Quebrando a barreira do microbatch: a arquitetura do Mode de tempo real do Apache Spark
Como evoluímos o Spark para lidar com ETL de alto throughput e cargas de trabalho de transmissão de latência ultrabaixa
por Jerry Peng, Siying Dong e Indrajit Roy
- O Mode tempo real do Apache Structured Streaming unifica ETL de throughput alto e cargas de trabalho operacionais com latência de milissegundos em um único mecanismo.
- Aprofunde-se no modelo de execução híbrido, detalhando os estágios de processamento concorrentes e os operadores não bloqueantes que oferecem latências de milissegundos.
- Os clientes agora podem alcançar uma capacidade de resposta inferior a 100 ms para aplicações de latência ultrabaixa, como detecção de fraudes em tempo real.
Com o lançamento do modo de tempo real (RTM) no Apache Spark 4.1, o Structured Streaming agora oferece latência de milissegundos. Em uma postagem no blog recente, mostramos como o RTM pode superar o Flink em muitas cargas de trabalho de engenharia de recursos de baixa latência (veja abaixo).
Neste blog, discutiremos as mudanças na arquitetura que permitiram ao Structured Streaming suportar tanto cargas de trabalho de ETL de alta throughput quanto cargas de trabalho de latência ultrabaixa.
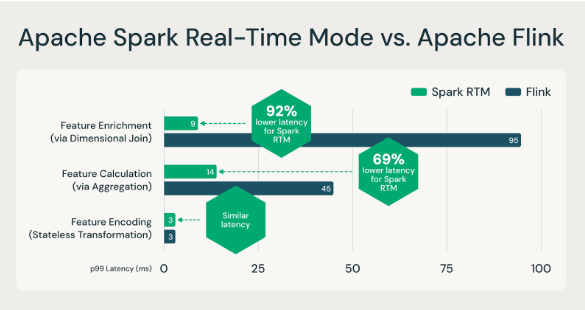
O RTM do Apache Spark é mais rápido que o Flink para casos de uso de engenharia de recursos.
O dilema de throughput vs. latência
Até agora, escolher um mecanismo de transmissão significava fazer uma concessão, optando por sistemas como o Apache Spark para cargas de trabalho de ETL de alta vazão, ou sistemas como o Apache Flink para cargas de trabalho de baixa latência. Os dois sistemas têm semântica e características de desempenho muito diferentes. Isso muda com o RTM no Structured Streaming. Com a introdução do RTM, o Apache Spark agora pode lidar com casos de uso tanto de alta throughput quanto de latência ultrabaixa. Isso significa que agora é possível escolher um único mecanismo, sem uma nova curva de aprendizado, e evitar o gerenciamento de dois sistemas completamente diferentes.
A arquitetura de microlote oferece alta throughput
O Spark Structured Streaming usa uma arquitetura de microlotes: o sistema de transmissão recebe os dados de entrada e os divide em lotes discretos, chamados de épocas, com base na disponibilidade dos dados e nas configurações de tamanho máximo de lote. O mecanismo do Spark aplica a lógica de negócios por meio de transformações como projeção, filtro e agregação. Os resultados são gerados como uma transmissão contínua de lotes. O Structured Streaming se destaca no processamento de alta throughput devido a essa arquitetura de microlotes: como vários registros são processados juntos, as sobrecargas fixas são amortizadas e a execução vetorizada pode melhorar ainda mais a throughput. Esses lotes são executados em paralelo, mantendo a alta utilização do hardware. O modo de microlote aloca dinamicamente slots de tarefa em várias transmissões, o que também ajuda a obter alta utilização e throughput. A inovação fundamental do Spark de tolerância a falhas baseada em linhagem garante que essas transmissões sejam processadas com fortes garantias de exatamente uma vez.
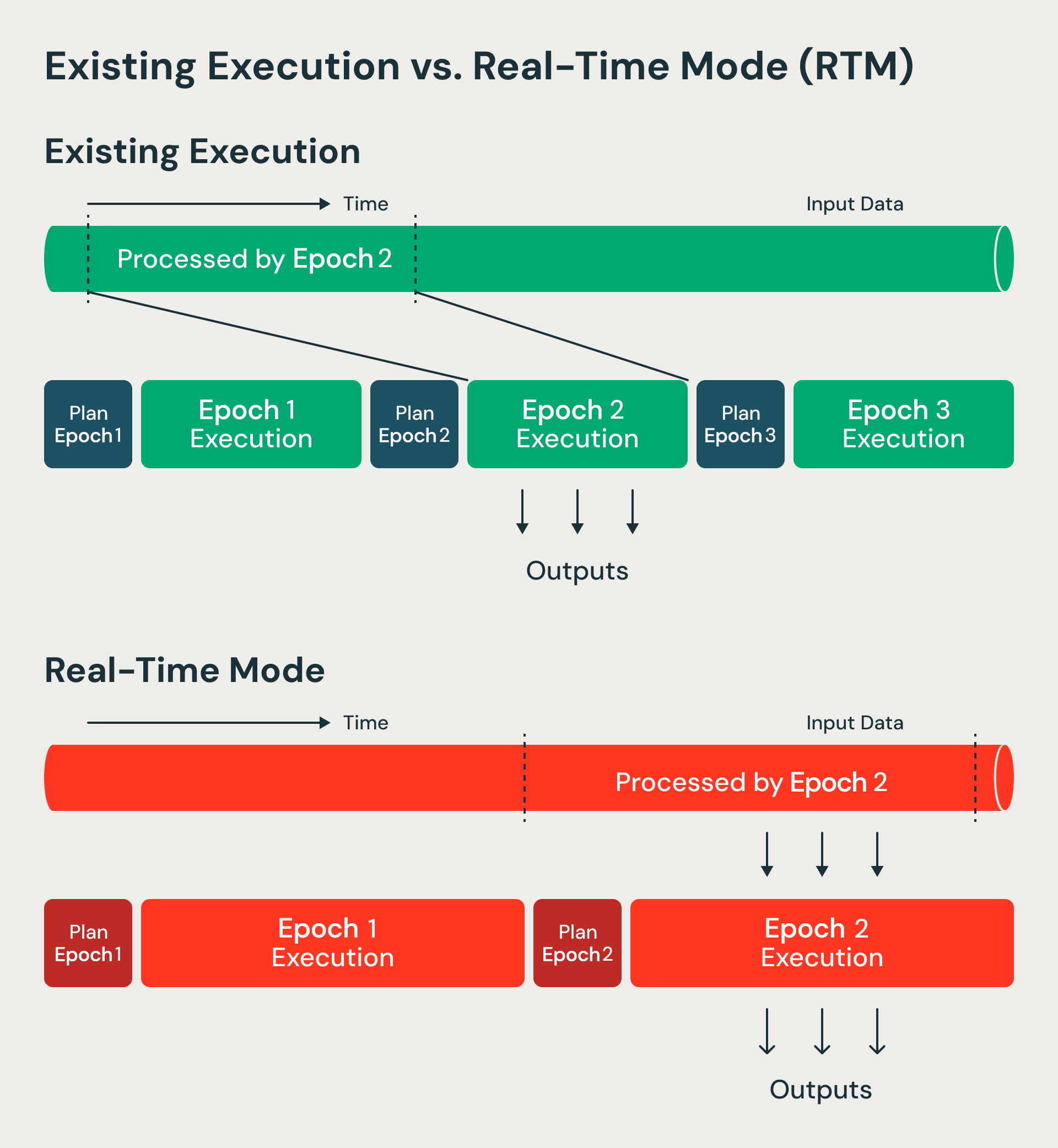
O RTM processa dados de maneira não bloqueante em comparação com o modo de microlote.
Resolvendo o desafio da baixa latência
Embora o Structured Streaming seja muito bom para lidar com cargas de trabalho de ETL e ingestão no nível de segundos, muitos casos de uso operacionais exigem latência no nível de milissegundos. Detecção de fraudes em transações financeiras, percepções em tempo real no setor de viagens ou análise de dados de telemetria de veículos conectados são exemplos em que os clientes precisam de respostas em milissegundos.
Desafio de arquitetura: por que lotes menores não funcionam
A solução óbvia pode parecer simples: basta diminuir o tamanho dos lotes. Se processarmos um registro por vez, deveríamos obter um desempenho em tempo real. Infelizmente, não é tão simples assim.
Cada microlote no Structured Streaming acarreta custos fixos que dominam o tempo de execução ao processar pequenas quantidades de dados. O sistema grava Logs no armazenamento de objetos durável antes e depois de cada execução de lotes. Além disso, as atualizações de estado para cada query com estado também precisam ser upload para o armazenamento de objetos ao final de um microlote. Esses são os passos críticos para garantir a semântica de consistência, mas podem adicionar centenas de milissegundos, se não segundos, ao tempo de execução. Mesmo que ocultemos algumas dessas latências, a latência do planejamento de cada lote, a sobrecarga do planejamento lógico e físico, a serialização de tarefas e o agendamento são difíceis de reduzir. Como você pode imaginar, a redução do tamanho dos lotes rapidamente encontra um obstáculo. A figura abaixo mostra que, quando os microlotes se tornam muito pequenos (barra mais à esquerda), os custos fixos de processamento de microlotes dominam a execução e aumentam a latência de ponta a ponta.
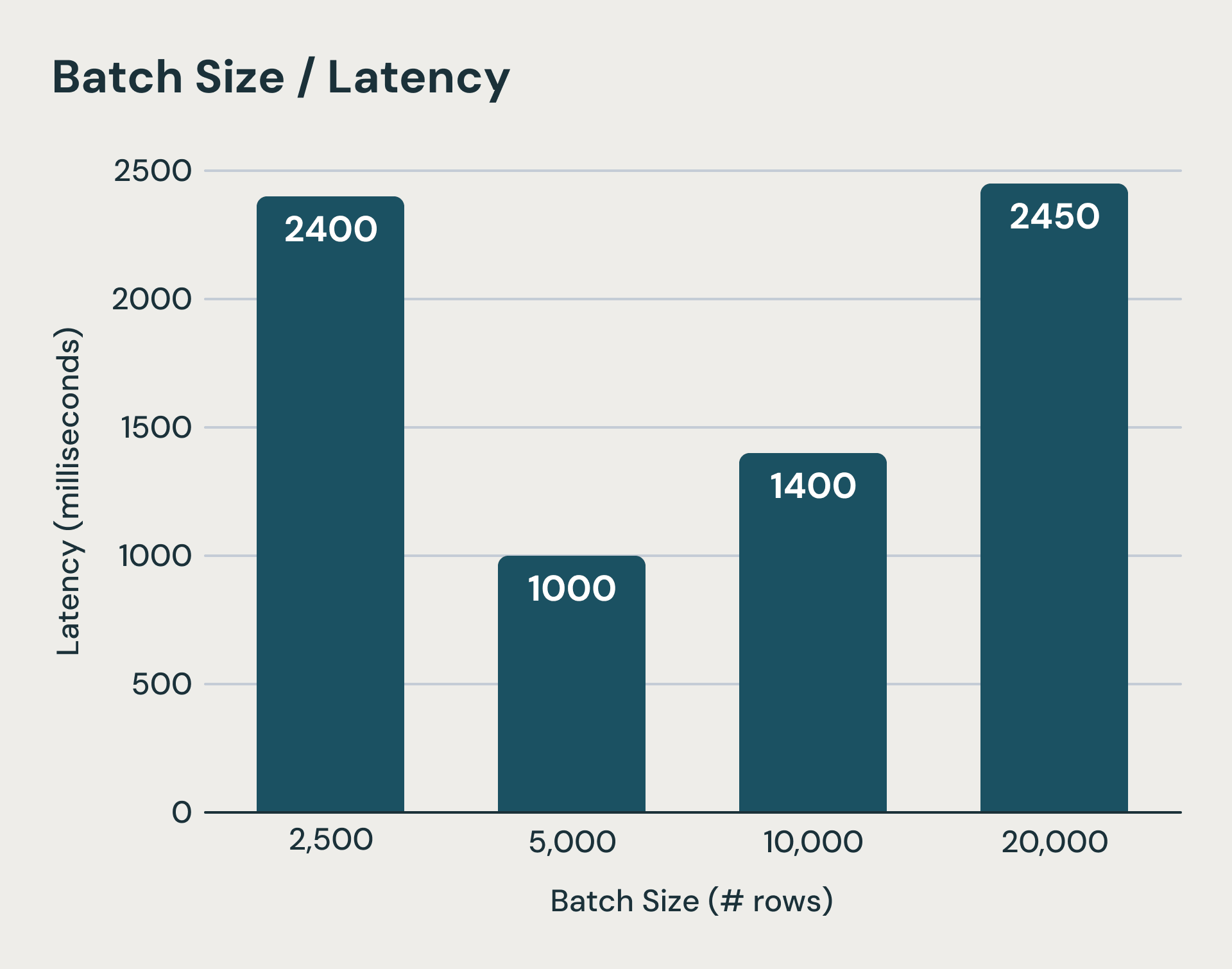
Além de um limite, tamanhos de lote menores podem aumentar a latência devido a sobrecargas fixas
Isso nos apresentou um desafio de arquitetura: queríamos manter as vantagens de custo e de tolerância a falhas da arquitetura de micro-lotes e, ao mesmo tempo, alcançar a baixa latência que se espera de modelos que processam um registro de cada vez (como o Apache Storm e o Apache Flink). Nossa key percepções é que podemos evoluir a arquitetura de microlote para dar suporte a cargas de trabalho em tempo real. Continuamos usando muitos dos principais recursos da arquitetura de microlote, como o checkpointing para tolerância a falhas. No entanto, eliminamos os passos em que os dados costumavam esperar, o que resultava em alta latência. Abordaremos essas mudanças abaixo.
Nossa solução: um modelo de execução híbrido
Veja como melhoramos a latência do Structured Streaming:
1. Épocas de maior duração com fluxo de dados contínuo
O modo de microlote processa lotes de dados chamados de épocas. Os limites da época são decididos antecipadamente usando offsets de começar e fim. O modo em tempo real, por sua vez, processa épocas de maior duração, mas modifica como os dados fluem dentro de cada época. Os dados agora fluem continuamente por diferentes estágios e operadores, sem bloqueio. Como as épocas têm maior duração, a sobrecarga de checkpointing e de barreiras é amortizada. Nos limites da época, ainda usamos barreiras para o registro de recuperação e o reagendamento de tarefas, mantendo os benefícios que tornam as arquiteturas de micro-lotes resilientes e eficientes. Essencialmente, evoluímos os lotes no Structured Streaming para um intervalo de checkpoint.
2. Estágios de processamento concorrentes
Na arquitetura do Structured Streaming, os estágios de processamento eram executados sequencialmente: os reducers esperavam a conclusão dos mappers, criando atrasos desnecessários. Tornamos esses estágios concorrentes no modo de tempo real. Agora, o driver do Spark solicita os deslocamentos de origem e agenda os mappers, mas os reducers podem começar a processar os arquivos de shuffle assim que eles se tornam disponíveis, em vez de esperar que todos os mappers terminem. Essa mudança reduz drasticamente a latência de ponta a ponta. A figura do RTM abaixo mostra que os dois estágios estão em execução simultaneamente, e o estágio 2 começa a processar as linhas assim que elas são processadas pelo estágio 1.
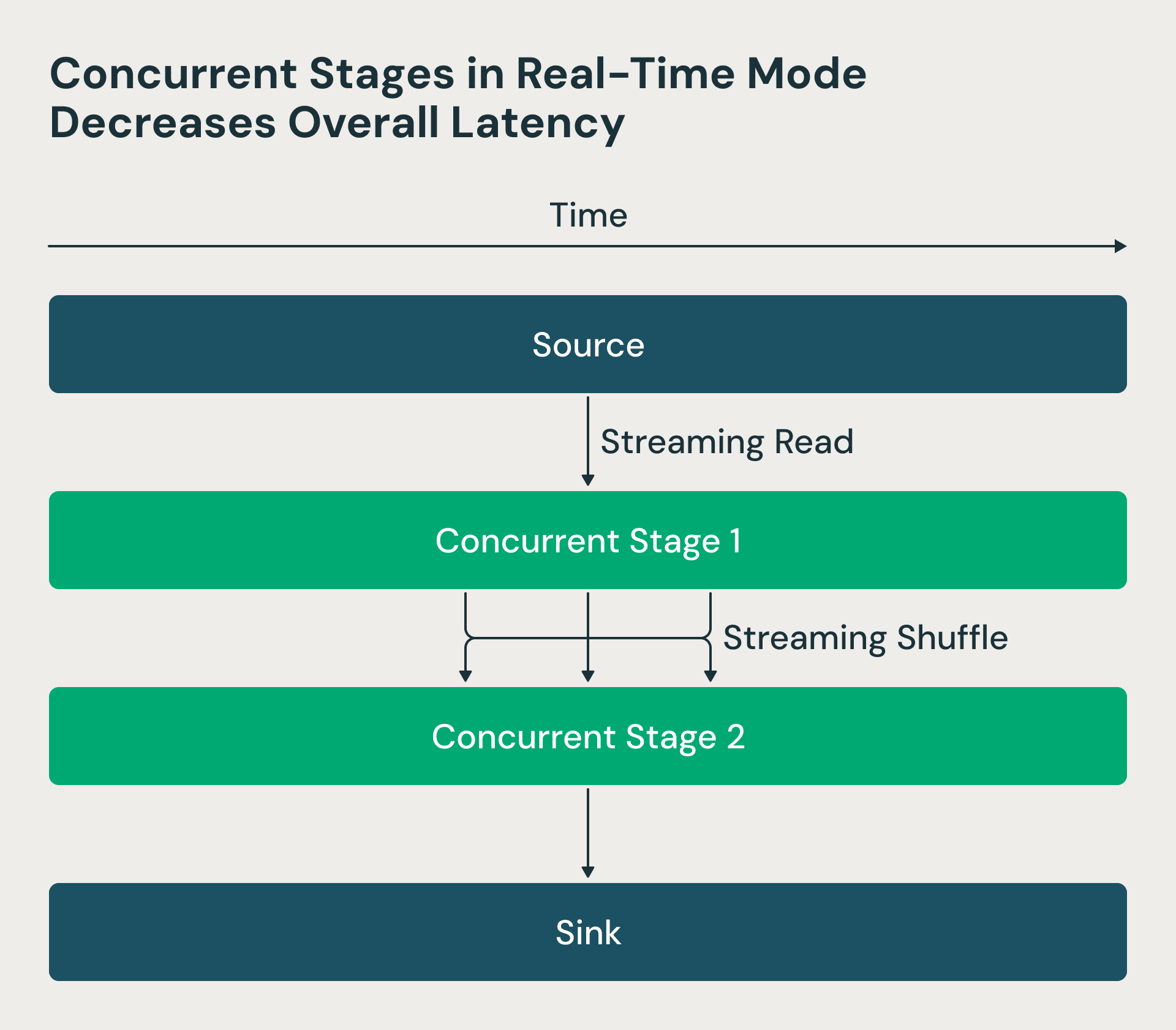
O modo de tempo real usa estágios concorrentes, o que diminui a latência
3. Operadores sem bloqueio
Reestruturamos operadores-key como o shuffle, que foram projetados para execução em lotes com bufferização substancial. No modo em lote, uma agregação group-by armazenaria em buffer todos os registros, realizaria a pré-agregação e emitiria os resultados somente no final. Para o processamento em tempo real, modificamos esses operadores para minimizar a bufferização e produzir resultados continuamente, permitindo que os dados fluam pelo pipeline sem esperas desnecessárias.
Resumo
Ao usar épocas de maior duração com fluxo de dados contínuo, estágios de processamento concorrentes e operadores sem bloqueio, generalizamos o mecanismo do Apache Spark Structured Streaming para lidar com casos de uso de transmissão tanto de alta vazão quanto de latência ultrabaixa. Essa abordagem híbrida agora elimina a necessidade de escolher entre mecanismos de transmissão. Os usuários só precisam aprender o Apache Spark e não há necessidade de aprender outro framework dedicado para transmissão de latência ultrabaixa.
O modo em tempo real já está em produção na Databricks e é usado por vários clientes, de empresas financeiras de ponta a sites de viagens. Nossos clientes conseguem atingir latência de milissegundos para seus casos de uso.
Embora este seja um salto importante nas capacidades do Spark, continuamos a adicionar novos recursos de transmissão. Se sua organização está procurando soluções para cargas de trabalho em tempo real, experimente o Apache Spark Structured Streaming!
Explore os recursos técnicos
Para se aprofundar na engenharia por trás do RTM, assista a esta sessão sob demanda conduzida por nossos especialistas no assunto. Eles apresentarão o design e a implementação do Mode de tempo real.
Ou consulte o guia técnico do Mode em tempo real para saber como começar. Você encontrará tudo o que precisa para habilitar o processamento em tempo real para suas cargas de trabalho de transmissão.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.