Introducing Spark Connect - The Power of Apache Spark, Everywhere
by Stefania Leone, Martin Grund, Herman van Hövell and Reynold Xin
At last week's Data and AI Summit, we highlighted a new project called Spark Connect in the opening keynote. This blog post walks through the project's motivation, high-level proposal, and next steps.
Spark Connect introduces a decoupled client-server architecture for Apache Spark that allows remote connectivity to Spark clusters using the DataFrame API and unresolved logical plans as the protocol. The separation between client and server allows Spark and its open ecosystem to be leveraged from everywhere. It can be embedded in modern data applications, in IDEs, Notebooks and programming languages.
Motivation
Over the past decade, developers, researchers, and the community at large have successfully built tens of thousands of data applications using Spark. During this time, use cases and requirements of modern data applications have evolved. Today, every application, from web services that run in application servers, interactive environments such as notebooks and IDEs, to edge devices such as smart home devices, wants to leverage the power of data.
Spark's driver architecture is monolithic, running client applications on top of a scheduler, optimizer and analyzer. This architecture makes it hard to address these new requirements: there is no built-in capability to remotely connect to a Spark cluster from languages other than SQL. The current architecture and APIs require applications to run close to the REPL, i.e., on the driver, and thus do not cater to interactive data exploration, as is commonly done with notebooks, or allow for building out the rich developer experience common in modern IDEs. Finally, programming languages without JVM interoperability cannot leverage Spark today.
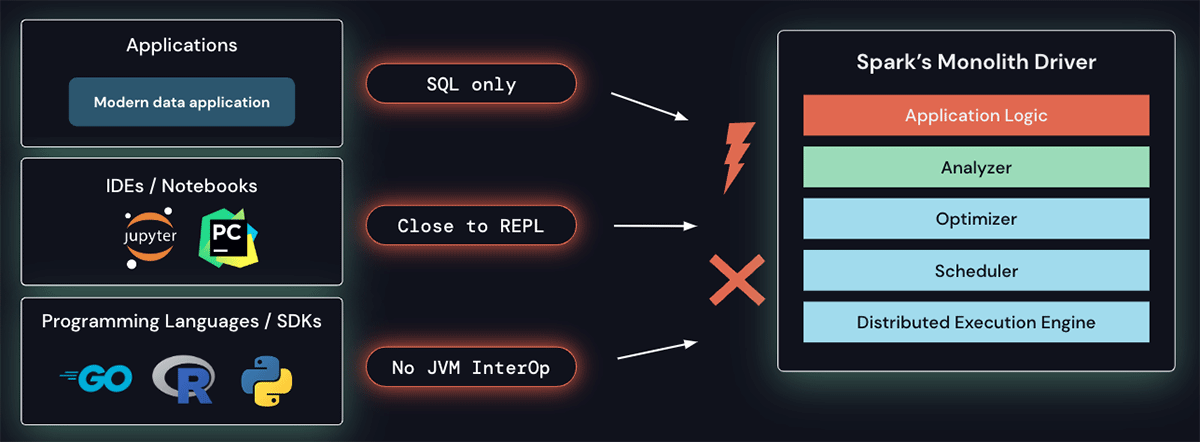
Additionally, Spark's monolithic driver architecture also leads to operational problems:
- Stability: Since all applications run directly on the driver, users can cause critical exceptions (e.g. out of memory) which may bring the cluster down for all users.
- Upgradability: the current entangling of the platform and client APIs (e.g., first and third-party dependencies in the classpath) does not allow for seamless upgrades between Spark versions, hindering new feature adoption.
- Debuggability and observability: The user may not have the correct security permission to attach to the main Spark process and debugging the JVM process itself lifts all security boundaries put in place by Spark. In addition, detailed logs and metrics are not easily accessible directly in the application.
How Spark Connect works
To overcome all of these challenges, we introduce Spark Connect, a decoupled client-server architecture for Spark.
The client API is designed to be thin, so that it can be embedded everywhere: in application servers, IDEs, notebooks, and programming languages. The Spark Connect API builds on Spark's well-known and loved DataFrame API using unresolved logical plans as a language-agnostic protocol between the client and the Spark driver.
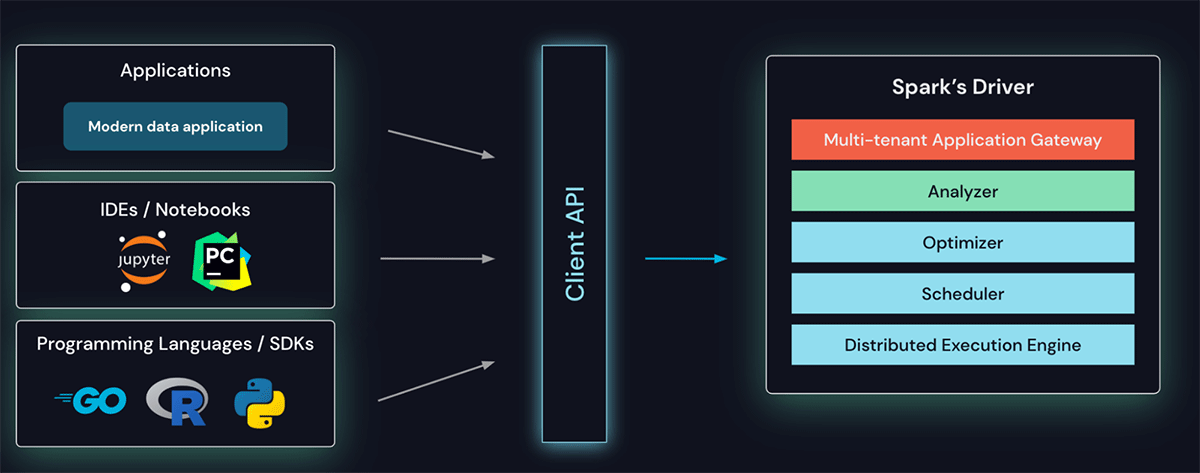
The Spark Connect client translates DataFrame operations into unresolved logical query plans which are encoded using protocol buffers. These are sent to the server using the gRPC framework. In the example below, a sequence of dataframe operations (project, sort, limit) on the logs table is translated into a logical plan and sent to the server.

The Spark Connect endpoint embedded on the Spark Server, receives and translates unresolved logical plans into Spark's logical plan operators. This is similar to parsing a SQL query, where attributes and relations are parsed and an initial parse plan is built. From there, the standard Spark execution process kicks in, ensuring that Spark Connect leverages all of Spark's optimizations and enhancements. Results are streamed back to the client via gRPC as Apache Arrow-encoded row batches.
Overcoming multi-tenant operational issues
With this new architecture, Spark Connect mitigates today's operational issues:
- Stability: Applications that use too much memory will now only impact their own environment as they can run in their own processes. Users can define their own dependencies on the client and don't need to worry about potential conflicts with the Spark driver.
- Upgradability: Spark driver can now seamlessly be upgraded independently of applications, e.g. to benefit from performance improvements and security fixes. This means applications can be forward-compatible, as long as the server-side RPC definitions are designed to be backwards compatible.
- Debuggability and Observability: Spark Connect enables interactive debugging during development directly from your favorite IDE. Similarly, applications can be monitored using the application's framework native metrics and logging libraries.
Next Steps
The Spark Improvement Process proposal was voted on and accepted by the community. We plan to work with the community to make Spark Connect available as an experimental API in one of the upcoming Apache Spark releases.
Our initial focus will be on providing DataFrame API coverage for PySpark to make the transition to this new API seamless. However, Spark Connect is a great opportunity for Spark to become more ubiquitous in other programming language communities and we're looking forward to seeing contributions of bringing Spark Connect clients to other languages.
We look forward to working with the rest of the Apache Spark community to develop this project. If you want to follow the development of Spark Connect in Apache Spark make sure to follow the dev@spark.apache.org mailing list or submit your interest using this form.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.