How Equinor Optimized Seismic Data Pipeline with Databricks
by Sourav Gulati and Anton Eskov
- Understanding the complexities in Seismic Data.
- Identifying challenges in existing seismic data processing pipeline .
- Demonstrating how Databricks platform enabled faster, scalable, and more efficient seismic data processing.
The oil and gas industry relies heavily on seismic data to explore and extract hydrocarbons safely and efficiently. However, processing and analyzing large amounts of seismic data can be a daunting task, requiring significant computational resources and expertise.
Equinor, a leading energy company, has used the Databricks Data Intelligence Platform to optimize one of its exploratory seismic data transformation workflows, achieving significant time and cost savings while improving data observability.
Equinor's goal was to enhance one of its 4D seismic interpretation workflows, focusing on automating and optimizing the detection and classification of reservoir changes over time. This process supports identifying drilling targets, reducing the risk of costly dry wells, and promoting environmentally responsible drilling practices. Key business expectations included:
- Optimal drilling targets: Improve target identification to drill up a large number of new wells in the upcoming decades.
- Faster, cost-effective analysis: Reduce the time and cost of 4D seismic analysis through automation.
- Deeper reservoir insights: Integrate more subsurface data to unlock improved interpretations and decision-making.
Understanding Seismic Data
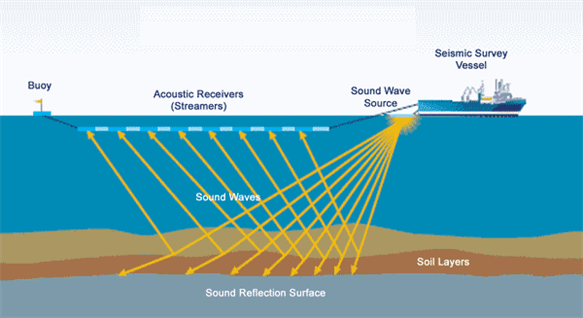
Seismic Cube: 3D models of the subsurface
Seismic data acquisition involves deploying air guns to generate sound waves, which reflect off subsurface structures and are captured by hydrophones. These sensors, located on streamers towed by seismic vessels or placed on the seafloor, collect raw data that is later processed to create detailed 3D images of the subsurface geology.
- File Format: SEG-Y (Society of Exploration Geophysicists) – proprietary file format for storing seismic data, developed in the 1970s, optimized for tape storage
- Data Representation: The processed data is stored as 3D cubes, offering a comprehensive view of subsurface structures.
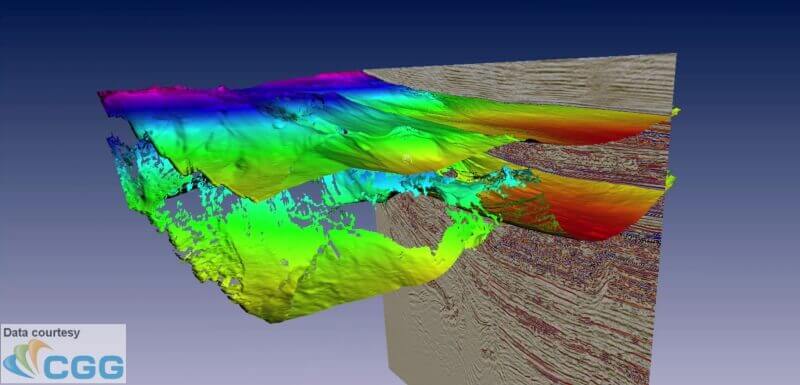
Seismic Horizons: Mapping Geological Boundaries
Seismic horizons are interpretations of seismic data, representing continuous surfaces within the subsurface. These horizons indicate geological boundaries, tied to changes in rock properties or even fluid content. By analyzing the reflections of seismic waves at these boundaries, geologists can identify key subsurface features.
- File Format: CSV – commonly used for storing interpreted seismic horizon data.
- Data Representation: Horizons are stored as 2D surfaces.
Challenges with the Existing Pipeline
The current seismic data pipeline processes data to generate the following key outputs:
- 4D Seismic Difference Cube: Tracks changes over time by comparing two seismic cubes of the same physical area, typically acquired months or years apart.
- 4D Seismic Difference Maps: These maps contain attributes or features from the 4D seismic cubes to highlight specific changes in the seismic data, aiding reservoir analysis.
However, several challenges limit the efficiency and scalability of the existing pipeline:
- Suboptimal Distributed Processing: Relies on multiple standalone Python jobs running in parallel on single-node clusters, leading to inefficiencies.
- Limited Resilience: Prone to failures and lacks mechanisms for error tolerance or automated recovery.
- Lack of Horizontal Scalability: Requires high-configuration nodes with substantial memory (e.g., 112 GB), driving up costs.
- High Development and Maintenance Effort: Managing and troubleshooting the pipeline demands significant engineering resources.
Proposed Solution Architecture
To address these challenges, we re-architected the pipeline as a distributed solution using Ray and Apache Spark™ governed by Unity Catalog on the Databricks Platform. This approach significantly improved scalability, resilience, and cost efficiency.

We used the following technologies on the Databricks Platform to implement the solution:
- Apache Spark™: An open source framework for large-scale data processing and analytics, ensuring efficient and scalable computation.
- Databricks Workflows: For orchestrating data engineering, data science, and analytics tasks.
- Delta Lake: An open source storage layer that ensures reliability through ACID transactions, scalable metadata handling, and unified batch and streaming data processing. It serves as the default storage format on Databricks.
- Ray: A high-performance distributed computing framework, used to scale Python applications and enable distributed processing of SEG-Y files by leveraging SegyIO and existing processing logic.
- SegyIO: A Python library for processing SEG-Y files, enabling seamless handling of seismic data.
Key Benefits:
This re-architected seismic data pipeline addressed inefficiencies in the existing pipeline while introducing scalability, resilience, and cost optimization. The following are the key benefits realized:
- Significant Time Savings: Eliminated duplicate data processing by persisting intermediate results (e.g., 3D and 4D cubes), enabling reprocessing of only the necessary datasets.
- Cost Efficiency: Reduced costs by up to 96% on specific calculation steps, such as map generation.
- Failure-Resilient Design: Leveraged Apache Spark’s distributed processing framework to introduce fault tolerance and automatic task recovery.
- Horizontal Scalability: Achieved horizontal scalability to overcome the limitations of the existing solution, ensuring efficient scaling as data volume grows.
- Standardized Data Format: Adopted an open, standardized data format to streamline downstream processing, simplify analytics, improve data sharing, and enhance governance and quality.
Conclusion
This project highlights the large potential of modern data platforms like Databricks in transforming traditional seismic data processing workflows. By integrating tools such as Ray, Apache Spark and Delta, and leveraging Databricks' platform, we achieved a solution that delivers measurable benefits:
- Efficiency Gains: Faster data processing and fault tolerance.
- Cost Reductions: A more economical approach to seismic data analysis.
- Improved Maintainability: Simplified pipeline architecture and standardized technology stacks reduced code complexity and development overhead.
The redesigned pipeline not only optimized seismic workflows but also set a scalable and robust foundation for future enhancements. This serves as a valuable model for other organizations aiming to modernize their seismic data processing while driving similar business outcomes.
Acknowledgments
Special thanks to the Equinor Data Engineering, Data Science and Analytics Communities, and Equinor Research and Development Teams for their contributions to this initiative.
“Excellent experience working with Professional services – very high technical competence and communication skills. Significant achievements in quite a short time” —Anton Eskov
https://www.databricks.com/blog/category/industries/energy?categories=energy
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.