The Evolution of Data Engineering: How Serverless Compute is Transforming Notebooks, Lakeflow Jobs, and Spark Declarative Pipelines
Learn how Databricks serverless compute is providing unmatched simplicity, performance, and reliability for Notebooks, Lakeflow Jobs, and Spark Declarative Pipelines.
by Aaron Davidson, Ihor Leshko, Justin Breese, Piyush Singh, Vivek Narasimhan, Prashanth Babu Velanati Venkata, Roland Fäustlin, Hemant Saxena, Mostafa Mokhtar and Zach Williams
- Serverless compute for Notebooks, Lakeflow Jobs, and Spark Declarative Pipelines eliminates the need to manage infrastructure and Spark upgrades
- Serverless compute is automatically improving workloads and has improved performance by 80% and cost efficiency by up to 70% over the last year without the need for user intervention
- Serverless compute is now Databricks’ most stable compute product, automatically sizing clusters to fit increasing data volumes and shielding workloads from cloud outages and stock-outs, resulting in 89% more successful runs
Data engineering has reached an inflection point. As organizations increasingly rely on AI and machine learning to drive business decisions, the complexity of managing compute infrastructure has become a critical bottleneck. Advances in Databricks serverless compute help teams save up to 20% of their time on routine tasks such as upgrading Databricks Runtime (DBR) versions, managing cluster settings, and troubleshooting infrastructure problems. Today, we're excited to share several recent feature launches for Databricks serverless compute and how it has fundamentally transformed the paradigm by providing unmatched simplicity, performance, and reliability for Notebooks, Lakeflow Jobs, and Spark Declarative Pipelines (SDP, formally known as DLT). For example, serverless compute offers 70% cost savings with the Standard performance mode compared to Performance-optimized workloads, and over 50% cost savings for Non-Spark workloads. Additionally, Performance-optimized workloads start in seconds and typically run twice as fast. Versionless has executed 25 DBR upgrades across more than 4.5 billion workloads with an extraordinary 99.998% success rate in the last year.
The Infrastructure Management Challenge is Real
Every data engineering platform must handle a broad set of operational responsibilities to maintain traditional Spark clusters, such as:
- Networks need to be set up with VPCs, gateways, IP address ranges, and private endpoints.
- Security and compliance require careful attention to vulnerability management, encryption, and protection against data exfiltration.
- Efficiency considerations, such as instance sizing, utilization, instance pools, and Delta optimization, are essential for running a robust data environment.
- Maintaining up-to-date runtimes with all the latest performance improvements is another important aspect of platform operations. With two long-term support DBR releases each year, it’s normal for teams to evaluate upgrades thoughtfully to ensure stability, performance, and compatibility with their workloads.
Serverless compute offers a different operating model: foundational tasks, like networking and IP ranges, security hardening, lifecycle management, and runtime upgrades, are all handled automatically and continuously optimized. This allows teams to adopt the latest optimizations sooner and shift more of their time toward building data products and delivering business value rather than managing infrastructure.
Serverless Compute: Simple, Performant, Maintenance-free
Databricks serverless compute is hands-off, auto-optimizing compute managed by Databricks and addresses these challenges through three core principles:
- Simple: You just need to choose whether you want the workload to run fast (performance-optimized mode) or cost-efficiently (standard mode). Databricks constantly and automatically fine-tunes to achieve the selected goal. No knobs, instance types, or scale factor selection needed.
- Performant: Backed by Databricks’ optimized infrastructure and a new autoscaler, serverless compute starts in seconds, loads dependent libraries in seconds from cache, and typically runs twice as fast as classic clusters.
- Maintenance-free: Databricks serverless automatically scales your compute horizontally and vertically to prevent out-of-memory issues, shields you from cloud outages, and fails over to available instance types, resulting in a high degree of fault-tolerance. It is also versionless, automatically upgrading you to the latest performance improvements while staying fully backwards compatible.
Serverless is Simple
Performance and Efficiency out of the Box
With serverless compute for Notebooks, Spark Declarative Pipelines, and Lakeflow Jobs, Databricks automatically selects the right infrastructure for your workload and then continuously optimizes it based on historical workload information. Thus, users no longer have to select specific instance types, autoscaler settings, or optimizations, such as Photon. Our AI automatically detects which infrastructure and settings would benefit the workload the most and enables those automatically, e.g., Photon is only used when the specific workload benefits from Photon acceleration.
For workloads that do not require Spark, our automatic infrastructure selection ensures that when Spark isn't needed, a smaller VM is provisioned on the fly. This approach can deliver over 50% cost savings and more than 33% faster startup compared to classic clusters, simply by using just the resources you actually need.
The introduction of performance modes for Lakeflow Jobs and Spark Declarative Pipelines represents a significant advancement in compute optimization, as it allows users to express what Databricks should optimize for. Performance Optimized mode starts up in seconds and executes typically twice as fast as classic clusters. This mode leverages warm pools of machines and aggressive resource scaling to minimize processing time, making it ideal for interactive and time-sensitive workloads.
Standard mode, which has been generally available since July, takes a different approach. By optimizing for cost efficiency rather than pure speed, it delivers up to 70% cost savings compared to Performance Optimized mode while maintaining competitive performance. This mode is perfect for batch workloads, scheduled jobs, and pipelines where 4-6 minutes startup latency is acceptable in exchange for significant cost reductions.
Performance modes enable users to focus on data insights and business needs specific to their use case, rather than managing infrastructure. This simplicity allows users to dedicate more time to generating insights from data. Keep in mind that serverless in interactive notebooks always starts in seconds and runs fast to make the most of users’ time.
| Serverless compute mode | Typical performance | Key benefits |
|---|---|---|
| Interactive mode for Notebooks Best serverless experience for data science, fully managed platform for Databricks Notebooks | < 10 seconds startup, fast scaling |
|
| Performance-optimized mode for Lakeflow Jobs and SDP Best serverless experience for data engineering, with fast startup and execution for time-sensitive Lakeflow Jobs and SDP | < 30 seconds startup, fast scaling |
|
| Standard mode for Lakeflow Jobs and Pipelines Lower cost serverless experience, fully managed platform to run Jobs and SDP | 4-6 minutes startup, conservative scaling |
|
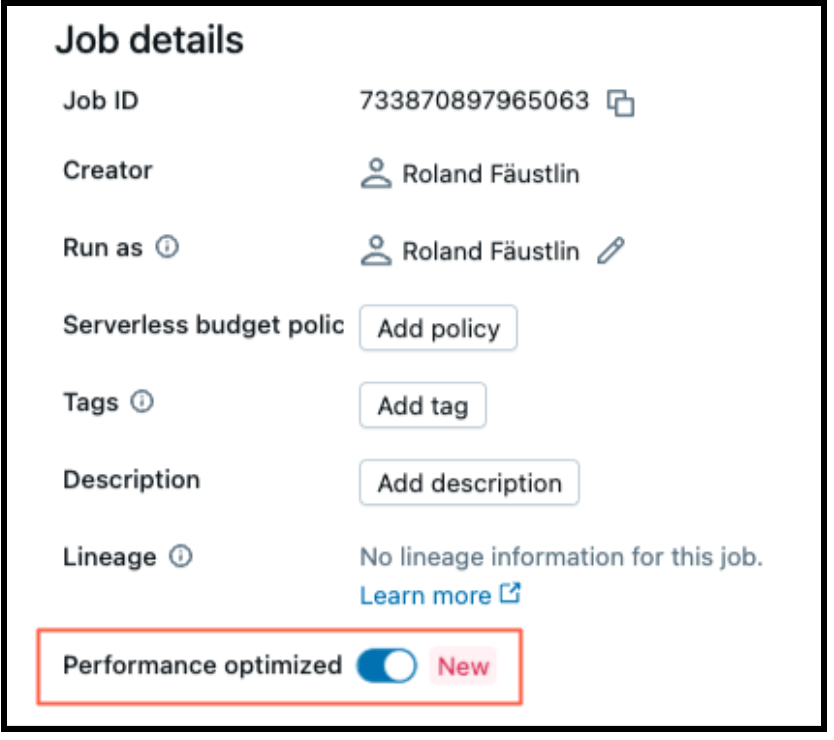
Serverless compute makes it as easy to tune for performance or efficiency as flipping a toggle. When “Performance optimized” is enabled, your workloads will start and execute faster. When it’s disabled, your workloads will run in “Standard” mode, optimizing efficiency.
Comprehensive Cost Management and Governance
Managing compute costs across distributed data engineering teams has traditionally required piecing together disparate data sources and billing components - a time-consuming process that often obscures the true total cost of ownership. Serverless compute transforms this complexity into clarity through unified billing, consolidating all cost components into a single, comprehensible view. Administrators gain instant visibility through pre-built budget dashboards and customizable queries built on system tables, thereby eliminating the need for manual reconciliation work across different service providers.
For organizations requiring internal chargebacks, serverless usage policies enable tag enforcement that automatically aggregates costs by team or project, ensuring accurate attribution and accountability across business units. The platform also provides multiple layers of protection against accidental spend—intelligent timeouts prevent runaway queries from depleting budgets, while granular usage policies give administrators precise control over who can access serverless compute and at what rate they can consume resources, creating a comprehensive governance framework that balances innovation with fiscal responsibility.
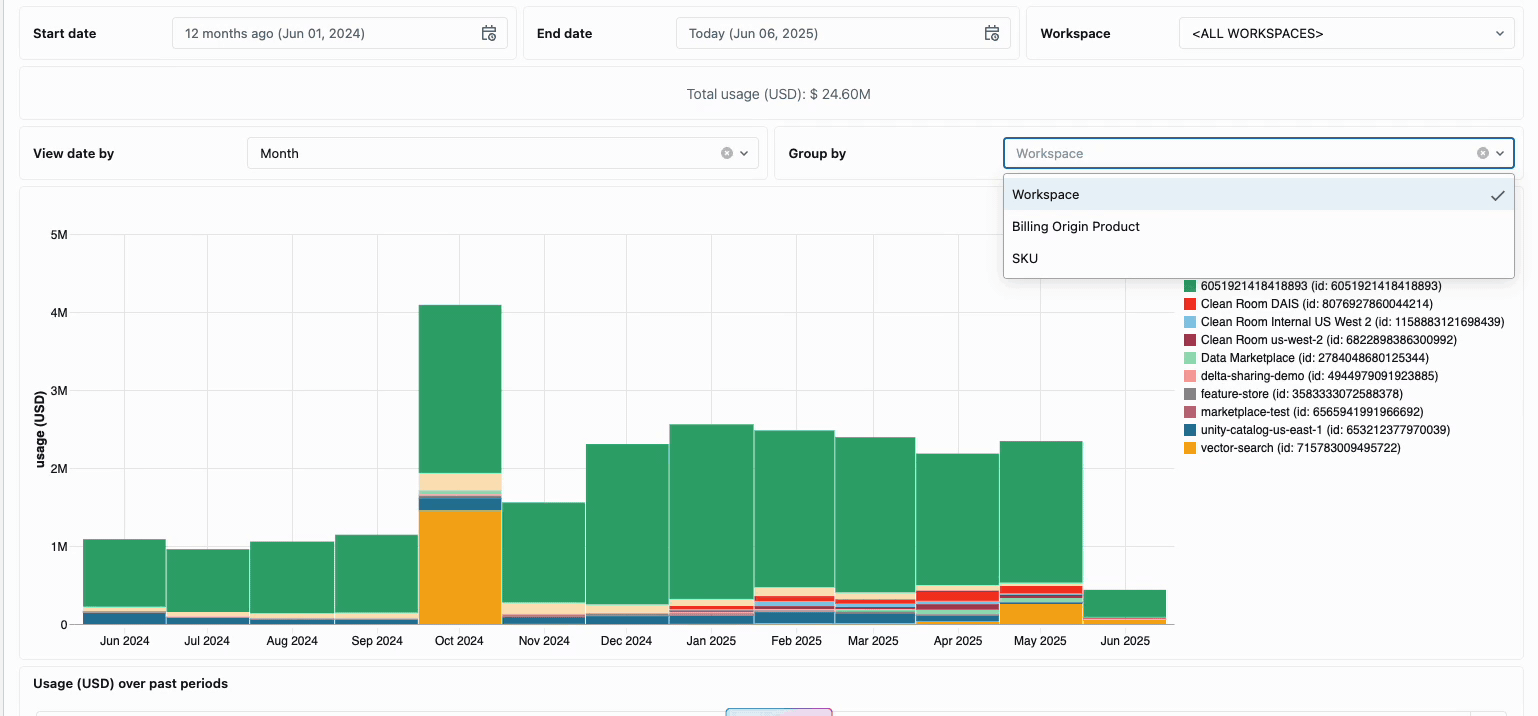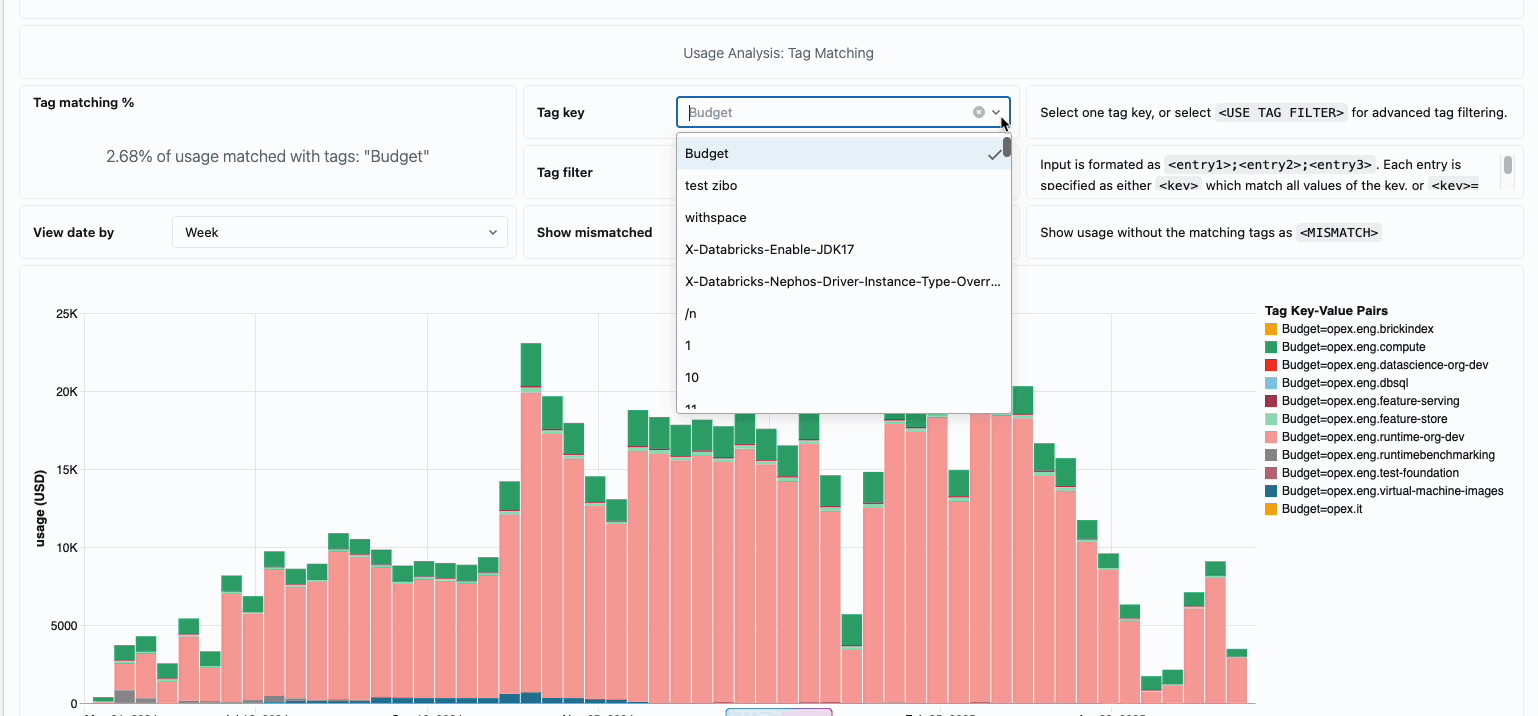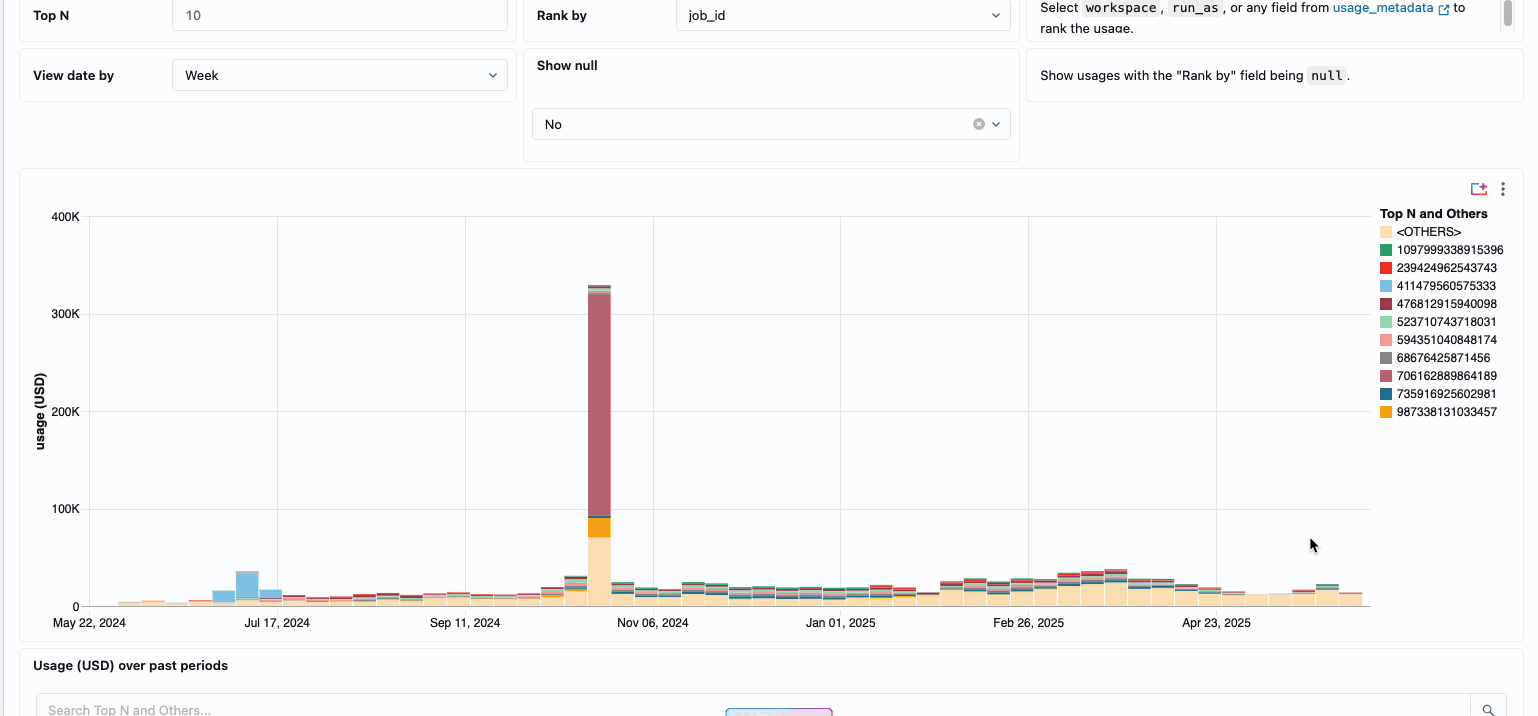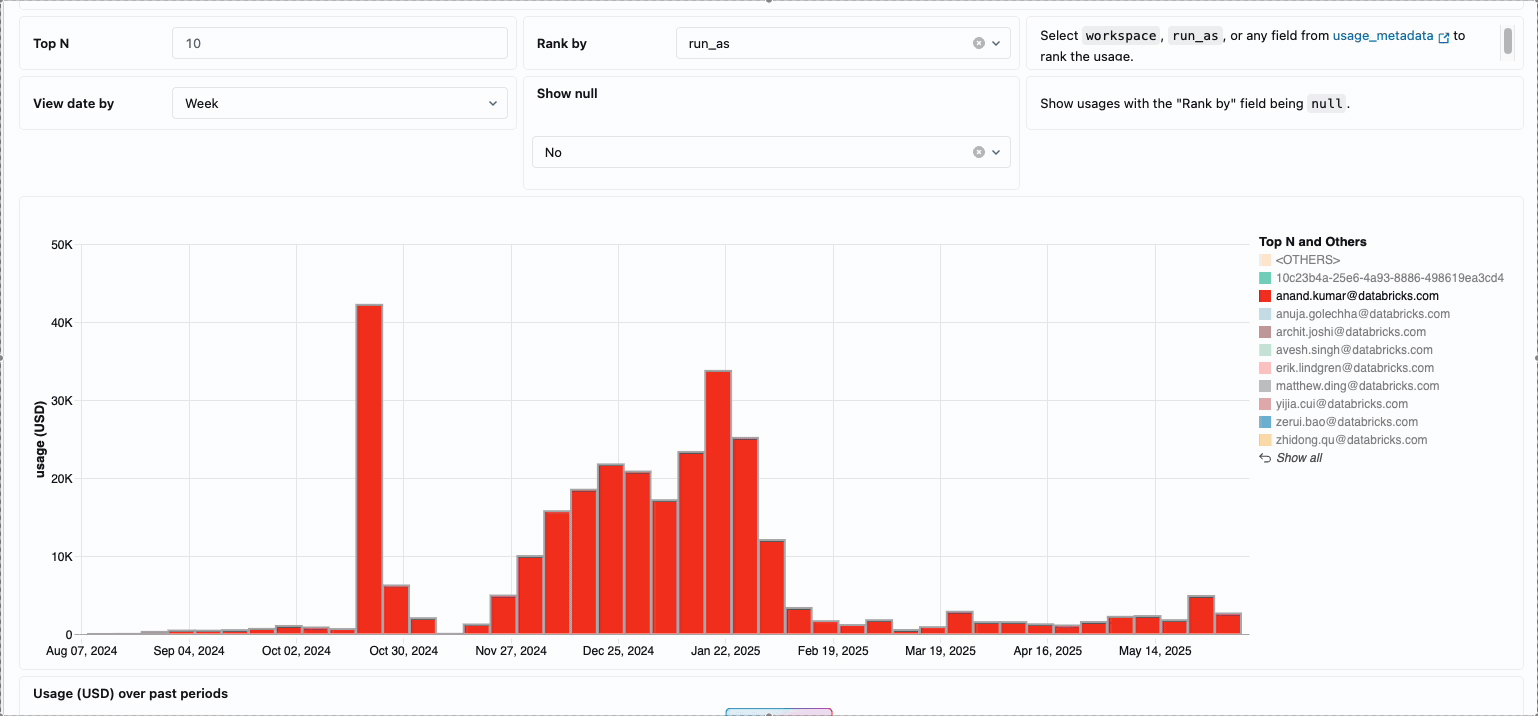
Serverless: Engineered for Performance
Environment Caching Eliminates Dependency Installation Overhead
Traditional compute setups often rely on installation steps to prepare the right environment for each run, especially when teams have diverse library needs. Serverless compute changes this by using intelligent environment caching. Users define their environment once, and Databricks automatically analyzes, downloads, and installs necessary libraries, then creates a snapshot and caches it. Future runs load the environment from cache in seconds—no downloads or installations needed. This is especially useful for small workloads and is on average 2x faster. New default base environments let admins centrally manage pre-configured environments for different teams, simplifying workflows for analysts, data scientists, and ML engineers.
Startup is a priority for us, and serverless Notebooks and Workflows have made a huge difference. Serverless compute for notebooks makes it easy with just a single click.—Chiranjeevi Katta, Data Engineer at Airbus
Serverless Spark Declarative Pipelines halve execution times without compromising costs, enhance engineering efficiency, and streamline complex data operations, allowing teams to focus on innovation rather than infrastructure in both production and development environments. —Cory Perkins, Sr. Data & AI Engineer at Qorvo
In practice, across all workloads on Databricks, we see that serverless compute is on average 20% more cost-efficient than comparable classic cluster workloads, and while customers pay their cloud provider for the startup of classic clusters, Databricks does not charge for startup.
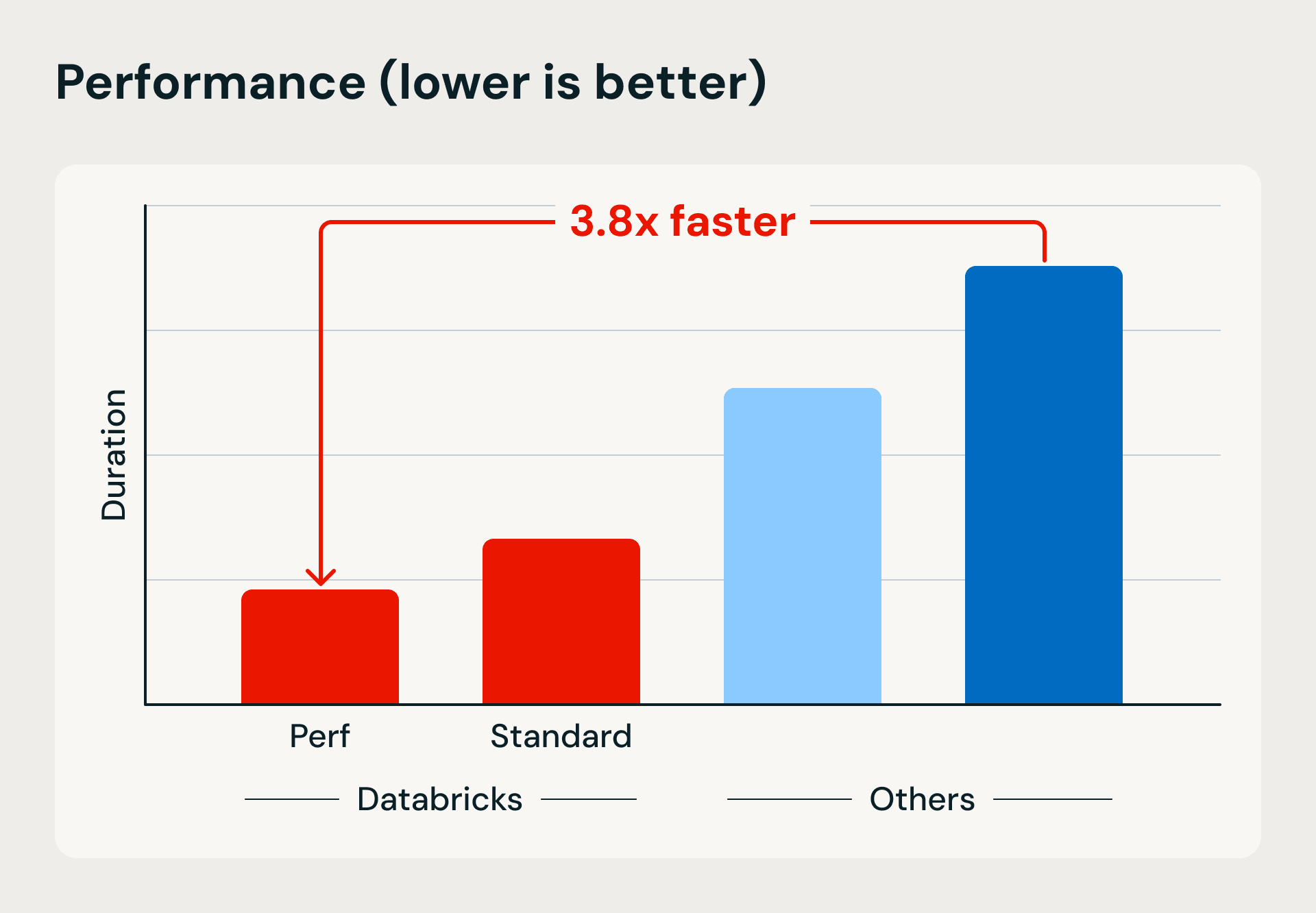
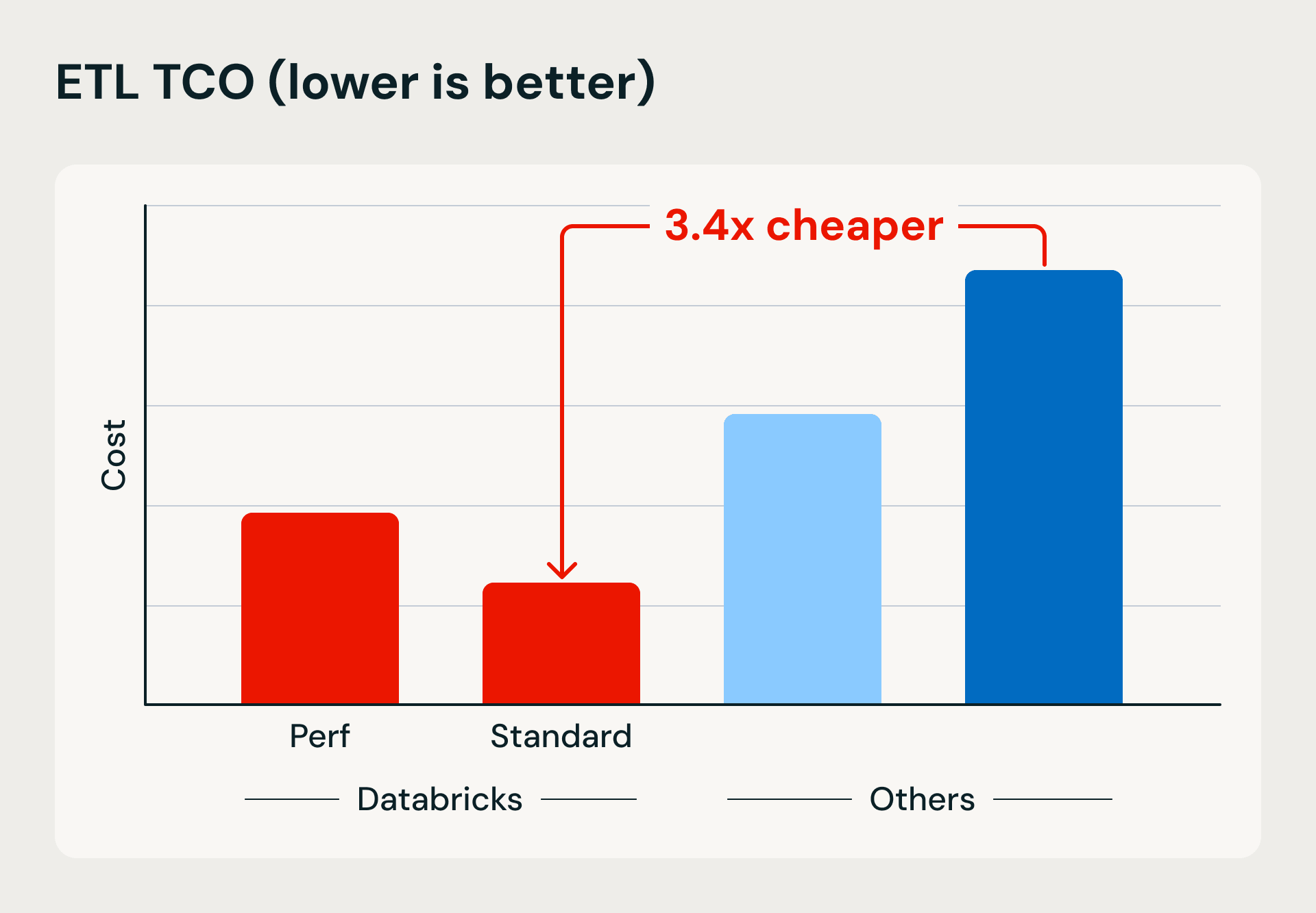
Performance and cost comparison showing Databricks’ serverless compute advantages in execution speed and efficiency. The benchmark loads 1TB into Bronze using Lakeflow Jobs and merge-based upserts, then refines and deduplicates the data into Silver and Gold tables.
After transitioning our Databricks pipelines to 'serverless' compute, HP realized cloud savings of over 32% and decreased the combined runtime of jobs by 36%. The effortless infrastructure management provided by 'serverless' made this decision an obvious and strategic choice. —Luis Alonso, Head of Data Strategy & Engineering at HP Marketing
Serverless Spark Declarative Pipelines on Google Cloud have redefined our approach at Uplight, enabling us to run ETL workloads more than twice as fast while keeping costs down. The ease of use, auto-optimization, and efficiency of serverless compute makes scaling more manageable and allow us to prioritize delivering value to our customers. —Micaela Christopher, Director of Data Science & Engineering at Uplight
Historically going from raw data to the silver layer took us about 16 minutes, but after switching to serverless, it's only about 7 minutes. —Aaron Jepsen, Director IT Operations at Jet Linx Aviation
[The] significant improvement in start-up time, combined with reduced DataOps configuration and maintenance, greatly enhances productivity and efficiency. —Gal Doron, Head of Data at AnyClip
Migrating to a serveless architecture reduced our ingestion and processing costs and eliminated the need to manage clusters. We can spin up new tasks much faster, without provisioning, tuning, or worrying about upgrades that used to require dedicated projects. —Giuseppe Guarnuto, Head of Data Governance and Quality at Plenitude
Serverless is Maintenance-Free
Automatic Infrastructure Selection: Eliminating Manual Cluster Management
The classic approach to cluster management provides users the most freedom in picking one of many possible configuration combinations and adjusting the configuration to meet the changing data and business requirements over time, including the prevention of out-of-memory errors or performance bottlenecks. Serverless compute fundamentally changes the game through AI infrastructure selection. The system continuously monitors workload patterns and resource utilization, automatically scaling up to larger instances when memory constraints are detected and seamlessly failing over to compatible instance types during cloud provider outages. By leveraging comprehensive workload history and real-time performance data, serverless compute makes optimal infrastructure decisions without human intervention, resulting in 89% fewer outages compared to classic compute environments. This automated approach not only shields users from cloud provider limitations but also enables automatic remediation of common infrastructure issues, making serverless compute Databricks' most stable and reliable compute offering.
With serverless [...], we’ve achieved a 3–5x improvement in latency. What used to take 10 minutes now takes just 2–3 minutes. —Bryce Dugar, Data Engineering Manager at Cincinnati Reds
The availability of serverless options eases the overhead on engineering maintenance and cost optimization. This move aligns seamlessly with our overarching strategy to migrate all pipelines to serverless environments within Databricks. —Bala Moorthy, Senior Data Engineering Manager at Compass
Versionless upgrades for Automatic Performance and Security Improvements
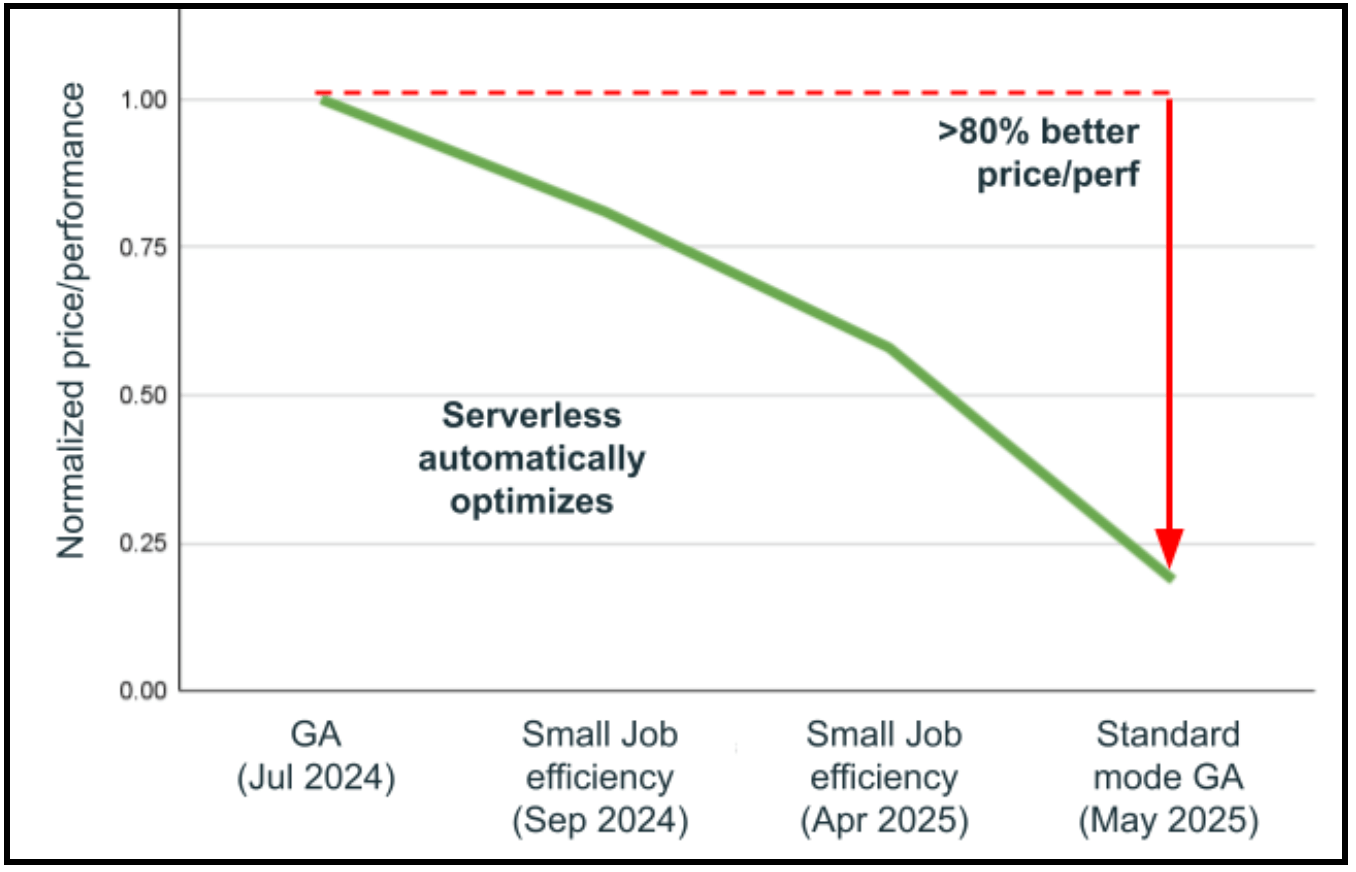
Perhaps the most transformative capability of serverless compute is its versionless architecture, which eliminates the need for manual runtime (DBR) upgrades. Keeping up with the latest runtime brings significant performance improvements. Serverless compute fundamentally reimagines this process through a revolutionary architecture that enables seamless DBR swapping without any breaking changes. Over the past year alone, Databricks has automatically performed 25 DBR upgrades across more than 4.5 billion workloads with an extraordinary 99.998% success rate. Even in the rare cases where issues are detected, workloads are automatically rolled back to the previous stable version while problems are resolved in the background, ensuring uninterrupted operations. The results speak for themselves: The combination of automatic infrastructure selection improvements and versionless upgrades has led to more than 80% better price-performance in under a year, without requiring users to touch the workload. This versionless approach means serverless compute continuously improves, automatically delivering the latest Spark optimizations, security patches, and performance enhancements while data engineering teams focus entirely on building business value rather than managing infrastructure upgrades.
More serverless features
Serverless compute now delivers a comprehensive set of advanced capabilities, including:
- Workspace-based environments enable admins to centrally manage user environments with automatic caching for fast startup.
- Scala jobs support brings local IDE development with fat JAR deployment capabilities.
- GPU support, including A10s and H100s, and SparkML support open serverless to machine learning and GenAI workloads.
- Suspend and resume makes development and debugging much easier by being able to snapshot current compute states and resume work later without losing any work and without having to pay for clusters.
- Enhanced cost management features include rate limits (coming soon), predicted query duration with warnings, and expanded system tables for detailed cost analysis.
These additions reinforce serverless compute's position as the most capable and intelligent compute platform for data engineering - and we’re just getting started.
Start Your Serverless Journey Today
The evidence is compelling—serverless compute represents the definitive evolution of data infrastructure, delivering unprecedented simplicity, reliability, and performance optimization. With Standard mode generally available and offering up to 70% cost savings, there has never been a better time to transition from complex cluster management to intelligent, automated compute. Whether you need the lightning-fast execution of Performance Optimized mode or the cost efficiency of Standard mode, serverless compute eliminates infrastructure complexity while continuously improving your workloads through automatic DBR upgrades and performance enhancements.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.