Como a MakeMyTrip Alcançou Personalização em Milissegundos em Escala com Databricks
Descubra como o Modo em Tempo Real entrega recomendações de viagem instantâneas e contexto para agentes de IA
- Arquitetura de Streaming Unificada: A MakeMyTrip superou os gargalos de latência do ETL tradicional ao adotar o Modo de Tempo Real (RTM) do Databricks, criando uma arquitetura Spark unificada sem a necessidade de outros motores especializados.
- Personalização em Milissegundos: Ao processar buscas de viajantes de alto volume com fluxo contínuo de dados, o RTM permitiu latências P50 abaixo de 50ms, impulsionando diretamente um aumento de 7% nas taxas de cliques dos usuários.
- Lógica Unificada, Inovação Mais Rápida: Ao usar um motor unificado, a MakeMyTrip consegue transitar perfeitamente do processamento em lote para o de tempo real sem reescrever a lógica de negócios. Isso não só elimina a complexidade operacional, mas também impulsiona a inovação futura, facilitando o fornecimento de contexto em tempo real para agentes de IA generativa, necessário para uma tomada de decisão precisa.
Entregando Personalização em Tempo Real em Escala
Cada milissegundo conta quando viajantes procuram hotéis, voos ou experiências. Como a maior agência de viagens online da Índia, a MakeMyTrip compete em velocidade e relevância em tempo real. Uma de suas funcionalidades mais importantes são os hotéis "recentemente pesquisados": quando os usuários tocam na barra de pesquisa, eles esperam uma lista em tempo real e personalizada de seus interesses recentes, com base em sua interação com o sistema.
Na escala da MakeMyTrip, entregar essa experiência requer latência inferior a um segundo em um pipeline de produção atendendo a milhões de usuários diários — em linhas de negócios de viagens de consumo e corporativas. Ao implementar o Modo em Tempo Real (RTM) da Databricks — o motor de execução de próxima geração no Apache Spark™ Structured Streaming, a MakeMyTrip alcançou com sucesso latências em nível de milissegundo, mantendo uma infraestrutura econômica e reduzindo a complexidade de engenharia.
O Desafio: Latência Ultra-Baixa Sem Fragmentação Arquitetural
A equipe de dados da MakeMyTrip precisava de latência inferior a um segundo para o fluxo de trabalho de hotéis "recentemente pesquisados" em todas as linhas de negócios. Na escala deles, mesmo alguns centenas de milissegundos de atraso criam atrito na jornada do usuário, impactando diretamente as taxas de cliques.
O modo de micro-lotes do Apache Spark introduziu limites de latência inerentes que a equipe não conseguiu superar, apesar de ajustes extensivos — entregando consistentemente latência de um a dois segundos, muito lento para seus requisitos.
Em seguida, eles avaliaram o Apache Flink em aproximadamente 10 pipelines de streaming que resolveram seus requisitos de latência. No entanto, adotar o Apache Flink como um segundo motor teria introduzido desafios significativos de longo prazo:
- Fragmentação arquitetural: Manter motores separados para processamento em tempo real e em lote
- Lógica de negócios duplicada: Regras de negócios precisariam ser implementadas e mantidas em duas bases de código
- Maior sobrecarga operacional: Dobrar o esforço de monitoramento, depuração e governança em múltiplos pipelines
- Riscos de consistência: Resultados correm risco de divergência entre processamento em lote e em tempo real
- Custos de infraestrutura: Executar e ajustar dois motores aumenta os gastos com computação e o fardo de manutenção
Por que o Modo em Tempo Real: Latência de Milissegundo em uma Única Pilha Spark
Como a MakeMyTrip nunca quis uma arquitetura de motor duplo, o Apache Flink não era uma opção viável de longo prazo. A equipe tomou uma decisão arquitetural deliberada: esperar o Apache Spark ficar mais rápido, em vez de fragmentar a pilha.
Portanto, quando o Apache Spark Structured Streaming introduziu o RTM, a MakeMyTrip se tornou o primeiro cliente a adotá-lo. O RTM permitiu que eles alcançassem latência em nível de milissegundo no Apache Spark — atendendo aos requisitos em tempo real sem introduzir outro motor ou dividir a plataforma.
Manter dois motores significa dobrar a complexidade e o risco de desvio de lógica entre cálculos em lote e em tempo real. Queríamos uma única fonte de verdade — um pipeline baseado em Spark — em vez de dois motores para manter. O Modo em Tempo Real nos deu o desempenho que precisávamos com a simplicidade que queríamos." —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
O RTM oferece processamento contínuo de baixa latência através de três inovações técnicas chave que trabalham juntas para eliminar as fontes de latência inerentes à execução de micro-lotes:
- Fluxo contínuo de dados: Os dados são processados à medida que chegam, em vez de serem discretizados em blocos periódicos.
- Agendamento de pipeline: Estágios são executados simultaneamente sem bloqueio, permitindo que tarefas downstream processem dados imediatamente sem esperar que os estágios upstream terminem.
- Shuffle de streaming: Os dados são passados entre tarefas imediatamente, contornando os gargalos de latência dos shuffles tradicionais baseados em disco.
Juntas, essas inovações permitem que o Apache Spark alcance pipelines em escala de milissegundo que antes só eram possíveis com motores especializados. Para saber mais sobre a base técnica do RTM, leia este blog, “Breaking the Microbatch Barrier: The Architecture of Apache Spark Real-Time Mode."
A Arquitetura: Um Pipeline Unificado em Tempo Real
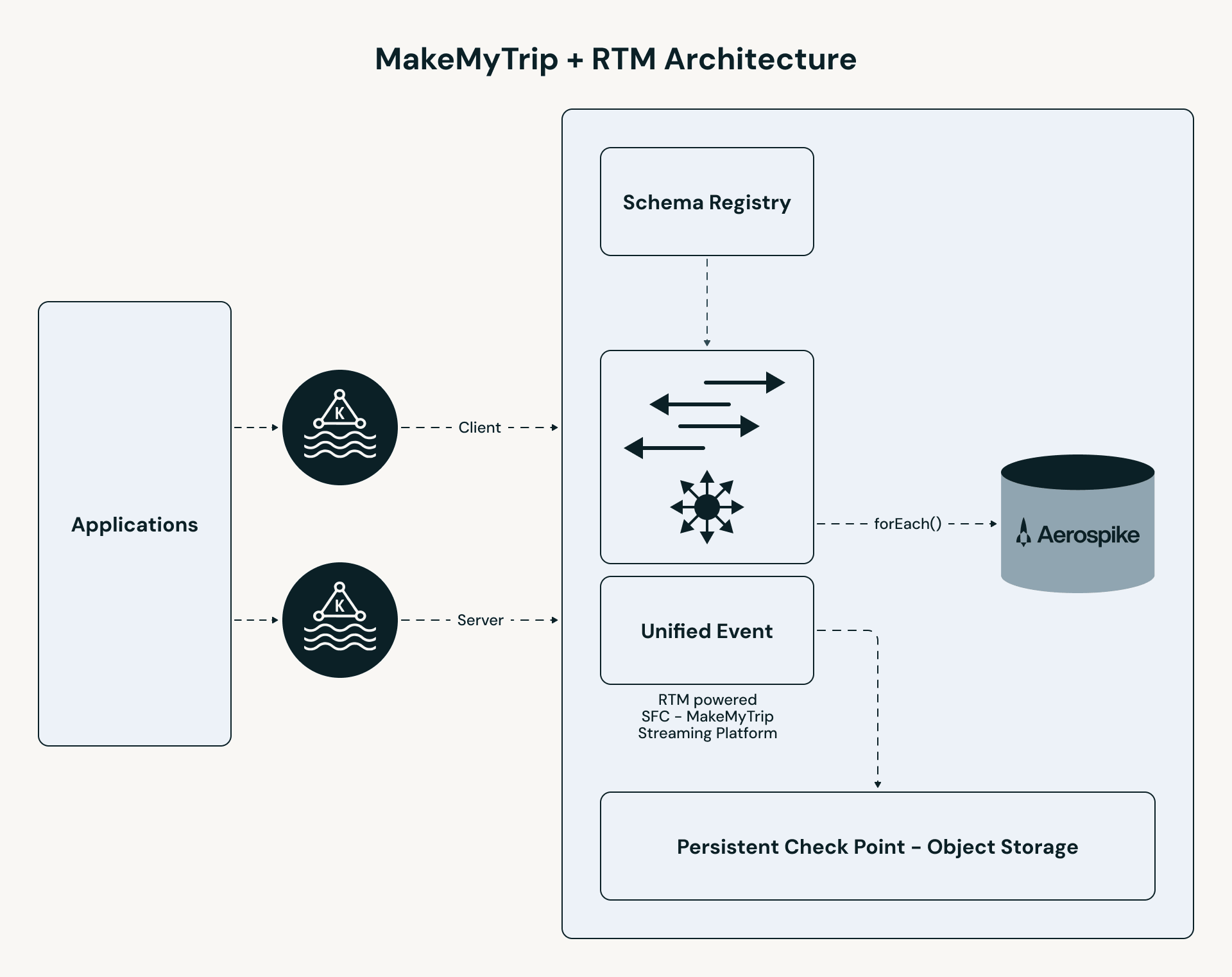
O pipeline da MakeMyTrip segue um caminho de alto desempenho:
- Ingestão unificada: Tópicos de clickstream B2C e B2B são mesclados em um único stream. Toda a lógica de personalização — enriquecimento, consulta com estado e processamento de eventos — é aplicada consistentemente em ambos os segmentos de usuários.
- Processamento RTM: O motor Apache Spark usa agendamento concorrente e shuffle de streaming para processar eventos em milissegundos.
- Enriquecimento com estado: O pipeline realiza uma consulta de baixa latência no Aerospike para recuperar os "Últimos N" hotéis para cada usuário.
- Serviço instantâneo: Os resultados são enviados para um cache de UI (Redis), permitindo que o aplicativo sirva resultados personalizados em menos de 50ms.
Configurando o RTM: uma única linha de alteração de código
Usar o RTM em sua consulta de streaming não requer reescrever a lógica de negócios ou reestruturar pipelines. A única alteração de código necessária é definir o tipo de gatilho como RealTimeTrigger, como mostrado no seguinte trecho de código:
A única consideração de infraestrutura: os slots de tarefa do cluster devem ser maiores ou iguais ao número total de tarefas ativas nas fases de origem e shuffle. A equipe da MakeMyTrip analisou suas partições Kafka, partições de shuffle e complexidade do pipeline antecipadamente para garantir concorrência suficiente antes de ir para produção.
Co-desenvolvimento do RTM para Produção
Como primeiro adotante do RTM, a MakeMyTrip trabalhou diretamente com a engenharia da Databricks para tornar o pipeline pronto para produção. Várias funcionalidades exigiram colaboração ativa entre as duas equipes para construir, ajustar e validar.
- Stream Union: Mesclando B2C e B2B em um Único Pipeline
A MakeMyTrip precisou unificar dois streams de tópicos Kafka separados — clickstream de consumidor B2C e viagens corporativas B2B — em um único pipeline RTM para que a mesma lógica de personalização pudesse ser aplicada consistentemente em ambos os segmentos de usuários. Após um mês de colaboração próxima com a engenharia da Databricks, o recurso foi construído e lançado. O resultado foi um único pipeline onde toda a lógica de negócios reside em um só lugar, sem risco de divergência entre os segmentos de usuários. - Multiplexação de Tarefas: Mais Partições, Menos Núcleos
O modelo padrão do RTM atribui um slot/núcleo por partição Kafka. Com 64 partições na configuração de produção da MakeMyTrip, isso se traduz em 64 slots/núcleos — proibitivo em termos de custo na escala deles. Para resolver isso, a equipe Databricks introduziu a opção MaxPartitions para Kafka, que permite que múltiplas partições sejam tratadas por um único núcleo. Isso deu à MakeMyTrip a alavancagem que precisavam para reduzir os custos de infraestrutura sem comprometer a taxa de transferência. - Fortalecimento do Pipeline: Checkpointing, Backpressure e Tolerância a Falhas
A equipe trabalhou em um conjunto de desafios operacionais específicos para cargas de trabalho de alta taxa de transferência e baixa latência: ajuste da frequência e retenção de checkpoint, tratamento de timeouts e gerenciamento de backpressure durante picos de volume de clickstream. Ao escalar para 64 partições Kafka, habilitando backpressure e limitando o MaxRatePerPartition a 500 eventos, a equipe otimizou a taxa de transferência e a estabilidade. Através deste ajuste iterativo de configurações de lote, particionamento e comportamento de retentativa, eles chegaram a um pipeline estável e pronto para produção atendendo a milhões de usuários diariamente.
Resultados
O RTM permitiu personalização instantânea e melhor responsividade, maior engajamento medido por taxas de cliques e simplicidade operacional de um único motor unificado. As principais métricas são mostradas abaixo.
Apache Spark como um Motor em Tempo Real
A implantação da MakeMyTrip prova que o RTM no Spark oferece a latência extremamente baixa que seus aplicativos em tempo real exigem. Como o RTM é construído nas mesmas APIs familiares do Spark, você pode usar a mesma lógica de negócios em pipelines batch e em tempo real. Você não precisa mais do overhead de manter uma segunda plataforma ou um codebase separado para processamento em tempo real e pode simplesmente habilitar o RTM no Spark com uma única linha de código.
O Modo em Tempo Real nos permitiu comprimir nossa infraestrutura e entregar experiências em tempo real sem gerenciar múltiplos motores de streaming. À medida que avançamos para a era dos agentes de IA, direcioná-los efetivamente requer a construção de contexto em tempo real a partir de fluxos de dados. Estamos experimentando o Spark RTM para fornecer aos nossos agentes o contexto mais rico e recente necessário para tomar as melhores decisões possíveis.” —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
Começando com o Modo em Tempo Real
Para saber mais sobre o Modo em Tempo Real, assista a este vídeo sob demanda sobre como começar ou revise a documentação.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.