Como Construir e Escalar Sistemas de IA Multimodal no Databricks
por Max Fisher e Colton Peltier
- Por que a multimodalidade é importante – Veja como a combinação de texto, imagens, áudio e muito mais proporciona insights mais profundos e melhor tomada de decisão para IA empresarial.
- Passo a passo no Databricks – Aprenda a construir um pipeline multimodal de ponta a ponta usando PySpark, ai_query(), Databricks AI Search e Databricks Model Serving.
- Exemplo do mundo real – Acompanhe um estudo de caso de um estimador de sinistros de seguro automotivo que classifica danos a partir de fotos e fornece previsões de custo instantâneas.
Por que a IA Multimodal é Importante para a IA Corporativa
O mundo real é multimodal, e sua IA também deveria ser. As empresas não podem mais depender de sistemas que processam apenas texto, imagens ou áudio isoladamente. Esta postagem do blog guiará você pelo processo de implementação e aproveitamento eficaz da IA multimodal na plataforma Databricks.
Construir esses sistemas requer mais do que apenas modelos poderosos, demanda uma plataforma unificada que possa lidar com diversos tipos de dados, escalar perfeitamente e incorporar governança desde o primeiro dia. É nisso que o Databricks se destaca, unindo dados, IA e orquestração para aplicações multimodais do mundo real.
Com o Databricks, as empresas podem passar da experimentação multimodal para a produção mais rapidamente, graças a recursos integrados como o Databricks Model Serving, o AI Search e o Unity Catalog.
Casos de uso de IA Multimodal
As aplicações da IA multimodal em diversos setores são vastas e transformadoras. A seguir, alguns casos de uso em que a combinação de diferentes modalidades de dados gera valor significativo:
- Atendimento e suporte ao cliente: um sistema de IA multimodal de atendimento ao cliente poderia não apenas entender a consulta textual de um cliente, mas também analisar seu tom de voz (áudio) e interpretar capturas de tela ou vídeos (imagens) de seu problema.
- Saúde e Diagnóstico: a IA multimodal pode integrar prontuários de pacientes (texto), imagens médicas (Raios-X, MRIs) e dados de sensores (frequência cardíaca, níveis de glicose) para fornecer diagnósticos mais precisos, prever a progressão de doenças e personalizar planos de tratamento.
- Varejo e E-commerce: a IA multimodal pode processar avaliações de clientes (texto), imagens de produtos e até mesmo vídeos de produtos em uso. Isso permite que as empresas entendam melhor as preferências dos clientes, otimizem as recomendações de produtos e detectem atividades fraudulentas.
Juntos, esses exemplos mostram como a IA multimodal pode transformar setores — mas o sucesso exige mais do que apenas modelos robustos. Você precisa de processamento de dados escalável, inferência, governança e armazenamento. O Databricks oferece a infraestrutura escalável e os recursos avançados necessários para transformar dados brutos em inteligência acionável, impulsionando a inovação e a vantagem competitiva. Este post do blog guiará você pelo processo de implementação e aproveitamento da IA multimodal de forma eficaz na plataforma Databricks.
Para destacar as capacidades de um sistema composto de IA multimodal, construiremos um pipeline de IA multimodal para uma seguradora de automóveis fictícia, a AutomatedAutoInsurance Corp. Ele usará a Inferência em Lote em sinistros históricos para classificar danos e criar embeddings para o AI Search. Estes serão então usados por um aplicativo de Inferência em Tempo Real para estimar cotações a partir de imagens enviadas por clientes, combinando-as com casos semelhantes classificados pelo pipeline de lote, permitindo-nos estimar a cobertura do seguro.
IA multimodal em ação: cotações instantâneas de seguro de carro
Imagine uma seguradora de automóveis que atua no ramo de seguros há anos. No banco de dados histórico de sinistros, eles têm fotos de carros danificados, bem como o custo total associado ao sinistro. Quando os clientes sofrem um acidente de carro, eles já estão tendo um dia estressante, e queremos ajudar a criar a experiência de sinistro mais tranquila possível. Queremos criar um sistema de IA composto para dar aos clientes uma estimativa em tempo real do custo do sinistro, apenas a partir de uma foto enviada pelo cliente no local do acidente. Para isso, precisaremos criar um bom entendimento dos sinistros históricos usando inferência em lote, bem como um pipeline multimodal em tempo real para permitir que nossos clientes obtenham as informações de que precisam rapidamente.
Inferência em lote multimodal
Usando o Batch Inference do Model Serving, podemos analisar nosso conjunto de dados histórico de sinistros e os dados de imagem associados a esses sinistros e criar classificações do tipo de dano nos carros. Isso nos ajudará a criar classificações consistentes de danos em carros juntamente com os dados reais dos sinistros, para que possamos criar embeddings adequados para serem usados posteriormente em nosso índice do AI Search.
O ai_query do Databricks permite a extração de saídas estruturadas, especificando o esquema JSON desejado. Isso é incrivelmente poderoso, pois impõe o esquema desejado, o que significa que você não precisa escrever um código de análise personalizado para as saídas do seu LLM! No nosso caso, queremos que nosso modelo identifique alguns tipos de danos predefinidos em fotografias de carros. Especificaremos os tipos de danos que queremos detectar no esquema JSON:
Uma maneira fácil e conhecida de definir classes em python de forma orientada a objetos é usando o Pydantic. Se você preferir definir seu esquema de saída com o Pydantic, confira o repositório de código deste blog, que inclui uma função auxiliar para converter sua classe Pydantic para o formato JSON para o ai_query.
Assim como em todos os modelos, nossos modelos multimodais terão algumas práticas recomendadas ou premissas de dados. Usaremos o Claude 3.7 Sonnet para este caso de uso em lote, e ele funciona melhor quando as imagens têm um tamanho máximo de 1568 pixels. Precisamos garantir que estamos redimensionando nossas imagens corretamente.
Agora, podemos combinar tudo isso para formatar a chamada ai_query().
O que resulta nesta ai_query()formatada
O processo completo de inferência em lote de ponta a ponta, desde a leitura das imagens, o redimensionamento delas e a aplicação da função de inferência em lote, está encapsulado aqui, onde lemos as imagens de um Volume UC.
Resultando em nossas classificações de danos:

Agora, precisamos encontrar uma maneira de recuperar sinistros de danos semelhantes de dados históricos quando um cliente envia uma nova foto. Uma possibilidade é realizar uma consulta simples ao banco de dados em busca de outros sinistros com os mesmos danos do novo sinistro do cliente. Um problema com essa ideia é descobrir como lidar com os casos em que encontramos novas combinações de danos para as quais não temos dados históricos. Como vamos recuperar os sinistros históricos certos para fazer uma boa estimativa para uma nova combinação de danos nunca antes vista?
A solução de recuperação que usaremos neste blog é aproveitar os embeddings. A maioria dos sistemas baseados em recuperação de embeddings utiliza uma métrica de similaridade de cosseno para encontrar os dados mais próximos para consulta. Isso funciona bem para muitos casos de uso, mas no nosso caso de uso podemos ter danos em várias peças com o mesmo nome. Por exemplo, imagine um sinistro com dois painéis de porta danificados. Se pegássemos os embeddings para "Painel de Porta" duas vezes e simplesmente calculássemos a média, teríamos os mesmos embeddings de um único "Painel de Porta" e nosso sistema de recuperação provavelmente usaria sinistros de um único "Painel de Porta" para estimar o novo sinistro do cliente de dois painéis de porta, o que seria muito impreciso! Em vez disso, podemos somar nossos embeddings para cada componente danificado e aproveitar uma métrica de distância euclidiana para recuperar sinistros semelhantes. Isso garantiria que sinistros com múltiplos componentes danificados do mesmo tipo ainda fossem bem representados, mas também logicamente próximos de apenas uma instância daquele componente danificado.
A busca vetorial do Databricks implementa a distância euclidiana (ou “L2”) por padrão, então só precisamos modificar nossa lógica de cálculo de embedding para obter os resultados desejados.
Em seguida, podemos criar nosso índice do AI Search:
Agora podemos fazer um teste simples, com uma combinação de danos de sinistro não vista em nenhum dos nossos dados históricos:
O que exibe as 5 solicitações de danos históricos mais próximas:
O que encontra alguns sinistros históricos interessantemente próximos, embora nenhuma correspondência exata tenha sido encontrada! Cada um dos sinistros retornados tem pelo menos uma das peças do novo sinistro, e cada um é um sinistro de dano com múltiplos componentes.
Inferência multimodal em tempo real
Agora, com nosso índice do AI Search criado, podemos combinar isso com nossas funções auxiliares para processar as imagens, calcular embeddings e estabelecer um esquema de saída por meio de um Pydantic Model em uma definição pyfunc para um agente que pode:
- Use uma imagem de dano no carro como entrada
- Processar a imagem
- Calcule o embedding da imagem processada
- Use isso para fazer uma busca por similaridade com nosso Índice do AI Search
- Use os sinistros semelhantes para obter um custo médio do sinistro
- Retornar a estimativa e a avaliação para o usuário
Aqui está a nossa parte predict() da definição pyfunc para o agente (como algumas das funções são referenciadas acima, removemos parte do código para sermos breves, mas você pode ver o exemplo completo aqui no GitHub):
Basicamente, executamos o mesmo processo do nosso exemplo em lote, mas damos o passo final de usar a análise de danos obtida da geração de texto a partir de imagem e fazer uma busca por similaridade em acidentes passados para obter dados de custo e calcular uma estimativa.
Ao testar nosso agente pyfunc, podemos executar cada uma das etapas mencionadas acima. Com o MLflow 3.0, podemos ver todo o processo de ponta a ponta no rastreamento visual.
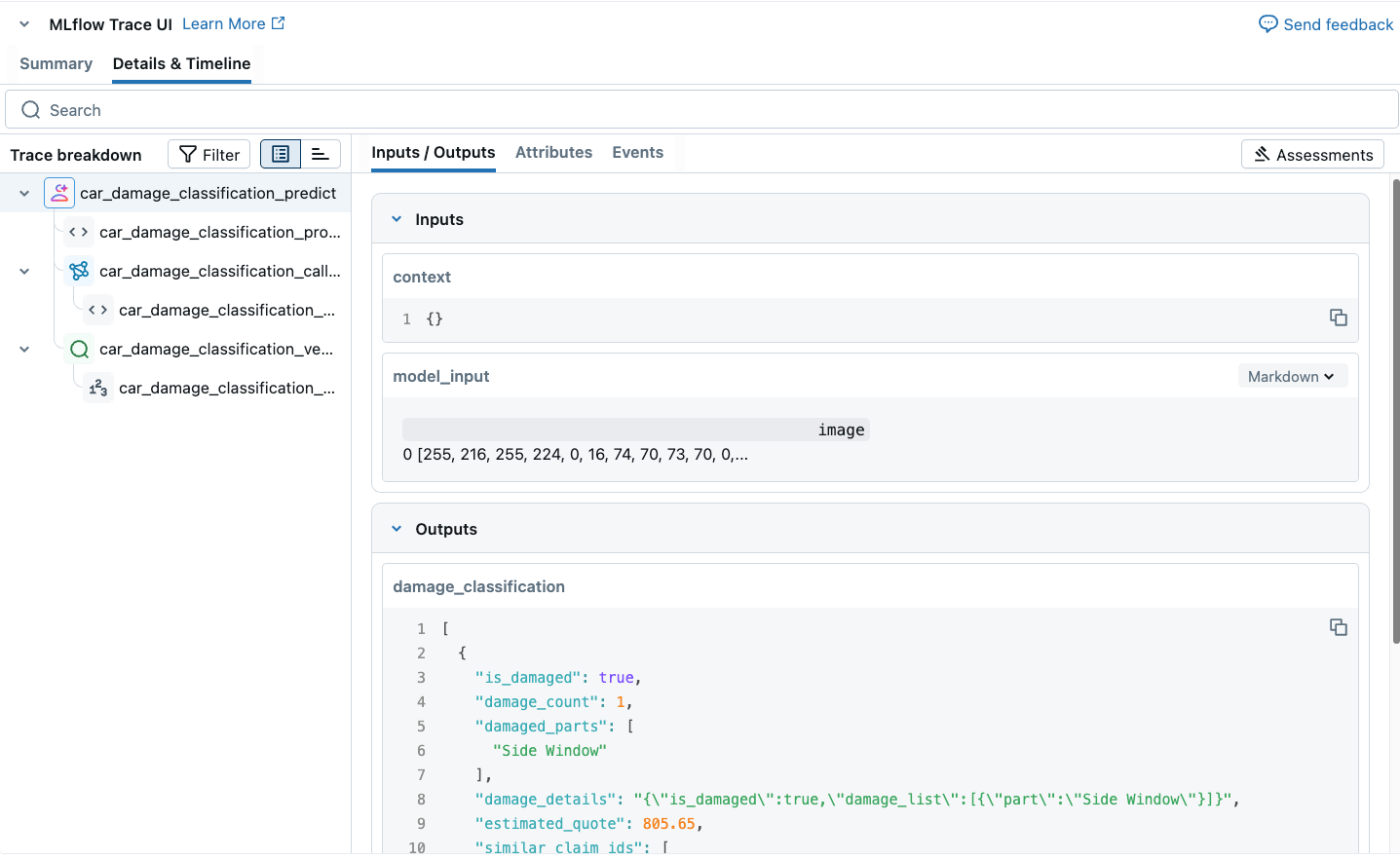
Após o log, o registro e a implantação do modelo no Databricks Model Serving, ele fica disponível para nosso Aplicativo Estimador de Cotações, e os usuários podem enviar fotos dos danos de seus carros e obter uma estimativa do custo dos danos ao veículo.

Começar
Construir sistemas de IA compostos e multimodais poderosos não precisa ser algo complexo. O Databricks tem recursos poderosos como PySpark, ai_query(), Databricks AI Search e Databricks Model Serving que funcionam em conjunto para simplificar seu fluxo de trabalho de sistema de IA de ponta a ponta.
Para trabalhos de GenAI com inferência em lote, use o Pyspark com ai_query() para escalar automaticamente sua inferência multimodal. O Databricks Databricks AI Search permite a indexação e consulta poderosas de embeddings para construir rapidamente um sistema de recuperação de nível de produção. O Databricks Databricks Model Serving permite implantar endpoints de nível de produção que podem reunir toda a lógica de sua aplicação. Modelos de fundação multimodais integrados, como Claude e Llama4, permitem que você comece a prototipar e lançar sistemas multimodais imediatamente.
Como sempre, certifique-se de seguir as melhores práticas para qualquer modelo que você escolher usar. Se você estiver realizando análise de imagem, como fizemos no exemplo deste blog, consulte a tabela abaixo para encontrar as dimensões máximas ideais de imagem a serem usadas para uma variedade de modelos multimodais populares.
| Família de modelos | Dimensões máximas ideais da imagem (pixels) |
|---|---|
| Llama 4 | 336 |
| Claude | 1568 |
| Gemma | 896 |
Aproveitando as capacidades avançadas de GenAI da Databricks, você pode começar a construir IA multimodal hoje mesmo.
Comece com os recursos abaixo:
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.