Como a arquitetura lakebase entrega gravações 5x mais rápidas no Postgres
Resolvendo o gargalo de desempenho estrutural no Postgres gerenciado
por David Wein e Vlad Lazar
- Lakebase agora oferece até 5x mais throughput para cargas de trabalho OLTP com alta intensidade de escrita, um ponto problemático comum para aplicações Postgres de alta escala.
- A arquitetura do lakebase nos permite descarregar tarefas críticas de recuperação de falhas da camada de computação para o armazenamento distribuído.
- A amostragem de produção mostra melhorias no throughput de escrita de 4,5x em computações de 32 vCPUs e uma redução de 94% no tráfego WAL, tudo isso enquanto reduz a latência de cauda de leitura em 2x sem comprometer a durabilidade.
Em uma lakebase, computação e armazenamento são separados por design. Embora essa separação tenha sido originalmente criada para flexibilidade operacional, incluindo escalabilidade, ramificação e recuperação instantânea, ela também abre uma enorme fronteira de desempenho.
Ao desacoplar essas camadas, podemos descarregar o trabalho da sua computação Postgres para o nosso armazenamento distribuído de maneiras que são estruturalmente impossíveis em implantações Postgres tradicionais e monolíticas. Nesta publicação, exploraremos como exploramos essa vantagem arquitetônica para eliminar um gargalo Postgres de décadas, melhorando a taxa de transferência de escrita do Postgres em 5x, enquanto reduzimos as latências de cauda de leitura em 2x e o tráfego WAL em 94%.
O custo oculto da durabilidade tradicional do Postgres
Para entender como alcançamos uma melhoria de 5x no desempenho do Postgres gerenciado, precisamos analisar como o Postgres tradicional lida com a durabilidade.
No Postgres, toda alteração de banco de dados é primeiro salva em um log sequencial (o Write-Ahead Log, ou WAL) para garantir que os dados não sejam perdidos em caso de falha. Para manter os tempos de recuperação de falhas rápidos, o Postgres executa periodicamente um evento de limpeza em segundo plano chamado "checkpoint". Ao contrário de um snapshot, um checkpoint é simplesmente um marcador de marco no log. Durante um checkpoint, o Postgres pega todos os dados modificados atualmente na memória (gerenciados em blocos de 8KB chamados "páginas") e os descarrega para o disco principal, até um ponto específico no log. Se ocorrer uma falha, o Postgres restaura seus dados começando nesse marco de checkpoint e reproduzindo os logs WAL recentes sobre o disco.
No entanto, existe um risco: se o servidor falhar exatamente enquanto salva uma página de 8KB no disco, a página pode ser escrita apenas parcialmente, resultando em uma "página corrompida". Se o Postgres tentar reproduzir uma pequena atualização de log sobre uma página corrompida, os dados são permanentemente arruinados. Para corrigir isso, o Postgres deve garantir que nunca dependa de um disco corrompido para recuperação.
Ele faz isso usando um "Full Page Write" (FPW). Na primeira vez que uma página é modificada após um marco de checkpoint, o Postgres não apenas registra a pequena alteração; ele copia a página inteira de 8KB para o WAL. Se ocorrer uma falha e a página do disco estiver corrompida, o Postgres ignora o disco danificado, pega o backup de 8KB intocado do WAL e o usa como ponto de partida perfeito para reproduzir o restante dos logs. Embora isso garanta segurança absoluta, é caro: em aplicações com muitas escritas, registrar páginas inteiras de 8KB pode inflar o volume do log em até 15x, muitas vezes se tornando o maior gargalo de desempenho do sistema.
A solução lakebase: eliminando o risco de páginas corrompidas
Na arquitetura lakebase, sua computação é sem estado. Ela não depende de um diretório de dados local. Em vez disso, ela transmite WAL para um quorum de safekeepers baseado em Paxos.
Como não há página de disco local para corromper, o modo de falha que o FPW foi projetado para prevenir simplesmente não existe. No entanto, desativar o FPW ingenuamente cria um problema secundário: o desempenho de leitura. Sem essas imagens periódicas de página completa no log, a camada de armazenamento teria que reproduzir uma cadeia infinitamente longa de pequenos deltas para reconstruir uma página para uma solicitação de leitura. O que antes era uma reprodução limitada O(frequência de checkpoint) torna-se uma cadeia ilimitada, levando a um pico na latência de leitura e no consumo de recursos.
Inovação: pushdown de geração de imagem para armazenamento distribuído
Resolvemos isso movendo a inteligência do nó de computação para a camada de armazenamento. Chamamos isso de pushdown de geração de imagem.
Quando a computação Postgres solicita uma página do armazenamento, o pageserver (um componente do sistema de armazenamento distribuído Lakebase) a reconstrói encontrando a imagem materializada mais recente dessa página e reproduzindo quaisquer deltas WAL por cima. As imagens de página completa que a computação costumava incorporar no WAL funcionavam como pontos de reinício periódicos nessa cadeia de deltas, mantendo naturalmente a cadeia razoavelmente limitada e as leituras rápidas. Para um tratamento mais aprofundado desse mecanismo, consulte Deep dive into Neon storage engine.
Com as escritas de página completa desabilitadas, esses pontos de reinício desaparecem. Sem inteligência adicional no sistema de armazenamento distribuído, uma página frequentemente atualizada poderia acumular uma longa cadeia de pequenos deltas sem uma imagem intermediária. O resultado seria um aumento indesejável na latência de leitura e no consumo de recursos, pois o pageserver reproduziria toda a cadeia para atender a uma leitura, aumentando a latência e o consumo de recursos.
Para evitar esse problema, transferimos a responsabilidade de geração de imagem do fluxo WAL da computação para a camada de armazenamento, preservando o comportamento de leitura limitada do armazenamento e ainda eliminando a sobrecarga do WAL na computação. O pageserver agora gera imagens de página completa quando uma página acumulou mais registros de delta do que um limite configurado sem uma imagem intermediária. Esta é uma abordagem naturalmente melhor porque a decisão de gerar uma nova imagem é baseada no número real de alterações em uma página, em vez do processo de checkpoint do Postgres, que não está relacionado.
Veja por que isso é significativamente melhor para o desempenho:
- Eficiência da rede: A computação envia apenas os deltas compactos, que são as alterações reais, resultando em uma redução de 94% no tráfego em nossos benchmarks.
- Escalabilidade: O trabalho é movido do único escritor Postgres para a camada de armazenamento distribuída e escalável independentemente. A geração de imagens para um branch de projeto agora é compartilhada entre vários pageservers em segundo plano.
- Leituras otimizadas: A geração de imagens agora é baseada nas alterações reais em uma página, em vez do processo de checkpoint do Postgres, que não está relacionado.
Quantificando o impacto: do laboratório à produção
Nós avaliamos essa otimização usando HammerDB TPROC-C (um benchmark OLTP derivado do TPC-C) e validamos os resultados em cargas de trabalho de produção do mundo real.
1. Escalabilidade de computação serverless
A taxa de transferência é medida em novos pedidos por minuto (NOPM). Os ganhos escalam dramaticamente com o tamanho da instância de computação:
Tamanho da computação | Antes (NOPM) | Depois (NOPM) | Ganho de taxa de transferência |
4-vCPU | 78,876 | 94,891 | 20% |
16-vCPU | 95,832 | 269,189 | 2.8x |
32-vCPU | 95,686 | 439,300 | 4.5x+ |

Em uma computação de 32 vCPU, a melhoria excedeu 450%.
Com imagens de página completa geradas na computação, cada transação gera 58Kb de WAL em média. Com a geração de imagens transferida (pushdown), esse valor cai para menos de 4Kb — uma redução de 94%. A melhoria na taxa de transferência segue diretamente: menos WAL significa menos contenção no caminho de escrita, menos largura de banda de rede consumida e menos trabalho para a camada de armazenamento ingerir.

Ao remover o gargalo FPW do Postgres, permitimos que a taxa de transferência escalasse linearmente com os recursos de computação. Isso é algo que o Postgres monolítico tem dificuldade em fazer sob carga pesada de escrita.
2. Validação em produção no mundo real
Em um ambiente de produção para um projeto de alto perfil de 56 vCPU, a ativação do pushdown de imagem reduziu a geração de WAL em estado estacionário de 30 MB/s para apenas 1 MB/s.

Essa diminuição no volume correlacionou-se diretamente com o aumento da taxa de transferência de transações durante os picos diários.
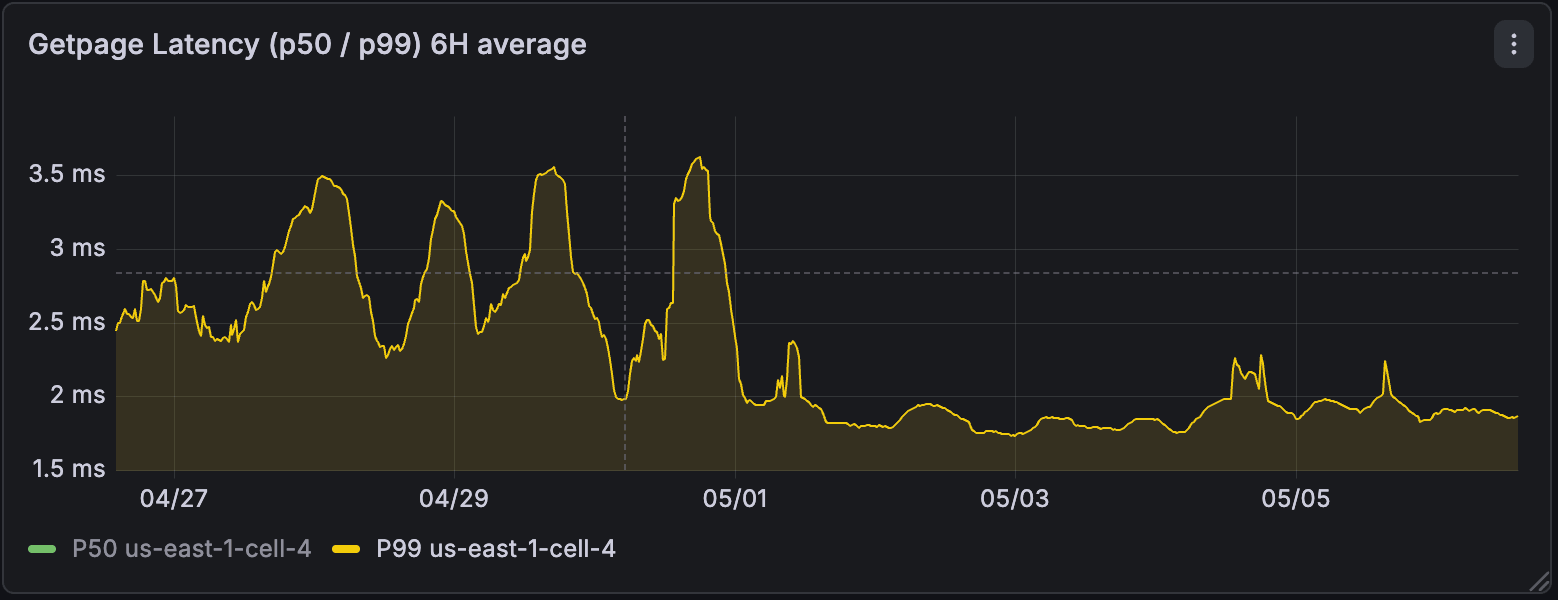
Isso não ajudou apenas as gravações. Ao otimizar as cadeias delta, o número de registros WAL que precisam ser aplicados por leitura caiu significativamente. Observamos as latências de leitura p99 caírem de 30% para 50% e as latências p50 caírem em aproximadamente 30%.

Em uma visão mais ampla, no nível regional, após a habilitação, vimos a quantidade total de WAL gerada pelos recursos de computação cair em até 4x. A latência p99 das leituras do motor de armazenamento melhorou em até 3x e se tornou muito mais estável.

3. Tabelas sincronizadas do Lakebase
Para Tabelas Sincronizadas com uso intensivo de dados, o impacto foi imediato. Um cliente viu a taxa de transferência de ingestão saltar de 17 mil linhas por segundo para 62 mil linhas por segundo, um aumento de 3x, simplesmente ao habilitar o pushdown de imagem.
Implantação contínua: desempenho sem interrupção
Desde o final de março, implementamos isso em toda a nossa frota. Agora está ativo para todos os bancos de dados Lakebase Serverless e Neon globalmente.
A mudança foi aplicada aos recursos de computação em execução por meio do nosso plano de controle e sistema de armazenamento, que coordenaram a transição automaticamente. Isso foi alcançado usando o mecanismo de registro WAL XLOG_FPW_CHANGE WAL existente do Postgres, o que significa que nenhuma reinicialização ou interrupção foi necessária para nossos clientes.
O que vem a seguir para o desempenho do Postgres gerenciado?
A arquitetura do Lakebase foi construída para flexibilidade, mas projetada para desempenho. O pushdown de gravações de página completa faz parte de um esforço sistemático para colher os benefícios da separação de armazenamento e computação.
Assim como introduzimos o pré-aquecimento de cache para aplicação de patches sem tempo de inatividade, continuamos a mover tarefas pesadas de suas transações para nossa pilha de armazenamento de fundo escalável. A 'taxa de gravação' do Postgres é oficialmente coisa do passado.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.