Como Superhuman e Databricks criaram juntas uma plataforma de inferência com 200 mil QPS
Engenheiros da Superhuman e Databricks compartilham como migraram conjuntamente cargas de trabalho de correção ortográfica e gramatical para a Plataforma de Serving de Modelos da Databricks, servindo mais de 200k QPS, com ganhos de throughput de 60% e...
por Christoph Stüber, Wai Wu, Arjun DCunha, Amine El Helou, Tian Ouyang e Alex Coleman
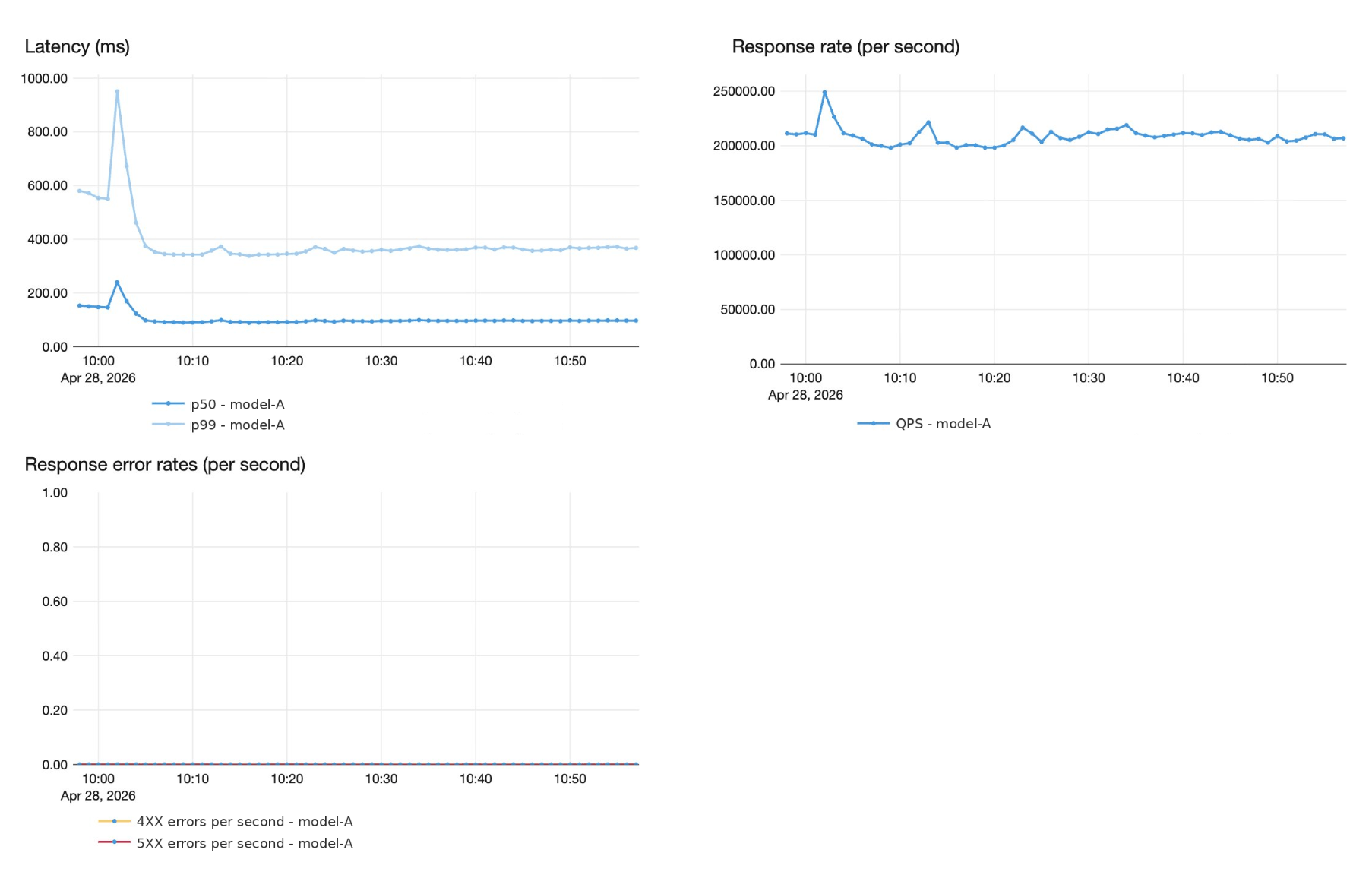
- A Superhuman migrou de uma pilha vLLM DIY para o Throughput Provisionado da FMAPI da Databricks, agora servindo um LLM customizado a mais de 200K QPS com latência P99 abaixo de um segundo. Isso permitiu que a equipe de engenharia da Superhuman se concentrasse na construção e melhoria de seu produto, enquanto delegava à Plataforma Databricks o gerenciamento da escala e infraestrutura.
- Otimizações conjuntas de engenharia entregaram um ganho de throughput de 60% por GPU (750 → 1.200 QPS por pod H100) e reduziram os custos de serving através de quantização FP8, eliminando sobrecarga do lado da CPU e otimizando kernels de atenção na arquitetura Hopper, tudo alcançado sem regressões de qualidade.
- A FMAPI da Databricks escala de forma confiável para mais de 250 GPUs através de balanceamento de carga de nível de produção, autoescalonamento e inicialização rápida de contêineres; com testes de estresse de ramp-up pré-produção garantindo que as metas de disponibilidade e latência p99 sejam atendidas antes que o tráfego atinja a produção.
De parceiros de análise a parceiros de inferência em tempo real
Superhuman, a plataforma de produtividade que inclui Superhuman, Coda, Superhuman Mail e Superhuman Go, atende a mais de 40 milhões de usuários diários em dezenas de idiomas. A assistência de comunicação por IA da Superhuman fornece sugestões em tempo real para correção, clareza, tom e estilo em todas as superfícies onde as pessoas escrevem.
Databricks e Superhuman são parceiros há anos. A equipe da Superhuman historicamente usou a Plataforma de Inteligência de Dados Databricks como base para análise. Mas a análise era apenas metade da história.
Por trás de muitas das sugestões em tempo real da Superhuman está um modelo de IA personalizado altamente sofisticado, servido em grande escala. A Superhuman executa este modelo com tráfego de pico de mais de 200.000 consultas por segundo, com latência de ponta a ponta inferior a 1 segundo em P99 e rigorosas garantias de confiabilidade de 4 noves. A Superhuman modernizou sua pilha de serviço para modelos de linguagem grandes aproveitando o serviço de modelos Databricks, o que exigiu um novo tipo de parceria, construída sobre trabalho conjunto de produto e engenharia.
Como a Superhuman modernizou sua pilha de serviço
Antes desta migração, a Superhuman operava uma pilha de serviço DIY construída sobre vLLM, juntamente com ferramentas internas para treinamento e gerenciamento de modelos. Uma equipe interna de infraestrutura de ML mantinha essa pilha, que suportava uma escala massiva, mas vários pontos problemáticos estavam se acumulando ao servir modelos de linguagem grandes.
O modelo de linguagem grande personalizado potencializa a correção gramatical em um volume enorme, pico de mais de 200 mil QPS com aproximadamente 50 tokens de entrada e 50 tokens de saída por solicitação. Estava empurrando os limites do que a pilha baseada em L40S-gpus poderia entregar. Cada nova iteração do modelo exigia meses de ajuste manual de desempenho para ser integrada. Enquanto isso, o fardo operacional estava crescendo, com planejamento de capacidade, ajuste de desempenho e escalonamento automático consumindo tempo de uma equipe enxuta que precisava se concentrar na qualidade do modelo e nas inovações do produto.
A Superhuman precisava de um parceiro de plataforma que pudesse se comprometer com SLAs de desempenho e latência na pilha de serviço, e que co-investisse na engenharia necessária para cumpri-los. Ambas as equipes definiram SLOs de latência em tempo real alvo antecipadamente: latência p99 abaixo de um segundo e nenhuma regressão de qualidade nas ferramentas de avaliação internas da Superhuman.
Cumprindo SLAs em tempo real na Infraestrutura da Plataforma
Atingir metas de latência em um único pod é necessário, mas não suficiente. Servir mais de 200 mil QPS de forma confiável requer infraestrutura que possa balancear carga, escalar dinamicamente e absorver picos. Conseguir isso exigiu colaboração estreita entre as duas equipes.
Otimizando o balanceamento de carga: escolhas de potência de dois
O tráfego do endpoint de correção gramatical da Superhuman exibe fortes padrões diurnos com rampas rápidas em certos períodos, frequentemente excedendo 200 mil QPS. Embora o balanceador de carga round robin padrão do Kubernetes seja suficiente em QPS baixo, nossos testes revelaram que esse desempenho se degrada em QPS mais alto, com distribuição desigual de solicitações criando hotspots que aumentam a latência de cauda.
No centro de nossa abordagem está o Endpoint Discovery Service (EDS) — um plano de controle leve que monitora continuamente a API do Kubernetes para alterações em Services e EndpointSlices. O EDS impulsiona um algoritmo de balanceamento de carga personalizado baseado na potência de duas escolhas (citação). Para cada solicitação, dois pods candidatos são amostrados e o tráfego é roteado para aquele que tem menos solicitações ativas, evitando os hotspots que o round-robin cria em QPS alto (ver blog).
Para manter a plataforma com custo otimizado para padrões de tráfego variáveis, o sistema escala dinamicamente com a demanda do cliente. O escalonador automático rastreia request_concurrency médio entre os pods, com alvos de concorrência por pod derivados de benchmarking do RPS máximo sustentável por réplica. A estratégia de escalonamento é intencionalmente assimétrica: o scale-up é agressivo e responsivo, enquanto o scale-down é conservador, para evitar o flapping que causa picos de latência. Através de testes sombra conjuntos entre Superhuman e Databricks, pegamos casos extremos e corrigimos problemas ao ajustar parâmetros no escalonador automático, incluindo quando escalar agressivamente, quando manter estável e quão conservador ser no scale-down.
Otimizando a inicialização de contêineres via aceleração de imagem
Quando o tráfego do endpoint da Superhuman aumenta de baixo para pico, o escalonador automático precisa adicionar dezenas de pods. Se cada pod levar minutos para baixar sua imagem de contêiner e iniciar, os usuários experimentarão picos de latência durante a rampa. Reduzir o tempo de inicialização do pod se traduz diretamente em escalonamento mais rápido e latência mais suave durante os picos de tráfego.
A equipe de serviço de modelos Databricks adotou o trabalho de aceleração de imagem originalmente construído para computação sem servidor (blog) para evitar cold starts. A abordagem se encaixa bem para os modelos relativamente pequenos que servimos para a Superhuman.
Ao construir uma imagem de contêiner, adicionamos uma etapa extra para converter o formato de imagem padrão baseado em gzip para o formato baseado em dispositivo de bloco adequado para carregamento preguiçoso. Isso permite que a imagem do contêiner seja representada como um dispositivo de bloco buscável com setores de 4 MB em produção.
Ao baixar imagens de contêineres, nosso tempo de execução de contêiner personalizado recupera apenas os metadados necessários para configurar o diretório raiz do contêiner, incluindo estrutura de diretórios, nomes de arquivos e permissões, e cria um dispositivo de bloco virtual de acordo. Em seguida, ele monta o dispositivo de bloco virtual no contêiner para que o aplicativo possa começar a ser executado imediatamente.
Quando o aplicativo lê um arquivo pela primeira vez, a solicitação de E/S contra o dispositivo de bloco virtual emitirá um callback para o processo de busca de imagem, que recupera o conteúdo real do bloco do registro de contêiner remoto. O conteúdo do bloco recuperado também é armazenado em cache localmente para evitar viagens de ida e volta de rede repetidas para o registro de contêiner, reduzindo o impacto da latência de rede variável em leituras futuras.
Este sistema de arquivos de contêiner de carregamento preguiçoso elimina a necessidade de baixar toda a imagem do contêiner antes de iniciar o aplicativo, reduzindo o tempo de inicialização do contêiner de vários minutos para apenas alguns segundos.
Otimizações de tempo de execução: 60% mais taxa de transferência por pod
Com a camada de plataforma lidando com a escala de frota, a próxima questão era quantos QPS cada pod poderia suportar e a que custo.
Nesta seção, apresentamos as otimizações que aumentaram a taxa de transferência por pod de 750 QPS para 1.200 QPS em GPUs H100, uma melhoria de 60%, mantendo zero regressões de qualidade.
Quantização FP8
A quantização FP8 foi a maior melhoria de taxa de transferência, alcançando até 30% de aumento em QPS por pod.
A equipe de ML da Superhuman pré-quantizou o checkpoint para FP8 usando a biblioteca de quantização online do vLLM, produzindo um checkpoint em formato de tensor comprimido que o Databricks carregou para serviço. Na configuração final, as projeções de atenção (Q, K, V e saída) e as projeções MLP passaram pelo caminho FP8, enquanto a quantização do KV-cache foi deixada desativada, pois a quantização de peso foi onde os ganhos de taxa de transferência vieram e a quantização do KV-cache introduziu seus próprios trade-offs de qualidade que não valeram a pena para esta carga de trabalho.
Antes de decidir pela configuração final, ambas as equipes iteraram sobre quais camadas quantizar. As projeções MLP foram quantizadas desde o início, e a questão em aberto era se quantizar as camadas de atenção. O serviço de modelos Databricks projetou o motor de serviço para suportar inferência de precisão híbrida desde o início, de modo que, se algum grupo de camadas se mostrasse muito sensível à qualidade sob quantização, poderíamos mantê-lo em maior precisão sem alterar a arquitetura geral de serviço. Lançamos um sinalizador que nos permitiu alternar a quantização de atenção ligada e desligada, para que ambas as equipes pudessem medir seu impacto diretamente. O experimento foi concluído com sucesso, quantizando as projeções Q/K/V e de saída não produziu degradação de qualidade mensurável nas avaliações da Superhuman.
A outra consideração foi a granularidade da quantização. Kernels prontos para uso usavam escalonamento por tensor (um único fator de escala FP8 para um tensor de peso inteiro). Os kernels do Databricks usam escalonamento por canal, calculando um fator de escala separado por canal de saída de cada camada linear. Isso preserva a faixa dinâmica onde importa, mantém o erro de quantização da camada MLP bem abaixo do limiar onde ele aparece nas avaliações. Combinado com melhorias no nível do kernel, a quantização por canal igualou ou superou outras bases de código aberto com a mesma taxa de transferência.
Eliminando gargalos do lado da CPU
Para modelos pequenos e rápidos, o desempenho é frequentemente limitado pela CPU – não pela GPU. A equipe Databricks já havia investigado a eliminação de gargalos de CPU em seu trabalho sobre serviço PEFT rápido e aqui aplicou otimizações de CPU semelhantes diretamente à carga de trabalho da Superhuman.
Especificamente, a equipe introduziu um servidor de tempo de execução multiprocessamento. Para a maioria das cargas de trabalho de serviço de modelos, um único processo é mais do que rápido o suficiente para manter a GPU saturada, pois a GPU é o gargalo, não a CPU. Mas com um modelo pequeno e rápido, a GPU completa sua passagem para frente mais rápido do que um único processo pode preparar o próximo lote, invertendo o gargalo para a CPU.
A equipe resolveu isso executando múltiplos processos de servidor RPC. Ao ter múltiplos processos de CPU preparando e despachando trabalho para a GPU em paralelo, eliminamos o gargalo de serialização de processo único. Isso entregou mais 20% de throughput adicional.
Outras otimizações do lado da CPU melhoraram o desempenho em alguns pontos percentuais.
- Redução do overhead do Python. Substituímos o fatiamento, cópia e preenchimento de tensores no nível do Python no início de cada etapa de decodificação do grafo CUDA por uma única chamada C++. Também exploramos estratégias paralelas (ThreadPool, OpenMP), mas C++ de thread única foi o ideal devido ao overhead de sincronização CUDA. Isso reduziu ligeiramente o tempo ocioso da GPU por passe de avanço.
- Agendamento assíncrono para melhor sobreposição de trabalho CPU-GPU. Removemos o pós-processamento do lado da CPU do caminho crítico para que ele seja executado concorrentemente com o próximo passe de avanço da GPU. Em vez de concluir todo o pós-processamento para o lote N antes de iniciar o lote N+1, o agendador despacha o N+1 imediatamente e lida com o pós-processamento do N em paralelo. O pós-processamento também itera apenas sobre o subconjunto relevante de solicitações em vez do lote completo. Isso resultou no início mais rápido do próximo passe de avanço.
Próximos passos
Este trabalho é a base para uma parceria mais ampla. A Superhuman está agora migrando modelos adicionais para Databricks, abrangendo diferentes tamanhos de modelo, tipos de tarefa e requisitos de latência — e adotando a Plataforma de IA de forma mais ampla para fluxos de trabalho de treinamento, rastreamento de experimentos, avaliações (ML clássico, Deep-Learning e IA Generativa/Agentes), registro de modelos e juízes (LLM) e ingestão de traces de agentes em escala.
Construir esta plataforma em larga escala foi um esforço de toda a empresa em ambos os lados, e uma experiência de aprendizado extraordinária. Um enorme agradecimento às equipes de ML e infraestrutura da Superhuman pela profunda colaboração, pela disposição de iterar abertamente em difíceis compensações e pelo rigor que trouxeram a cada barra de qualidade e teste de carga. O manual de engenharia que construímos juntos é deles tanto quanto nosso, e estamos animados para trazer o mesmo nível de parceria para todas as cargas de trabalho que seguirem.
Principais conclusões
Usar um serviço de inferência gerenciado não significa ter que desistir do controle. A Superhuman mantém a propriedade total do treinamento do modelo, quantização e padrões de qualidade, enquanto a Databricks mantém o desempenho do tempo de execução e a confiabilidade da plataforma. Essa divisão de responsabilidades funciona bem com SLOs compartilhados, validação conjunta de qualidade e testes de carga progressivos ao integrar-se à plataforma Databricks.
Pronto para servir seus modelos personalizados em escala? Descubra como a API de Modelos Fundamentais da Databricks pode atender aos seus SLAs de inferência mais exigentes — e dar à sua equipe um verdadeiro parceiro de engenharia, não apenas um serviço gerenciado. Entre em contato conosco em https://www.databricks.com/company/contact para integrar seu caso de uso de serviço de modelo de alto QPS.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.