Breaking the microbatch barrier: The architecture of Apache Spark Real-Time Mode
How we evolved Spark to handle high-throughput ETL and ultra low-latency streaming workloads
by Jerry Peng, Siying Dong and Indrajit Roy
- Apache Structured Streaming's Real-Time Mode unifies high-throughput ETL and millisecond-latency operational workloads in a single engine.
- Dive deep into the hybrid execution model, detailing concurrent processing stages and non-blocking operators that deliver millisecond latencies.
- Customers can now achieve sub-100ms responsiveness for ultra-low latency applications, such as real-time fraud detection.
With the launch of real-time mode (RTM) in Apache Spark 4.1, Structured Streaming now delivers millisecond-level latency. In a recent blog post, we showed how RTM can outperform Flink for many low latency feature engineering workloads (see below).
In this blog, we will discuss the architectural changes that enabled Structured Streaming to support both high-throughput ETL workloads as well as ultra low-latency workloads.
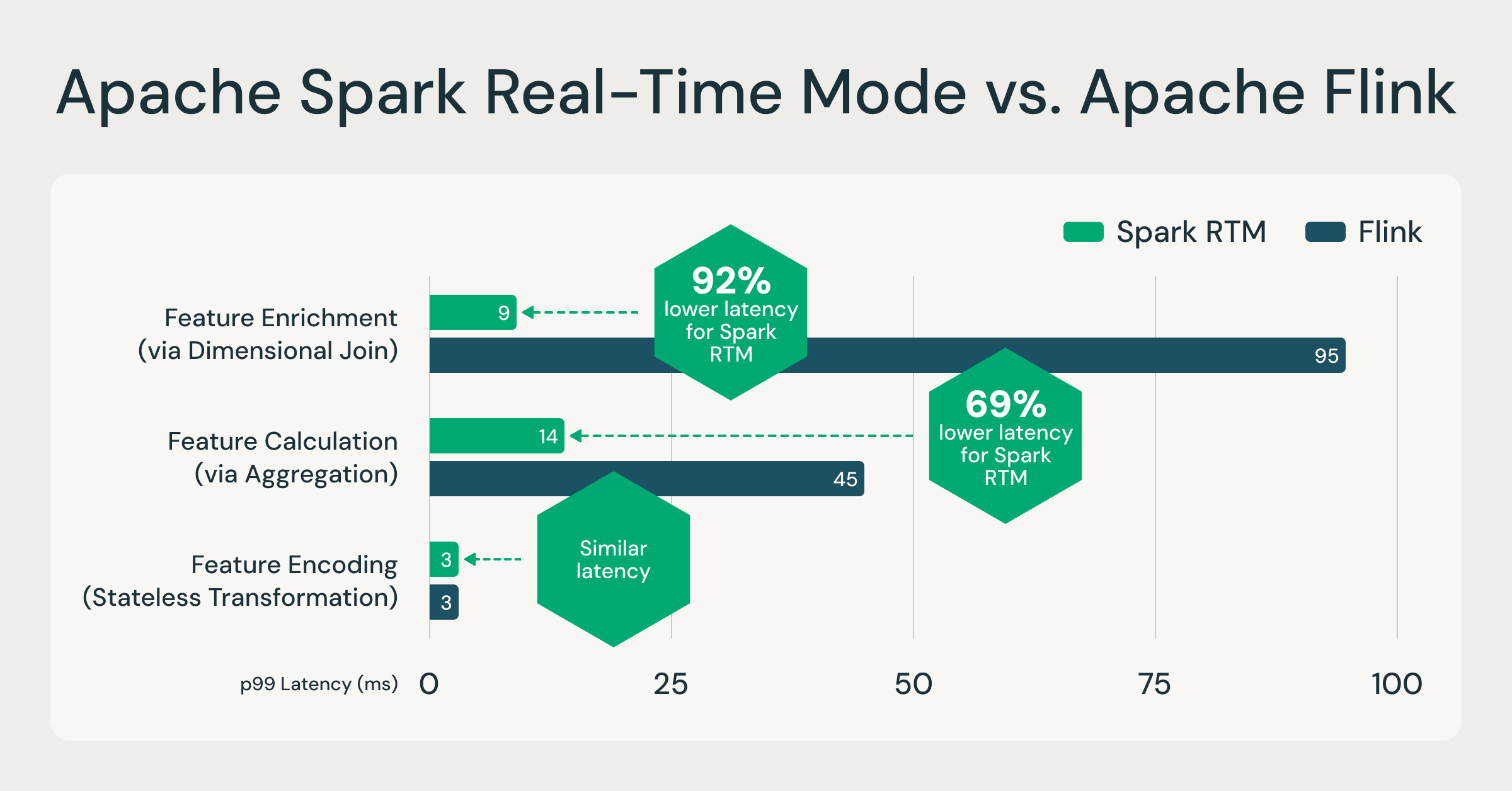
Apache Spark RTM is faster than Flink for feature engineering use cases.
The throughput vs. latency dilemma
Up until now, choosing a streaming engine meant making a trade-off by picking systems like Apache Spark for high throughput ETL workloads, or systems like Apache Flink for low latency workloads. The two systems have very different semantics and performance characteristics. That changes with RTM in Structured Streaming. With the introduction of RTM, Apache Spark can now handle both high throughput and ultra low-latency use cases. This means it’s now possible to pick a single engine with no new learning curve and avoid managing two completely different systems.
Microbatch architecture delivers high throughput
Spark Structured Streaming uses a microbatch architecture: the streaming system receives input data and divides it into discrete batches called epochs based on data availability and maximum batch size configurations. The Spark engine applies the business logic through transformations like project, filter, and aggregation. The results are output as a continuous stream of batches. Structured Streaming excels in high-throughput processing because of this microbatch architecture: since multiple records are processed together, the fixed overheads are amortized and vectorized execution can further improve throughput. These batches are executed in parallel while keeping hardware utilization high. Microbatch mode dynamically allocates task slots across multiple streams which additionally helps with high utilization and throughput. Spark’s foundational innovation of lineage based fault tolerance ensures that these streams are processed with strong exactly-once guarantees.
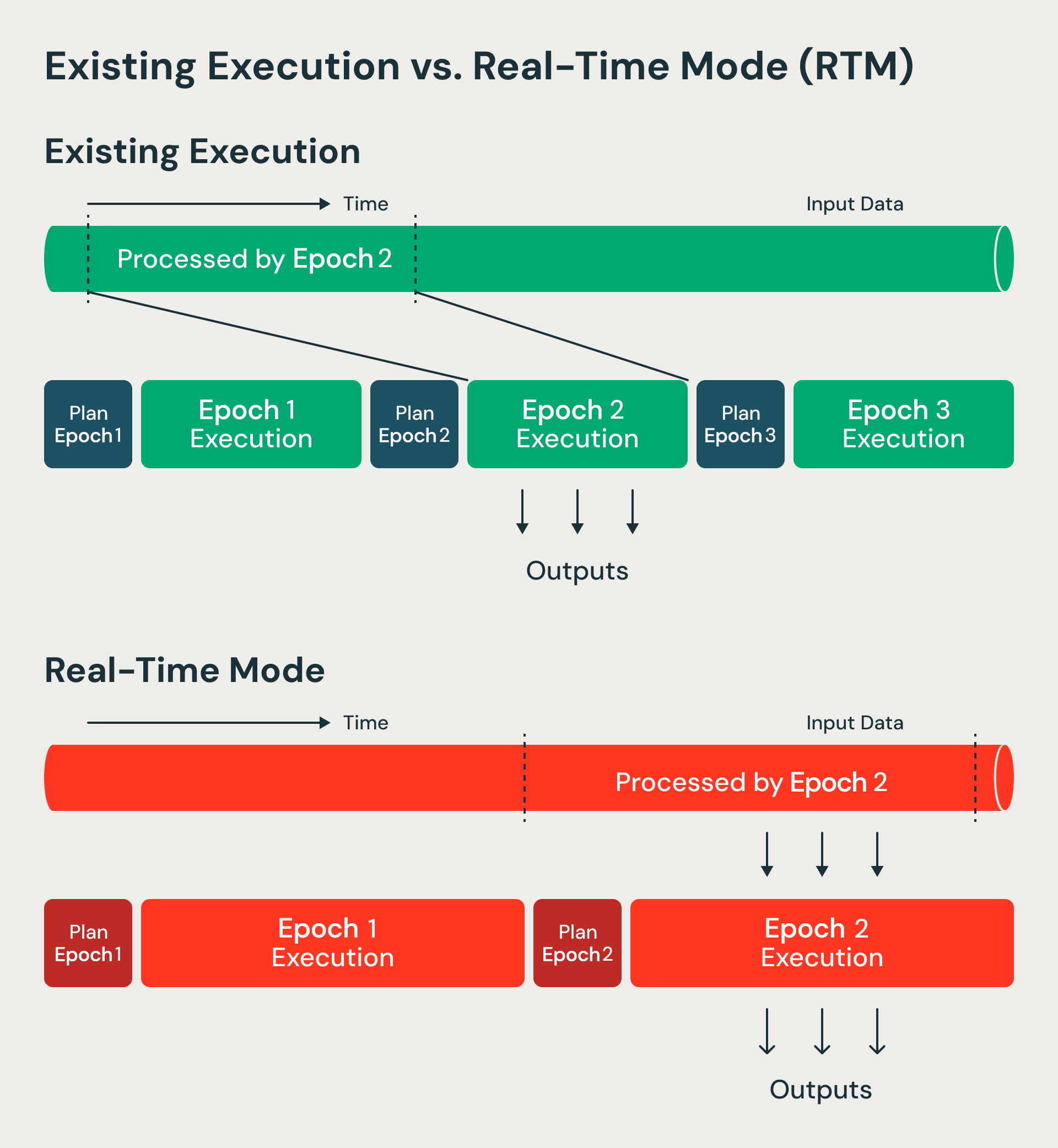
RTM processes data in a non-blocking manner compared to microbatch mode.
Threading the low-latency needle
While Structured Streaming is very good at handling seconds-level ETL and ingestion workloads, many operational use cases demand millisecond-level latency. Fraud detection in financial transactions, real-time insights in the travel industry, or analyzing telemetry data from connected vehicles are all examples where customers need answers in milliseconds.
Architectural challenge: Why smaller batches don't work
The obvious solution might seem simple: just make the batches smaller. If we process one record at a time, we should get real-time performance. Unfortunately, it's not that straightforward.
Each microbatch in Structured Streaming carries fixed costs that dominate execution time when processing small amounts of data. The system writes log files to durable object storage before and after each micro-batch execution. On top of that, state updates for each stateful query needs to be uploaded to object storage at the end of a microbatch as well.These are critical steps for guaranteeing consistency semantics but can add hundreds of milliseconds if not seconds to the execution time. Even if we hide some of these latencies, the latency of planning each batch, logical and physical planning overhead, task serialization, and scheduling are hard to reduce. As you can imagine, shrinking batch sizes quickly hits a wall. The figure below shows when microbatches become too small (leftmost bar), fixed microbatch processing costs dominate execution and increase end to end latency.
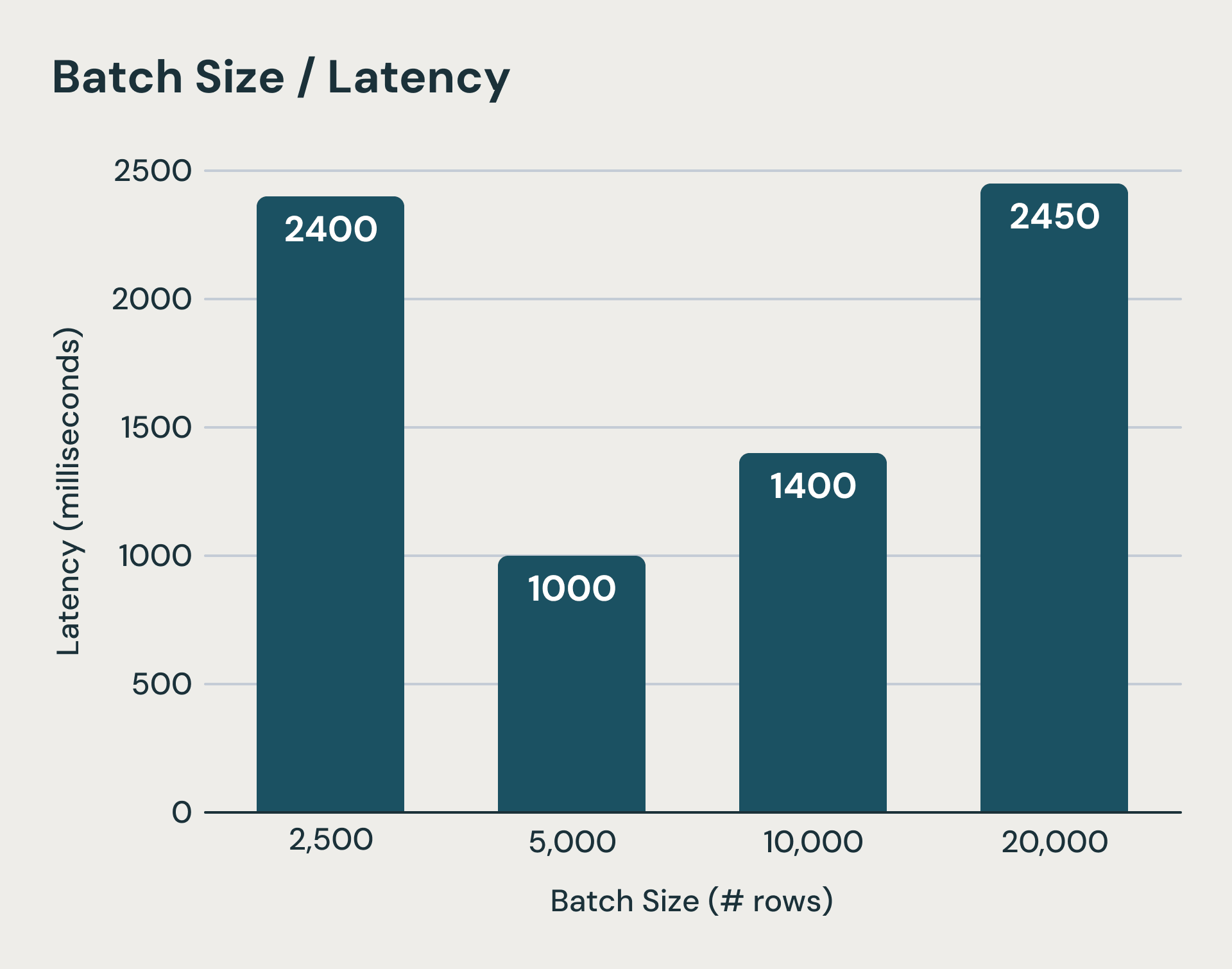
Beyond a threshold, lower batch sizes can increase latency due to fixed overheads
This presented us with an architectural challenge: we want to retain the cost and fault tolerance advantages of the micro-batch architecture while achieving low latency that one expects from models that process record-at-a-time (such as Apache Storm and Apache Flink). Our key insight is that we can evolve the microbatch architecture to support real-time workloads. We continued using many of the core microbatch architecture features such as checkpointing for fault tolerance. However, we eliminated the steps where data used to wait and was resulting in high latency. We discuss these changes below.
Our solution: a hybrid execution model
Here is how we improved Structured Streaming’s latency:
1. Longer duration epochs with continuous data flow
Microbatch mode processes batches of data called epochs. Epoch boundaries are decided upfront using start and end offsets. Real-time mode instead processes longer duration epochs but modifies how data flows within each epoch. Data now streams continuously through different stages and operators without blocking. Since epochs are of longer duration, the overheads of checkpointing and barriers is amortized. At epoch boundaries, we still use barriers for recovery bookkeeping and task rescheduling—maintaining the benefits that make micro-batch architectures resilient and efficient. We essentially evolved the micro-batch in Structured Streaming into a checkpoint interval.
2. Concurrent processing stages
In the Structured Streaming architecture, processing stages executed sequentially—reducers waited for mappers to complete, creating unnecessary delays. We made these stages concurrent in the real-time mode. Now the Spark driver requests source offsets and schedules mappers, but reducers can start processing shuffle files as soon as they become available, rather than waiting for all mappers to finish. This change dramatically reduces end-to-end latency. The RTM figure below shows that the two stages run concurrently, and stage 2 starts processing rows as soon as they are processed by stage 1.
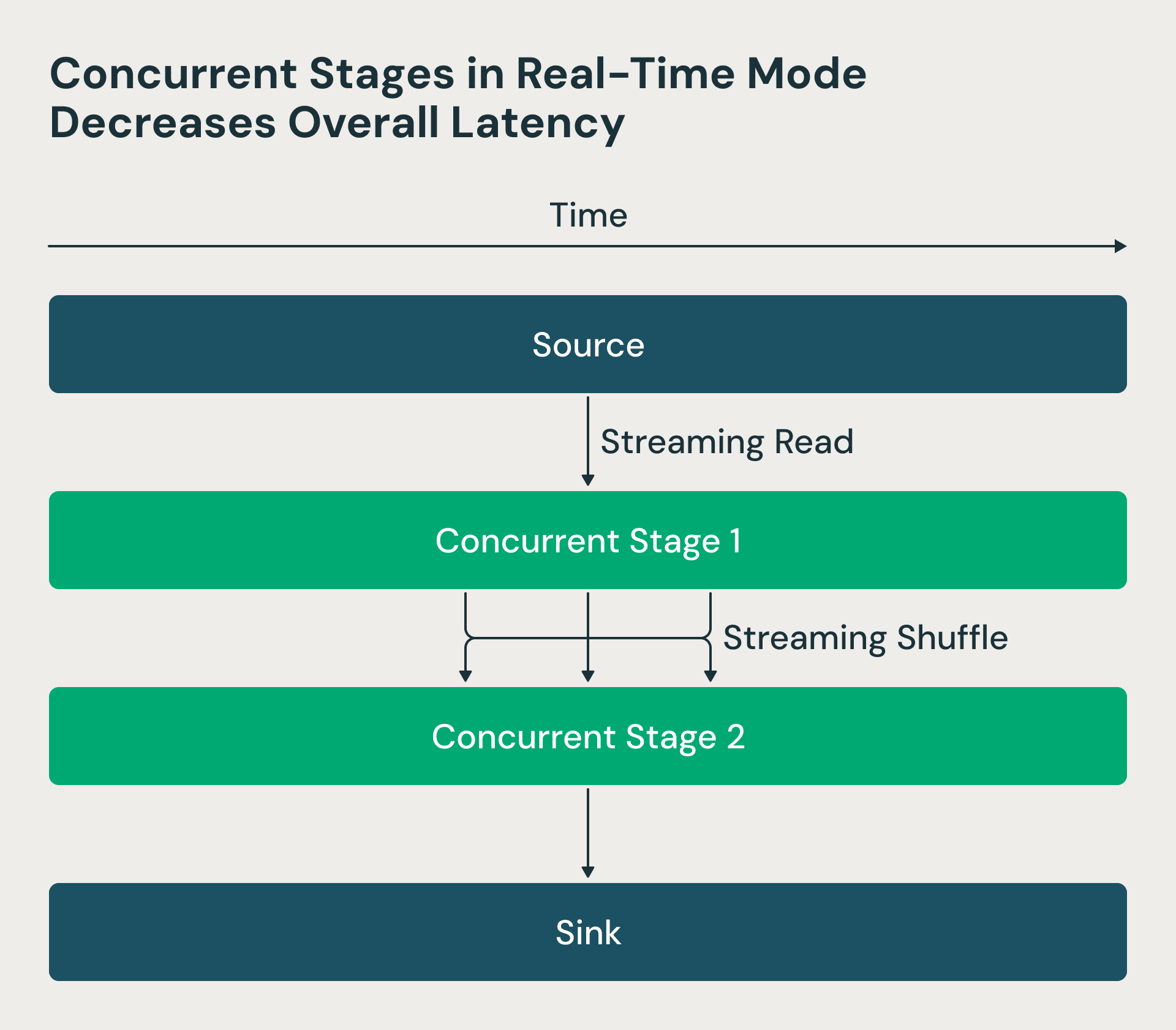
Real-time mode uses concurrent stages which decreases latency
3. Non-blocking operators
We restructured key operators like shuffle, which were designed for batch execution with substantial buffering. In batch mode, a group-by aggregation would buffer all records, perform pre-aggregation, and emit results only at the end. For real-time processing, we modified these operators to minimize buffering and produce results continuously, allowing data to flow through the pipeline without unnecessary waits.
Summary
By using longer duration epochs with continuous data flow, concurrent processing stages, and non-blocking operators, we have generalized Apache Spark Structured Streaming engine to handle both high throughput and ultra low-latency streaming use cases. This hybrid approach now removes the need to choose between streaming engines. Users only need to learn Apache Spark and there’s no need to learn another framework dedicated for ultra low-latency streaming.
Real-time mode is already in production at Databricks and used by multiple customers from cutting edge finance companies to travel sites. Our customers are able to achieve millisecond latency for their use cases.
While this is an important leap in Spark’s capabilities, we are continuing to add new streaming features. If your organization is looking for solutions for real-time workloads, take Apache Spark Structured Streaming for a spin!
Explore technical resources
To go deeper into the engineering behind RTM, watch this on-demand session led by our subject matter experts. They will walkthrough the design and implementation of Real-Time Mode.
Or review the Real-Time Mode technical guide on how to get started. You’ll find everything you need to enable real-time processing for your streaming workloads.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.