Como a Equinor otimizou a Pipeline de Dados Sísmicos com o Databricks
por Sourav Gulati e Anton Eskov
- Entendendo as complexidades nos Dados Sísmicos.
- Identificando desafios na pipeline de processamento de dados sísmicos existente.
- Demonstrando como a plataforma Databricks possibilitou um processamento de dados sísmicos mais rápido, escalável e eficiente.
A indústria de petróleo e gás depende fortemente de dados sísmicos para explorar e extrair hidrocarbonetos de maneira segura e eficiente. No entanto, processar e analisar grandes quantidades de dados sísmicos pode ser uma tarefa assustadora, exigindo recursos computacionais significativos e expertise.
A Equinor, uma empresa líder em energia, utilizou a Plataforma de Inteligência de Dados Databricks para otimizar um de seus fluxos de trabalho de transformação de dados sísmicos exploratórios, alcançando economia significativa de tempo e custos, além de melhorar a observabilidade dos dados.
O objetivo da Equinor era aprimorar um de seus fluxos de trabalho de interpretação sísmica 4D, focando na automação e otimização da detecção e classificação de mudanças no reservatório ao longo do tempo. Este processo auxilia na identificação de alvos de perfuração, reduzindo o risco de poços secos custosos e promovendo práticas de perfuração ambientalmente responsáveis. As principais expectativas de negócios incluíam:
- Alvos de perfuração otimizados: Melhore a identificação de alvos para perfurar um grande número de novos poços nas próximas décadas.
- Análise mais rápida e econômica: Reduza o tempo e o custo da análise sísmica 4D por meio da automação.
- Insights mais profundos do reservatório: Integre mais dados do subsolo para desbloquear interpretações aprimoradas e tomada de decisões.
Entendendo os Dados Sísmicos
Cubo Sísmico: Modelos 3D do subsolo
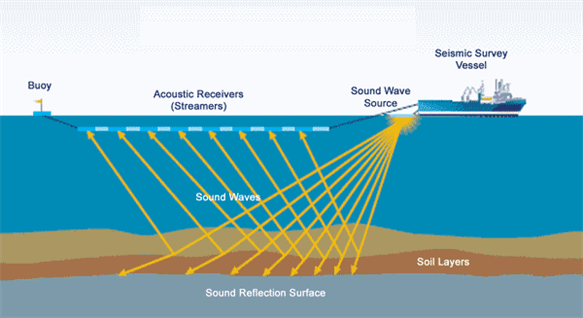
A aquisição de dados sísmicos envolve a implantação de canhões de ar para gerar ondas sonoras, que refletem nas estruturas do subsolo e são capturadas por hidrofones. Esses sensores, localizados em streamers rebocados por navios sísmicos ou colocados no fundo do mar, coletam dados brutos que são posteriormente processados para criar imagens 3D detalhadas da geologia do subsolo.
- Formato de Arquivo: SEG-Y (Sociedade de Geofísicos de Exploração) - formato de arquivo proprietário para armazenamento de dados sísmicos, desenvolvido na década de 1970, otimizado para armazenamento em fita
- Representação de Dados: Os dados processados são armazenados como cubos 3D, oferecendo uma visão abrangente das estruturas do subsolo.
Horizontes Sísmicos: Mapeamento de Limites Geológicos
Horizontes sísmicos são interpretações de dados sísmicos, representando superfícies contínuas dentro do subsolo. Esses horizontes indicam limites geológicos, ligados a mudanças nas propriedades das rochas ou até mesmo no conteúdo de fluidos. Ao analisar os reflexos das ondas sísmicas nessas fronteiras, os geólogos podem identificar características-chave do subsolo.
- Formato do arquivo: CSV - comumente usado para armazenar dados interpretados do horizonte sísmico.
- Representação de Dados: Os horizontes são armazenados como superfícies 2D.
Desafios com a Pipeline Existente
O atual pipeline de dados sísmicos processa dados para gerar as seguintes saídas-chave:
- Cubo de Diferença Sísmica 4D: Rastreia mudanças ao longo do tempo comparando dois cubos sísmicos da mesma área física, normalmente adquiridos meses ou anos apart.
- Mapas de Diferença Sísmica 4D: Esses mapas contêm atributos ou características dos cubos sísmicos 4D para destacar mudanças específicas nos dados sísmicos, auxiliando na análise do reservatório.
No entanto, vários desafios limitam a eficiência e escalabilidade da pipeline existente:
- Processamento Distribuído Subótimo: Depende de vários trabalhos Python independentes rodando em paralelo em clusters de um único nó, levando a ineficiências.
- Resiliência Limitada: Propenso a falhas e carece de mecanismos para tolerância a erros ou recuperação automatizada.
- Falta de Escalabilidade Horizontal: Requer nós de alta configuração com memória substancial (por exemplo, 112 GB), aumentando os custos.
- Alto Esforço de Desenvolvimento e Manutenção: Gerenciar e solucionar problemas do pipeline demanda recursos de engenharia significativos.
Arquitetura de Solução Proposta
Para enfrentar esses desafios, reestruturamos o pipeline como uma solução distribuída usando Ray e Apache Spark™ governados pelo Catálogo Unity na Plataforma Databricks. Esta abordagem melhorou significativamente a escalabilidade, resiliência e eficiência de custos.

Utilizamos as seguintes tecnologias na Plataforma Databricks para implementar a solução:
- Apache Spark™: Um framework de código aberto para processamento e análise de dados em larga escala, garantindo cálculos eficientes e escaláveis.
- Fluxos de trabalho Databricks: Para orquestrar tarefas de engenharia de dados, ciência de dados e análises.
- Delta Lake: Uma camada de armazenamento de código aberto que garante confiabilidade através de transações ACID, manipulação de metadados escalável e processamento unificado de dados em lote e streaming. Ele serve como o formato de armazenamento padrão no Databricks.
- Ray: Um framework de computação distribuída de alto desempenho, usado para escalar aplicações Python e permitir o processamento distribuído de arquivos SEG-Y, aproveitando o SegyIO e a lógica de processamento existente.
- SegyIO: Uma biblioteca Python para processar arquivos SEG-Y, permitindo o manuseio contínuo de dados sísmicos.
Benefícios chave:
Esta pipeline de dados sísmicos reestruturada abordou as ineficiências na pipeline existente, introduzindo escalabilidade, resiliência e otimização de custos. Os seguintes são os principais benefícios realizados:
- Economia de Tempo Significativa: Eliminou o processamento duplicado de dados persistindo resultados intermediários (por exemplo, cubos 3D e 4D), permitindo o reprocessamento apenas dos conjuntos de dados necessários.
- Eficiência de Custo: Redução de custos em até 96% em etapas específicas de cálculo, como a geração de mapas.
- Design Resistente a Falhas: Aproveitou o framework de processamento distribuído do Apache Spark para introduzir tolerância a falhas e recuperação automática de tarefas.
- Escalabilidade Horizontal: Alcançou escalabilidade horizontal para superar as limitações da solução existente, garantindo escalabilidade eficiente à medida que o volume de dados cresce.
- Formato de Dados Padronizado: Adotou um formato de dados aberto e padronizado para simplificar o processamento downstream, simplificar a análise, melhorar o compartilhamento de dados e aprimorar a governança e a qualidade.
Conclusão
Este projeto destaca o grande potencial de plataformas de dados modernas como o Databricks na transformação de fluxos de trabalho tradicionais de processamento de dados sísmicos. Ao integrar ferramentas como Ray, Apache Spark e Delta, e aproveitando a plataforma Databricks, alcançamos uma solução que oferece benefícios mensuráveis:
- Ganhos de eficiência: Processamento de dados mais rápido e tolerância a falhas.
- Reduções de Custo: Uma abordagem mais econômica para a análise de dados sísmicos.
- Manutenibilidade Melhorada: A arquitetura simplificada do pipeline e as pilhas de tecnologia padronizadas reduziram a complexidade do código e o overhead de desenvolvimento.
O pipeline redesenhado não apenas otimizou os fluxos de trabalho sísmicos, mas também estabeleceu uma base escalável e robusta para futuros aprimoramentos. Isso serve como um modelo valioso para outras organizações que visam modernizar seu processamento de dados sísmicos enquanto impulsionam resultados de negócios semelhantes.
Agradecimentos
Agradecimentos especiais às Comunidades de Engenharia de Dados, Ciência de Dados e Análise da Equinor, e às Equipes de Pesquisa e Desenvolvimento da Equinor por suas contribuições para esta iniciativa.
“Excelente experiência trabalhando com serviços profissionais - competência técnica e habilidades de comunicação muito altas. "Conquistas significativas em um curto espaço de tempo" —Anton Eskov
https://www.databricks.com/blog/category/industries/energy?categories=energy
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.