Serviço rápido de PEFT em grande escala
Criar um runtime de inferência ultrarrápido não se trata apenas de velocidade bruta, mas de resolver os problemas certos para clientes reais. Na Databricks, nosso foco em Inteligência de Dados significa ajudar os clientes a transformar seus dados proprietários em agentes de IA que atendem a workloads de produção em grande escala. O mecanismo de inferência está no centro desse desafio, orquestrando tudo, desde o agendamento de solicitações até a execução do kernel da GPU. No último ano, criamos um mecanismo de inferência personalizado que não só supera o código aberto em até 2x nas workloads dos nossos clientes em alguns casos, mas também apresenta menos erros em benchmarks comuns.
Com nosso foco em inteligência de dados, criando IA que pode raciocinar sobre os dados da sua empresa, uma das workloads mais críticas é o serviço de modelos com ajuste fino, que são treinados pelo próprio cliente ou produzidos pelo Agent Bricks. No entanto, modelos com ajuste fino de todos os parâmetros não são escaláveis economicamente ao lidar com solicitações fragmentadas em dezenas de casos de uso especializados. Técnicas de ajuste fino como Low Rank Adapters (LoRA) de (Hu et al, 2021) são abordagens populares, pois são eficientes em termos de memória para o ajuste fino e também podem manter os custos gerenciáveis. Trabalhos tanto da nossa equipe Databricks Research (Biderman et al, 2024) quanto da comunidade (Schulman et al, 2025) estabeleceram que, como uma técnica de treinamento, o PEFT possui características vantajosas.
O desafio que abordamos aqui, no entanto, é como fazer a inferência de PEFT funcionar em grande escala sem sacrificar o desempenho ou a qualidade do modelo.
Nosso runtime de inferência de ponta
Nosso produto Model Serving potencializa grandes volumes de dados em tempo real e em lote no Databricks, e descobrimos que, para oferecer desempenho nas cargas de trabalho dos clientes, é preciso inovar além do que está disponível em código aberto. É por isso que desenvolvemos um runtime de inferência proprietário e um sistema associado que supera significativamente o desempenho das alternativas de código aberto em até 1,8x em alguns casos, mesmo ao executar apenas modelos base.
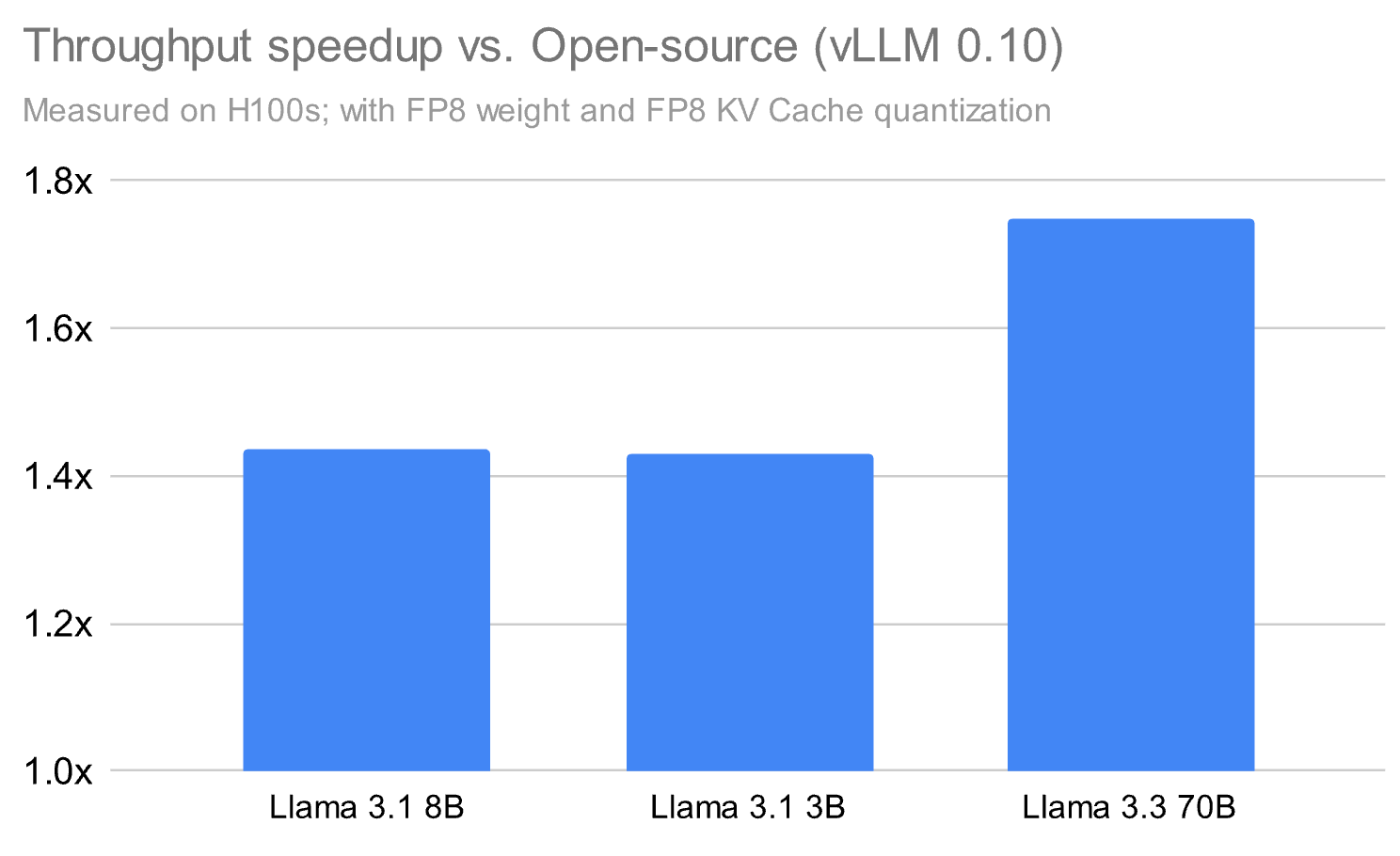
Além do runtime de inferência em si, criamos uma infraestrutura de serviço abrangente que abrange todo o stack de produção: escalabilidade, confiabilidade e tolerância a falhas. Isso envolveu a solução de desafios complexos de sistemas distribuídos, incluindo escalonamento automático e balanceamento de carga, implantação em várias regiões, monitoramento de integridade, roteamento e enfileiramento inteligente de solicitações, gerenciamento de estado distribuído e controles de segurança de nível empresarial.
Com isso, nossos clientes alcançam não apenas uma inferência rápida, mas um sistema pronto para produção que lida com workloads empresariais do mundo real com a confiabilidade e a escala que eles exigem. Embora tenhamos feito muitas inovações para alcançar esse desempenho, desde kernels personalizados até runtimes otimizados, neste blog, focaremos em apenas uma dessas direções: o serviço rápido de modelos com ajuste fino com LoRA.
Estes são os princípios-chave que guiaram nosso trabalho:
- Pense primeiro no framework, não no kernel: As otimizações mais eficazes surgem quando se tem uma visão mais ampla, entendendo como o agendamento, a memória e a quantização interagem entre as camadas do stack.
- A quantização deve respeitar a qualidade do modelo: utilizar FP8 pode proporcionar grandes ganhos de velocidade, mas somente se combinado com formatos híbridos e kernels fundidos que preservam a precisão.
- A sobreposição é um multiplicador de throughput: Seja sobrepondo kernels entre streams ou no mesmo stream usando a limitação de SM, maximizar a utilização da GPU é fundamental para maximizar o throughput.
- Os overheads da CPU costumam ser o gargalo silencioso: especialmente para modelos menores, o desempenho da inferência é cada vez mais limitado pela rapidez com que a CPU consegue preparar e despachar o trabalho para a GPU. Também é importante minimizar o tempo ocioso da GPU entre duas etapas de decodificação, sobrepondo a execução da CPU com a execução da GPU.
Análise aprofundada da disponibilização rápida de modelos com ajuste fino
Entre muitas técnicas de ajuste fino com eficiência de parâmetros (PEFT), LoRA surgiu como o método PEFT mais amplamente adotado devido ao seu equilíbrio entre preservação da qualidade e eficiência computacional. Pesquisas recentes, incluindo o estudo abrangente "LoRA Without Regret" de Schulman et al. e nosso próprio estudo “LoRA learns less, forgets less”, validaram princípios-chave para o uso eficaz de LoRA: aplicar LoRA a todas as camadas (especialmente camadas MLP/MoE) e garantir capacidade de adaptador suficiente em relação ao tamanho do conjunto de dados. No entanto, alcançar uma boa eficiência computacional na inferência exige muito mais do que apenas seguir esses princípios. As vantagens teóricas de FLOP do LoRA não se traduzem automaticamente em ganhos de desempenho no mundo real devido a inúmeros overheads no tempo de inferência.
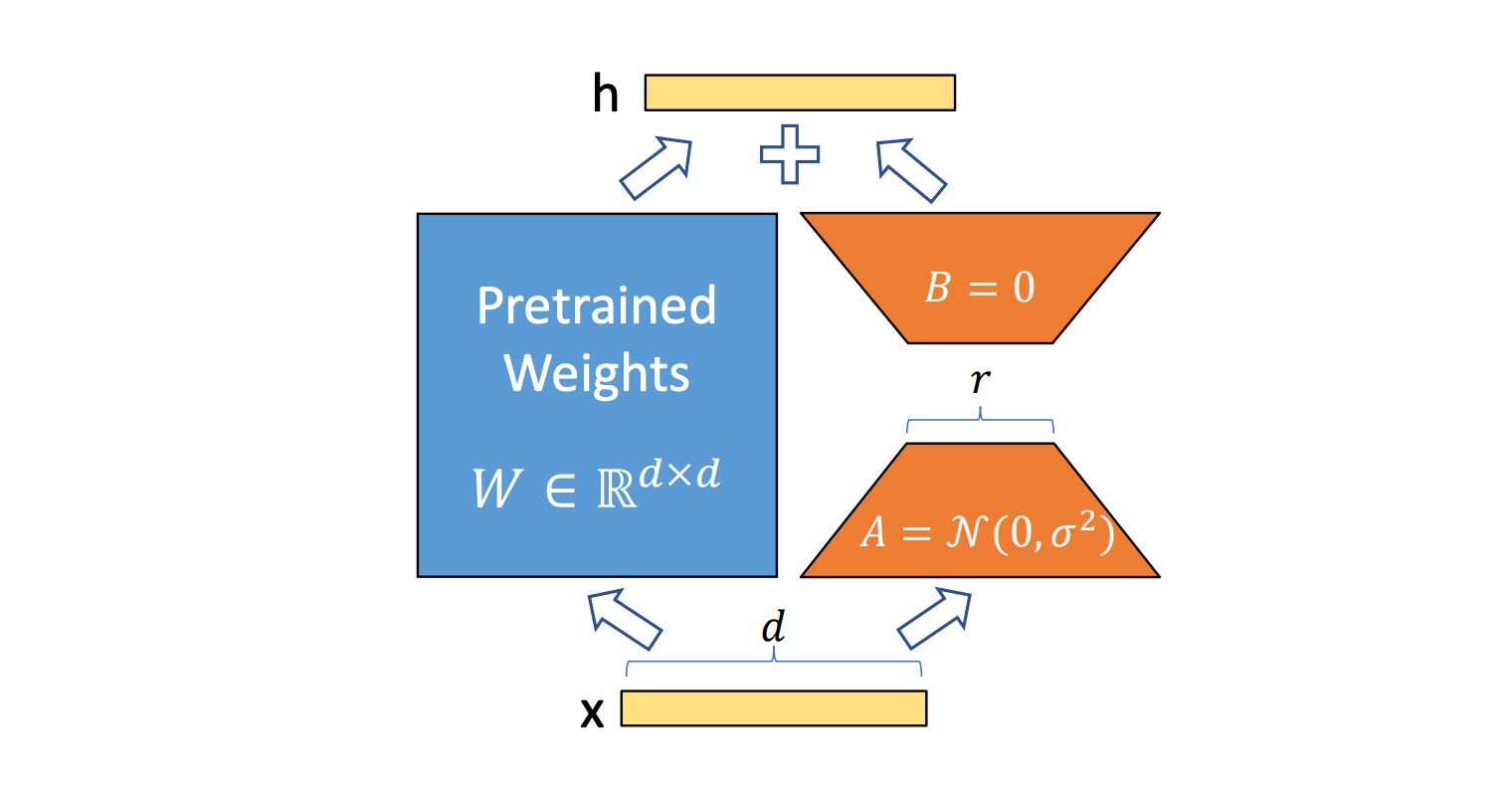
Além disso, existe um trade-off entre o rank do LoRA, que afeta a qualidade do modelo final, e o desempenho da inferência do modelo. Com base em nossos experimentos, descobrimos que, para a maioria dos clientes, um rank maior, de 32, era necessário para não degradar a qualidade do modelo durante o treinamento. Mas isso pressiona o sistema de inferência a otimizar.
Em sistemas de produção, os servidores devem lidar com um número variável de solicitações LoRA, o que é um problema desafiador para otimização de desempenho. As abordagens existentes têm overheads significativos ao servir LoRA, às vezes, retardando a inferência em até 60% em cenários realistas.
Durante a inferência, os adaptadores LoRA são aplicados como multiplicações de matrizes de baixo rank para cada um dos adaptadores individuais e para cada token em paralelo com as camadas lineares do modelo base. Essas multiplicações de matrizes geralmente envolvem dimensões internas e externas menores do que as dimensões observadas para modelos na comunidade de código aberto. Por exemplo, dimensões ocultas comuns para modelos de código aberto como o modelo Llama 3.1 8B são 8192, enquanto a dimensão do rank pode ser tão baixa quanto 8 para multiplicações de matrizes LoRA. Dessa forma, a comunidade de código aberto não investiu esforços significativos na otimização de seus kernels para essas configurações e em técnicas para maximizar a utilização de hardware para esses cenários.
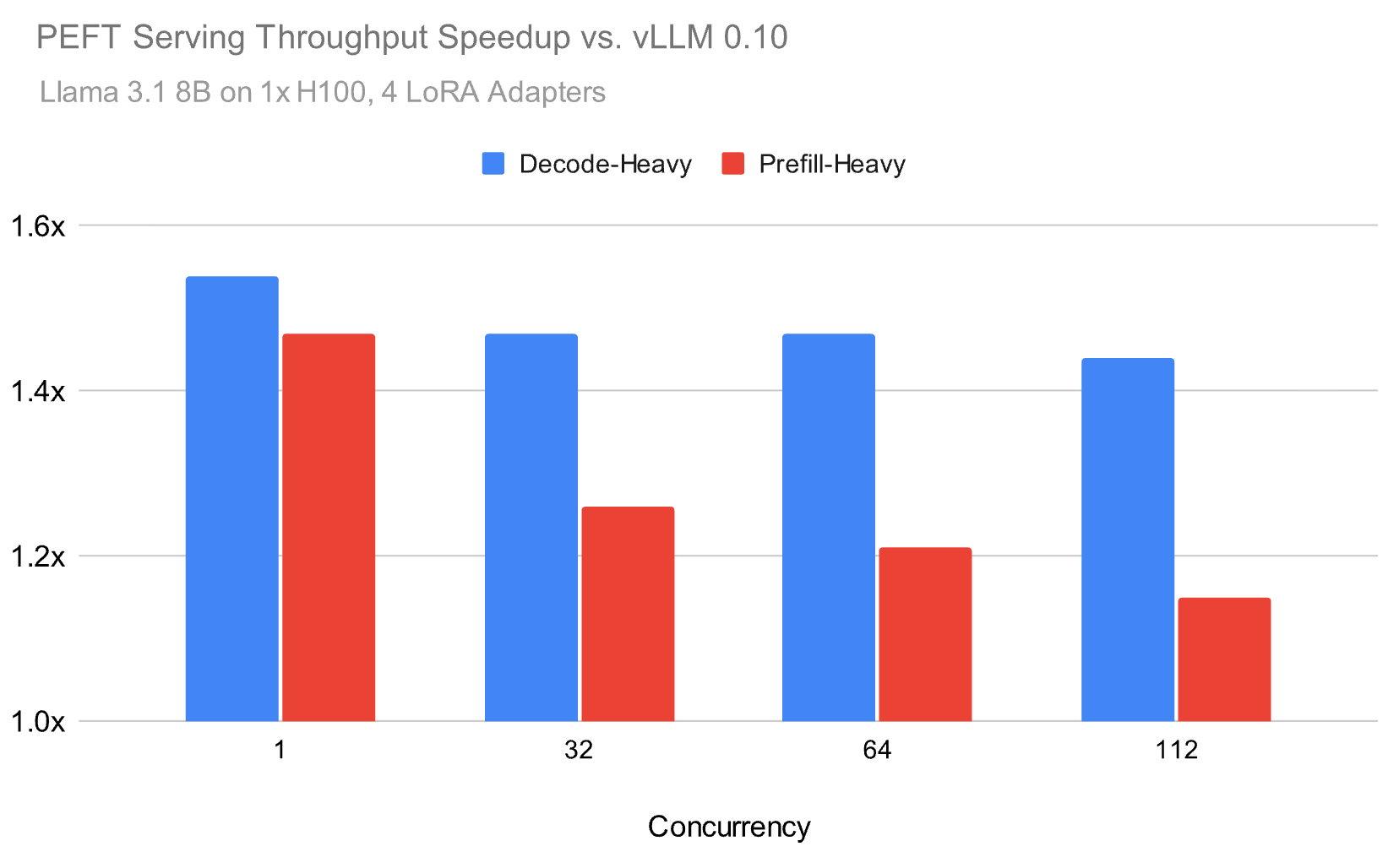
No último ano, desenvolvemos nosso runtime de inferência para enfrentar esses desafios e, como ilustrado na Figura 1, conseguimos alcançar uma aceleração de até 1,5x no serviço de LoRA em ambientes realistas em comparação com o código aberto. Por exemplo, abaixo, fazemos o benchmark do modelo Meta Llama 3.1 8B usando uma distribuição Zipf para os adaptadores LoRA com uma média de 4 adaptadores.
Nosso runtime de inferência alcança um throughput até 1,5x maior do que as alternativas populares de código aberto, tanto para cargas de trabalho pesadas em prefill quanto em decode, com a diferença de desempenho diminuindo, mas permanecendo substancial em cargas mais altas. Para alcançar esses ganhos de velocidade, focamos em alguns componentes que descrevemos neste blog:
- A qualidade é tão importante quanto as otimizações de desempenho. Conseguimos maximizar o desempenho com implementações personalizadas de Attention e GEMM, preservando a qualidade do modelo nos principais benchmarks.
- Particionar os recursos da GPU entre e dentro de multiprocessadores para lidar melhor com as pequenas multiplicações de matrizes em GEMM.
- Otimização da sobreposição de execuções de kernel para minimizar gargalos no sistema.
Quantização que preserva a qualidade do modelo base
A quantização para aproveitar unidades de hardware de menor precisão é fundamental para o desempenho, mas pode ter um impacto na qualidade. Os provedores de modelos geralmente comprimem seus modelos para fp8 durante a inferência. Por outro lado, o treinamento é mais sensível à qualidade, então o ajuste fino dos adaptadores LoRA é geralmente realizado em modelos em sua precisão nativa (bf16). Essa discrepância leva a um desafio para o serviço de modelos PEFT, onde devemos maximizar os recursos de hardware, garantindo ao mesmo tempo que a qualidade do modelo base seja preservada durante a inferência para imitar da melhor forma as configurações de treinamento.
Para manter a qualidade enquanto otimizamos o desempenho, desenvolvemos algumas técnicas personalizadas em nosso runtime personalizado. Como visto na tabela abaixo, nossas otimizações podem manter a qualidade dos adaptadores treinados em comparação com o serviço em precisão total. Esta é uma das razões pelas quais nosso runtime não é apenas mais rápido, mas também tem maior qualidade em benchmarks em comparação com runtimes de código aberto.
Adaptadores PEFT com ajuste fino para as tarefas listadas abaixo PEFT Llama 3.1 8B instruct | Precisão total (Acur. ± Desv. Padrão) % | Databricks Inference Runtime | vLLM 0.10 |
Humaneval | 74.02 ± 0.16 | 73,66 ± 0,39 | 71.88 ± 0.44 |
Matemática | 59.13 ± 0.14 | 59.13 ± 0.06 | 57.79 ± 0.36 |
Figura 4, com nossas alterações personalizadas, conseguimos manter mais de perto a qualidade de uma linha de base onde o modelo base é servido em BF16. Observe que todas as medições com vLLM 0.10 são feitas com a quantização de peso tensorwise FP8, ativação dinâmica e cache KV habilitada.
Validação de qualidade rigorosa
Uma lição fundamental ao colocar a quantização em produção é a necessidade de uma validação de qualidade rigorosa. No Databricks, não apenas fazemos o benchmark de modelos, mas também realizamos comparações estatísticas detalhadas entre as saídas quantizadas e as de precisão total para garantir que não ocorra nenhuma degradação perceptível. Toda otimização que implementamos deve atender a esse critério, independentemente do ganho de desempenho que ela proporciona.
A quantização também deve ser tratada como uma questão no nível do framework, e не como uma otimização local. Por si só, a quantização pode introduzir sobrecargas ou gargalos. Mas, quando coordenada com a fusão de kernels ou técnicas de processamento in-kernel, como a especialização de warp, essas sobrecargas podem ser totalmente ocultadas, resultando em qualidade e desempenho. Na seção abaixo, exploramos estratégias de quantização específicas que tornaram isso possível.
Quantização de Peso FP8
Existem inúmeras abordagens para quantizar os pesos de um modelo, cada uma com seu próprio conjunto de tradeoffs. Algumas técnicas de quantização são mais granulares no posicionamento de seus fatores de escala, enquanto outras são de granulação grossa. Essas abordagens de granulação grossa resultam em erro maior, mas menos overhead durante a quantização dos tensores de ativação.
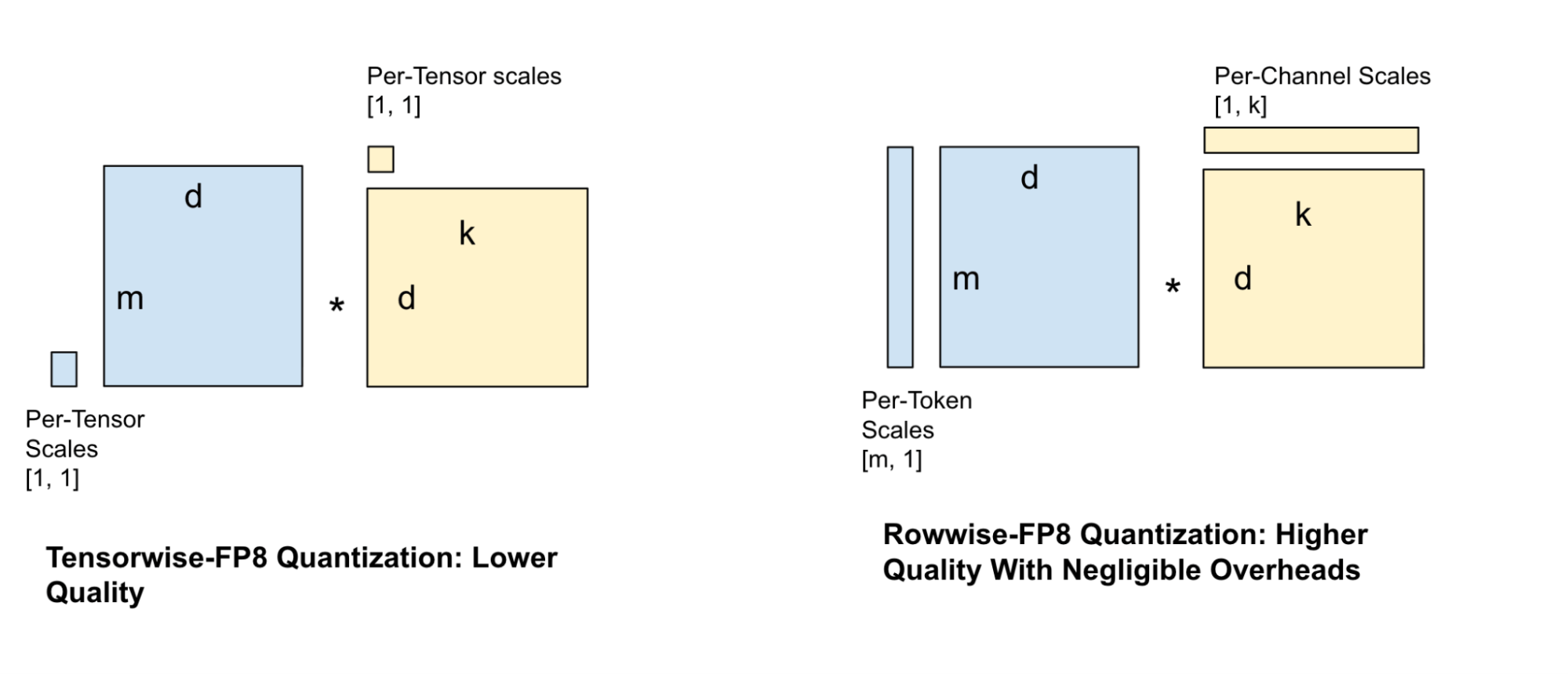
Uma técnica popular de quantização para servir modelos é a quantização FP8 por tensor, na qual um único fator de escala é atribuído a todo o tensor. No entanto, essa técnica causa uma perda de informação considerável e resulta em uma redução significativa da qualidade, especialmente para modelos menores. Isso exige fatores de escala mais granulares, o que nos levou a experimentar várias configurações de fator de escala para os pesos e as ativações, como escalas por canal e por bloco. Equilibrando a velocidade do GEMM com a perda de qualidade, escolhemos a configuração de fator de escala por linha, conforme mostrado na Figura 4.
Para superar a sobrecarga de desempenho do cálculo de fatores de escala mais granulares para as ativações, realizamos algumas fusões de kernels críticas com operações anteriores limitadas pela largura de banda para ocultar a sobrecarga da computação adicional.
Attention híbrido
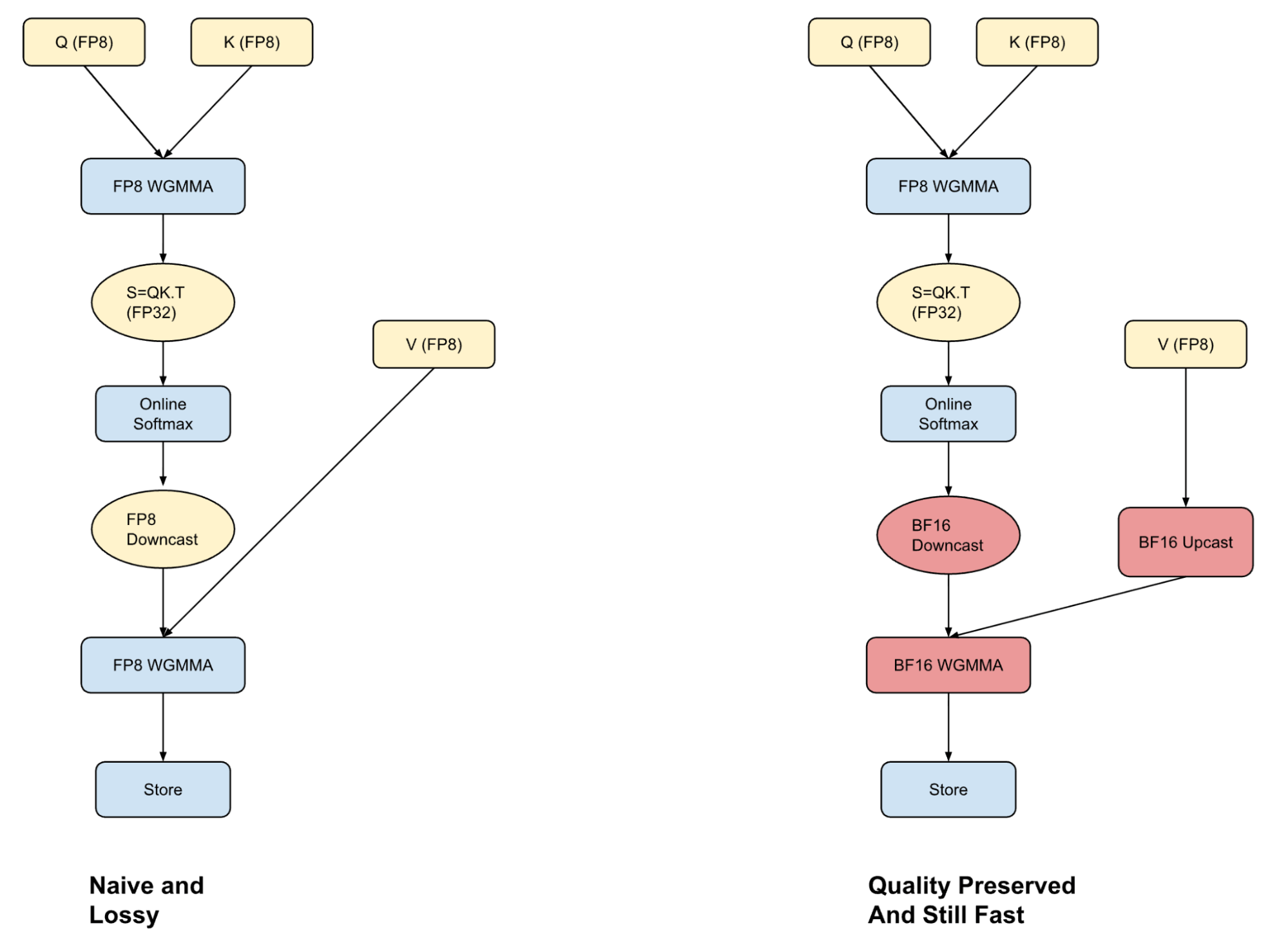
Uma parte central da inferência baseada em Transformer é a operação de Attention, que pode consumir até 50% do tempo total de computação para modelos menores com comprimentos de contexto longos. Uma abordagem comum para acelerar as decodificações durante a inferência é armazenar em cache as saídas de valor-chave do pré-preenchimento.
Armazenar caches KV no formato FP8 pode melhorar o throughput, mas para aproveitar todo o benefício é necessário um kernel de atenção que consiga processar entradas FP8 com precisão e rapidez. A maioria dos frameworks realiza a atenção inteiramente em FP8 (rápido, mas com perdas) ou usa BF16 (mais preciso, mas mais lento devido ao upcasting). Adotamos um caminho intermediário com a atenção híbrida: combinamos os pontos fortes de ambos os formatos para alcançar um melhor trade-off entre desempenho e qualidade.
Convergimos para este formato após descobrirmos que o erro de quantização na computação de atenção FP8 vem do downcasting da computação softmax para uma representação de bits inferior. Ao realizar a primeira parte da computação em FP8 e explorando estratégias de especialização de warp em GPUs Hopper, podemos sobrepor o upcast do vetor V com a computação Q-K. Isso nos permite executar a computação P-V em BF16 sem nenhuma penalidade de desempenho. Embora isso ainda seja mais lento do que fazer toda a computação em FP8, o mais importante é que a abordagem híbrida não degrada a qualidade do modelo.
Nosso trabalho se baseia em abordagens semelhantes sugeridas no meio acadêmico, SageAttention e SageAttention2 por Zhang et al., bem como em um blog do CharacterAI.
Transformadas Rápidas de Hadamard Fundidas Pós-RoPE
Lembre-se de que a consulta (query) e a chave (key) para um determinado token são calculadas a partir de seu embedding x no início do módulo de atenção como:
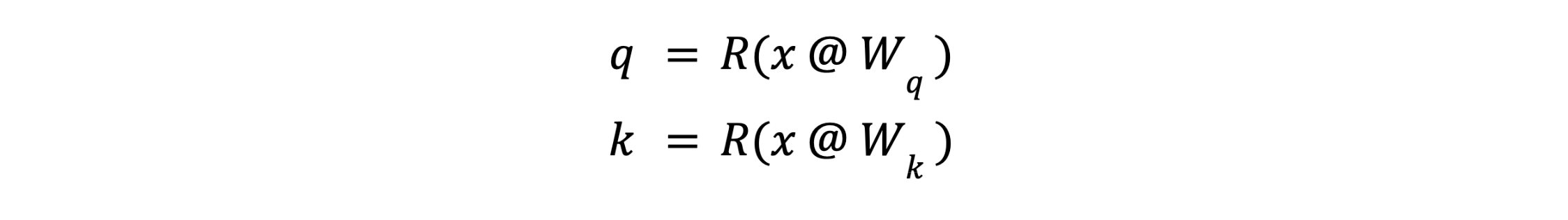
Onde R() é o operador de embedding RoPE. Após o RoPE, não é necessário preservar os valores exatos de q ou k; é necessário apenas preservar os produtos internos q.T @ k para todas as consultas q e chaves k. Isso nos permite aplicar uma transformada linear U a q e k:
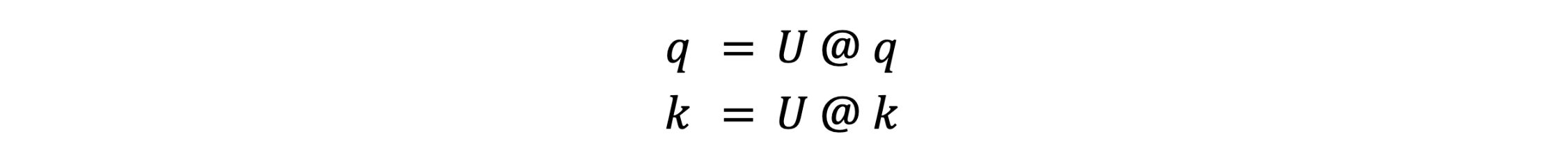
tal que U.T @ U = I, a matriz identidade. Isso faz com que U se anule durante o cálculo da atenção:
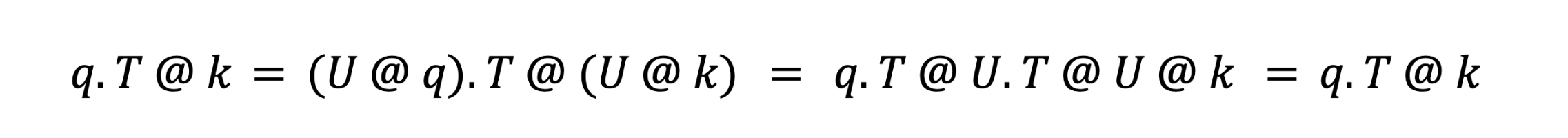
Isso nos permite otimizar os vetores q e k para quantização sem alterar (matematicamente) a computação de atenção. A transformação específica que usamos é a Transformada Rápida de Hadamard (FHT), que nos permite espalhar a variância por D canais em operações O(log2(D)). Essa dispersão da variância elimina outliers e permite escalas FP8 menores – você pode pensar nisso como a capacidade de dar um "zoom" para obter melhor resolução. Este trabalho se baseia em abordagens semelhantes sugeridas na academia, FlashAttention3 por Dao et al., e QuaRot por Ashkboos et al.
Para evitar overhead, escrevemos um kernel que funde RoPE, FHT, quantização e a anexação ao cache KV.
Sobreposição de kernels para minimizar os overheads de PEFT
Durante a inferência com LoRA, o rank do adaptador representa uma das dimensões da multiplicação de matrizes. Como o rank normalmente pode ser pequeno (por exemplo, 8 ou 32), isso leva a multiplicações de matrizes com dimensões assimétricas, resultando em overhead adicional durante a inferência (Figura 1).
Assim, inspirados no trabalho Nanoflow de Zhu et al., temos explorado várias estratégias para ocultar esse overhead sobrepondo os kernels LoRA com o modelo base e entre si.
Conforme descrito na Figura 1, a inferência de LoRA consiste em dois kernels principais, um kernel de projeção para baixo (definido como o kernel “Shrink”) e um kernel de projeção para cima (definido como o kernel “Expand”). Estes são principalmente Grouped GEMMs (onde cada GEMM opera em um adaptador diferente), já que normalmente servimos vários adaptadores LoRA simultaneamente. Isso nos permite sobrepor esses Grouped GEMMs com as computações do modelo base e os kernels Shrink e Expand entre si, conforme descrito abaixo na Figura 6.
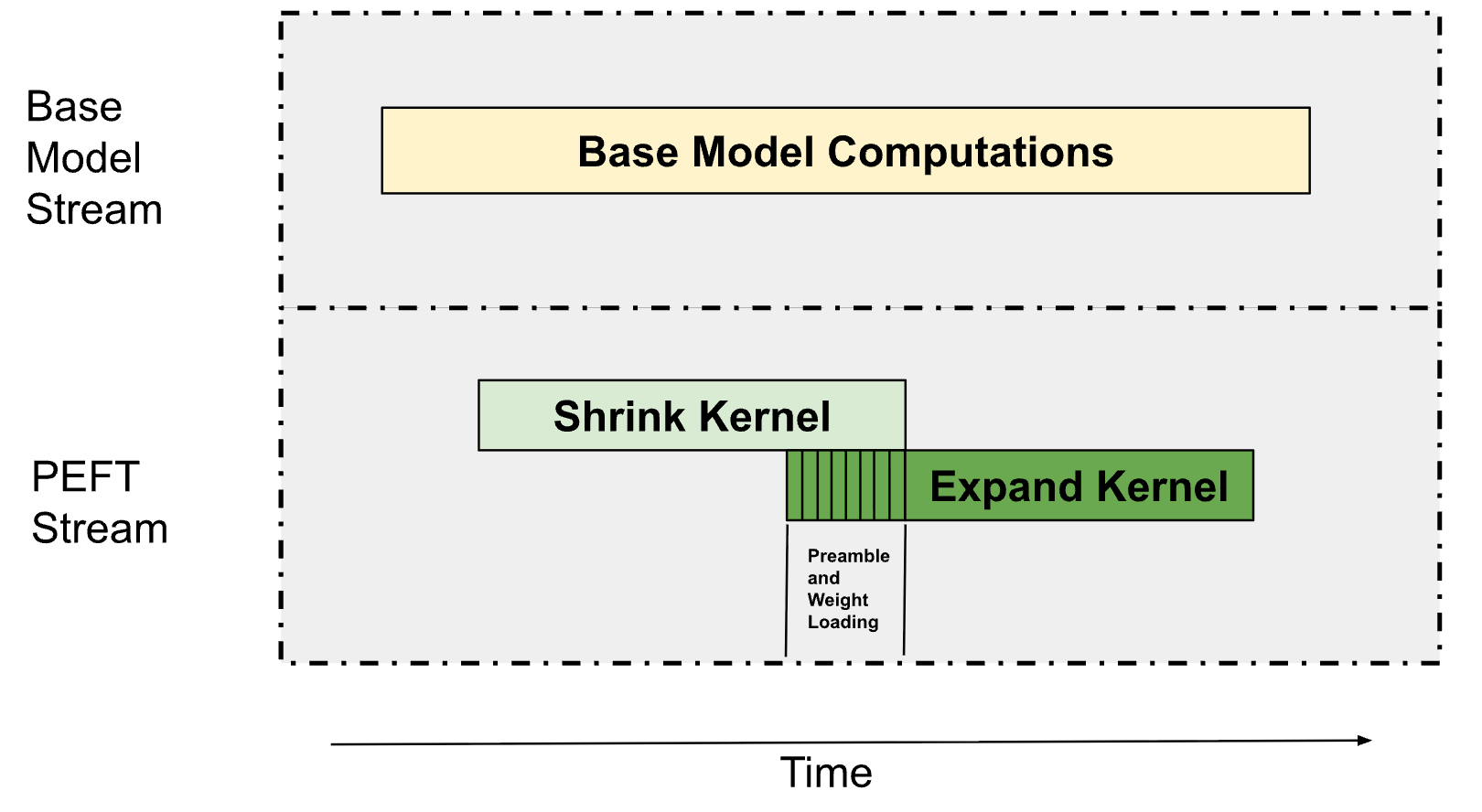
Fluxos Paralelos com Particionamento Multiprocessador
Em um nível superficial, é trivialmente possível sobrepor execuções de kernel que dependem de dados diferentes ao iniciá-las em streams separados. Essa abordagem depende inerentemente do distribuidor de trabalho de computação para agendar os blocos das diferentes execuções de kernel. No entanto, isso só funciona quando há capacidade de computação não utilizada suficiente. Para cargas de trabalho maiores que normalmente saturariam a GPU, precisamos de uma abordagem mais sofisticada.
Indo além disso, percebemos que podemos particionar o número de Streaming Multiprocessors (SMs) exigidos pelos kernels limitados pela largura de banda sem afetar significativamente seu desempenho. Na maioria dos cenários, descobrimos que os kernels limitados pela largura de banda não precisam de todos os SMs possíveis para poderem acessar toda a largura de banda da memória na GPU. Dessa forma, isso nos permite restringir o número de SMs usados por esses kernels e, em seguida, usar os multiprocessadores restantes para realizar outras computações.
Para o PEFT, executamos dois fluxos: um para o modelo base e outro para o caminho do PEFT. O modelo base recebe até 75% dos SMs na GPU, e o restante vai para o caminho do PEFT. Com esse particionamento, descobrimos que o caminho do modelo base não fica significativamente mais lento, enquanto o caminho do PEFT consegue ser executado em segundo plano, o que nos permite ocultar a sobrecarga do PEFT na maioria dos casos.
Mesmo stream com inicializações dependentes
Embora as execuções de kernel que dependem de dados diferentes possam ser facilmente sobrepostas em streams diferentes, as execuções de kernel dependentes no mesmo stream são mais difíceis de sobrepor, pois cada kernel deve esperar o anterior ser concluído. Para resolver isso, usamos o Programmatic Dependent Launch (PDL), que nos permite pré-buscar os pesos para o próximo kernel enquanto o atual ainda está em execução.
PDL é um recurso avançado do runtime CUDA que permite iniciar um kernel dependente antes que o kernel primário no mesmo stream tenha terminado de executar. Isso é ilustrado na Figura 8 abaixo.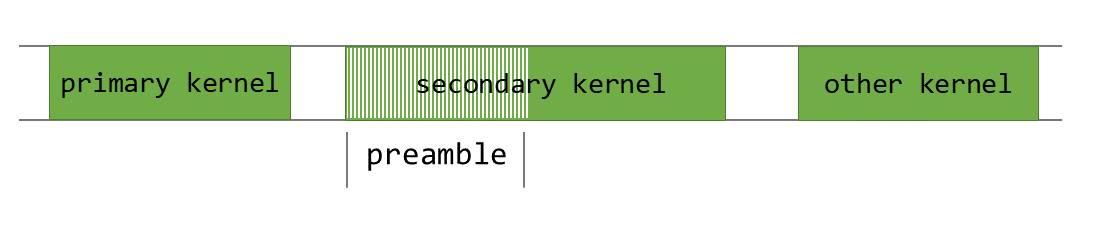
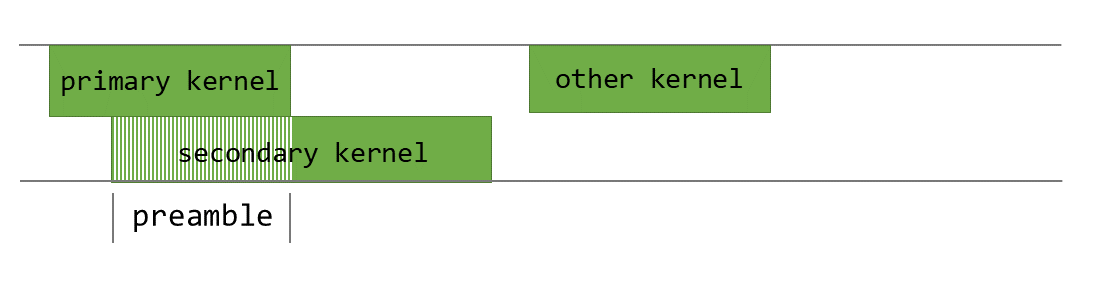
Para nossos kernels PEFT, usamos o PDL para sobrepor as operações de redução e expansão. Enquanto o kernel de redução é executado, nós pré-buscamos os pesos necessários para o kernel de expansão para a memória compartilhada e o cache L2. Nós limitamos a memória compartilhada e os recursos de registrador do kernel de redução para garantir que haja recursos suficientes para a execução do kernel de expansão. Isso permite que o kernel de expansão inicie o processamento dos pesos enquanto o kernel de reducción ainda está concluindo sua computação. Assim que o kernel de redução é concluído, o kernel de expansão carrega as ativações e começa a realizar os cálculos de multiplicação de matrizes.
Conclusão
Permitir que nossos clientes aproveitem seus dados para gerar insights exclusivos é uma parte central de nossa estratégia aqui na Databricks. Uma parte fundamental disso é ser capaz de servir com sucesso as solicitações LoRA no runtime de inferência. As técnicas que compartilhamos — desde formatos de quantização até fusão de kernels, desde agendamento em nível de SM até sobreposição CPU-GPU, todas derivam desta filosofia de "framework-first". Cada otimização foi validada em benchmarks de qualidade rigorosos para garantir que nunca trocamos precisão por velocidade.
Olhando para o futuro, estamos entusiasmados para avançar ainda mais com mais estratégias de megakernel e mecanismos de agendamento mais inteligentes.
Para começar a usar a inferência de LLM, experimente o Databricks Model Serving em nossa plataforma.
Autores: Nihal Potdar, Megha Agarwal, Hanlin Tang, Asfandyar Qureshi, Qi Zheng, Daya Khudia
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.