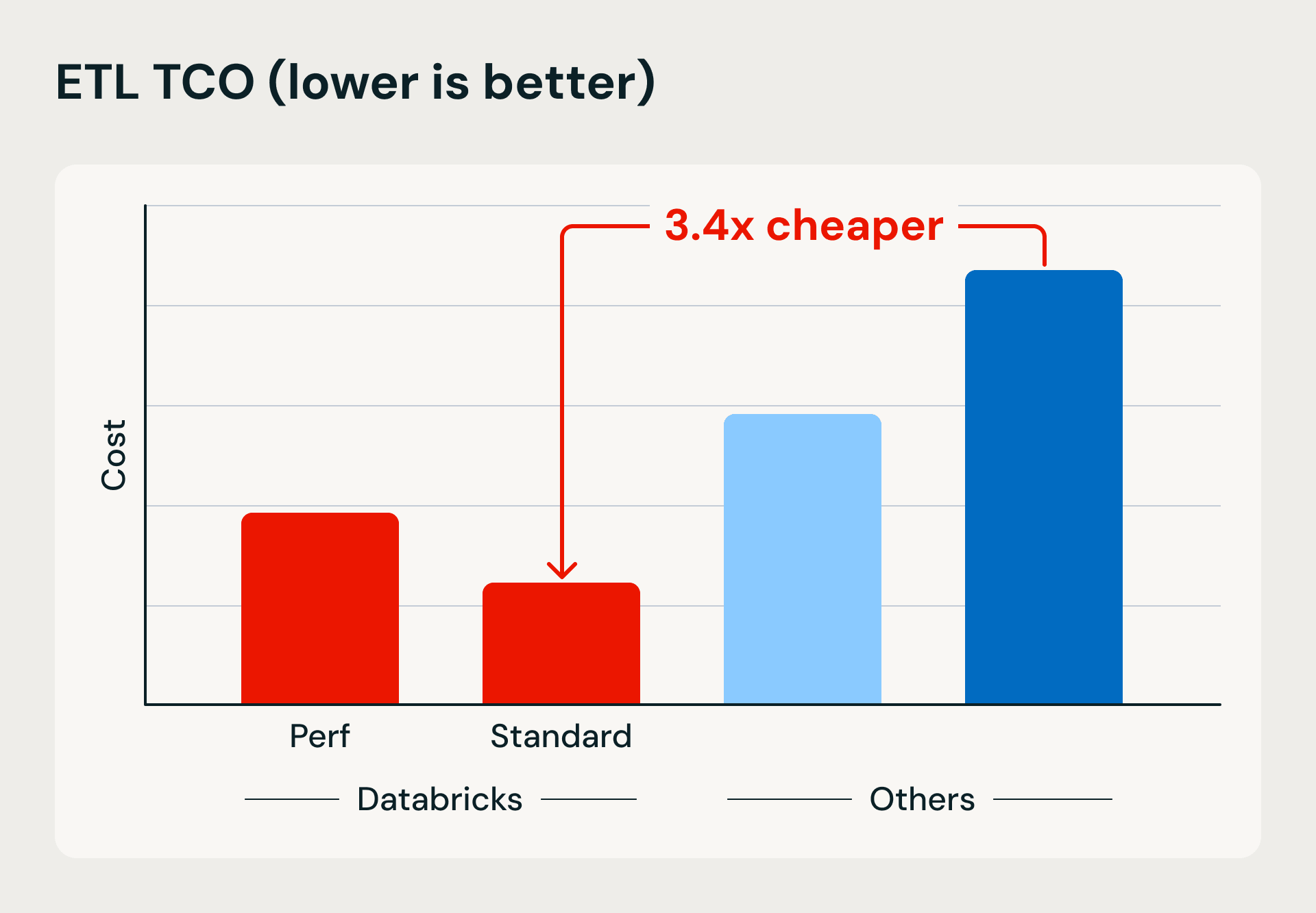
Comparação de desempenho e custo mostrando as vantagens da computação serverless do Databricks em velocidade de execução e eficiência. O benchmark carrega 1 TB no Bronze usando Lakeflow Jobs e upserts baseados em mesclagem, em seguida, refina e desduplica os dados em tabelas Silver e Gold.
Após a transição de nossos pipelines Databricks para computação 'serverless', a HP obteve uma economia de nuvem de mais de 32% e diminuiu o tempo de execução combinado dos trabalhos em 36%. O gerenciamento de infraestrutura sem esforço fornecido por 'serverless' tornou esta decisão uma escolha óbvia e estratégica. - Luis Alonso, chefe de estratégia e engenharia de dados da HP Marketing
O Spark Declarative Pipelines serverless no Google Cloud redefiniu nossa abordagem na Uplight, permitindo-nos executar cargas de trabalho ETL mais de duas vezes mais rápido, mantendo os custos baixos. A facilidade de uso, a otimização automática e a eficiência da computação serverless tornam o dimensionamento mais gerenciável e nos permitem priorizar a entrega de valor aos nossos clientes. - Micaela Christopher, diretora de ciência de dados e engenharia da Uplight
Historicamente, ir de dados brutos para a camada silver levava cerca de 16 minutos, mas depois de mudar para serverless, leva apenas cerca de 7 minutos. - Aaron Jepsen, diretor de operações de TI da Jet Linx Aviation
A melhoria significativa no tempo de inicialização, combinada com a configuração e manutenção reduzidas do DataOps, aumenta muito a produtividade e a eficiência. - Gal Doron, chefe de dados da AnyClip
Serverless é livre de manutenção
Seleção automática de infraestrutura: eliminando o gerenciamento manual de cluster
A abordagem clássica para o gerenciamento de cluster oferece aos usuários a maior liberdade na escolha de uma entre muitas combinações de configuração possíveis e no ajuste da configuração para atender aos requisitos de dados e negócios em constante mudança ao longo do tempo, incluindo a prevenção de erros de falta de memória ou gargalos de desempenho. A computação serverless muda fundamentalmente o jogo por meio da seleção de infraestrutura de IA. O sistema monitora continuamente os padrões de carga de trabalho e a utilização de recursos, dimensionando automaticamente para instâncias maiores quando restrições de memória são detectadas e fazendo failover contínuo para tipos de instância compatíveis durante interrupções do provedor de nuvem. Ao aproveitar o histórico abrangente de carga de trabalho e os dados de desempenho em tempo real, a computação serverless toma decisões de infraestrutura ideais sem intervenção humana, resultando em 89% menos interrupções em comparação com os ambientes de computação clássicos. Esta abordagem automatizada não só protege os usuários das limitações do provedor de nuvem, mas também permite a correção automática de problemas comuns de infraestrutura, tornando a computação serverless a oferta de computação mais estável e confiável do Databricks.
Com serverless [...], alcançamos uma melhora de 3 a 5 vezes na latência. O que costumava levar 10 minutos agora leva apenas 2 a 3 minutos. - Bryce Dugar, gerente de engenharia de dados do Cincinnati Reds
A disponibilidade de opções serverless alivia a sobrecarga na manutenção de engenharia e otimização de custos. Esta mudança se alinha perfeitamente com nossa estratégia abrangente de migrar todos os pipelines para ambientes serverless dentro do Databricks. - Bala Moorthy, gerente sênior de engenharia de dados da Compass
Atualizações sem versão para melhorias automáticas de desempenho e segurança
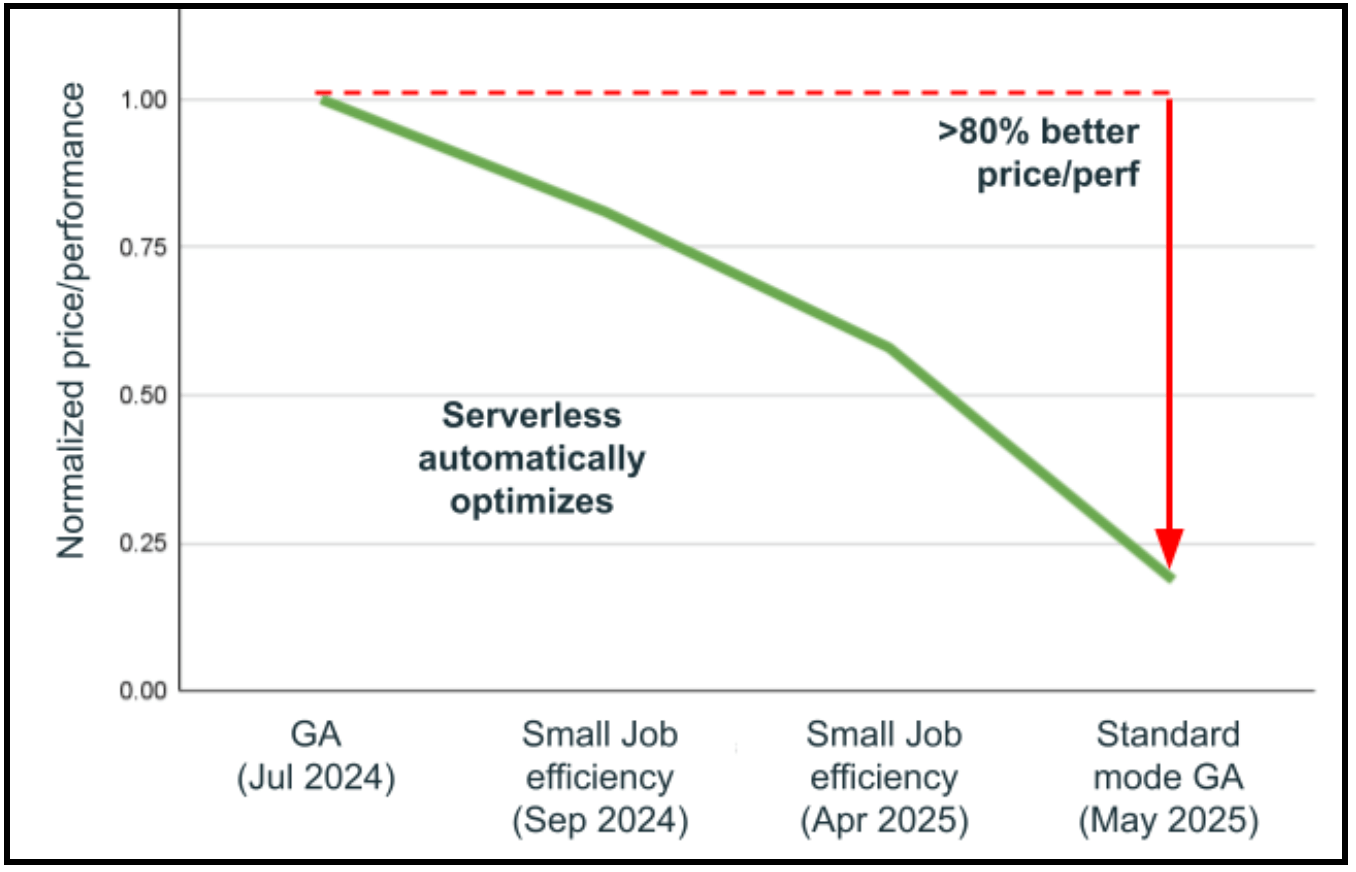
Talvez a capacidade mais transformadora da computação serverless seja sua arquitetura sem versão, que elimina a necessidade de atualizações manuais de runtime (DBR). Manter-se atualizado com o runtime mais recente traz melhorias significativas de desempenho. A computação serverless reimagina fundamentalmente este processo por meio de uma arquitetura revolucionária que permite a troca contínua de DBR sem quaisquer alterações interruptivas. Apenas no ano passado, o Databricks realizou automaticamente 25 atualizações de DBR em mais de 4,5 bilhões de cargas de trabalho com uma extraordinária taxa de sucesso de 99,998%. Mesmo nos raros casos em que problemas são detectados, as cargas de trabalho são automaticamente revertidas para a versão estável anterior enquanto os problemas são resolvidos em segundo plano, garantindo operações ininterruptas. Os resultados falam por si: A combinação de melhorias automáticas na seleção de infraestrutura e atualizações sem versão levou a um desempenho de preço 80% melhor em menos de um ano, sem exigir que os usuários tocassem na carga de trabalho. Esta abordagem sem versão significa que a computação serverless melhora continuamente, entregando automaticamente as otimizações Spark, patches de segurança e melhorias de desempenho mais recentes, enquanto as equipes de engenharia de dados se concentram inteiramente na construção de valor de negócios, em vez de gerenciar atualizações de infraestrutura.
Mais recursos serverless
A computação serverless agora oferece um conjunto abrangente de recursos avançados, incluindo:
- Os ambientes baseados em workspace permitem que os administradores gerenciem centralmente os ambientes do usuário com cache automático para inicialização rápida.
- O suporte a trabalhos Scala traz desenvolvimento IDE local com recursos de implantação de JAR fat.
- O suporte a GPU, incluindo A10s e H100s, e o suporte a SparkML abrem o serverless para machine learning e cargas de trabalho GenAI.
- Suspender e retomar torna o desenvolvimento e a depuração muito mais fáceis, permitindo tirar um snapshot dos estados de computação atuais e retomar o trabalho mais tarde sem perder nenhum trabalho e sem ter que pagar por clusters.
- Os recursos aprimorados de gerenciamento de custos incluem limites de taxa (em breve), duração de consulta prevista com avisos e tabelas de sistema expandidas para análise detalhada de custos.
Essas adições reforçam a posição da computação serverless como a plataforma de computação mais capaz e inteligente para engenharia de dados - e estamos apenas começando.
Comece sua jornada serverless hoje
A evidência é convincente - a computação serverless representa a evolução definitiva da infraestrutura de dados, oferecendo simplicidade, confiabilidade e otimização de desempenho sem precedentes. Com o modo Standard geralmente disponível e oferecendo até 70% de economia de custos, nunca houve um momento melhor para fazer a transição do gerenciamento complexo de cluster para a computação inteligente e automatizada. Se você precisa da execução extremamente rápida do modo otimizado para desempenho ou da eficiência de custo do modo Standard, a computação serverless elimina a complexidade da infraestrutura enquanto melhora continuamente suas cargas de trabalho por meio de atualizações automáticas de DBR e melhorias de desempenho.
- Inscreva-se em uma conta Databricks Serverless
- Computação Serverless para Notebooks, Lakeflow Jobs e Spark Declarative Pipelines
- Guia do profissional para computação Serverless
- Introdução ao SDP
- Demonstração do SDP
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.