Como a Zalando construiu uma base de dados unificada para IA e análise no Databricks
A Zalando separa a criação do consumo de dados, padroniza definições de métricas e habilita consultas confiáveis em linguagem natural em dashboards e IA.
por Fabian Halkivaha, Mukrram Ur Rahman, Maria Vedenina e Timur Yüre
- A Zalando construiu uma base de dados unificada na Databricks com Unity Catalog, Metric Views e Genie para governar dados, padronizar métricas e habilitar análises em linguagem natural.
- Eles centralizaram a lógica de negócios usando Metric Views (“métricas como código”), resolvendo definições inconsistentes de métricas entre dashboards, SQL e pipelines.
- Ao fundamentar o Genie nesta camada semântica, a Zalando entrega consultas confiáveis em linguagem natural, reduzindo o tempo para responder a novas perguntas e melhorando a confiança nos resultados.
Na Zalando, uma plataforma online líder na Europa para moda e lifestyle, orquestramos um ecossistema digital massivo que conecta mais de 50 milhões de clientes ativos com mais de 7.000 marcas e parceiros em toda a Europa. Cada interação do cliente (navegação, pedido, devolução, etc.) gera um pulso de dados que impulsiona nossas decisões, desde recomendações personalizadas até otimização logística.
Operar nessa escala traz um conjunto único de desafios. Nossa paisagem de dados é vasta e complexa, alimentada por uma arquitetura de microsserviços que transmite terabytes de eventos para nosso data lake central. Embora essa arquitetura nos permitisse escalar rapidamente, ela também tornou a governança desafiadora e obscureceu a distinção entre Dados Transacionais (operações comerciais do dia a dia) e Dados Analíticos (insights para tomada de decisão).
Por anos, buscamos uma abordagem distribuída para resolver isso, descentralizando a propriedade, para que as equipes de domínio (como "Pagamentos" ou "Logística") pudessem gerenciar seus próprios produtos de dados. Uma estrutura de governança centralizada é crucial nesse cenário para garantir uma carga gerenciável nas equipes e prevenir riscos de negócios. Além disso, sem uma camada unificada para definir a verdade, enfrentamos o desafio da divergência de métricas: Por que o painel de Marketing mostra uma "Receita Líquida" diferente do relatório Financeiro? Como as métricas vivem em silos, é difícil governá-las e garantir que sejam descobertas e confiáveis para reutilização ao longo de seu ciclo de vida.
Neste post, compartilharemos como a Zalando está alcançando isso, aproveitando toda a amplitude da Plataforma Databricks. Mergulharemos em como estamos construindo uma Camada Semântica Unificada que preenche a lacuna entre Dados Transacionais e Dados Analíticos. Especificamente, abordaremos:
- A Fundação: Como o Unity Catalog permite governança federada e compartilhamento seguro entre centenas de equipes.
- A Camada Semântica: Como o Unity Catalog Business Semantics, alimentado por Metric Views, nos permite definir a lógica de negócios uma vez e servi-la em todos os lugares.
- A Análise com IA Conversacional: Como aproveitamos a camada semântica através do Genie, uma interface alimentada por IA generativa que permite aos usuários consultar dados usando linguagem natural sem precisar de expertise em SQL, ajudando-nos a tomar decisões mais rápidas e baseadas em dados.
A Fundação – Democratizando a Governança com Unity Catalog
Para gerenciar nossa vasta paisagem de dados de forma eficaz, decidimos abandonar o controle de acesso centrado em recursos. Nesse modelo, cada novo conjunto de dados ou consumidor exigia funções IAM personalizadas, políticas de bucket S3 e tratamento de exceções. Mas identificamos desafios: as permissões estavam fragmentadas em milhares de recursos, eram difíceis de revisar e propensas a desvios. Portanto, mudamos para uma abordagem de governança baseada em identidade. As decisões de acesso são expressas como políticas reutilizáveis vinculadas a pessoas e grupos. Elas são avaliadas consistentemente em todos os conjuntos de dados e aplicadas centralmente. Isso torna o acesso mais fácil de operar, auditar e evoluir à medida que as equipes e os dados mudam. Construímos essa base usando o Databricks Unity Catalog e implementamos uma estrutura de controle de acesso federado sobre ela.
A Arquitetura
Projetamos um padrão de catálogo duplo que separa estritamente a criação de dados de seu consumo, garantindo que a agilidade não venha ao custo do controle:
- Catálogos Privados para Autonomia: Cada equipe de domínio cria seu próprio Catálogo Privado usando uma solução interna de autoatendimento. Dentro desse ambiente privado, a equipe pode criar esquemas, ingerir dados brutos e construir tabelas em seu próprio ritmo, sem esperar pela aprovação central. Isso serve como sua "fábrica", otimizada para desenvolvimento e iteração irrestritos. A única limitação que enfrentam é que todos os objetos criados aqui são acessíveis apenas pela própria equipe, mais um número limitado de contribuidores relacionados. Isso significa que os casos de uso construídos sobre esses catálogos não são destinados ao uso em toda a empresa.
- O Catálogo Compartilhado Central para Governança: Para casos de uso em que várias equipes em toda a empresa precisam usar esses conjuntos de dados, introduzimos um catálogo compartilhado central. Isso atua como o "showroom" de toda a empresa. Todos os dados compartilhados em toda a organização devem ser expostos aqui via Dynamic Views, onde ficam sob rigorosa governança central. No momento em que os dados chegam aqui, eles são instantaneamente descobertos através do Unity Catalog.
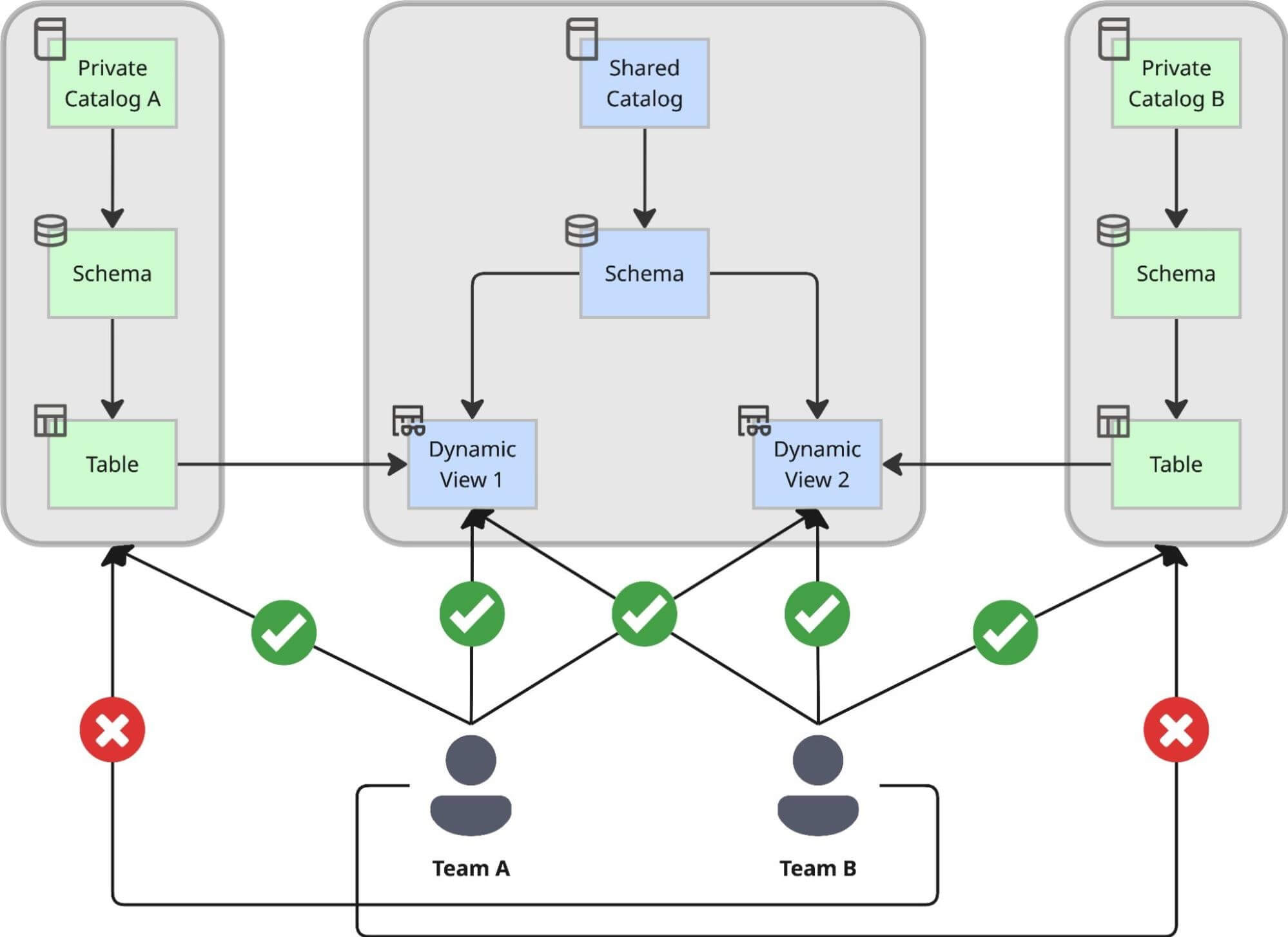
Por que Dynamic Views? Controle Centralizado e Auditabilidade
Tomamos a decisão estratégica de expor os dados no catálogo compartilhado exclusivamente via Dynamic Views, em vez de ponteiros diretos de tabela. Essa abordagem nos permite impor um processo de acesso centralizado capaz de lidar com regras de conformidade complexas.
Ao usar Dynamic Views como a camada de serviço, alcançamos:
- Regras de Processo Personalizadas para GDPR: Injetamos lógica personalizada diretamente na definição da view usando funções como is_account_group_member(). Isso garante um controle de acesso robusto, verificando se os usuários atendem aos requisitos antitruste e estão autorizados a acessar dados confidenciais (como email).
- Acesso Interno Padrão em Conformidade: Devido a um processo de classificação automatizado, cada coluna é classificada. Todas as colunas não confidenciais são acessíveis a uma ampla variedade de usuários por padrão, o que acelera a democratização de dados e a tomada de decisões.
- Auditabilidade Completa: Como todo o acesso entre equipes flui através dessas views gerenciadas centralmente, mantemos um rastro de auditoria completo das decisões de acesso. Sabemos exatamente qual política concedeu a um usuário acesso a uma linha ou coluna específica.
- Insights Confiáveis: Para evitar a geração de dados incorretos ou números enganosos devido a agregação parcial, qualquer consulta que tente acessar uma coluna sensível sem a autorização específica necessária falhará explicitamente com um erro de permissão negada.
Governança como Código: O Fluxo de Trabalho de Compartilhamento
Para manter esse processo eficiente, automatizamos o fluxo de trabalho de compartilhamento usando uma abordagem GitOps:
- Pull Request para Compartilhar: Quando uma equipe está pronta para compartilhar um conjunto de dados de seu catálogo privado para o catálogo compartilhado, ela não abre um ticket. Ela abre um Pull Request (PR) em um repositório central com um arquivo de configuração apontando para sua tabela de origem.
- Regras de Aprovação: O Pull Request é verificado quanto aos critérios de compartilhamento, exclusividade e outros fatores importantes de decisão.
- Validação e Provisionamento Automatizados: Assim que o PR é aprovado e mesclado, nosso serviço de plataforma gera automaticamente a Dynamic View correspondente no catálogo compartilhado central e classifica automaticamente as colunas.
Essa configuração nos permite manter a agilidade das equipes distribuídas, ao mesmo tempo em que aplicamos um padrão de governança centralizado e totalmente auditável que mantém nossos dados facilmente descobertos, seguros e em conformidade.
A Camada Semântica – Definindo "A Verdade" com Metric Views
Com a base segura que estabelecemos para acessar dados, agora estamos focados em garantir a interpretação consistente dos dados.
Estamos centralizando ativamente a lógica de negócios que antes era fragmentada em toda a pilha de dados:
- Ferramentas de BI: Definições de métricas incorporadas em painéis individuais
- Scripts SQL: Lógica duplicada em notebooks e pipelines
- Tabelas Materializadas: Métricas pré-computadas vinculadas a casos de uso específicos
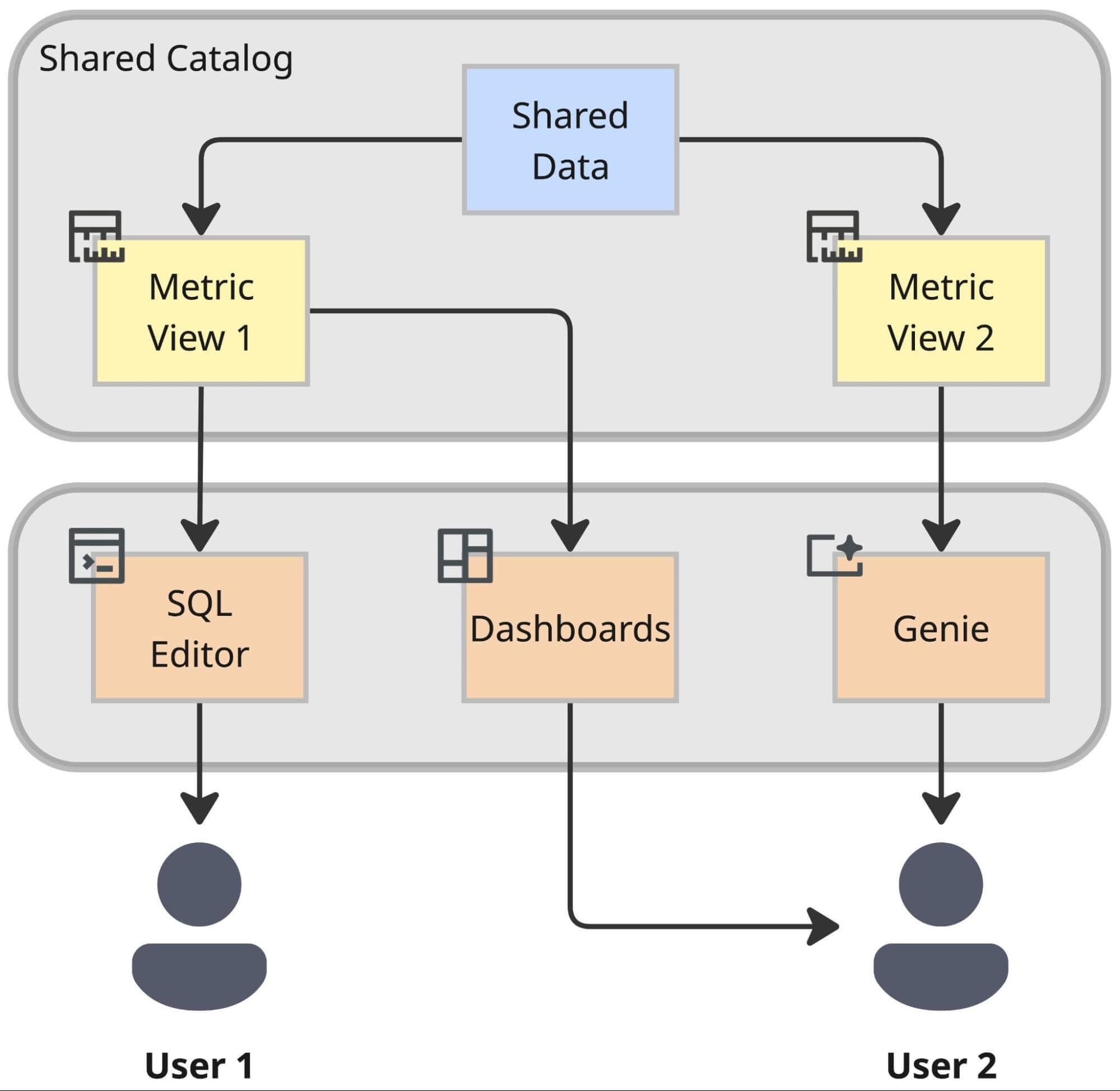
Estamos unificando milhares de definições de métricas em uma única camada governada. Isso nos permite quebrar o "aprisionamento de lógica": a definição de "Valor Bruto de Mercadoria" (NMV) em uma ferramenta de dashboarding se torna totalmente acessível a um cientista de dados trabalhando em um notebook ou a um bot de IA respondendo à pergunta de um usuário.
Para alcançar isso, estamos adotando as Databricks Metric Views como nossa camada semântica unificada. Isso desacopla decisivamente a definição de uma métrica de seu consumo, garantindo que os usuários recebam exatamente o mesmo resultado calculado, quer consultem via um editor SQL, um dashboard ou um agente de IA. Na prática, isso garante que tanto usuários técnicos quanto não técnicos usem as mesmas definições de métricas.
Métrica como Código: O Ciclo de Vida da Métrica
Implementamos uma abordagem rigorosa de "Métrica como Código" em nossa camada semântica, assim como utilizamos GitOps para compartilhamento de dados no Unity Catalog. Garantimos a consistência entre todas as equipes centralizando e padronizando cada definição de KPI.
Nossa arquitetura gerencia todo o ciclo de vida de uma métrica:
- Definição em YAML: As métricas são definidas em código (arquivos YAML) armazenados em um repositório central. Isso captura não apenas a lógica de agregação (por exemplo, SUM(amount)) e as relações entre tabelas, fatos e métricas, mas também metadados críticos como propriedade, descrição e formatação.
- Validação Automatizada: Antes que uma métrica possa ser mesclada à produção, nosso pipeline de CI/CD executa um conjunto de verificações automatizadas. Estas incluem:
- Unicidade: Garantir que nenhuma métrica com o mesmo nome ou definição já exista.
- Conformidade: Aplicar convenções de nomenclatura (por exemplo, snake_case) para garantir a descoberta.
- Propriedade: Verificar se um ID de equipe válido está associado à métrica para responsabilidade.
- Humano no loop: Através do princípio dos 4 olhos, cada Pull Request é revisado por especialistas do domínio.
- Ambientes de Desenvolvimento Individuais: Para permitir que as equipes iterem rapidamente, mas ainda testem em um ambiente muito próximo da produção, cada Pull Request implanta as Metric Views em um ambiente de teste separado. Essa configuração possibilita verificar as implicações da mudança imediatamente.
Construindo um Esquema Estrela para o Lakehouse
Por baixo dos panos, confiamos em princípios estabelecidos de modelagem dimensional. Cada Metric View em nosso ambiente de produção atua como uma interface padrão, geralmente mapeando 1 para 1 com nossas tabelas de Fatos, enquanto herda atributos de tabelas de Dimensão conformadas.
Essa configuração é crucial para nossa escala. Ao impor que as Metric Views sejam construídas sobre os dados confiáveis em nosso Shared Catalog (da Seção 1), garantimos que a camada semântica herde todos os benefícios de segurança e conformidade da plataforma subjacente. Um usuário consultando uma view de métrica ainda está sujeito à mesma segurança em nível de linha e coluna, e às regras de acesso que definimos na camada Unity Catalog. Também aprimoraremos essa configuração ainda este ano com uma camada de autorização adicional via Metric Views, para que os usuários não precisem mais de acesso a dados brutos, mas apenas acesso em nível de métrica e dimensão.
O Resultado: Interoperabilidade
O retorno dessa arquitetura é a interoperabilidade. Ao extrair a lógica de negócios de ferramentas proprietárias de BI para a camada semântica do Lakehouse, nos preparamos para o futuro. Uma métrica definida uma vez nesta camada torna-se instantaneamente disponível para:
- Databricks Dashboards para relatórios padrão.
- Genie para análise alimentada por IA em uma interface conversacional usando linguagem natural.
- Ferramentas e Aplicações Externas via conectores padronizados.
Essa centralização é a chave para nosso próximo grande passo: capacitar o negócio a "conversar" com seus dados.
Análise Conversacional Alimentada por IA
Dashboards são essenciais para responder a perguntas cotidianas e recorrentes. No entanto, a velocidade dos negócios muitas vezes supera a capacidade de relatórios padrão de capturar tudo. Por exemplo, um Gerente de Categoria pode precisar saber: "Quais marcas de tênis tiveram uma alta taxa de cliques, mas não entraram no top 10 por número de itens vendidos na Alemanha na semana passada?" Responder a perguntas novas como essa, não abordadas por relatórios padrão existentes, frequentemente exigia a construção de um novo dashboard. Mesmo com ferramentas de autoatendimento, uma lacuna significativa de "tempo para insight" persistia. Os usuários precisavam encontrar o conjunto de dados correto, configurar widgets e aplicar filtros antes de obterem uma resposta. Isso frequentemente resultava em dashboards pontuais, contribuindo para a proliferação de dashboards e a redução da descoberta.
Para otimizar a experiência do usuário, avaliamos várias soluções de "Falar com Dados" que oferecem interfaces conversacionais com LLM, frequentemente chamadas de chatbots de IA. O Genie teve o melhor desempenho porque está fundamentado em uma camada semântica unificada, enquanto soluções sem essa camada lutavam para gerar SQL preciso para lógica de negócios complexa.
É por isso que a introdução das Metric Views se mostrou instrumental para análises conversacionais alimentadas por IA como o Genie. Ao direcionar o Genie para as Metric Views pré-estabelecidas (conforme detalhado na Seção 2), alcançamos um avanço crítico: respostas consistentes e confiáveis fundamentadas em definições de negócios governadas.
Por que Metric Views aumenta drasticamente a precisão da IA
A maior barreira para a adoção de IA em análises é a confiança. Se um LLM alucinar uma consulta SQL, os números estarão errados e os usuários perderão a fé.
O Genie resolve isso trabalhando com nossa camada semântica em Metric Views.
- Sem Adivinhação: Quando um usuário pede "NMV" (Net Merchandise Value), o Genie não tenta calculá-lo a partir de tabelas brutas. Ele reconhece "NMV" como uma métrica governada em nossa view de métricas e simplesmente consulta a lógica pré-definida. Assim, a view de métricas reduz a complexidade de gerar uma instrução SQL, levando a uma maior precisão.
- Ciente do Contexto: Investimos pesadamente no enriquecimento de nossos metadados do Unity Catalog, adicionando descrições, sinônimos e exemplos de consultas. O Genie usa esse contexto para entender que, quando um usuário diz "Cancelamentos", ele especificamente se refere a pedidos cancelados antes do envio, correspondendo à nossa definição interna.
Capacitando a Linha de Frente
Testamos o Genie com equipes não técnicas, como Merchandisers, Compradores e Analistas de Preços, que historicamente dependiam de exportações do Excel ou ferramentas de BI. O feedback foi imediato: os usuários conseguiam obter respostas rápidas para perguntas granulares (por exemplo, desempenho específico de mercado combinado com tipo de dispositivo específico) sem precisar saber uma única linha de SQL ou gastar tempo construindo uma view de relatório personalizada.
A introdução do novo Modo Agente aprimorou significativamente a experiência do usuário. O Modo Agente analisa automaticamente os dados para identificar a causa raiz dos resultados da análise, permitindo que os usuários simplesmente perguntem "por que" algo aconteceu. Na Zalando, isso poderia reduzir o tempo de preparação para nossas reuniões regulares de desempenho — onde decisões críticas de direcionamento são tomadas — de várias horas para apenas alguns minutos.
No entanto, com sua extensa funcionalidade, o Genie também pode se tornar caro se não for configurado corretamente, por exemplo, em tabelas e visualizações não agregadas. É por isso que é fundamental curar cuidadosamente os dados e o contexto que o Genie usa. Além disso, reconhecemos o potencial para aprimoramento adicional, como o benefício de introduzir o controle de versão completo do Genie e permitir atualizações programáticas para as configurações do Genie, nas quais a Databricks já está trabalhando e que atualmente já são parcialmente suportadas.
Escalando o Genie para Adoção Empresarial
Não estamos tratando o Genie apenas como um experimento de sandbox; estamos integrando-o em nossas operações empresariais. Nossas áreas de foco para escalonamento incluem:
- Estabelecendo Governança: Espaços Genie curados serão sustentados por Metric Views governadas e devidamente mantidas.
- Garantindo a Confiabilidade dos Dados: Estamos colaborando com as equipes proprietárias de dados para estabelecer espaços Genie curados. Esses espaços oferecerão representações analíticas de seus dados por meio de Metric Views, garantindo que a qualidade dos dados seja mantida pelos próprios proprietários dos dados.
- Integrando com Agent Bricks ou usando Genies no Databricks One: Planejamos orquestrar esses espaços Genie curados usando Agent Bricks ou usando Genies dentro do Databricks One. Essa abordagem garante que os usuários tenham um ponto de entrada único e unificado para todas as suas consultas de dados.
Ao combinar a governança do Unity Catalog, a padronização da lógica de negócios por meio de Metric Views e a inteligência do Genie, estamos construindo uma cultura de dados onde "perguntar aos dados" é tão fácil quanto perguntar a um colega.
Obrigado a Merve Karali, Tobias Efinger e Roberto Bruno Martins por contribuírem para esta postagem.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.