Julgando com Confiança: Conheça o PGRM, o Modelo de Recompensa Orientado por Prompt
por Alex Trott, Sean Kulinski, Cory Stephenson, Pallavi Koppol, Jonathan Chang, Ashutosh Baheti, Samraj Moorjani, Eric Peter, Jonathan Frankle e Matei Zaharia
A IA está transformando a maneira como as empresas operam, mas garantir que seus sistemas de IA sejam realmente úteis, seguros e alinhados com suas necessidades continua sendo um grande desafio - especialmente quando você os coloca em produção em larga escala. A revisão manual é lenta e cara, enquanto as ferramentas de monitoramento existentes podem ser rígidas, ineficientes ou faltam transparência. E se você pudesse monitorar, avaliar e controlar o comportamento da sua IA de maneira confiável com uma única ferramenta adaptável - sem a necessidade de conhecimento profundo?
É aqui que entra o novo Modelo de Recompensa Orientado por Prompt (PGRM) da Databricks. Pense no PGRM como o inspetor de controle de qualidade da sua IA - um que pode se adaptar instantaneamente a novas regras, sinalizar casos incertos para revisão e fornecer pontuações claras e respaldadas por confiança para cada decisão. É tão flexível quanto um juiz LLM, mas tão eficiente e calibrado quanto um classificador construído para um propósito específico. Seja para impor diretrizes de segurança, garantir a precisão factual ou alinhar as saídas com a sua marca, o PGRM torna possível fazer isso em larga escala e com transparência.
Por que isso importa? Com o PGRM, você pode:
- Unifique suas salvaguardas e avaliação do LLM com um único prompt adaptável
- Foque o tempo dos seus especialistas onde é mais importante
- Adapte a supervisão conforme suas necessidades evoluem - sem precisar treinar tudo novamente do zero
Não apenas isso, mas o PGRM também pode alimentar fluxos de trabalho avançados de modelagem de recompensa - ajudando você a trazer à tona automaticamente as melhores respostas do seu AI, ajustar modelos às suas necessidades específicas com aprendizado por reforço e impulsionar a melhoria contínua com muito menos esforço manual.
O PGRM oferece o melhor de ambos, um juiz LLM e um modelo de recompensa. Como um juiz LLM, ele atinge uma precisão média de 83,3% em nossos benchmarks internos que medem a qualidade do julgamento, igualando o GPT-4o (83,6%) em tarefas de avaliação chave como a correção da resposta e a fidelidade ao contexto. Como um modelo de recompensa, no RewardBench2, um novo e desafiador benchmark público para modelagem de recompensa, o PGRM se classifica como o segundo classificador sequencial e o quarto no geral, com uma pontuação geral de 80,0—superando a maioria dos modelos de recompensa dedicados e até mesmo ultrapassando LLMs de fronteira como o GPT-4o (64,9) e o Claude 4 Opus (76,5) na avaliação de recompensa detalhada. Isso faz do PGRM o primeiro modelo a entregar resultados de última geração tanto em julgamento instrutível quanto em modelagem de recompensa de alta precisão sem comprometer a eficiência.
Agora, vamos dar uma olhada mais de perto em como o PGRM preenche a lacuna entre os modelos de recompensa tradicionais e os juízes LLM flexíveis, e o que isso significa para a construção de uma IA confiável.
PGRM: Um Novo Híbrido Instruível
A necessidade de supervisão escalável do comportamento da IA nunca foi tão grande. A solução automatizada mais comum para este problema é usar um LLM para "julgar" se o seu sistema de IA se comportou adequadamente de acordo com um conjunto de diretrizes. Esta abordagem de julgamento se baseia na capacidade dos LLMs de seguir diversas instruções em linguagem natural, por exemplo, dando ao juiz LLM uma rubrica que explica como avaliar várias entradas. Quer saber se uma saída é "segura", "verdadeira" ou "de acordo com a marca"? Apenas mude o rubric. No entanto, os juízes LLM são caros e notoriamente ruins em estimar sua própria confiança na precisão de seus julgamentos.
E quanto aos modelos de recompensa (RMs)? Estes são um tipo especializado de classificador treinado para prever como um humano avaliaria uma resposta de IA. Os RMs são normalmente usados para alinhar os modelos de base com as preferências humanas em técnicas como RLHF. Eles são eficientes e escaláveis, pois não precisam gerar nenhuma saída, e são úteis para o cálculo em tempo de teste, destacando a melhor resposta entre muitas geradas pela sua IA. Ao contrário dos juízes LLM, eles são calibrados: além de gerar uma previsão, eles também adivinham com precisão o quão certos ou incertos estão sobre se essa previsão está correta. Mas eles geralmente não fazem parte da conversa quando se trata de coisas como avaliação ou monitoramento, provavelmente porque eles não têm a instrutibilidade de um juiz LLM. Em vez disso, cada RM é ajustado a uma especificação ou conjunto de critérios fixos - atualizar ou direcionar sua definição de "bom" significa um caro retrabalho do zero. Por essa razão, os RMs geralmente são considerados apenas para RLHF, fluxos de trabalho de cálculo em tempo de teste como o melhor-de-N, ou métodos de ajuste fino de RL como o TAO.
Desenvolvemos o PGRM porque julgamento e modelagem de recompensa são dois lados da mesma moeda, apesar de muitas vezes serem tratados como separados. O PGRM preenche essa lacuna ao embalar um juiz LLM na forma de um RM. O resultado é um modelo que reúne o melhor dos dois mundos - a velocidade e calibração de um RM com a instrutibilidade de um juiz LLM - produzindo uma hibridização que desbloqueia novo potencial em ambas as frentes.
| Modelos de Recompensa | Juízes de LLM | PGRM | |
|---|---|---|---|
| Instruível | ❌ | ✅ | ✅ |
| Escalável | ✅ | ❌ | ✅ |
| Calibrado | ✅ | ❌ | ✅ |
Vamos definir alguns desses conceitos-chave. Instrutível significa que o sistema permite instruções arbitrárias em linguagem natural descrevendo como um exemplo deve ser pontuado ou julgado. Como exemplo simples, “Qual é a capital da França? Paris.” pode ser bom se a diretriz for 'ser correto', mas ruim se a diretriz for 'responder em frases completas'. Sistemas instrutáveis permitem que você defina essas regras. Abordagens escaláveis são aquelas que evitam a sobrecarga associada aos LLMs (ou seja, o tempo e o custo incorridos na geração de texto). Finalmente, em um alto nível, calibrado essencialmente significa que o sistema não apenas julga algo como bom ou ruim, mas também transmite o quão confiante está nesse julgamento. Uma boa calibração é útil para muitas tarefas, como priorizar quais saídas de LLM são mais propensas a serem problemáticas e identificar a melhor resposta entre um conjunto de candidatos. Isso também adiciona uma camada de interpretabilidade e controle no contexto da avaliação. O PGRM combina todas essas características em um único modelo.
Colocando PGRM para Trabalhar
O PGRM desbloqueia um novo conjunto de ferramentas para IA no Databricks e adiciona um novo nível de personalização aos métodos baseados em RM para melhorar seus sistemas de IA. Veja como o PGRM poderia remodelar o ciclo de vida do desenvolvimento de IA:
- Supervisão Simplificada: Imagine gerenciar tanto um guarda-corpo quanto um juiz com um único prompt ajustável. A instrutibilidade do PGRM significa que você pode focar seus esforços de avaliação e manter sua IA alinhada com as regras de negócios em evolução - tudo com um único prompt.
- Triagem de Qualidade Direcionada e Rotulagem Inteligente: As pontuações de confiança calibradas do PGRM ajudam você a se concentrar nos casos ambíguos que precisam de atenção especializada. Isso significa menos esforço desperdiçado revisando seu sistema de IA e uma curadoria mais rápida de conjuntos de dados de alta qualidade.
- Alinhamento com Especialista do Domínio: Ajuste facilmente o que conta como uma resposta "boa" ou "ruim" para corresponder aos padrões da sua organização. A pontuação ajustável do PGRM ajuda a garantir que os julgamentos automatizados permaneçam sincronizados com seus especialistas, construindo confiança e melhorando a precisão.
- Melhoria Contínua do Modelo: Aproveite as capacidades de modelagem de recompensa do PGRM para trazer à tona e promover automaticamente as melhores respostas da IA durante o TAO- com total controle sobre o que "melhor" significa. Ao ajustar seus modelos com PGRM, você pode direcionar melhorias na qualidade, segurança e alinhamento.
Avaliando o PGRM como um Juiz
O PGRM fornece um sistema de julgamento que é tão adaptável quanto um LLM, mas tão prático e eficiente quanto um modelo de recompensa construído para esse fim. Em contraste com os modelos de recompensa, um "juiz" não é um tipo de modelo - é essencialmente um conjunto de instruções fornecidas a um LLM padrão. Ou seja, você normalmente cria um juiz instruindo um LLM a avaliar uma resposta de acordo com alguns critérios. Portanto, julgar respostas em uma variedade de dimensões de qualidade requer um modelo que possa seguir instruções. Os RMs padrão não atendem a essa exigência, então a prática típica é recorrer aos juízes LLM. O PGRM, no entanto, é um RM projetado para lidar com instruções como um juiz.
Para demonstrar que o PGRM pode lidar com o tipo de tarefas de julgamento necessárias para avaliar e monitorar sistemas de IA, comparamos sua precisão de julgamento com a do GPT-4o em algumas tarefas; especificamente, as mesmas tarefas que alimentam nosso mlflow produto de avaliação.
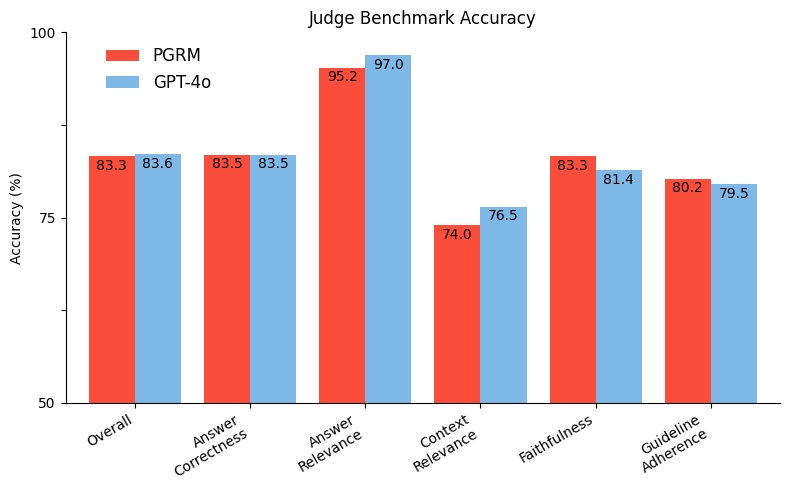
Este gráfico mostra as precisões média e por tarefa do PGRM e GPT-4o em nosso benchmark interno. Cada tarefa aqui é definida por uma instrução específica pedindo ao modelo para julgar uma determinada resposta de alguma maneira específica. Por exemplo, Correção da Resposta exige que o modelo determine se a resposta concorda com uma verdade pré-verificada e Fidelidade pergunta se a resposta foi apoiada pelo contexto disponível. Como mostrado, o PGRM alcança quase paridade com o GPT-4o, igualando efetivamente a qualidade do julgamento de um LLM de fronteira.
Julgando com Confiança
Como um modelo de recompensa instrutível, o PGRM iguala as capacidades de julgamento de um LLM poderoso, enquanto introduz escalabilidade e calibração. Um juiz LLM pode oferecer um bom julgamento de aprovação/reprovação, mas não indicará de forma confiável sua confiança. Como um modelo fundamentalmente construído para classificação, as pontuações do PGRM indicam naturalmente sua confiança em seu veredicto, com pontuações mais extremas indicando maior certeza.
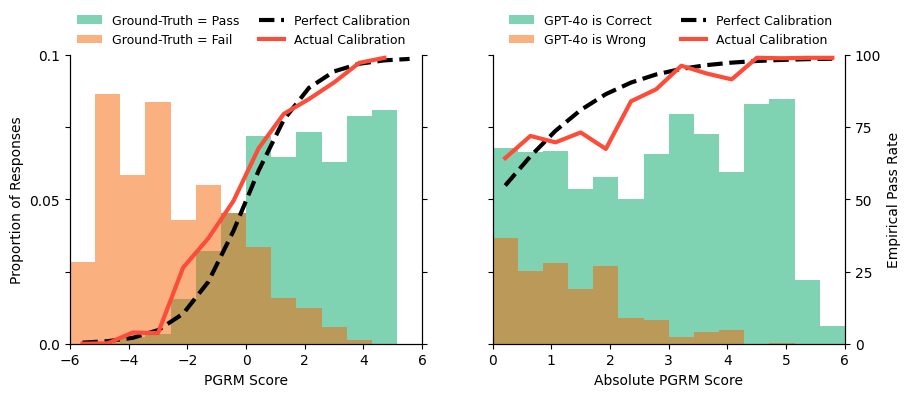
A figura à esquerda ilustra a calibração. Estamos sobrepondo dois histogramas: pontuações PGRM para exemplos de referência onde o veredicto da verdade fundamental foi "passar" (verde) e aqueles com "falhar" (laranja). Podemos medir a proporção de exemplos de passar/falhar em cada balde de pontuação (vermelho) e comparar isso com o que esperaríamos de um classificador perfeitamente calibrado (preto), observando uma correspondência próxima. Em outras palavras, quando o PGRM diz que sua confiança é de 70%, ele estará correto cerca de 70% do tempo.
Em contraste, os LLMs são bem conhecidos por serem classificadores capazes, mas piores em relatar sua própria confiança. Isso se traduz em boa precisão ao julgar aprovação/reprovação, mas sem escrutínio em termos de quão perto o julgamento estava da fronteira de decisão. Curiosamente, no entanto, descobrimos que para os exemplos em que o PGRM tem menos confiança, o GPT-4o também é menos preciso. Isso é capturado na figura à direita. Isso sugere que o PGRM e o GPT-4o estão captando as mesmas fontes de ambiguidade ou dificuldade, mas apenas o PGRM torna esses casos identificáveis.
Isso não é apenas uma propriedade interessante do PGRM, mas introduz uma nova funcionalidade importante como juiz. Por um lado, pontuações de confiança bem calibradas permitem distinguir falhas óbvias em seu sistema de IA de casos limítrofes, facilitando a identificação de exemplos de alta prioridade para revisão adicional. Além disso, recalibrar o PGRM para ser mais conservador ou mais permissivo é simplesmente uma questão de escolher um limite de pontuação de passar/falhar que melhor se adapte à sua aplicação. Em contraste, como os LLMs não externalizam sua confiança, calibrá-los tem que ser feito no nível do prompt, exigindo ou engenharia de prompt adicional (mais difícil do que parece) ou demonstrações de poucos tiros (tornando-o ainda mais caro para rodar).
Avaliando a Qualidade do RM no RewardBench2
O PGRM nos permite olhar para o julgamento e a modelagem de recompensa como dois lados da mesma moeda. Em ambos os casos, estamos essencialmente tentando medir o quão boa é a resposta de uma IA, mas no caso da modelagem de recompensa, o ênfase está em medir essa qualidade com um alto grau de precisão. Em um alto nível, os RMs precisam ser capazes de trazer à tona a melhor resposta de um conjunto de candidatos. RewardBench2 é o último benchmark projetado para medir exatamente essa habilidade. No momento deste blog, o PGRM se classifica como o segundo modelo classificador sequencial geral e o quarto no geral entre todos os modelos no ranking do RewardBench2.
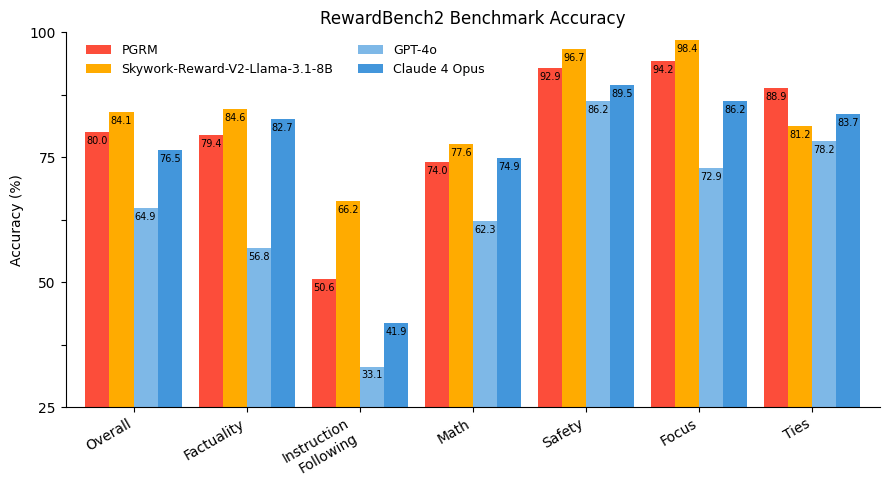
Este gráfico mostra o desempenho por subconjunto e geral de vários modelos no RewardBench2. O PGRM é competitivo com o Skywork-Reward-V2-Llama-3.1-8B, o modelo líder, e supera todos os outros modelos de classificadores sequenciais. Vale a pena enfatizar que o GPT-4o tem um desempenho ruim como um modelo de recompensa, demonstrando que LLMs como o GPT-4o simplesmente não são treinados para produzir pontuações bem calibradas. Eles são úteis para julgamento grosseiro (ou seja, passar/falhar), mas não são a ferramenta certa para o trabalho quando você precisa de algo mais refinado.
O que vem a seguir
Ao reunir modelagem de recompensa e julgamento, o PGRM nos permite pedir mais de cada um. Ajuste fino baseado em RM com recompensas adaptadas às suas necessidades específicas, substituindo noções genéricas de "boas respostas" por aquelas que realmente refletem o que você se importa. Juízes que permitem que você monitore seus agentes de IA em escala. Modelos de proteção personalizáveis eficientes o suficiente para trabalhar com seus agentes online. O PGRM abre a porta para todas essas frentes.
Já estamos usando o PGRM para impulsionar nossa pesquisa e produtos. Por exemplo, dentro do Agent Bricks Custom LLM, usamos o PGRM como o modelo de recompensa ao fazer o ajuste fino do TAO. Então, graças ao PGRM, o Agent Bricks permite que você construa um modelo de alta qualidade que é otimizado para sua tarefa e diretrizes, mesmo sem dados rotulados. E esta é apenas uma das muitas aplicações que imaginamos.
O PGRM representa apenas o primeiro passo nessa direção e inspira uma nova agenda de pesquisa em modelagem de recompensa direcionável. Na Databricks, estamos ansiosos para expandir o PGRM em algumas direções empolgantes. Ao modificar a receita de treinamento, podemos ensinar o PGRM a realizar julgamentos de nível de token refinados, tornando-o uma ferramenta particularmente poderosa quando aplicado no momento da inferência, para guardrails, busca guiada por valor e muito mais! Além disso, estamos explorando maneiras de trazer o cálculo em tempo de teste para o próprio PGRM, na forma de arquiteturas inovadoras que combinam raciocínio e julgamento calibrado.
Se você está interessado em experimentar o PGRM para o seu caso de uso, preencha este formulário e nossa equipe entrará em contato.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.