Mode Tempo Real: transmissão de latência ultrabaixa nas Spark APIs sem um segundo mecanismo
Processe dados de transmissão em milissegundos no Apache Spark, sem nenhuma das sobrecargas do Apache Flink
por Navneeth Nair, Jerry Peng e Abhay Bothra
- Unificação: Saiba como o Modo em Tempo Real (RTM) no Apache Spark unifica o treinamento offline e a engenharia de recursos online de latência ultrabaixa em um único mecanismo de alto desempenho.
- Desempenho: descubra a rearquitetura que permite uma latência ultrabaixa no Spark, com uma análise de desempenho comparando o Apache Spark RTM com o Apache Flink.
- Simplicidade & Adoção: o RTM oferece muitas vantagens operacionais, incluindo migração simplificada, uma API unificada para evitar o "desvio de lógica" e casos de uso de clientes do mundo real.
O Apache Spark Structured Streaming há muito tempo alimenta pipelines de dados de missão crítica em grande escala, desde ETL de transmissão até analítica e machine learning. Mas, à medida que os casos de uso operacionais evoluíram, as equipes começaram a exigir algo mais: latências de subsegundos para aplicações como detecção de fraude, personalização, detecção de anomalias, alertas e relatórios em tempo real.
Historicamente, atender a esses requisitos de latência ultrabaixa significava introduzir sistemas especializados juntamente com o Spark. Com a introdução do Modo tempo real no Spark Structured Streaming, essa compensação não é mais necessária. Neste blog, exploramos como o Spark simplifica a arquitetura de transmissão em tempo real para casos de uso comuns, como engenharia de atributos, elimina a complexidade operacional de longa data e oferece desempenho líder do setor.
A transmissão em tempo real não exige mais a execução de vários sistemas distintos
A capacidade de processar e agir com base nos dados em tempo real agora é um requisito fundamental. As aplicações modernas, especialmente os agentes de AI, dependem de uma transmissão contínua de contexto atualizado para funcionar. Se os dados subjacentes estiverem incompletos ou atrasados, a experiência do usuário será prejudicada. O desempenho em tempo real não é necessário apenas para casos de uso tradicionais, como detecção de fraudes, mas para toda interação comum em que um usuário espera respostas precisas e atualizadas. Nesse ambiente, a latência impacta diretamente a receita, a confiança do cliente e a vantagem competitiva.
As equipes de dados que criam aplicações de streaming em tempo real historicamente precisaram gerenciar dois stacks de processamento de dados distintos: o Apache Spark™ para analítica em grande escala e sistemas especializados como o Apache Flink® ou o Kafka Streams para aplicações sensíveis à latência de subsegundos. Essa fragmentação exige que as equipes mantenham bases de código duplicadas, gerenciem modelos de governança separados e contratem talentos especializados para ajustar e manter a infraestrutura específica do mecanismo.
Lançado em pré-visualização pública em agosto de 2025, o Modo em Tempo Real (RTM) para Apache Spark Structured Streaming foi projetado para eliminar esse atrito. Ao evoluir fundamentalmente o mecanismo de execução do Spark, removemos a necessidade de um segundo sistema. Essa mudança permite que os engenheiros abordem todo o espectro de casos de uso — de ETL de alta throughput a aplicativos em tempo real de baixa latência — usando a mesma API do Spark que já conhecem. Isso significa menos tempo gerenciando a infraestrutura e mais tempo para focar no caso de uso de negócios.
O Spark agora pode processar eventos em milissegundos; até 92% mais rápido que o Flink
O Mode Tempo Real (RTM) introduziu um novo mecanismo de execução otimizado que permite ao Spark oferecer latências consistentes abaixo de um segundo. Para avaliar o desempenho, realizamos uma comparação lado a lado entre o Spark RTM e o Apache Flink. Os testes foram baseados em cargas de trabalho de computação de recursos em tempo real que normalmente vemos em produção. Esses padrões de computação de recursos são representativos da maioria dos casos de uso de ETL de baixa latência, como detecção de fraudes, personalização e analítica operacional.
Avaliamos três padrões de recurso comuns:
- Codificação de recursos (transformação stateless): Truncando linhas de entrada e codificando
- Enriquecimento de recursos (via join): junção de uma transmissão com uma tabela estática
- Cálculo de recursos (via agregação): agregação GroupBy + Count
Os resultados demonstram que a arquitetura evoluída do Spark oferece um perfil de latência comparável ao de frameworks de transmissão especializados.
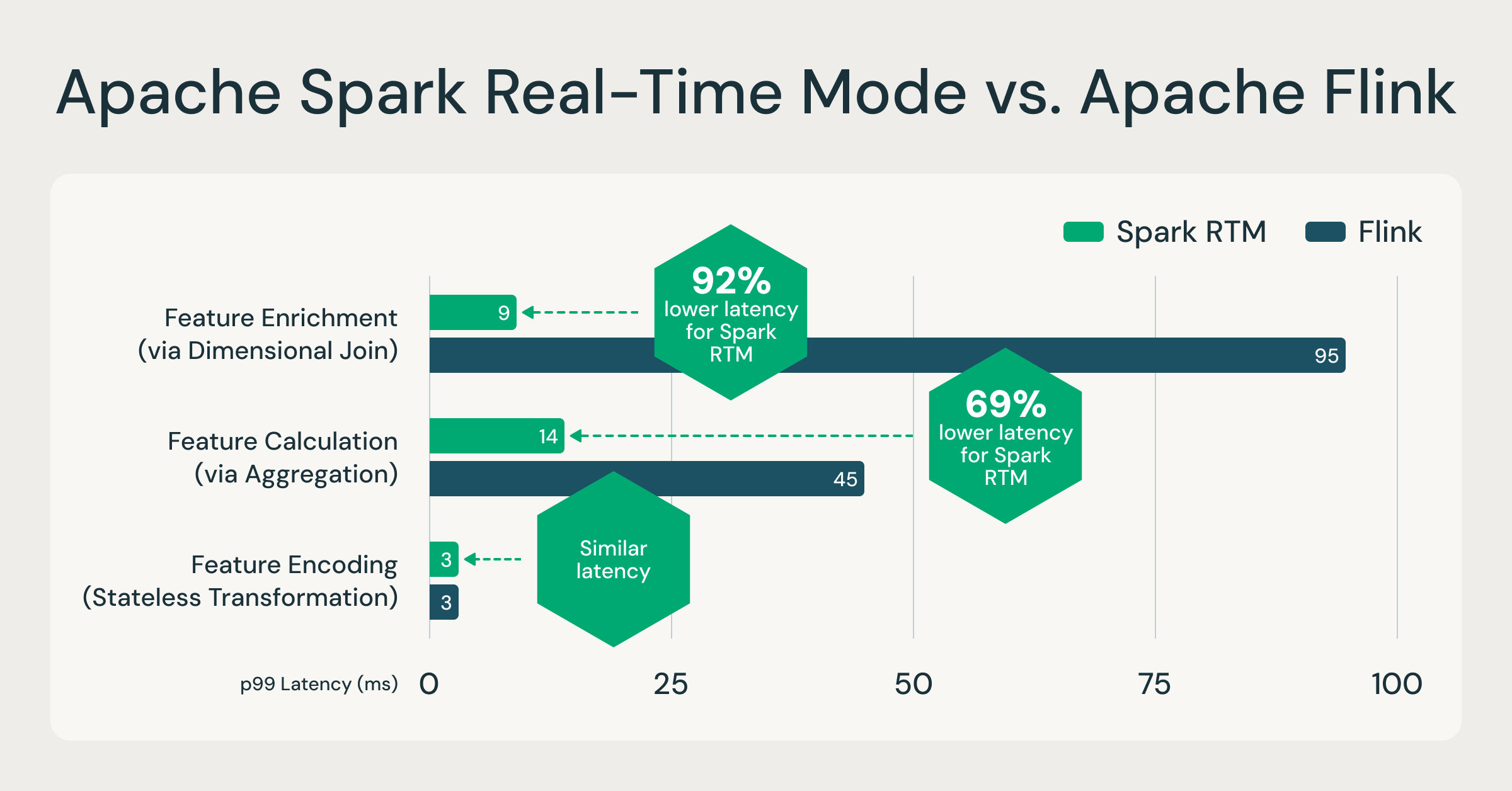
Esse desempenho é possibilitado por três inovações técnicas key no RTM:
- Fluxo de dados contínuo: os dados são processados à medida que chegam, em vez de em blocos periódicos e discretizados.
- Agendamento de pipeline: os estágios são executados simultaneamente sem bloqueio, permitindo que as tarefas subsequentes processem os dados imediatamente, sem esperar que os estágios anteriores terminem.
- Transmissão shuffle: os dados são passados entre as tarefas imediatamente, evitando os gargalos de latência dos shuffles tradicionais baseados em disco.
Juntos, estes transformam o Spark em um mecanismo de alto desempenho e baixa latência, capaz de lidar com os casos de uso operacionais mais exigentes.
As equipes operam com menos infraestrutura e avançam mais rápido com o Spark.
Embora a velocidade bruta seja essencial, o verdadeiro valor do modo em tempo real está em sua capacidade de eliminar a complexidade operacional que normalmente impede a construção de pipelines de latência ultrabaixa. O Spark RTM simplifica significativamente sua arquitetura por meio de três vantagens principais. Para tornar isso concreto, descrevemos essas vantagens no contexto de aplicações de machine learning em tempo real.
Minimize o "logic drift" entre treinamento e inferência: o ML em tempo real, como a detecção de fraudes, requer uma transferência contínua entre o throughput de alta throughput (para treinamento de modelos) e a transmissão de baixa latência (para inferência ao vivo). O Spark é a escolha preferida dos cientistas de dados para o treinamento de modelos, e forçar uma mudança do Spark para o Flink para inferência criaria uma lacuna na lógica de negócios. Você acaba com uma versão da lógica no Spark para treinamento e uma base de código completamente diferente no Flink para produção. Essa replicação da lógica de negócios pode ser propensa a erros e leva ao drift de lógica, em que seu modelo é treinado em uma realidade, mas pontua em outra. Com o Spark RTM, seu código de transformação permanece idêntico, permitindo que você coloque features em produção mais rapidamente e com grande precisão.
Atualização sob demanda com a alteração de uma única linha de código: os requisitos de negócios raramente são estáticos. Um pipeline de features que hoje começa com um SLA de 1 minuto pode exigir latência de subsegundos amanhã, à medida que as necessidades de atualização do modelo evoluem. Por outro lado, para muitos casos de uso, "ir mais devagar" (por exemplo, lotes diários ou de hora em hora) é significativamente mais econômico quando a atualização imediata não é necessária. O Spark oferece espaço para crescer e escalar juntamente com seu produto. Ele permite que você pivote facilmente sua estratégia de engenharia de recursos com uma alteração de código de uma única linha. Por exemplo, você pode definir seu trigger como AvailableNow para executar um pipeline em um agendamento diário ou de hora em hora. Quando as necessidades de negócios mudam, você pode fazer a transição para a transmissão contínua de latência ultrabaixa simplesmente mudando para o modo de tempo real: .trigger(RealTimeTrigger.apply()). Em contraste, realizar isso no Flink é um processo manual. Muitas vezes, é necessário que você ajuste o paralelismo e orquestre o desligamento e a reinicialização dos recursos de compute apenas para corresponder a uma nova frequência de processamento.
Acelere o desenvolvimento: o RTM é construído sobre a mesma API do Spark que sua equipe já conhece. Isso elimina o atrito de manter vários sistemas, permitindo que você avance mais rapidamente ao criar e dimensionar aplicações em tempo real em um ambiente único e consistente.
Os clientes estão executando várias aplicações em tempo real no Spark
Os primeiros usuários estão usando o RTM para potencializar uma gama de aplicações de baixa latência em diversos setores.
Detecção de fraudes: uma plataforma líder de ativos digitais compute recursos de risco dinâmicas, como verificações de velocidade e padrões de gastos agregados a partir de transmissões do Kafka, atualizando seu Feature Store online em menos de 200 milissegundos para bloquear transações fraudulentas no ponto de venda.
Experiências personalizadas: uma plataforma de e-commerce computa recursos de intenção em tempo real com base na sessão atual de um usuário, permitindo que os modelos atualizar as recomendações no momento em que um usuário interage com um produto.
Monitoramento de IoT: uma empresa de transporte e logística ingere telemetria ao vivo para impulsionar a detecção de anomalias, passando da tomada de decisão reativa para a proativa em milissegundos.
O DraftKings, um dos maiores serviços de apostas esportivas e fantasy sports da América do Norte, usa o RTM para potencializar a computação de recursos para seus modelos de detecção de fraudes.
“Em apostas esportivas ao vivo, a detecção de fraudes exige velocidade extrema. A introdução do Tempo Real Mode, juntamente com a API transformWithState no Spark Structured Streaming, foi um divisor de águas para nós. Conseguimos melhorias substanciais tanto na latência quanto no design do pipeline e, pela primeira vez, construímos pipelines de recursos unificados para treinamento de ML e inferência online, alcançando latências ultrabaixas que simplesmente não eram possíveis antes.” —Maria Marinova, Engenheira de Software Líder Sênior, DraftKings
Comece a construir com o Spark Modo de Tempo Real
A era de escolher entre "fácil" e "rápido" acabou. Por que gerenciar dois mecanismos, dois modelos de segurança e dois conjuntos de habilidades especializadas quando um mecanismo agora faz tudo? O RTM oferece a velocidade de subsegundos que suas aplicações em tempo real exigem, com a simplicidade de arquitetura que sua equipe merece. Ao remover o "imposto operacional", você pode finalmente se concentrar na criação de valor em vez de gerenciar a infraestrutura.
Pronto para eliminar a complexidade da sua pilha de tempo real?
- Aprofunde-se nos detalhes: explore a documentação do RTM para entender todas as especificações técnicas, fontes e coletores compatíveis e exemplos de consultas. Você encontrará tudo o que precisa para habilitar o novo trigger e configurar suas cargas de trabalho de transmissão.
- Veja em ação: para se aprofundar na engenharia por trás do RTM, assista a esta sessão de aprofundamento técnico, que detalha o design e a implementação.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.