Melhorando o Desempenho do Text2SQL com Facilidade no Databricks
por Matthew Hayes, Evion Kim, Linqing Liu, Alnur Ali, Ritendra Datta e Sam Shah
Quer colocar seu LLM entre os 10 melhores do Spider, um benchmark amplamente utilizado para tarefas de text-to-SQL? O Spider avalia o quão bem os LLMs conseguem converter consultas de texto em código SQL.
Para quem não está familiarizado com text-to-SQL, sua importância reside em transformar a forma como as empresas interagem com seus dados. Em vez de depender de especialistas em SQL para escrever consultas, as pessoas podem simplesmente fazer perguntas aos seus dados em linguagem natural e receber respostas precisas. Isso democratiza o acesso aos dados, aprimora a inteligência de negócios e permite uma tomada de decisão mais informada.
O benchmark Spider é um padrão amplamente reconhecido para avaliar o desempenho de sistemas text-to-SQL. Ele desafia os LLMs a traduzir consultas em linguagem natural em instruções SQL precisas, exigindo um profundo entendimento dos esquemas de banco de dados e a capacidade de gerar código SQL sintática e semanticamente correto.
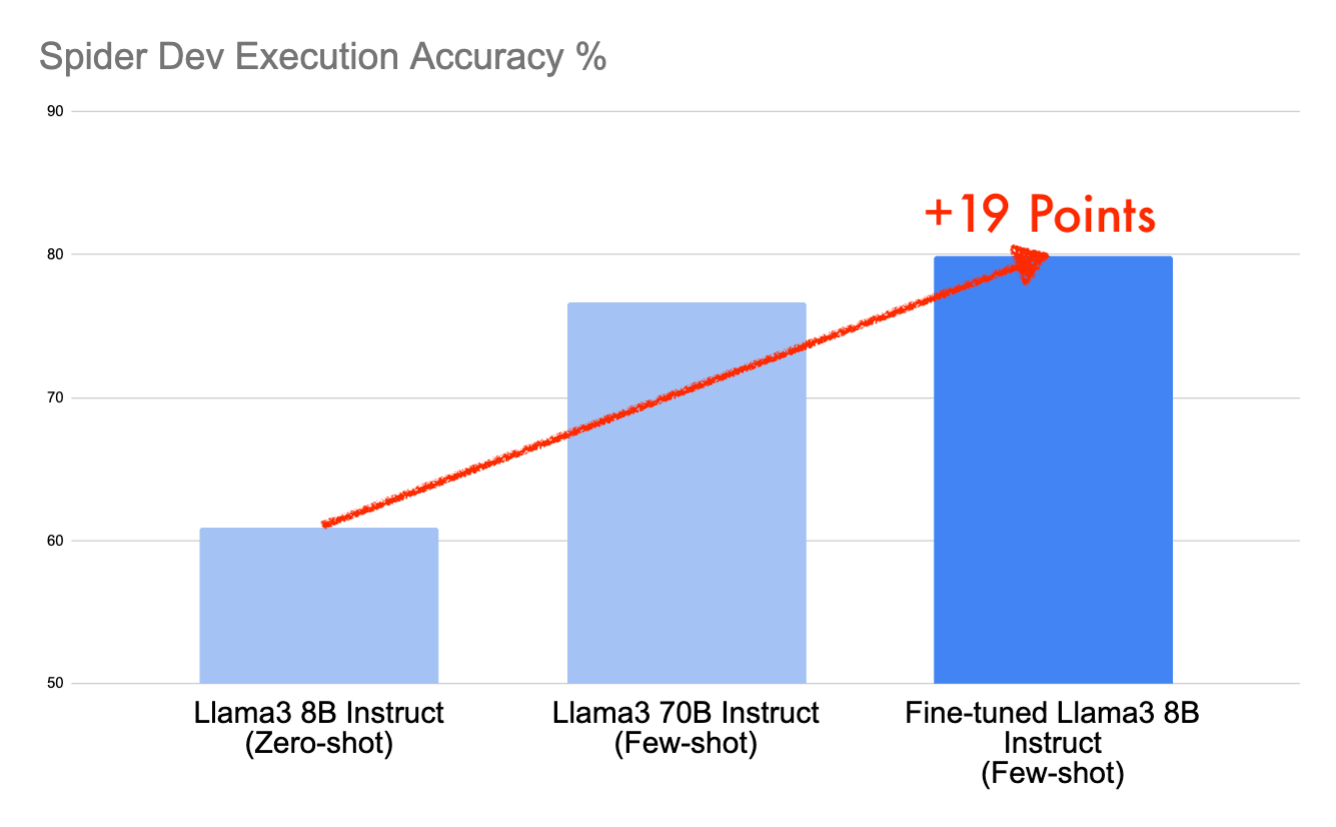
Neste post, vamos detalhar como alcançamos pontuações de 79,9% no conjunto de desenvolvimento do Spider e 78,9% no conjunto de teste em menos de um dia de trabalho usando o modelo open-source Llama3 8B Instruct – uma notável melhoria de 19 pontos em relação ao baseline. Esse desempenho nos colocaria entre os 10 primeiros no leaderboard do Spider, agora congelado, graças a prompts estratégicos e fine-tuning no Databricks.
Prompting Zero-shot para Desempenho Baseline
Vamos começar avaliando o desempenho do Meta Llama 3 8B Instruct no conjunto de desenvolvimento do Spider usando um formato de prompt muito simples, consistindo nas instruções CREATE TABLE que criaram as tabelas e uma pergunta que gostaríamos de responder usando essas tabelas:
Esse tipo de prompt é frequentemente chamado de "zero-shot", pois não há outros exemplos no prompt. Para a primeira pergunta no conjunto de desenvolvimento do Spider, este formato de prompt produz:
Executar o benchmark Spider no conjunto de desenvolvimento usando este formato produz uma pontuação geral de 60,9 quando medida por precisão de execução e decodificação greedy. Isso significa que, em 60,9% das vezes, o modelo produz um SQL que, ao ser executado, gera os mesmos resultados de uma consulta "gold" que representa a solução correta.
| Fácil | Médio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Zero-shot | 78,6 | 69,3 | 42,5 | 31,3 | 60,9 |
Com a pontuação baseline estabelecida, antes mesmo de entrarmos no fine-tuning, vamos tentar diferentes estratégias de prompting para tentar aumentar a pontuação do modelo base no conjunto de dados de benchmark do Spider.
Prompting com Amostras de Linhas
Uma das desvantagens do primeiro prompt que usamos é que ele não inclui nenhuma informação sobre os dados nas colunas, além do tipo de dado. Um artigo sobre a avaliação das capacidades text-to-SQL de modelos com o Spider descobriu que adicionar amostras de linhas ao prompt levava a uma pontuação maior, então vamos tentar isso.
Podemos atualizar o formato do prompt acima para que as consultas CREATE TABLE também incluam as primeiras linhas de cada tabela. Para a mesma pergunta de antes, agora temos um prompt atualizado:
Incluir amostras de linhas para cada tabela aumenta a pontuação geral em cerca de 6 pontos percentuais, para 67,0:
| Fácil | Médio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Zero-shot com amostras de linhas | 80,6 | 75,3 | 51,1 | 41,0 | 67,0 |
Prompting Few-shot
O prompting few-shot é uma estratégia bem conhecida usada com LLMs, onde podemos melhorar o desempenho em uma tarefa, como gerar SQL correto, incluindo alguns exemplos que demonstram a tarefa a ser executada. Com um prompt zero-shot, fornecemos os esquemas e, em seguida, fizemos uma pergunta. Com um prompt few-shot, fornecemos alguns esquemas, uma pergunta, o SQL que responde a essa pergunta e, em seguida, repetimos essa sequência algumas vezes antes de chegar à pergunta real que queremos fazer. Isso geralmente resulta em um desempenho melhor do que um prompt zero-shot.
Uma boa fonte de exemplos que demonstram a tarefa de geração de SQL é, na verdade, o próprio conjunto de treinamento do Spider. Podemos pegar uma amostra aleatória de algumas perguntas deste conjunto de dados com suas tabelas correspondentes e construir um prompt few-shot demonstrando o SQL que pode responder a cada uma dessas perguntas. Como estamos usando amostras de linhas a partir do prompt anterior, também devemos garantir que um desses exemplos inclua amostras de linhas para demonstrar seu uso.
Outra melhoria que podemos fazer no prompt zero-shot anterior é incluir também um "system prompt" no início. System prompts são tipicamente usados para fornecer orientação detalhada ao modelo, delineando a tarefa a ser executada. Enquanto um usuário pode fazer várias perguntas ao longo de uma conversa com um modelo, o system prompt é fornecido apenas uma vez antes que o usuário faça uma pergunta, essencialmente estabelecendo expectativas sobre como o "sistema" deve se comportar durante a conversa.
Com essas estratégias em mente, podemos construir um prompt few-shot que também começa com uma mensagem do sistema representada como um grande bloco de comentários SQL no topo, seguido por três exemplos:
Este novo prompt resultou em uma pontuação de 70,8, que é outra melhoria de 3,8 pontos percentuais em relação à nossa pontuação anterior. Aumentamos a pontuação em quase 10 pontos percentuais em relação ao ponto de partida, apenas através de estratégias simples de prompting.
| Fácil | Médio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Few-shot com amostras de linhas | 83,9 | 79,1 | 55,7 | 44,6 | 70,8 |
Provavelmente estamos chegando ao ponto de retornos decrescentes ao ajustar nosso prompt. Vamos fazer o fine-tuning do modelo para ver quais ganhos adicionais podem ser feitos.
Ajuste Fino com LoRA
Se estivermos ajustando o modelo, a primeira pergunta é quais dados de treinamento usar. O Spider inclui um conjunto de dados de treinamento, então este parece um bom lugar para começar. Para ajustar o modelo, usaremos QLoRA para que possamos treinar o modelo de forma eficiente em um único cluster de GPU Databricks A100 80GB, como o Standard_NC24ads_A100_v4 no Databricks. Isso pode ser concluído em cerca de quatro horas usando os 7 mil registros do conjunto de dados de treinamento Spider. Discutimos anteriormente o ajuste fino com LoRA em um post de blog anterior. Leitores interessados podem consultar esse post para mais detalhes. Podemos seguir receitas de treinamento padrão usando as bibliotecas trl, peft e bitsandbytes.
Embora estejamos obtendo os registros de treinamento do Spider, ainda precisamos formatá-los de uma maneira que o modelo possa aprender. O objetivo é mapear cada registro, consistindo no esquema (com linhas de exemplo), pergunta e SQL em uma única string de texto. Começamos realizando algum processamento no conjunto de dados bruto do Spider. Dos dados brutos, produzimos um conjunto de dados onde cada registro consiste em três campos: schema_with_rows, question e query. O campo schema_with_rows é derivado das tabelas correspondentes à pergunta, seguindo a formatação da instrução CREATE TABLE e as linhas usadas no prompt few-shot anterior.
Em seguida, carregue o tokenizer:
Definiremos uma função de mapeamento que converterá cada registro do nosso conjunto de dados de treinamento Spider processado em uma string de texto. Podemos usar apply_chat_template do tokenizer para formatar convenientemente o texto no formato de chat esperado pelo modelo Instruct. Embora este não seja exatamente o mesmo formato que estamos usando para nosso prompt few-shot, o modelo generaliza bem o suficiente para funcionar mesmo que a formatação boilerplate dos prompts seja ligeiramente diferente.
Para SYSTEM_PROMPT, usamos o mesmo prompt do sistema usado no prompt few-shot anterior. Para USER_MESSAGE_FORMAT, usamos de forma semelhante:
Com esta função definida, tudo o que resta é transformar o conjunto de dados Spider processado com ela e salvá-lo como um arquivo JSONL.
Estamos prontos para treinar. Algumas horas depois, temos um Llama3 8B Instruct ajustado. Reexecutar nosso prompt few-shot neste novo modelo resultou em uma pontuação de 79.9, que é uma melhoria de mais 9 pontos percentuais em relação à nossa pontuação anterior. Agora aumentamos a pontuação total em ~19 pontos percentuais em relação à nossa linha de base zero-shot simples.
| Fácil | Médio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Few-shot com linhas de exemplo (Llama3 8B Instruct Ajustado) |
91.1 | 85.9 | 72.4 | 54.8 | 79.9 |
| Few-shot com linhas de exemplo (Llama3 8B Instruct) |
83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
| Zero-shot com linhas de exemplo (Llama3 8B Instruct) |
80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
| Zero-shot (Llama3 8B Instruct) |
78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Você pode estar se perguntando agora como o modelo Llama3 8B Instruct e sua versão ajustada se comparam a um modelo maior como o Llama3 70B Instruct. Repetimos o processo de avaliação usando o modelo 70B pronto para uso no conjunto de dados dev com oito GPUs A100 de 40 GB e registramos os resultados abaixo.
| Few-shot com linhas de exemplo (Llama3 70B Instruct) |
89.5 | 83.0 | 64.9 | 53.0 | 76.7 |
| Zero-shot com linhas de exemplo (Llama3 70B Instruct) |
83.1 | 81.8 | 59.2 | 36.7 | 71.1 |
| Zero-shot (Llama3 70B Instruct) |
82.3 | 80.5 | 57.5 | 31.9 | 69.2 |
Como esperado, comparando os modelos prontos para uso, o modelo 70B supera o modelo 8B quando medido usando o mesmo formato de prompt. Mas o surpreendente é que o modelo Llama3 8B Instruct ajustado pontua mais alto que o modelo Llama3 70B Instruct por 3 pontos percentuais. Quando focado em tarefas específicas como text-to-SQL, o ajuste fino pode resultar em modelos pequenos que são comparáveis em desempenho com modelos muito maiores em tamanho.
Implantar em um Endpoint de Serviço de Modelo
O Llama3 é suportado pelo Databricks Model Serving, então poderíamos até implantar nosso modelo Llama3 ajustado em um endpoint e usá-lo para potencializar aplicações. Tudo o que precisamos fazer é registrar o modelo ajustado no Unity Catalog e, em seguida, criar um endpoint usando a interface do usuário. Uma vez implantado, podemos consultá-lo usando bibliotecas comuns.
Conclusão
Iniciamos nossa jornada com o Llama3 8B Instruct no conjunto de dados dev do Spider usando um prompt zero-shot, alcançando uma pontuação modesta de 60.9. Ao aprimorar isso com um prompt few-shot — completo com mensagens do sistema, múltiplos exemplos e linhas de exemplo — aumentamos nossa pontuação para 70.8. Ganhos adicionais vieram do ajuste fino do modelo no conjunto de dados de treinamento Spider, impulsionando-nos para impressionantes 79.9 no dev do Spider e 78.9 no teste do Spider. Essa subida significativa de 19 pontos em relação ao nosso ponto de partida e uma vantagem de 3 pontos sobre o Llama3 70B Instruct base não apenas demonstra a proeza do nosso modelo, mas também nos garantiria um lugar cobiçado entre os 10 melhores resultados no Spider.
Saiba mais sobre como alavancar o poder dos LLMs de código aberto e da Plataforma de Inteligência de Dados registrando-se no Data+AI Summit.
Apêndice
Configuração de Avaliação
A geração foi realizada usando vLLM, decodificação greedy (temperatura de 0), duas GPUs A100 de 80 GB e 1024 tokens máximos novos. Para avaliar as gerações, usamos a suíte de testes do repositório taoyds/test-suite-sql-eval no Github.
Configuração de Treinamento
Aqui estão os detalhes específicos sobre a configuração de ajuste fino:
| Modelo Base | Llama3 8B Instruct |
| GPUs | A100 80GB Única |
| Máximo de Passos | 100 |
| Registros do conjunto de dados de treinamento Spider | 7000 |
| LoRA R | 16 |
| LoRA Alpha | 32 |
| LoRA Dropout | 0.1 |
| Taxa de Aprendizagem | 1.5e-4 |
| Agendador de Taxa de Aprendizagem | Constante |
| Passos de Acumulação de Gradiente | 8 |
| Checkpointing de Gradiente | True |
| Tamanho do Lote de Treinamento | 12 |
| Módulos Alvo LoRA | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
| Modelo de Resposta do Data Collator | <|start_header_id|>assistente<|end_header_id|> |
Exemplo de Prompt Zero-shot
Este é o primeiro registro do conjunto de dados de desenvolvimento que usamos para avaliação, formatado como um prompt zero-shot que inclui os esquemas das tabelas. As tabelas às quais a pergunta se refere são representadas usando as instruções CREATE TABLE que as criaram.
Exemplo de Prompt Zero-shot com Linhas de Amostra
Este é o primeiro registro do conjunto de dados de desenvolvimento que usamos para avaliação, formatado como um prompt zero-shot que inclui os esquemas das tabelas e linhas de amostra. As tabelas às quais a pergunta se refere são representadas usando as instruções CREATE TABLE que as criaram. As linhas foram selecionadas usando "SELECT * {table_name} LIMIT 3" de cada tabela, com os nomes das colunas aparecendo como um cabeçalho.
Exemplo de Prompt Few-shot com Linhas de Amostra
Este é o primeiro registro do conjunto de dados de desenvolvimento que usamos para avaliação, formatado como um prompt few-shot que inclui os esquemas das tabelas e linhas de amostra. As tabelas às quais a pergunta se refere são representadas usando as instruções CREATE TABLE que as criaram. As linhas foram selecionadas usando "SELECT * {table_name} LIMIT 3" de cada tabela, com os nomes das colunas aparecendo como um cabeçalho.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.