Analisando o Apache Spark™ sem versão: atualizações com tecnologia de IA e estabilidade contínua para 2 bilhões de cargas de trabalho
Como eliminamos os upgrades manuais do Spark da plataforma
por Justin Breese, Vijayan Prabhakaran, Amit Shukla, Martin Grund, Stefania Leone, Chris Munson, Tatiana Romanova e Lennart Kats
- As atualizações do Apache Spark™ agora são automáticas e sem versão para Notebooks e Jobs Serverless, eliminando a necessidade de migrações ou alterações de código.
- Uma API de cliente estável e um gerenciamento de lançamentos com tecnologia de IA mantêm os workloads confiáveis, ao mesmo tempo que entregam os recursos e as correções mais recentes.
- Mais de dois bilhões de workloads foram atualizados com uma taxa de sucesso de 99,99%, provando que o sistema funciona em grande escala.
Atualizar o Apache Spark™ nunca foi fácil. Cada versão principal traz melhorias de desempenho, correções de bugs e novos recursos, mas o processo é doloroso. A maioria dos usuários do Spark sabe como funciona. As cargas de trabalho falham, as APIs mudam e os desenvolvedores podem passar semanas corrigindo jobs apenas para se atualizar. Isso faz com que a adoção de novos recursos, melhorias de desempenho e correções de bugs e segurança leve muito mais tempo.
Na Databricks, queríamos eliminar totalmente esse atrito. O resultado é o Versionless Spark, uma nova maneira de executar o Spark que oferece atualizações contínuas, zero alterações de código e estabilidade incomparável. Nos últimos 18 meses, desde o lançamento dos Serverless Notebooks and Jobs, o Versionless Spark atualizou automaticamente mais de 2 bilhões de cargas de trabalho do Spark em 25 versões do Databricks Runtime, incluindo as principais versões do Spark, sem nenhuma intervenção do usuário.
Neste blog, compartilharemos como criamos o Spark sem versão, destacaremos os resultados que vimos e mostraremos onde encontrar mais detalhes em nosso artigo da SIGMOD 2025 publicado recentemente.
Um novo caminho a seguir: API pública estável por meio de um cliente com versão
Para tornar os upgrades transparentes e devolver o tempo aos usuários do Databricks, precisávamos ter uma API pública e estável do Spark para que pudéssemos atualizar o servidor de forma transparente. Conseguimos isso com uma API de cliente estável e versionada, baseada em Spark Connect, que desacopla o cliente do servidor Spark, permitindo que o Databricks atualize o servidor automaticamente.
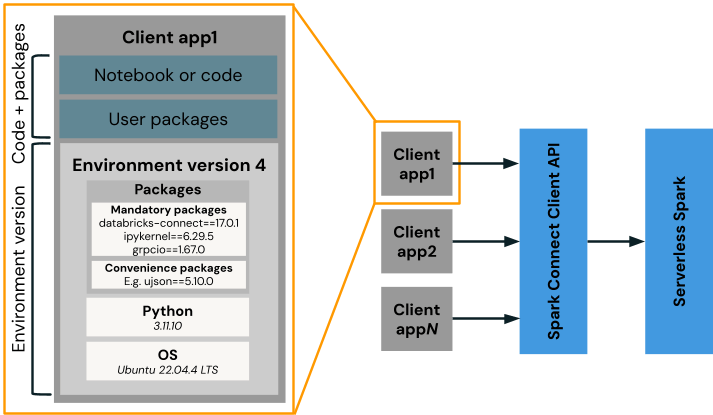
A versão de ambiente do Databricks serve como uma imagem base que contém pacotes de client como Spark Connect, Python e dependências do pip. O código do usuário e pacotes adicionais são executados neste ambiente (por exemplo, Aplicativo client 1) e se comunica com nosso serviço Spark serverless. O Databricks lança periodicamente novas versões de ambiente, cada uma com três anos de suporte, semelhante ao DBR LTS. Por padrão, novas cargas de trabalho usam a versão mais recente, mas os usuários podem continuar executando em versões mais antigas e com suporte, se preferirem.
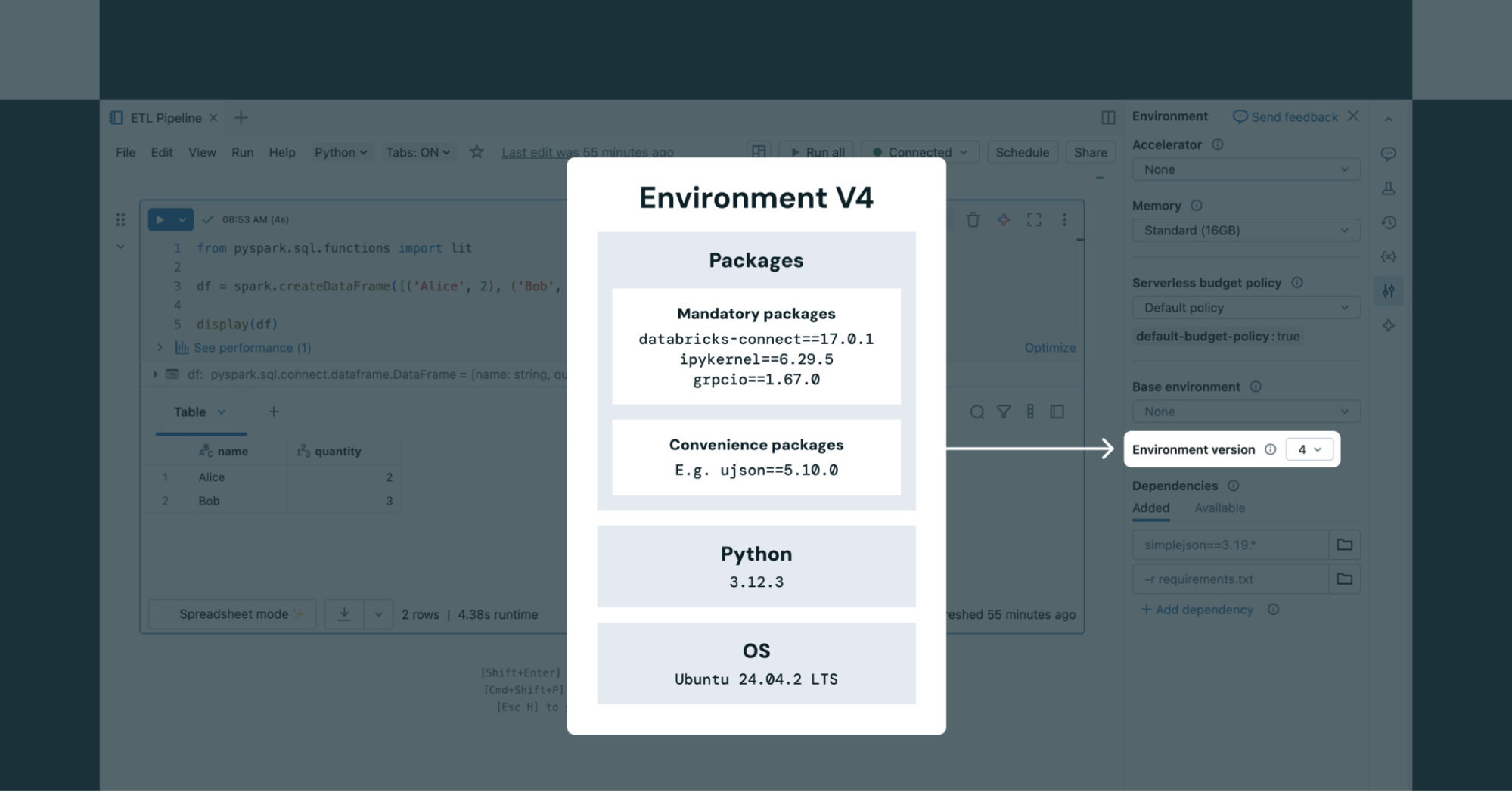
Ao usar Notebooks sem servidor, os usuários podem escolher qualquer uma das versões de ambiente compatíveis no painel "Ambiente" do notebook (conforme mostrado na Figura 2). Para jobs sem servidor, a versão do ambiente é definida por meio da API de Job.
Upgrades automáticos e reversões com tecnologia de IA
Fornecer aos nossos usuários atualizações frequentes de segurança, confiabilidade e desempenho é fundamental ao executar workloads automatizados no Databricks. Isso deve ser feito automaticamente e sem comprometer a estabilidade, especialmente para pipelines de produção. Isso é feito por meio do nosso Release Stability System (RSS) com tecnologia de IA, que combina a assinatura exclusiva de um workload automatizado com metadados de execução para detectar workloads com regressão em novas versões do servidor e reverter automaticamente as execuções subsequentes para a versão anterior do servidor. O RSS contém vários componentes:
- Cada workload tem uma impressão digital de workload para identificar execuções repetidas do mesmo workload com base em um conjunto de propriedades.
- Execuções históricas retêm metadados sobre execuções anteriores
- O serviço de pinning rastreia as cargas de trabalho que se comportam de maneira diferente em duas versões diferentes do servidor.
- Modelos de ML determinam a classificação de erros, fazem a triagem de tickets e detectam anomalias na frota.
- Os pipelines de detecção de anomalias rodam em toda a frota.
- Relatórios e alertas de integridade da versão fornecem informações em tempo real sobre a integridade da versão para a equipe de engenharia do Databricks

Os rollbacks automáticos garantem que as cargas de trabalho continuem sendo executadas com sucesso após encontrar regressões.
Quando o RSS realiza uma reversão em um job automatizado, o workload é executado novamente de forma automática na última versão conhecida em que foi bem-sucedido. Vamos ilustrar o RSS com um exemplo do mundo real: um determinado job automatizado foi executado em 9 de abril usando a versão 16.1.2 do DBR e apresentou um erro. As execuções históricas indicaram que o workload foi bem-sucedido por vários dias consecutivos na versão 16.1.1. O modelo de ML descobriu que o erro provavelmente foi causado por um bug. Como resultado, uma entrada de fixação foi criada automaticamente no serviço de fixação. Quando a nova tentativa automática do workload começou, ela encontrou a entrada do serviço de fixação e o workload foi executado novamente na versão 16.1.1 e foi bem-sucedido. Isso resultou em um processo de triagem automático no qual a engenharia do Databricks foi alertada, identificou o bug e emitiu uma correção. Nesse ínterim, as execuções subsequentes da carga de trabalho permaneceram fixadas em 16.1.1 até que a correção do bug fosse implementada na versão 16.1.3 e o workload foi finalmente liberado para a versão 16.1.3 (caixa azul) e continuou a rodar com sucesso.
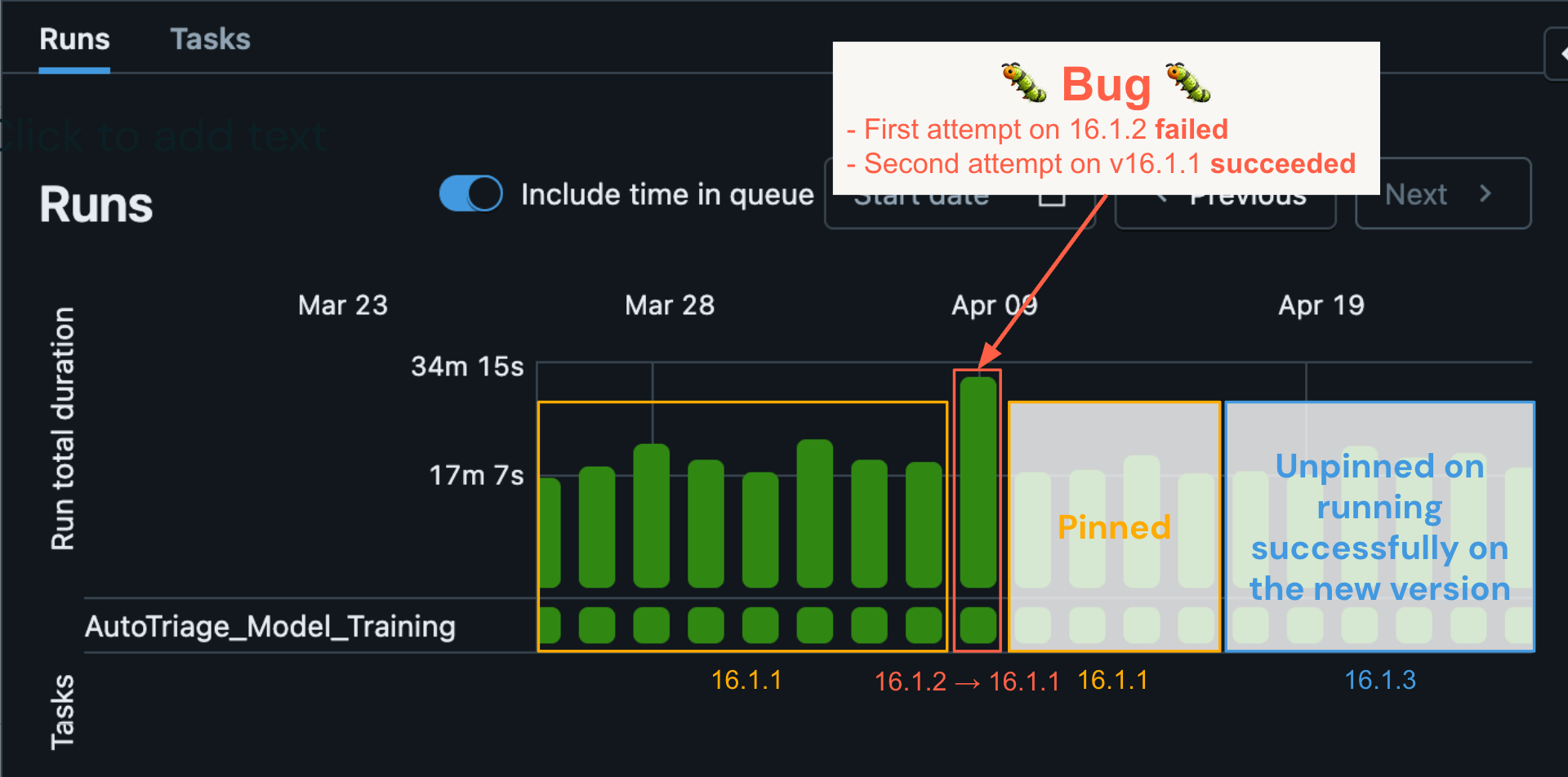
Nesse caso, conseguimos detectar e corrigir rapidamente um bug muito sutil que afetou apenas um pequeno número de workloads de clientes, sem nenhum impacto na confiabilidade do cliente. Compare isso com o modelo clássico de upgrade do Spark, que depende do upgrade manual do usuário e geralmente com um atraso significativo. O usuário realizaria o upgrade, veria seu job começar a falhar e, em seguida, talvez precisasse abrir um ticket de suporte para resolver o problema. Isso provavelmente levaria muito mais tempo para ser resolvido, exigindo, em última análise, mais envolvimento do cliente e com menor confiabilidade.
Conclusão
Usamos o Release Stability System para fazer o upgrade de mais de 2 bilhões de jobs, do DBR 14 ao DBR 17, incluindo a transição para o Spark 4, enquanto entregamos de forma transparente novos recursos como agrupamento, otimização de bloom filter join e drivers JDBC. Desses, apenas 0,000006% dos jobs exigiram uma reversão automática, e cada reversão foi corrigida com um reparo e atualizada com sucesso para a versão mais recente em uma média de 12 dias. Essa conquista marca um feito inédito no setor: fazer o upgrade de bilhões de workloads de produção do Spark automaticamente, sem nenhuma alteração de código por parte dos usuários.
Tornamos os upgrades do Spark completamente transparentes ao construir uma nova arquitetura que combina versionamento de ambiente, um servidor sem versão com upgrade automático e o Release Stability System. Essa abordagem inédita no setor permitiu que o Databricks entregasse recursos e correções aos usuários com muito mais rapidez e maior estabilidade, permitindo que as equipes de dados se concentrassem mais em resultados de negócios de alto valor em vez de na manutenção da infraestrutura.
Estamos apenas começando esta jornada e esperamos melhorar ainda mais a UX.
Passos seguintes
- Confira nosso artigo detalhado sobre este tópico na SIGMOD 2025
- Anúncio original do GA da computação Serverless para notebooks e jobs
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.