Como criar Genie Spaces prontos para produção e construir confiança ao longo do caminho
Uma jornada de construção de um espaço Genie do zero até estar pronto para produção, melhorando a precisão por meio da avaliação de benchmark e otimização sistemática.
por Pulkit Pareek e Eric Lind
- Aproveite os benchmarks para medir a prontidão do seu espaço Genie de forma objetiva, em vez de subjetiva.
- Siga um exemplo de ponta a ponta do desenvolvimento de um espaço Genie pronto para produção, cobrindo muitos cenários comuns de solução de problemas.
- Crie confiança com os usuários finais compartilhando os resultados finais de precisão sobre as perguntas que eles precisam que sejam respondidas corretamente.
O Desafio da Confiança em analítica de Autoatendimento
O Genie é um recurso do Databricks que permite que as equipes de negócios interajam com seus dados usando linguagem natural. Ele usa IA generativa adaptada à terminologia e aos dados da sua organização, com a capacidade de monitorar e refinar seu desempenho por meio do feedback do usuário.
Um desafio comum em qualquer ferramenta de analítica de linguagem natural é construir a confiança dos usuários finais. Considere a Sarah, uma especialista em marketing que está experimentando o Genie pela primeira vez em vez de seus dashboards.
Sarah: "Qual foi a nossa taxa de cliques no último trimestre?"
Genie: 8,5%
Pensamento de Sarah: Espere, eu me lembro de comemorar quando atingimos 6% no último trimestre...
Esta é uma pergunta para a qual Sarah sabe a resposta, mas não está vendo o resultado correto. Talvez a query gerada tenha incluído campanhas diferentes ou usado uma definição de calendário padrão para “último trimestre”, quando deveria estar usando o calendário fiscal da empresa. Mas Sarah não sabe o que está errado. O momento de incerteza introduziu a dúvida. Sem a avaliação adequada das respostas, essa dúvida sobre a usabilidade pode aumentar. Os usuários voltam a solicitar suporte de analistas, o que interrompe outros projetos e aumenta o custo e o tempo de retorno para gerar um único insight. O investimento em auto-serviço fica subutilizado.
A questão não é apenas se o seu espaço Genie pode gerar SQL. É se seus usuários confiam nos resultados o suficiente para tomar decisões com base neles.
Construir essa confiança exige ir além da avaliação subjetiva ("parece que funciona") para uma validação mensurável ("testamos sistematicamente"). Demonstraremos como o recurso de benchmarks integrado do Genie transforma uma implementação de referência em um sistema pronto para produção no qual os usuários confiam para tomar decisões críticas. Os benchmarks fornecem uma maneira data-driven para avaliar a qualidade do seu Genie space e ajudam a abordar lacunas ao fazer a curadoria do Genie space.
Neste blog, vamos guiar você por uma jornada de exemplo de ponta a ponta na criação de um Genie space com benchmarks para desenvolver um sistema confiável.
Os dados: Análise de campanha de marketing
Nossa equipe de marketing precisa analisar o desempenho da campanha em quatro datasets interconectados.
- Clientes em potencial - Informações da empresa, incluindo setor e localização
- Contatos - Informações do destinatário, incluindo departamento e tipo de dispositivo
- Campanhas - Detalhes da campanha, incluindo orçamento, padrão e datas
- Eventos - Acompanhamento de eventos de e-mail (envios, aberturas, cliques, denúncias de spam)
O fluxo de trabalho: Identificar empresas-alvo (prospects) → encontrar contatos nessas empresas → enviar campanhas de marketing → rastrear como os destinatários respondem a essas campanhas (eventos).
Algumas perguntas de exemplo que os usuários precisaram responder são:
- "Quais campanhas apresentaram o melhor ROI por indústria?"
- "Qual é o nosso risco de compliance nos diferentes tipos de campanha?"
- "Como os padrões de engajamento (CTR) diferem por dispositivo e departamento?"
- "Quais padrões têm o melhor desempenho para segmentos específicos de clientes em potencial?"
Essas perguntas exigem a junção de tabelas, o cálculo de métricas específicas do domínio e a aplicação de conhecimento de domínio sobre o que torna uma campanha "bem-sucedida" ou "de alto risco". Acertar essas respostas é importante porque elas influenciam diretamente a alocação de orçamento, a estratégia de campanha e as decisões de compliance. Vamos começar!
A jornada: do desenvolvimento da linha de base à produção
Não se deve esperar que a adição anedótica de tabelas e de alguns prompts de texto resulte em um espaço Genie suficientemente preciso para os usuários finais. Um entendimento aprofundado das necessidades dos seus usuários finais, combinado com o conhecimento dos conjuntos de dados e das capacidades da plataforma Databricks, levará aos resultados desejados.
Neste exemplo de ponta a ponta, avaliamos a precisão do nosso espaço Genie por meio de benchmarks, diagnosticamos lacunas de contexto que causam respostas incorretas e implementamos correções. Considere esta estrutura para abordar o desenvolvimento e as avaliações do seu Genie.
- Defina seu conjunto de benchmark (procure ter de 10 a 20 perguntas representativas). Essas perguntas devem ser determinadas por especialistas no assunto e pelos usuários finais reais que devem usar o Genie para analítica. Idealmente, essas perguntas são criadas antes de qualquer desenvolvimento real do seu espaço do Genie.
- Estabeleça sua acurácia de baseline. Execute todas as perguntas de benchmark no seu espaço com apenas os objetos de dados base adicionados ao espaço Genie. Documente a acurácia e quais perguntas são aprovadas, quais são reprovadas e por quê.
- Otimize sistematicamente. Implemente um conjunto de alterações (ex. adicionando descrições de colunas). Execute a execução de todas as perguntas de benchmark. Meça o impacto, as melhorias e continue o desenvolvimento iterativo seguindo as Melhores Práticas publicadas.
- Meça e comunique. A execução dos benchmarks fornece critérios de avaliação objetivos de que o Genie space atende satisfatoriamente às expectativas, construindo a confiança de usuários e stakeholders.
Criamos um conjunto de 13 perguntas de benchmark que representam as respostas que os usuários finais procuram em nossos dados de marketing. Cada pergunta de benchmark é uma pergunta realista em inglês simples, combinada com uma query SQL validada que responde a essa pergunta.
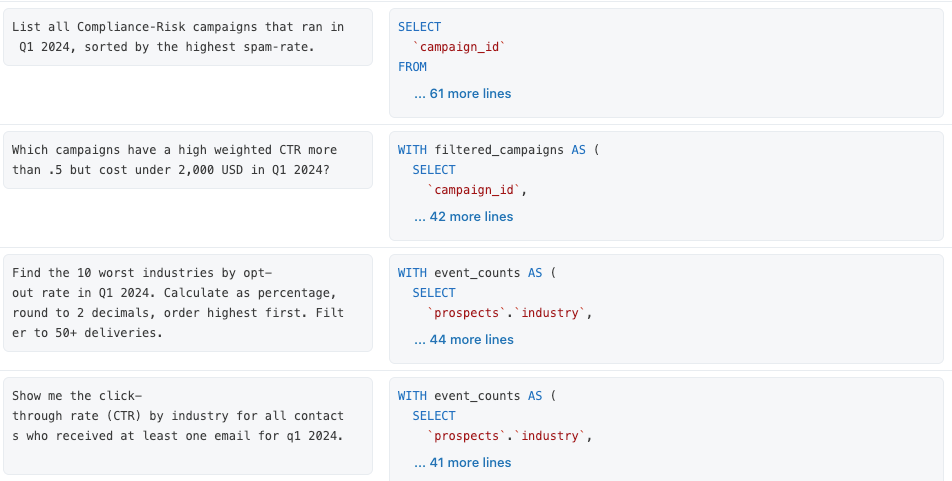
O Genie não inclui essas consultas SQL de benchmark como contexto existente, propositalmente. Elas são usadas puramente para avaliação. É nosso trabalho fornecer o contexto certo para que essas perguntas possam ser respondidas corretamente. Vamos lá!
Iteração 0: estabelecer a linha de base
Começamos intencionalmente com nomes de tabelas inadequados, como cmp e proc_delta, e nomes de colunas como uid_seq (para campaign_id), label_txt (para campaign_name), num_val (para cost) e proc_ts (para event_date). Este ponto de partida reflete o que muitas organizações realmente enfrentam: dados modelados para convenções técnicas em vez de significado de negócio.
As tabelas por si só também não fornecem contexto sobre como calcular KPIs e métricas específicas do domínio. O Genie sabe como aproveitar centenas de funções SQL integradas, mas ainda precisa das colunas e da lógica certas para usar como entradas. Então, o que acontece quando o Genie não tem contexto suficiente?
Análise de benchmark: o Genie não conseguiu responder corretamente a nenhuma das nossas 13 perguntas de benchmark. Não porque a IA não fosse poderosa o suficiente, mas porque não tinha nenhum contexto relevante, como mostrado abaixo.

Insight: toda pergunta que os usuários finais fazem depende de o Genie produzir uma consulta query SQL a partir dos objetos de dados que você fornece. Portanto, convenções de nomenclatura de dados ruins afetarão cada uma das consultas geradas. Não é possível pular a qualidade dos dados fundamentais e esperar criar confiança com os usuários finais! O Genie não gera uma query SQL para todas as perguntas. Ele só faz isso quando tem contexto suficiente. Esse é um comportamento esperado para evitar alucinações e respostas enganosas.
Próxima ação: as baixas pontuações iniciais de benchmark indicam que você deve primeiro se concentrar na limpeza dos objetos do Unity Catalog, então começamos por aí.
Iteração 1: Significados de Coluna Ambíguos
Melhoramos os nomes das tabelas para campaigns, events, contacts e prospects e adicionamos descrições claras das tabelas no Unity Catalog.

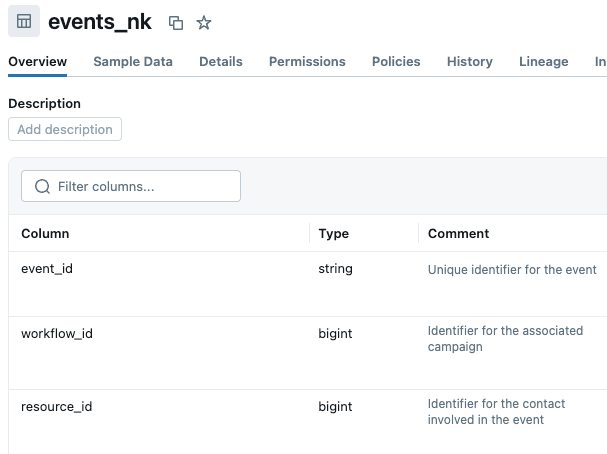
No entanto, encontramos outro desafio relacionado: nomes de colunas ou comentários enganosos que sugerem relacionamentos que não existem.
Por exemplo, colunas como workflow_id, resource_id e owner_id existem em várias tabelas. Parece que eles deveriam conectar tabelas, mas não o fazem. A tabela events usa workflow_id como chave estrangeira para campanhas (não uma tabela de fluxo de trabalho separada) e resource_id como chave estrangeira para contatos (não uma tabela de recurso separada). Enquanto isso, a tabela campaigns tem sua própria coluna workflow_id, que não tem nenhuma relação. Se os nomes e as descrições dessas colunas não forem anotados adequadamente, isso pode levar ao uso incorreto desses atributos. Atualizamos as descrições das colunas no Unity Catalog para esclarecer a finalidade de cada uma dessas colunas ambíguas. Observação: se você não conseguir editar metadados no UC, poderá adicionar descrições de tabela e coluna na base de conhecimento do espaço Genie.
Análise de benchmark: queries simples de tabela única começaram a funcionar graças a nomes e descrições claros. Perguntas como "Contar eventos por tipo em 2023" e "Quais campanhas começaram nos últimos três meses?" agora recebiam respostas corretas. No entanto, qualquer query que exigia junções entre tabelas falhou — o Genie ainda não conseguia determinar corretamente quais colunas representavam relacionamentos.
Insight: Convenções de nomenclatura claras ajudam, mas sem definições de relacionamento explícitas, o Genie precisa adivinhar quais colunas conectam as tabelas. Quando várias colunas têm nomes como workflow_id ou resource_id, essas suposições podem levar a resultados imprecisos. Metadados adequados servem como base, mas os relacionamentos devem ser definidos explicitamente.
Próxima Ação: Defina as relações de join entre seus objetos de dados. Nomes de colunas como id ou resource_id aparecem o tempo todo. Vamos esclarecer exatamente quais dessas colunas referenciam outros objetos de tabela.
Iteração 2: Modelo de dados ambíguo
A melhor maneira de esclarecer quais colunas o Genie deve usar ao unir tabelas é por meio do uso de chaves primárias e estrangeiras. Adicionamos restrições de chave primária e estrangeira no Unity Catalog, informando explicitamente ao Genie como as tabelas se conectam: campaigns.campaign_id se relaciona com events.campaign_id, que se conecta a contacts.contact_id, que se conecta a prospects.prospect_id. Isso elimina a adivinhação e dita como as joins de várias tabelas são criadas por default. Observação: se você não conseguir editar relacionamentos no UC, ou se o relacionamento da tabela for complexo (por exemplo, várias condições JOIN), você pode defini-las na base de conhecimento do Genie space.
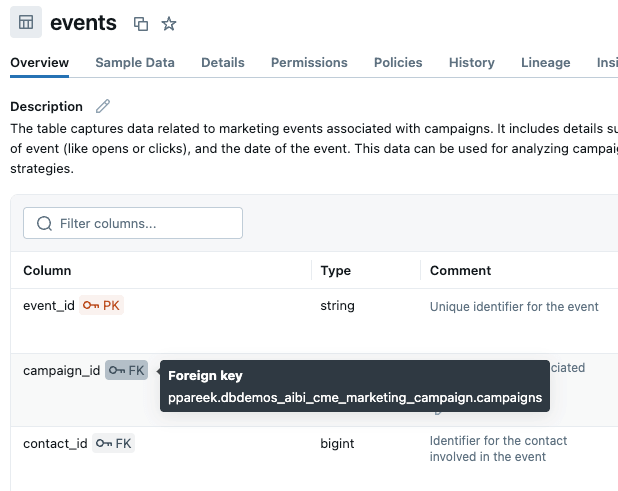
Alternativamente, poderíamos considerar a criação de uma view de métricas que pode incluir detalhes de join explicitamente na definição do objeto. Mais sobre isso mais tarde.
Análise de benchmark: progresso constante. Perguntas que exigiam joins em várias tabelas começaram a funcionar: "Mostrar custos de campanha por setor para o primeiro trimestre de 2024" e "Quais campanhas tiveram mais de 1.000 eventos em janeiro?" agora foram bem-sucedidas.
Percepção: Os relacionamentos permitem as complexas multi-tabela queries que entregam valor de negócio real. O Genie está gerando SQL estruturado corretamente e fazendo coisas simples como somas de custos e contagens de eventos corretamente.
Ação: Dos benchmarks incorretos restantes, muitos deles incluem referências a valores que os usuários pretendem usar como filtros de dados. A forma como os usuários finais fazem perguntas não corresponde diretamente aos valores que aparecem no dataset.
Iteração 3: Entendendo os valores dos dados
Um espaço do Genie deve ter uma curadoria para responder a perguntas específicas do domínio. No entanto, as pessoas nem sempre usam exatamente a mesma terminologia de como nossos dados aparecem. Os usuários podem dizer "empresas de bioengenharia", mas o valor dos dados é "biotecnologia."
A ativação de dicionários de valores e amostragem de dados produz uma consulta mais rápida e precisa dos valores existentes nos dados, em vez de o Genie usar apenas o valor exato solicitado pelo usuário final.

Valores de exemplo e dicionários de valores agora estão ativados por padrão, mas vale a pena verificar novamente se as colunas certas comumente usadas para filtragem estão ativadas e têm dicionários de valores personalizados quando necessário.
Análise de benchmark: mais de 50% das perguntas de benchmark agora estão recebendo respostas bem-sucedidas. Perguntas envolvendo valores de categoria específicos, como “biotecnologia”, começaram a identificar corretamente esses filtros. O desafio agora é implementar métricas e agregações personalizadas. Por exemplo, o Genie está fornecendo uma suposição sobre como calcular a CTR com base na descoberta de “clique” como um valor de dados e em sua compreensão de métricas baseadas em taxas. Mas não tem confiança suficiente para simplesmente gerar as queries:
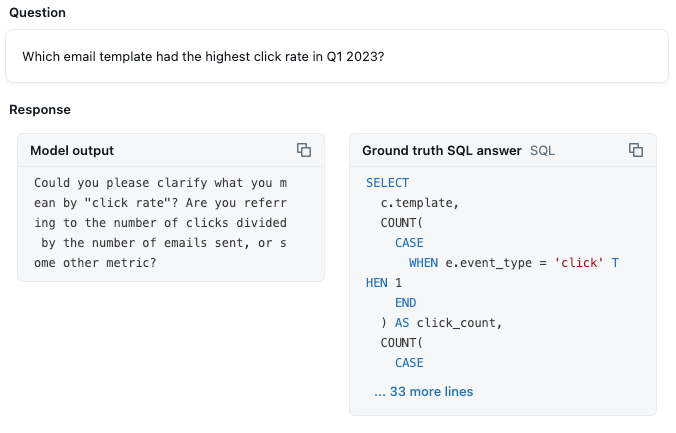
Esta é uma métrica que queremos que seja calculada corretamente 100% das vezes, então precisamos esclarecer esse detalhe para o Genie.
Observação: a amostragem de valores melhora a geração de SQL do Genie ao fornecer acesso a valores de dados reais. Quando os usuários fazem perguntas coloquiais com erros de ortografia ou terminologia diferente, a amostragem de valores ajuda o Genie a corresponder os prompts aos valores de dados reais em suas tabelas.
Próxima ação: o problema mais comum agora é que o Genie ainda não está gerando o SQL correto para nossas métricas personalizadas. Vamos abordar explicitamente nossas definições de métricas para obter resultados mais precisos.
Iteração 4: definindo métricas personalizadas
Neste ponto, o Genie tem contexto para atributos de dados categóricos que existem nos dados, consegue filtrar nossos valores de dados e realizar agregações diretas de funções SQL padrão (ex.: “contar eventos por tipo” usa COUNT()). Para deixar mais claro como o Genie deve calcular nossas métricas, adicionamos exemplos de queries SQL ao nosso genie space. Este exemplo demonstra a definição de métrica correta para CTR:
Observe que é recomendável deixar comentários em suas queries SQL, pois esse é um contexto relevante junto com o código.
Análise de benchmark: Isso resultou na maior melhoria de precisão até agora. Considere que nosso objetivo é tornar o Genie capaz de responder a perguntas em um nível muito detalhado para um público definido. Espera-se que a maioria das perguntas dos usuários finais dependa de métricas personalizadas, como CTR, taxas de spam, métricas de engajamento etc. Mais importante, variações dessas perguntas também funcionaram. O Genie aprendeu a definição da nossa métrica e a aplicará a qualquer query daqui para frente.
Observação: as consultas de exemplo ensinam a lógica de negócios que os metadados por si só não conseguem transmitir. Uma query de exemplo bem elaborada geralmente resolve uma categoria inteira de lacunas de benchmark simultaneamente. Isso agregou mais valor do que qualquer outro passo de iteração até agora.
Próxima ação: Apenas algumas perguntas de benchmark permanecem incorretas. Após uma inspeção mais aprofundada, notamos que os benchmarks restantes estão falhando por dois motivos:
- Os usuários estão fazendo perguntas sobre atributos de dados que não existem diretamente nos dados. Por exemplo, “quantas campanhas geraram uma CTR alta no último trimestre?” O Genie não sabe o que um usuário quer dizer com CTR “alta”, porque não existe nenhum atributo de dados.
- Essas tabelas de dados incluem registros que deveríamos excluir. Por exemplo, temos muitas campanhas de teste que não são direcionadas aos clientes. Precisamos excluí-las dos nossos KPIs.
Iteração 5: documentando regras específicas do domínio
Essas lacunas restantes são partes do contexto que se aplicam globalmente a como todas as nossas queries devem ser criadas e se relacionam a valores que não existem diretamente em nossos dados.
Vamos pegar aquele primeiro exemplo sobre alta CTR, ou algo semelhante como campanhas de alto custo. Nem sempre é fácil ou mesmo recomendado adicionar dados específicos do domínio às nossas tabelas, por vários motivos:
- Fazer alterações, como adicionar um campo
campaign_cost_segmentation(alto, médio, baixo), às tabelas de dados levará tempo e afetará outros processos, pois os esquemas de tabela e os pipelines de dados precisarão ser alterados. - Para cálculos agregados como a CTR, à medida que novos dados chegam, os valores da CTR mudarão. De qualquer forma, não devemos pré-compute este cálculo, pois queremos que ele seja computado em tempo real à medida que esclarecemos filtros como períodos de tempo e campanhas.
Portanto, podemos usar uma instrução baseada em texto no Genie para realizar essa segmentação específica do domínio para nós.

Da mesma forma, podemos especificar como o Genie deve sempre escrever queries para se alinhar às expectativas de negócios. Isso pode incluir itens como calendários personalizados, filtros globais obrigatórios, etc. Por exemplo, estes dados de campanha incluem campanhas de teste que devem ser excluídas dos nossos cálculos de KPI.


Análise de benchmark: 100% de precisão no benchmark! Casos extremos e perguntas baseadas em limites começaram a funcionar de forma consistente. Perguntas sobre "campanhas de alto desempenho" ou "campanhas de risco de compliance" agora aplicavam nossas definições de negócios corretamente.
Observação: instruções baseadas em texto são uma maneira simples e eficaz de preencher quaisquer lacunas restantes das etapas anteriores, para garantir que as consultas certas sejam geradas para os usuários finais. No entanto, não deve ser o primeiro nem o único lugar em que você confia para a injeção de contexto.
Observe que, em alguns casos, pode não ser possível atingir 100% de precisão. Por exemplo, às vezes as perguntas de benchmark exigem consultas muito complexas ou vários prompts para gerar a resposta correta. Se você não conseguir criar facilmente um único exemplo de query SQL, simplesmente anote essa lacuna ao compartilhar os resultados da sua avaliação de benchmark com outras pessoas. A expectativa típica é que os benchmarks do Genie estejam acima de 80% antes de passar para o teste de aceitação do usuário (UAT).
Próxima ação: Agora que o Genie atingiu nosso nível de precisão esperado em nossas perguntas de benchmark, passaremos para o UAT e coletaremos mais feedback dos usuários finais!
(Opcional) Iteração 6: pré-cálculo de métricas complexas
Para nossa iteração final, criamos uma custom view que pré-define as key métricas de marketing e aplicamos classificações de negócios. Criar uma view ou uma view de métrica pode ser mais simples nos casos em que todos os seus datasets se encaixam em um único modelo de dados, e você tem dezenas de métricas personalizadas. É mais fácil encaixar tudo isso na definição de um objeto de dados em vez de escrever uma SQL query de exemplo para cada um deles específica para o Genie space.
Resultado do benchmark: ainda alcançamos 100% de precisão de benchmarking, aproveitando as views em vez de apenas as tabelas base, porque o conteúdo dos metadados permaneceu o mesmo.
Observação: em vez de explicar cálculos complexos por meio de exemplos ou instruções, você pode encapsulá-los em uma view ou visualização de métrica, definindo uma única fonte de verdade.
O que aprendemos: o impacto do desenvolvimento orientado por benchmark
Não existe uma "bala de prata" na configuração de um Genie space que resolva tudo. A precisão pronta para produção normalmente só ocorre quando você tem dados de alta qualidade, metadados devidamente enriquecidos, lógica de métricas definida e contexto específico do domínio injetado no espaço. Em nosso exemplo de ponta a ponta, encontramos problemas comuns que abrangiam todas essas áreas.
Os benchmarks são essenciais para avaliar se o seu espaço está atendendo às expectativas e pronto para o feedback do usuário. Isso também orientou nossos esforços de desenvolvimento para preencher as lacunas na interpretação das perguntas do Genie. Em resumo:
- Iterações 1-3: 54% de precisão do benchmark. Essas iterações focaram em fazer o Genie reconhecer nossos dados e metadados com mais clareza. Implementar nomes de tabela, descrições de tabela, descrições de coluna e chaves de junção apropriados e habilitar valores de exemplo são todos os passos fundamentais para qualquer Genie space. Com esses recursos, o Genie deve identificar corretamente a tabela, as colunas e as condições de junção certas que afetam qualquer consulta que ele gera. Ele também pode fazer agregações e filtragens simples. O Genie conseguiu responder a mais da metade das nossas perguntas de benchmark específicas do domínio corretamente com apenas esse conhecimento fundamental.
- Iteração 4 - 77% de precisão no benchmark. Esta iteração se concentrou em esclarecer nossas definições de métricas personalizadas. Por exemplo, o CTR não faz parte de todas as perguntas de benchmark, mas é um exemplo de uma métrica não padrão (ou seja, diferente de `sum()`, `avg()`, etc.) métricas que precisa ser respondida corretamente sempre.
- Iteração 5 - 100% de precisão no benchmark. Esta iteração demonstrou o uso de instruções baseadas em texto para preencher as lacunas restantes de imprecisões. Essas instruções abrangeram cenários comuns, como a inclusão de filtros globais nos dados para uso analítico, definições específicas do domínio (ex.: o que torna uma campanha de altoengajamento), e informações especificadas de calendários fiscais.
Ao seguir uma abordagem sistemática para avaliar nosso Genie space, detectamos um comportamento de consulta não intencional proativamente, em vez de ouvir sobre isso da Sarah reativamente. Transformamos a avaliação subjetiva ("parece que funciona") em medição objetiva ("validamos que funciona para 13 cenários representativos que cobrem nossos principais casos de uso, conforme inicialmente definidos pelos usuários finais").
O Caminho a Seguir
Construir confiança em analítica de autoatendimento não se trata de alcançar a perfeição no primeiro dia. Trata-se de melhoria sistemática com validação mensurável. Trata-se de detectar problemas antes que os usuários o façam.
O recurso Benchmarks fornece a camada de medição que torna isso possível. Ele transforma a abordagem iterativa que a documentação da Databricks recomenda em um processo quantificável e que gera confiança. Vamos recapitular este processo de desenvolvimento sistemático e orientado por benchmarks:
- Crie perguntas de benchmark (procure ter de 10 a 15) que representem as perguntas realistas dos seus usuários
- Teste seu espaço para estabelecer a precisão da linha de base
- Faça melhorias na configuração seguindo a abordagem iterativa que a Databricks recomenda em nossas práticas recomendadas.
- Teste novamente todos os benchmarks após cada alteração para medir o impacto e identificar lacunas de contexto de perguntas incorretas. Documente sua progressão de precisão para criar a confiança das partes interessadas.
Comece com bases sólidas no Unity Catalog. Adicione contexto de negócios. Teste de forma abrangente por meio de benchmarks. Meça cada alteração. Crie confiança por meio da precisão validada.
Você e seus usuários finais serão beneficiados!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.