Como a Observabilidade em Lakeflow Ajuda Você a Construir Pipelines de Dados Confiáveis
A suíte de recursos de observabilidade do Lakeflow fornece aos engenheiros de dados as ferramentas para manter com confiança pipelines de dados eficientes, confiáveis e saudáveis em grande escala.
por Theresa Hammer e Joanna Zouhour
- Databricks Lakeflow ajuda você a construir pipelines de dados confiáveis, saudáveis e atualizados com observabilidade integrada
- Os profissionais de dados obtêm acesso rápido a trabalhos críticos e dados de pipeline através de uma única interface de usuário para visibilidade de ponta a ponta
- Lakeflow suporta alertas proativos, análise rápida de causa raiz e solução de problemas
À medida que o volume de dados aumenta, também aumentam os riscos para a sua plataforma de dados: desde pipelines desatualizados a erros ocultos e custos fora de controle. Sem a observabilidade integrada à sua solução de engenharia de dados, você está voando às cegas e correndo o risco de impactar não apenas a saúde e a atualidade de suas pipelines de dados, mas também de perder problemas sérios em seus dados, análises e cargas de trabalho de IA downstream. Com o Lakeflow, a solução unificada e inteligente de engenharia de dados da Databricks, você pode facilmente enfrentar esse desafio com soluções de observabilidade integradas em uma interface intuitiva diretamente em sua plataforma ETL, em cima de sua Inteligência de Dados.
Neste blog, apresentaremos as capacidades de observabilidade do Lakeflow e mostraremos como construir pipelines de dados confiáveis, atualizadas e saudáveis.
Observabilidade é Essencial para Engenharia de Dados
A observabilidade para engenharia de dados é a capacidade de descobrir, monitorar e solucionar problemas em sistemas para garantir que o ETL funcione corretamente e de maneira eficaz. É a chave para manter pipelines de dados saudáveis e confiáveis, revelar insights e fornecer análises downstream confiáveis.
À medida que as organizações gerenciam um número cada vez maior de pipelines críticos para os negócios, monitorar e garantir a confiabilidade de uma plataforma de dados tornou-se vital para um negócio. Para enfrentar esse desafio, mais engenheiros de dados estão reconhecendo e buscando os benefícios da observabilidade. De acordo com a Gartner, 65% dos líderes de dados e análises esperam que a observabilidade de dados se torne uma parte central de sua estratégia de dados dentro de dois anos. Engenheiros de dados que desejam se manter atualizados e encontrar maneiras de melhorar a produtividade, ao mesmo tempo em que conduzem dados estáveis em escala, devem implementar práticas de observabilidade em sua plataforma de engenharia de dados.
Estabelecer a observabilidade certa para sua organização envolve trazer as seguintes capacidades-chave:
- Visibilidade de ponta a ponta em escala: elimine pontos cegos e descubra insights do sistema visualizando e analisando facilmente seus trabalhos e pipelines de dados em um único local
- Monitoramento proativo e detecção precoce de falhas: identificar possíveis problemas assim que surgirem, antes que impactem algo downstream
- Solução de problemas e otimização: corrija problemas para garantir a qualidade de suas saídas e otimize o desempenho do seu sistema para melhorar os custos operacionais
Continue lendo para ver como o Lakeflow suporta tudo isso em uma única experiência.
Visibilidade de ponta a ponta em escala em Jobs e Pipelines
A observabilidade eficaz começa com visibilidade completa. O Lakeflow vem com uma variedade de visualizações prontas e visões unificadas para ajudá-lo a ficar por dentro de seus pipelines de dados e garantir que todo o processo de ETL esteja funcionando sem problemas.
Menos pontos cegos com uma visão centralizada e granular de seus jobs e pipelines
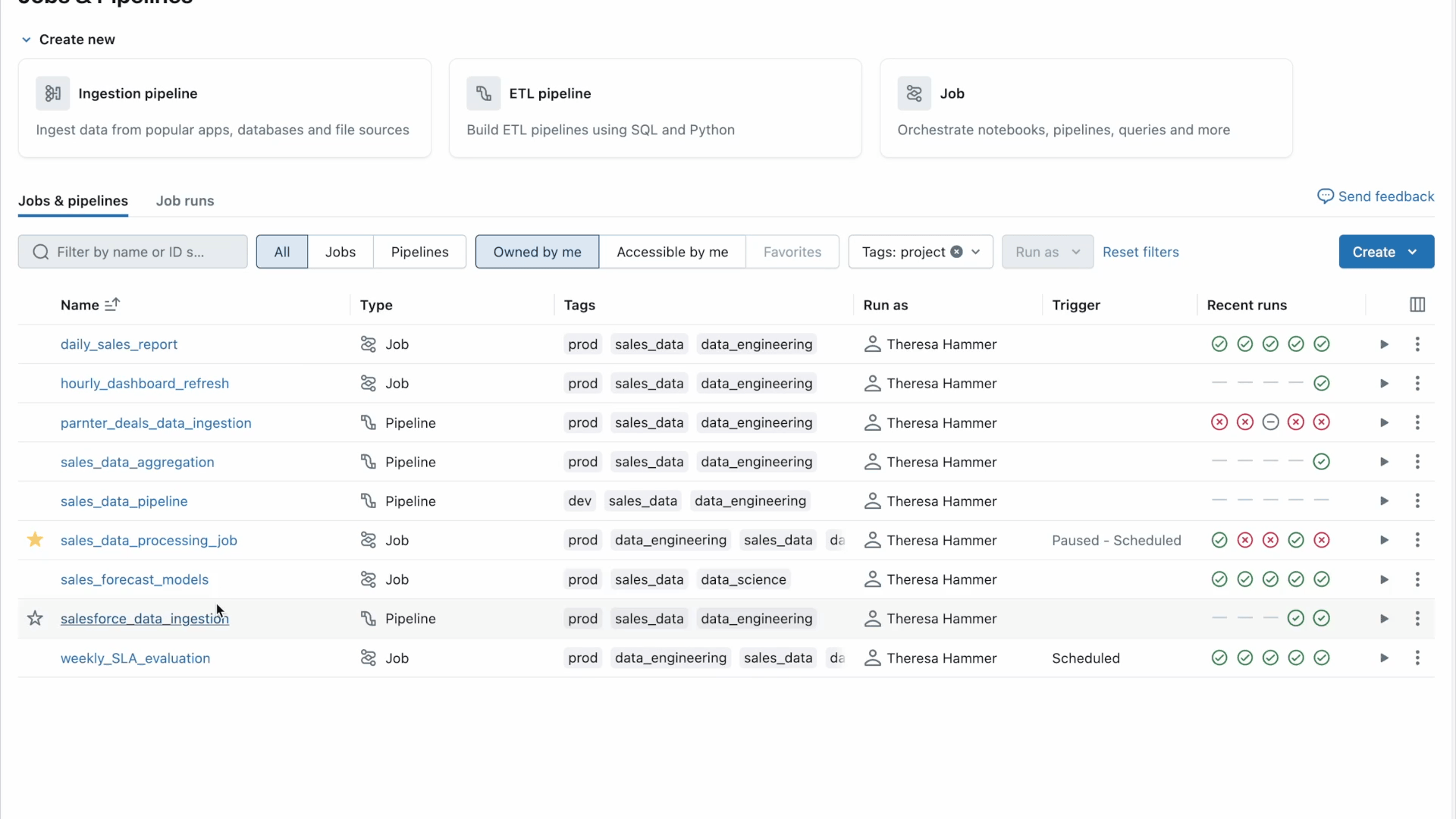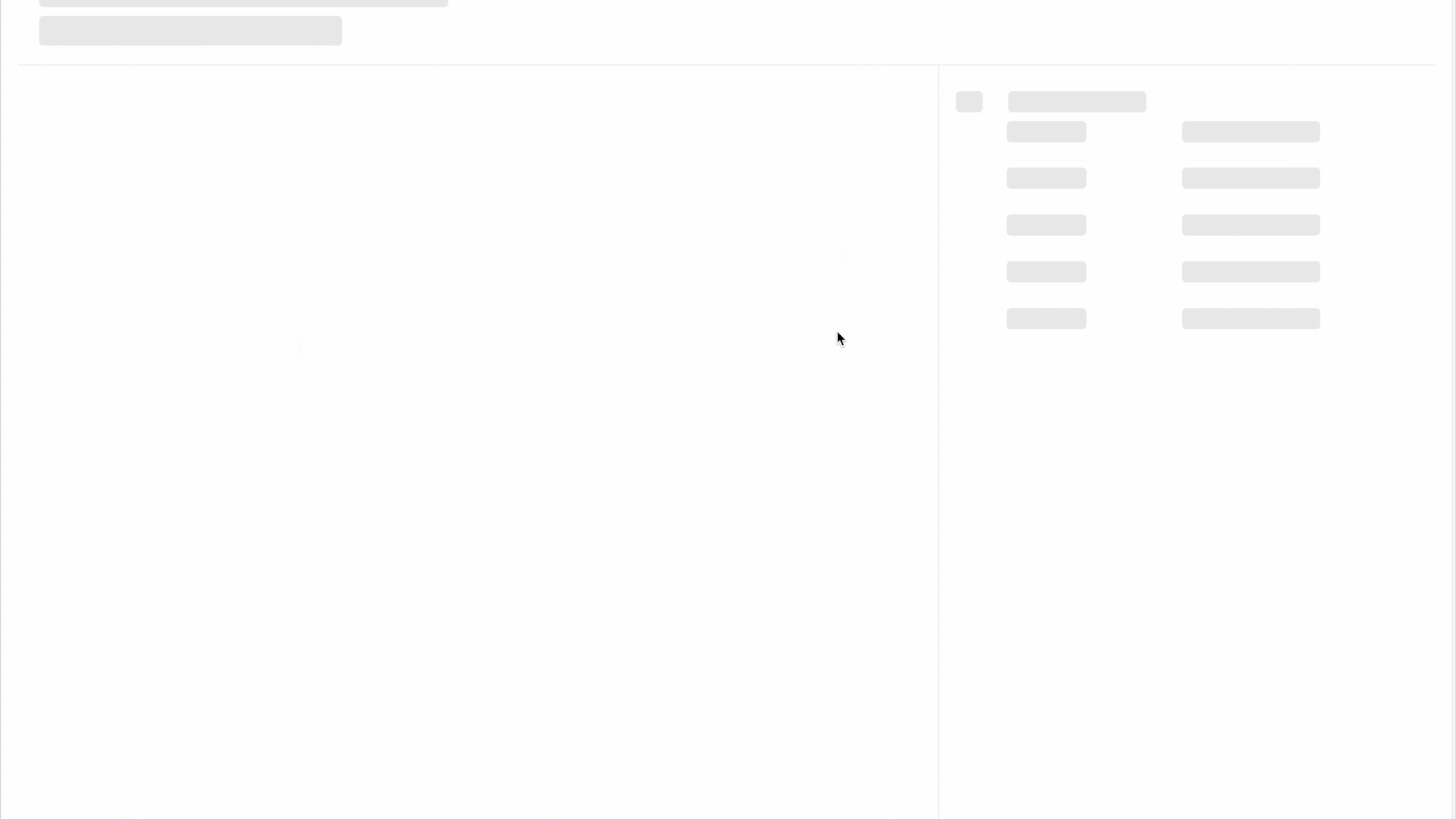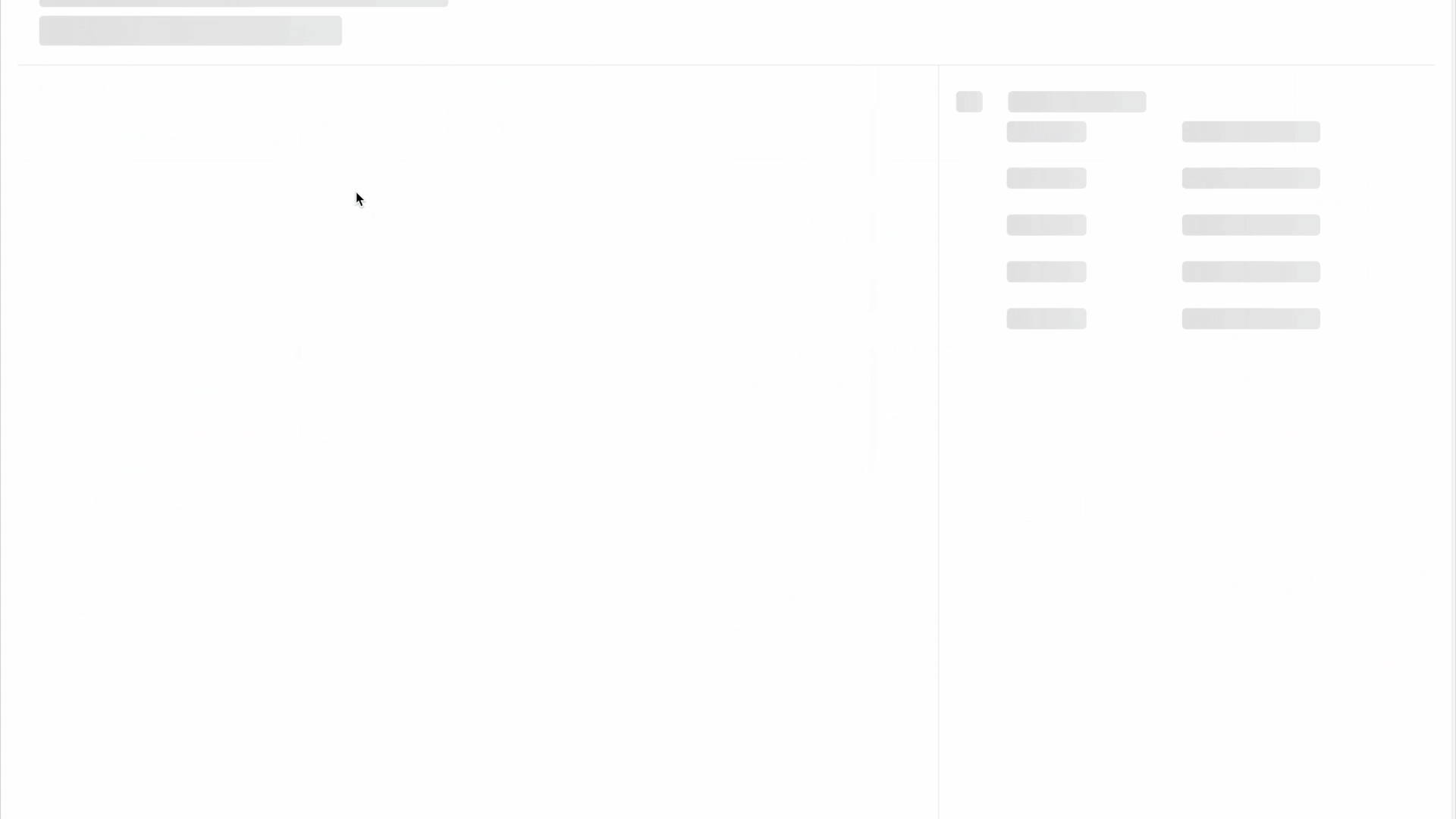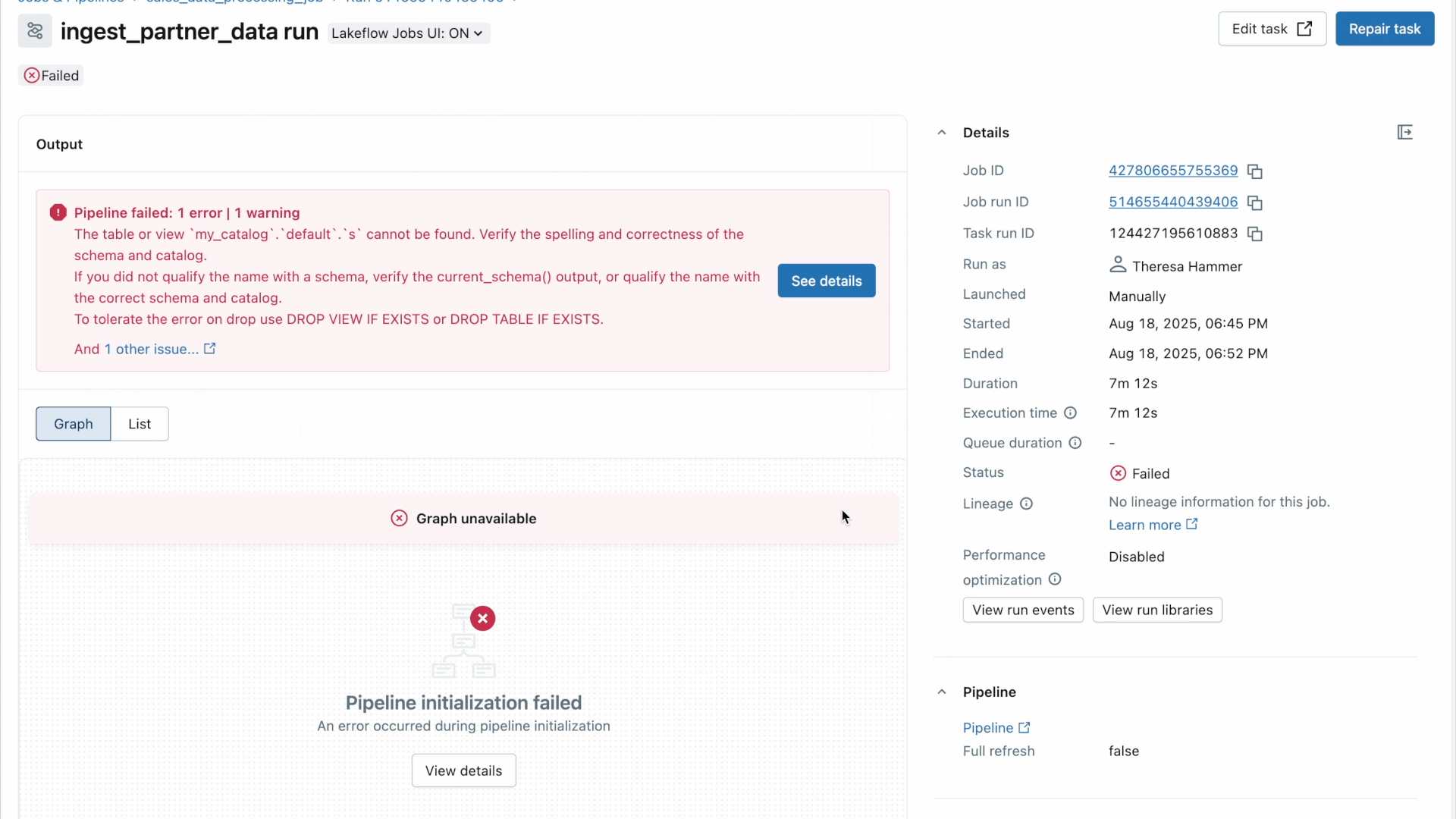
A página de Trabalhos e Pipelines centraliza o acesso a todos os seus trabalhos, pipelines e seu histórico de execução em todo o espaço de trabalho. Esta visão unificada de suas execuções simplifica a descoberta e o gerenciamento de seus pipelines de dados e facilita a visualização de execuções e o acompanhamento de tendências para um monitoramento mais proativo.
Procurando mais informações sobre seus Jobs? Basta clicar em qualquer job para ir a uma página dedicada que apresenta uma Visão em Matriz e destaca detalhes importantes como status, duração, tendências, avisos e mais. Você pode:
- facilmente aprofunde-se em uma execução específica de Job para obter insights adicionais, como a visualização do gráfico para visualizar dependências ou ponto de falha
- aproxime para ver o nível da tarefa (como pipeline, saída do notebook, etc.) para mais detalhes, como métricas de streaming (disponível em Visualização Pública).
O Lakeflow também oferece uma página dedicada à execução de Pipeline onde você pode facilmente monitorar o status, as métricas e acompanhar o progresso da execução do seu pipeline em tabelas.
Mais insights com visualização de seus dados em escala
Além dessas visões unificadas, o Lakeflow fornece observabilidade histórica para suas cargas de trabalho para obter insights sobre seu uso e tendências. Usando Tabelas de Sistema, tabelas gerenciadas pelo Databricks que rastreiam e consolidam cada job e pipeline criado em todos os espaços de trabalho em uma região, você pode construir painéis detalhados e relatórios para visualizar seus jobs e pipelines de dados em escala. Com o recentemente atualizado interativo modelo de painel para Tabelas de Sistema do Lakeflow, ficou muito mais fácil e rápido para:
- rastrear tendências de execução: facilmente trazer à tona insights sobre o comportamento do job ao longo do tempo para melhores decisões baseadas em dados
- identificar gargalos: detectar possíveis problemas de desempenho (abordados em mais detalhes na seção seguinte)
- referência cruzada com a faturação: melhore o monitoramento de custos e evite surpresas na fatura
Tabelas de Sistema para Jobs e Pipelines estão atualmente em Visualização Pública.

A visibilidade vai além do nível de tarefa ou trabalho. A integração do Lakeflow com o Unity Catalog, a solução unificada de governança do Databricks, ajuda a completar o quadro com uma visualização de toda a sua linhagem de dados. Isso facilita o rastreamento do fluxo de dados e das dependências e permite obter o contexto completo e o impacto de seus pipelines e trabalhos em um único lugar.

Monitoramento Proativo, Detecção Antecipada de Falhas de Trabalho, Solução de Problemas e Otimização
Como engenheiros de dados, vocês não são apenas responsáveis por monitorar seus sistemas. Vocês também precisam ser proativos sobre quaisquer problemas ou lacunas de desempenho que possam surgir em seu desenvolvimento de ETL e abordá-los antes que eles impactem seus resultados e custos.
Alerta Proativo Para Capturar Coisas Cedo
Com as notificações nativas do Lakeflow notificações, você pode escolher se e como ser alertado sobre erros críticos de job, durações ou atrasos via Slack, email ou até mesmo PagerDuty. Ganchos de evento em Pipelines Declarativos do Lakeflow (atualmente em Visualização Pública) oferecem ainda mais flexibilidade ao definir funções de retorno de chamada Python personalizadas para que você decida o que monitorar ou quando ser alertado sobre eventos específicos.
Análise de Causa Raiz Mais Rápida para Remediação Rápida
Uma vez que você recebe o alerta, o próximo passo é entender por que algo deu errado.
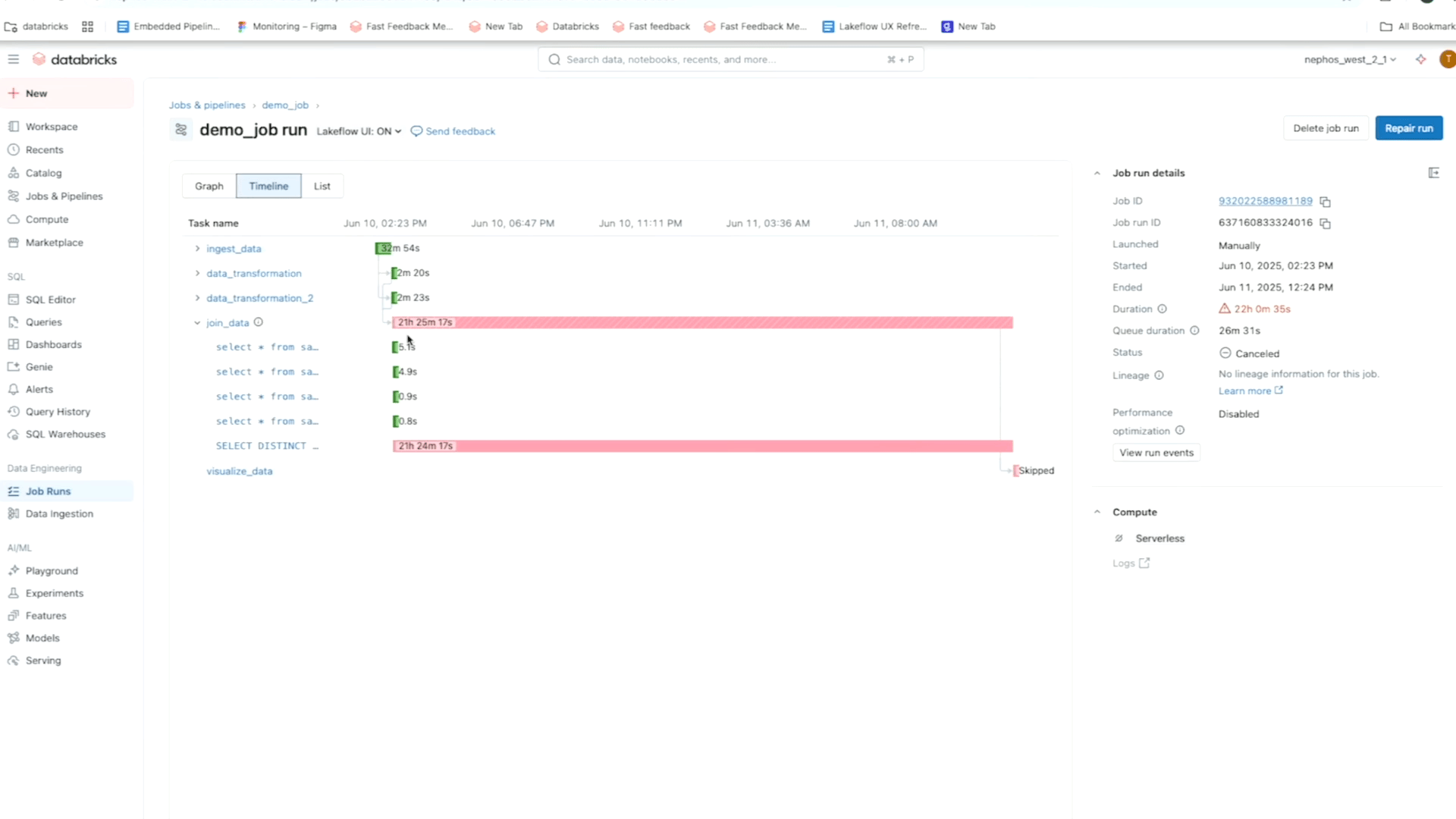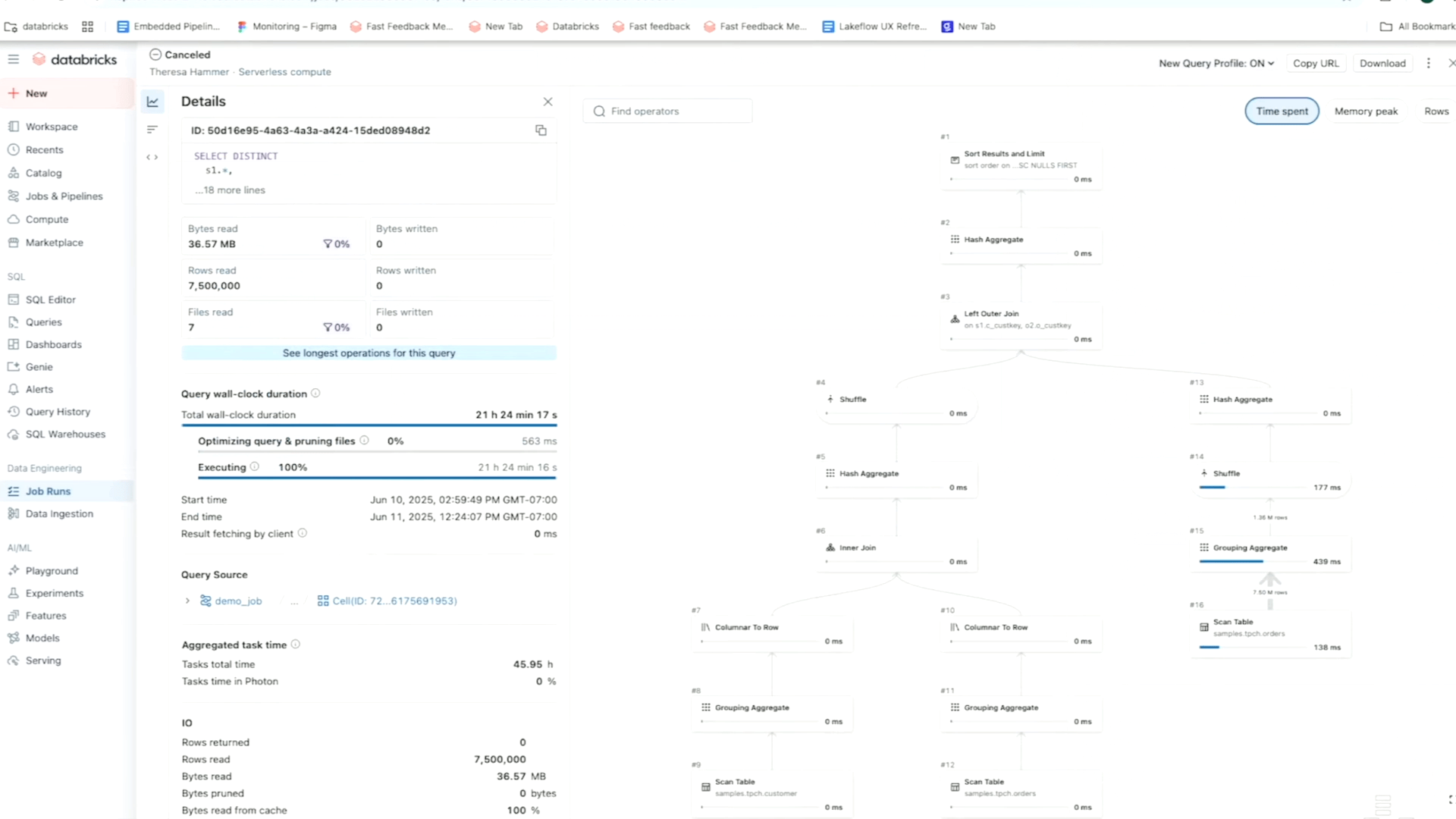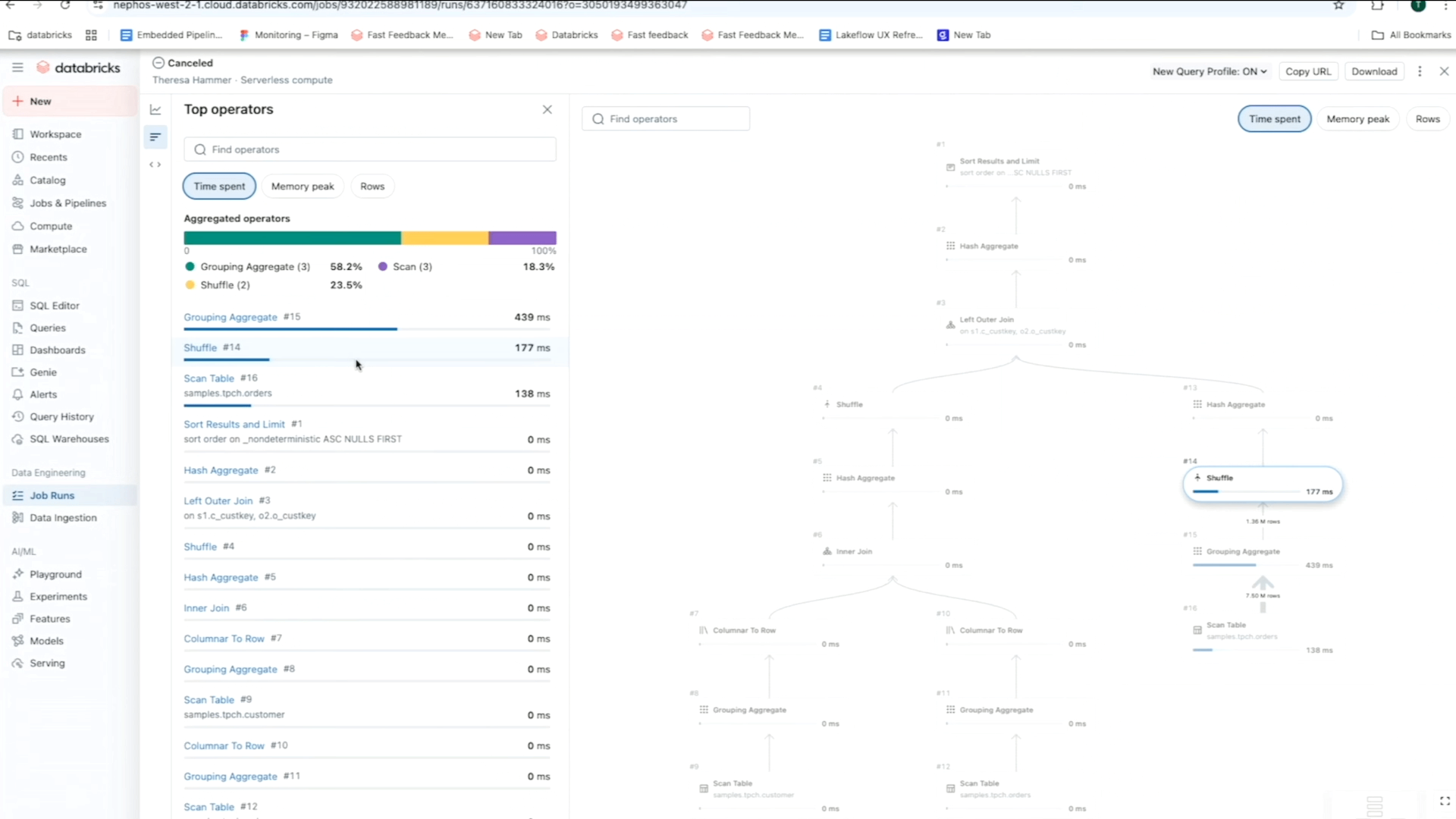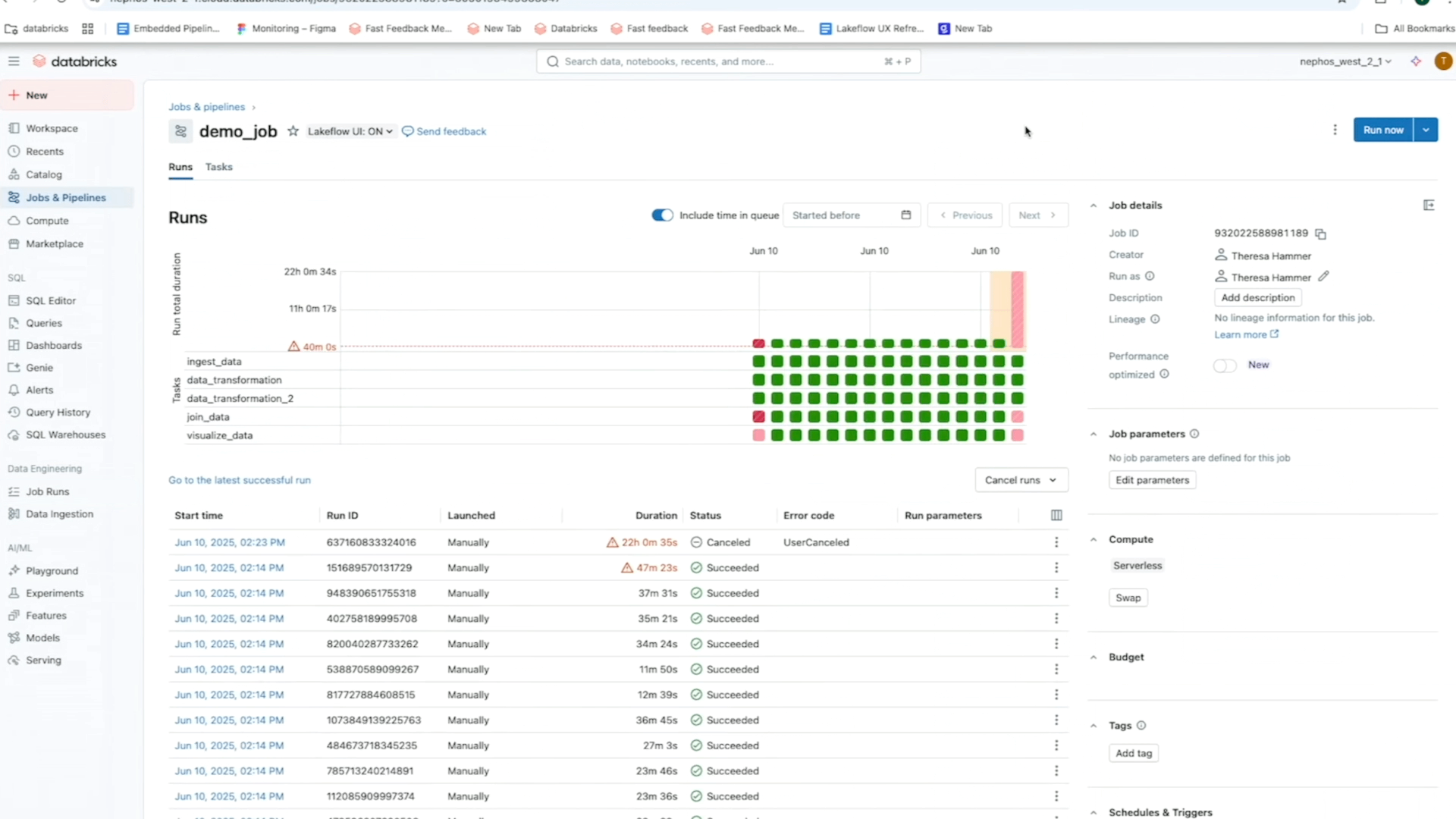
Lakeflow permite que você pule da notificação diretamente para a visualização detalhada de uma falha específica de job ou tarefa para análise de causa raiz no contexto. O nível de detalhe e flexibilidade com que você pode ver seus dados de fluxo de trabalho permite que você identifique facilmente o que exatamente é responsável pelo erro.
Por exemplo, usando a visualização em matriz de um trabalho, você pode acompanhar padrões de falha e desempenho em tarefas para um fluxo de trabalho específico. Enquanto isso, a linha do tempo (Gantt) divide a duração de cada tarefa e consulta (para trabalhos sem servidor) para que você possa identificar problemas de desempenho lento em um trabalho e investigar mais a fundo as causas raiz usando Perfis de Consulta. Como lembrete, os Perfis de Consulta da Databricks fornecem uma visão geral rápida do seu SQL, Python e execuções de Pipeline Declarativo, facilitando a identificação de gargalos e a otimização de cargas de trabalho em sua plataforma ETL.
Você também pode contar com as Tabelas de Sistema para facilitar a análise de causa raiz, construindo painéis que destacam irregularidades em seus trabalhos e suas dependências. Esses painéis ajudam você a identificar rapidamente não apenas falhas, mas também lacunas de desempenho ou oportunidades de melhoria de latência, como latência P50/P90/P99 e métricas de cluster. Para complementar sua análise, você pode aproveitar os dados de linhagem e as tabelas de sistema de histórico de consultas, para que possa rastrear facilmente erros upstream e impactos downstream através da linhagem de dados.
Depuração e Otimização para Pipelines Confiáveis
Além da análise de causa raiz, o Lakeflow oferece ferramentas para solução rápida de problemas, seja um problema de recurso de cluster ou um erro de configuração. Depois de resolver o problema, você pode executar as tarefas que falharam e suas dependências sem ter que executar o job inteiro novamente, economizando recursos computacionais. Enfrentando casos de uso de solução de problemas mais complexos? Assistente Databricks, nosso assistente alimentado por IA (atualmente em Visualização Pública), fornece insights claros e ajuda a diagnosticar erros em seus jobs e pipelines.

Atualmente estamos desenvolvendo capacidades adicionais de observabilidade para ajudá-lo a monitorar melhor seus pipelines de dados. Em breve, você também poderá visualizar as métricas de saúde de seus fluxos de trabalho e pipelines e entender melhor o comportamento de suas cargas de trabalho com indicadores e sinais emitidos por Jobs e Pipelines.
Resumo das Capacidades de Observabilidade do Lakeflow
| Pilares-chave da Observabilidade | Capacidades do Lakeflow |
|---|---|
| Visibilidade de ponta a ponta em escala |
|
| Monitoramento Proativo e Detecção Precoce de Falhas |
|
| Solução de Problemas e Otimização de Desempenho |
Comece a Construir Engenharia de Dados Confiável com Lakeflow
Lakeflow oferece o suporte de que você precisa para garantir que seus jobs e pipelines funcionem sem problemas, estejam saudáveis e operem de forma confiável em escala. Experimente nossas soluções de observabilidade integradas e veja como você pode construir uma plataforma de engenharia de dados pronta para seus esforços de inteligência de dados e necessidades de negócios.
- Saiba mais sobre a Observabilidade do Lakeflow
- Assista à sessão de Observabilidade do Lakeflow do nosso Data+AI summit sob demanda
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.