Patching sem Interrupção no Lakebase Parte 1: Pré-aquecimento
O primeiro de vários recursos que tornam as reinicializações de computação invisíveis
por Hans Norheim
- A manutenção planejada causa mais interrupção do que falhas não planejadas para a maioria dos bancos de dados, pois os patches ocorrem com mais frequência do que as falhas de hardware. O objetivo é tornar as atualizações de versão e os patches de segurança completamente imperceptíveis.
- O principal problema com as reinicializações de banco de dados é que os caches em memória são perdidos, causando degradação de desempenho de até 70% enquanto os dados são recarregados do armazenamento. Sob carga de trabalho pesada, isso pode evoluir de um problema de desempenho para um problema de disponibilidade.
- O Lakebase resolve isso iniciando um novo nó de computação em segundo plano antes de uma reinicialização agendada, pré-aquecendo seu cache usando a lista de páginas da primária atual e o stream WAL, e então promovendo-o para primária sem custo adicional ou sobrecarga de réplica.
Garantir que os bancos de dados dos clientes estejam sempre disponíveis é uma das coisas mais importantes que fazemos no Lakebase. Projetamos o sistema com redundância em todos os níveis, alternando e recuperando automaticamente seu banco de dados em caso de falhas de hardware ou software.
Em um sistema de larga escala, essas falhas não planejadas são uma expectativa estatística, mas para um banco de dados individual, elas não são tão frequentes. Para um banco de dados individual, a manutenção planejada tende a causar mais interrupção de carga de trabalho. Afinal, um banco de dados típico é atualizado com mais frequência do que sofre falhas de hardware.
Hoje, quase todos os provedores de banco de dados operam com janelas de manutenção: períodos em que seu banco de dados encerra todas as conexões ativas e é atualizado e reiniciado em um processo que pode levar de alguns segundos a minutos. Embora o Lakebase permita que você agende atualizações em um horário que seja ideal para você, ainda é uma breve interrupção quando acontece.
Acreditamos que podemos fazer melhor. Este post é o primeiro de uma série sobre como estamos aproveitando a arquitetura do lakebase para eliminar completamente o impacto da manutenção planejada. Nosso objetivo: tornar as atualizações de versão e os patches de segurança completamente imperceptíveis.
Neste post, abordaremos o pré-aquecimento: uma técnica que evita qualquer degradação de desempenho que segue uma reinicialização do banco de dados. Em posts futuros, discutiremos melhorias no próprio processo de failover e otimizações adicionais que nos aproximam do verdadeiro patching sem interrupção.
O Problema com Reinicializações a Frio
O desafio ao reiniciar o PostgreSQL é que os caches em memória (especificamente o buffer cache e o local file cache) são perdidos. Mesmo que o banco de dados volte a ficar online muito rapidamente (1 segundo @ P99), a carga de trabalho pode experimentar uma desaceleração nos primeiros minutos após a reinicialização – vimos uma redução de ~70% no pgbench TPS. Isso se deve a uma baixa taxa de acertos do cache enquanto os dados são lidos novamente do armazenamento e o cache é pré-aquecido. Embora isso possa parecer apenas um problema de desempenho, pode ser um problema de disponibilidade se a desaceleração for grave o suficiente para que o banco de dados não consiga acompanhar a carga de trabalho e ocorram timeouts.
Existem técnicas para resolver isso no Postgres: o pg_prewarm pode ser usado para pré-aquecer os caches de buffer. No entanto, isso é executado após uma reinicialização, quando a carga de trabalho já está impactada. A replicação de streaming pode ser usada para configurar uma réplica, que pode ser pré-aquecida antes de alternar para ela (promovendo-a para primária). No entanto, isso requer a criação de uma réplica completa e a orquestração cuidadosa do pré-aquecimento antes do failover.
Pré-aquecimento na Arquitetura Lakebase
Na arquitetura do lakebase, combinamos nós de computação sem estado e elásticos com armazenamento compartilhado e desassociado. Os nós de computação utilizam caches locais para oferecer o máximo desempenho sem sacrificar as propriedades serverless. Embora o cache enfrente os mesmos problemas de inicialização a frio descritos acima, temos mais opções com a arquitetura Lakebase.
Como as réplicas de computação Postgres do Lakebase são sem estado, podemos iniciá-las e encerrá-las sob demanda. Utilizamos isso e combinamos com o pré-aquecimento automático em reinicializações planejadas para minimizar o impacto no desempenho da carga de trabalho. Veja como funciona:
- Uma nova versão da imagem de computação Postgres do Lakebase fica disponível. Você recebe uma notificação e pode agendar a reinicialização para um horário conveniente.
- Pouco antes do horário agendado, nosso plano de controle inicia uma nova computação Postgres em segundo plano. Você não a vê e não é cobrado por ela. A carga de trabalho da primária atual não é afetada.
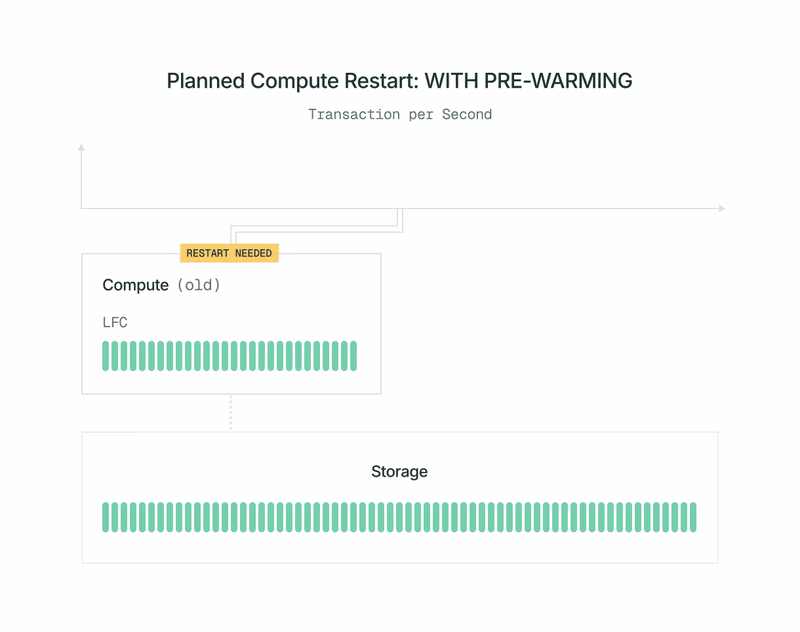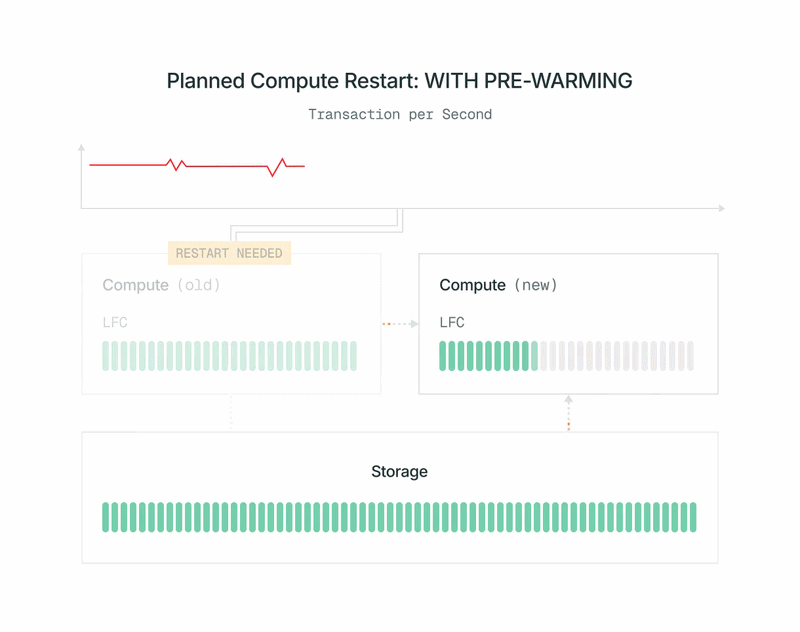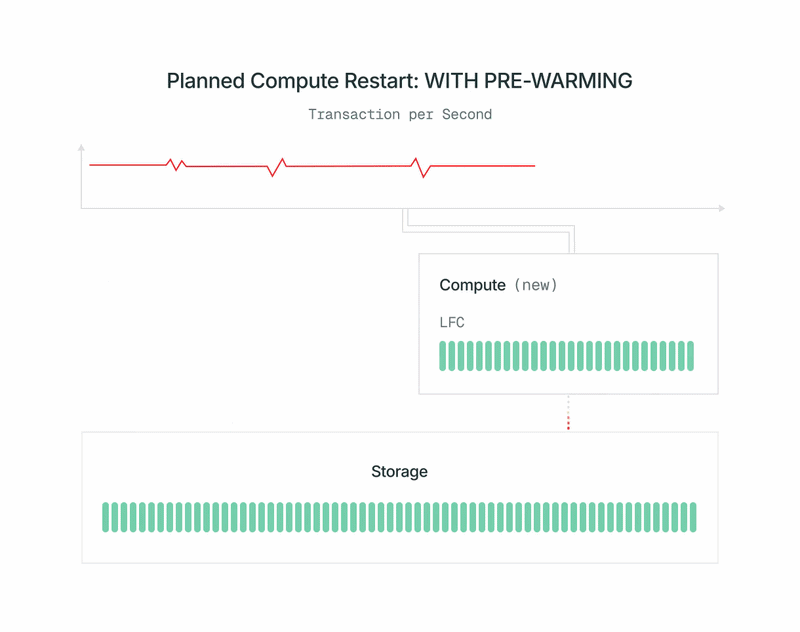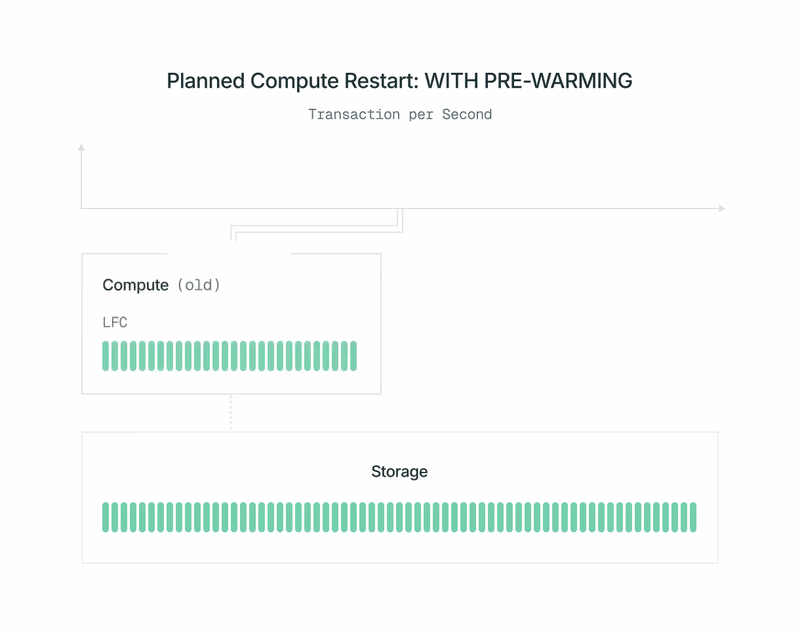
- Uma lista de páginas no cache da primária atual é enviada para a nova computação. A nova computação carrega essas páginas em cache de nossa camada de armazenamento compartilhado sem impactar a primária.
- A nova computação se inscreve no WAL (write-ahead log) para manter seu cache atualizado. Para eficiência, ao contrário de uma réplica Postgres normal, ela pode ignorar todos os registros WAL que não afetam seu cache. Ela obtém o WAL de nossos Safekeepers, não colocando carga adicional na computação primária.
- Quando o pré-aquecimento é concluído, desligamos rapidamente a primária antiga, promovemos a nova computação para primária e a ativamos. A promoção usa o pg_promote padrão do OSS Postgres e não reinicia o servidor do banco de dados.
Antes:

Depois:
Com a arquitetura Lakebase, você obtém isso sem custo adicional, sem pagar por réplicas extras. A partir de hoje, todas as reinicializações planejadas de endpoints de leitura/gravação são realizadas dessa forma sem que você precise fazer nada. Em breve, estenderemos isso também para endpoints somente leitura.
Resultados
Para medir o impacto de caches frios, executamos o pgbench de 10 GB (fator de escala 670) em um banco de dados enquanto o reiniciávamos - primeiro com o pré-aquecimento ativado, depois sem o pré-aquecimento. O primeiro gráfico mostra uma carga de trabalho somente leitura (pgbench “select only”), enquanto o segundo mostra uma carga de trabalho de leitura/gravação (pgbench “simple update”).


Em ambos os casos, vemos que a taxa de transferência se recupera quase instantaneamente com o pré-aquecimento. Sem o pré-aquecimento, a recuperação é muito mais lenta enquanto o cache frio está sendo pré-aquecido. A diferença é mais acentuada para a carga de trabalho somente leitura porque o pré-aquecimento melhora a taxa de acertos do cache, o que ajuda mais as leituras do que as gravações.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.