Otimize Inteligente de Custos e Confiabilidade no Databricks
Explore a intersecção entre gestão financeira e computação em nuvem na Plataforma de Inteligência de Dados Databricks
por Vuong Nguyen e Wasim Ahmad
A Plataforma Databricks Data Intelligence oferece flexibilidade incomparável, permitindo que os usuários acessem recursos de computação escaláveis horizontalmente e quase instantaneamente. Essa facilidade de criação pode levar a custos de nuvem descontrolados se não forem gerenciados adequadamente.
Implemente a Observabilidade para Rastrear e Cobrar Custos
Como usar a observabilidade de forma eficaz para rastrear e cobrar custos no Databricks
Ao trabalhar com ecossistemas técnicos complexos, entender proativamente os desconhecidos é fundamental para manter a estabilidade da plataforma e controlar os custos. A observabilidade fornece uma maneira de analisar e otimizar sistemas com base nos dados que eles geram. Isso é diferente do monitoramento, que se concentra em identificar novos padrões em vez de rastrear problemas conhecidos.
Principais recursos para rastreamento de custos no Databricks
Tags: Use tags para categorizar recursos e cobranças. Isso permite uma alocação de custos mais granular.
Tabelas do Sistema: Utilize tabelas do sistema para rastreamento automatizado de custos e cobrança. Ferramentas nativas de nuvem para monitoramento de custos: Utilize essas ferramentas para obter insights sobre os custos em todos os recursos.
O que são Tabelas do Sistema e como usá-las
O Databricks oferece ótimos recursos de observabilidade usando Tabelas do Sistema. As Tabelas do Sistema são repositórios analíticos hospedados pelo Databricks dos dados operacionais de uma conta de cliente encontrados no catálogo do sistema. Elas fornecem observabilidade histórica em toda a conta e incluem informações tabulares fáceis de usar sobre a telemetria da plataforma. Insights chave como dados de uso de faturamento estão disponíveis nas tabelas do sistema (atualmente, isso inclui apenas o Preço de Lista de DBUs), com cada registro de uso representando um agregado horário do uso faturável de um recurso.
Como habilitar tabelas do sistema
As tabelas do sistema são gerenciadas pelo Unity Catalog e exigem um workspace habilitado para o Unity Catalog para acesso. Elas incluem dados de todos os workspaces, mas só podem ser consultadas a partir de workspaces habilitados. A habilitação das tabelas do sistema ocorre no nível do esquema - habilitar um esquema habilita todas as suas tabelas. Os administradores devem habilitar manualmente novos esquemas usando a API.

O que são tags do Databricks e como usá-las
A marcação do Databricks permite aplicar atributos (pares de chave-valor) a recursos para melhor organização, pesquisa e gerenciamento. Para rastreamento de custos e cobrança, as equipes podem marcar seus jobs e computação do Databricks (Clusters, SQL warehouse), o que pode ajudá-las a rastrear o uso, os custos e atribuí-los a equipes ou unidades específicas.
Como aplicar tags
As tags podem ser aplicadas aos seguintes recursos do Databricks para rastreamento de uso e custos:
- Computação Databricks
- Jobs Databricks
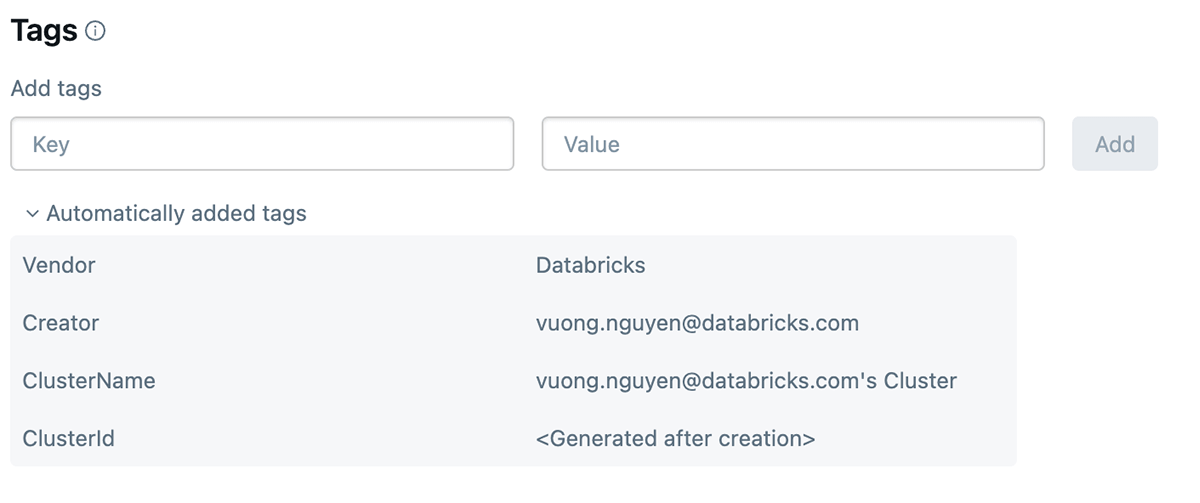
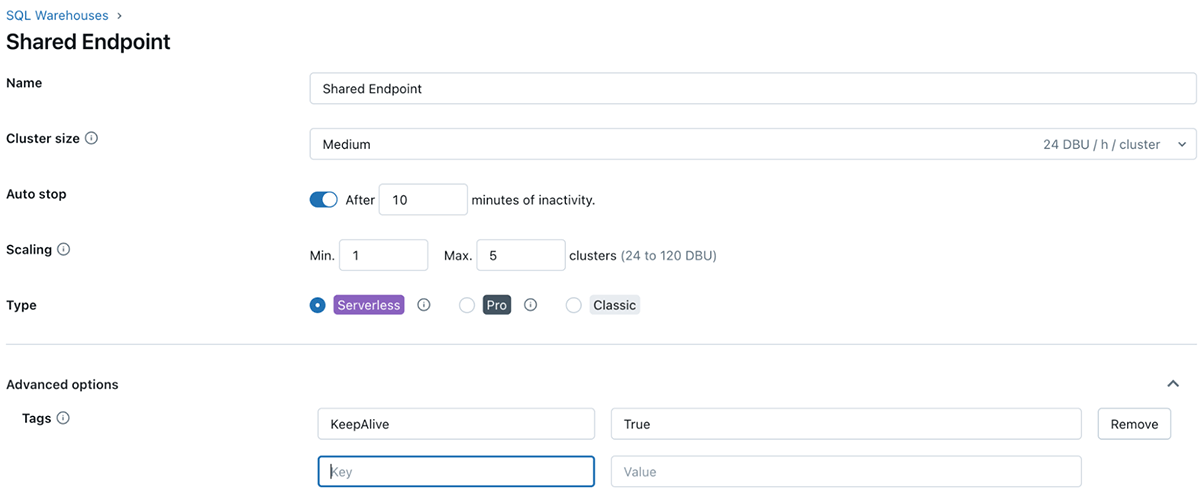
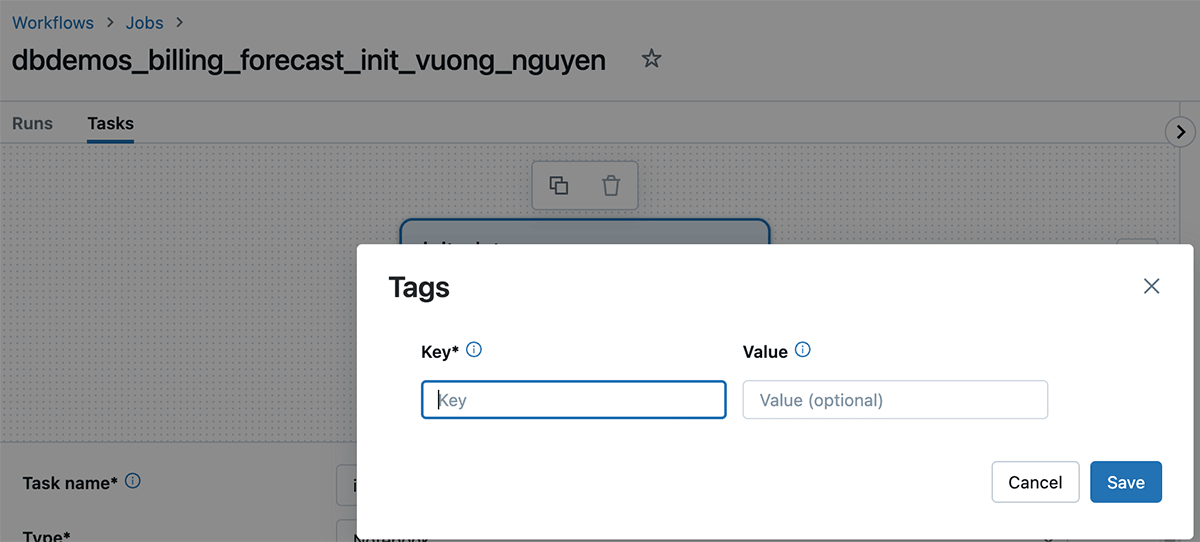
Uma vez que essas tags são aplicadas, análises detalhadas de custos podem ser realizadas usando as tabelas do sistema de uso faturável.
Como identificar custos usando ferramentas nativas da nuvem
Para monitorar custos e atribuir com precisão o uso do Databricks às unidades de negócios e equipes da sua organização (para cobrança, por exemplo), você pode marcar workspaces (e os grupos de recursos gerenciados associados), bem como recursos de computação.
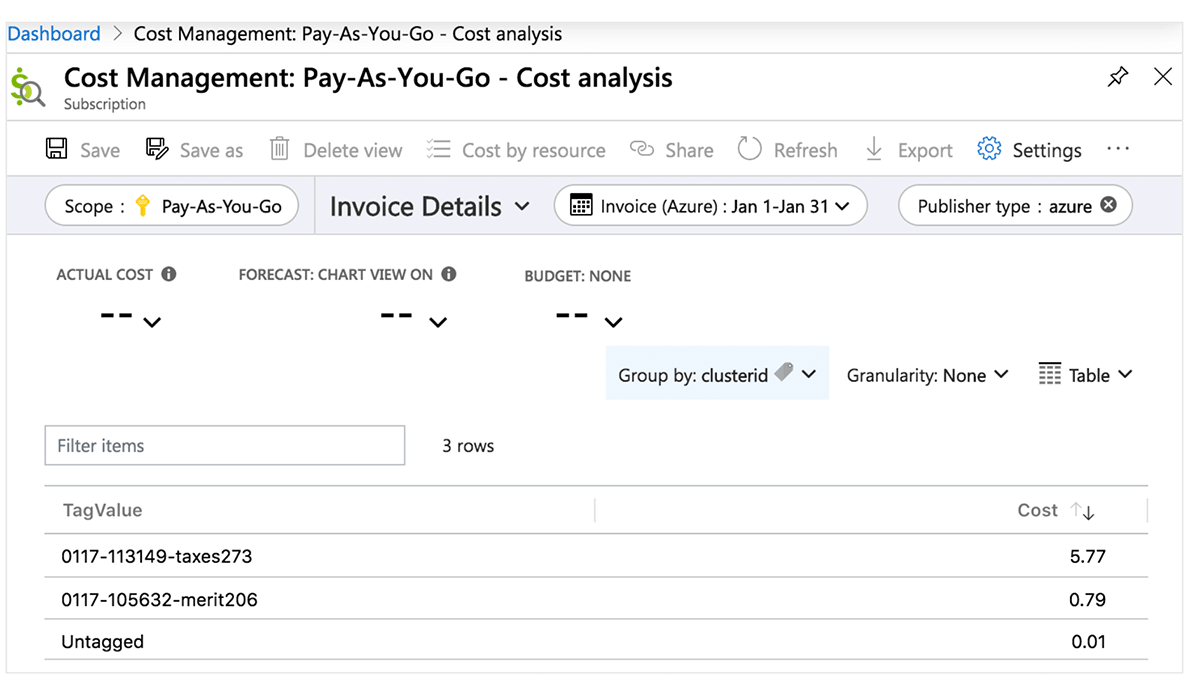
Centro de Custos do Azure
A tabela a seguir detalha os objetos do Azure Databricks onde as tags podem ser aplicadas. Essas tags podem se propagar para relatórios detalhados de análise de custos que você pode acessar no portal e para a tabela do sistema de uso faturável. Encontre mais detalhes sobre propagação e limitações de tags no Azure.
| Objeto do Azure Databricks | Interface de Marcação (UI) | Interface de Marcação (API) |
|---|---|---|
| Workspace | Portal do Azure | API de Recursos do Azure |
| Pool | UI de Pools no workspace do Azure Databricks | API de Instance Pool |
| Computação de propósito geral e de jobs | UI de Computação no workspace do Azure Databricks | API de Clusters |
| SQL Warehouse | UI de SQL warehouse no workspace do Azure Databricks | API de Warehouse |
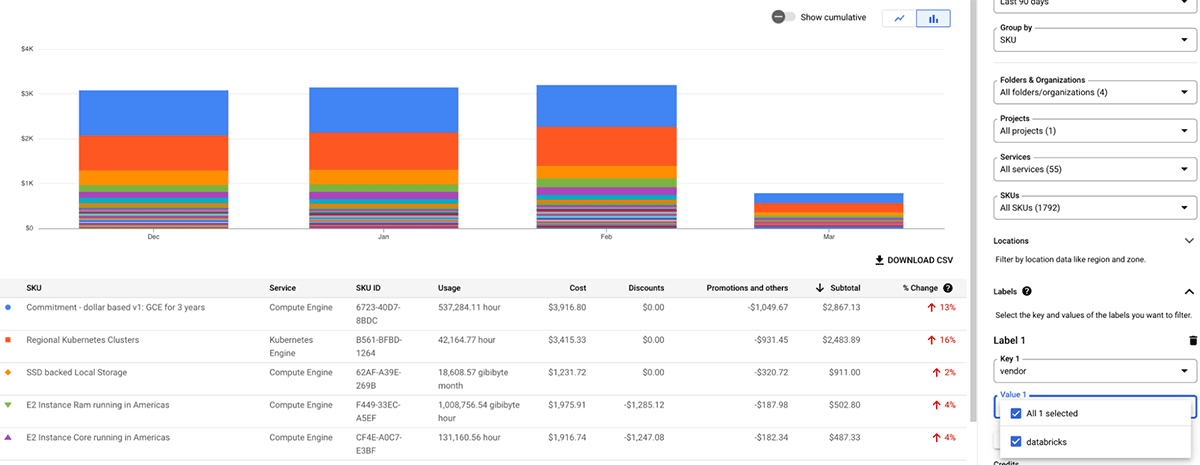
AWS Cost Explorer
A tabela a seguir detalha os Objetos Databricks da AWS onde as tags podem ser aplicadas. Essas tags podem se propagar para logs de uso e para instâncias AWS EC2 e AWS EBS para análise de custos. O Databricks recomenda o uso de tabelas do sistema (Prévia Pública) para visualizar dados de uso faturável. Encontre mais detalhes sobre propagação e limitações de tags na AWS.
| Objeto Databricks AWS | Interface de Marcação (UI) | Interface de Marcação (API) |
|---|---|---|
| Workspace | N/A | API de Conta |
| Pool | UI de Pools no workspace Databricks | API de Instance Pool |
| Computação de propósito geral e de jobs | UI de Computação no workspace Databricks | API de Clusters |
| SQL Warehouse | UI de SQL warehouse no workspace Databricks | API de Warehouse |
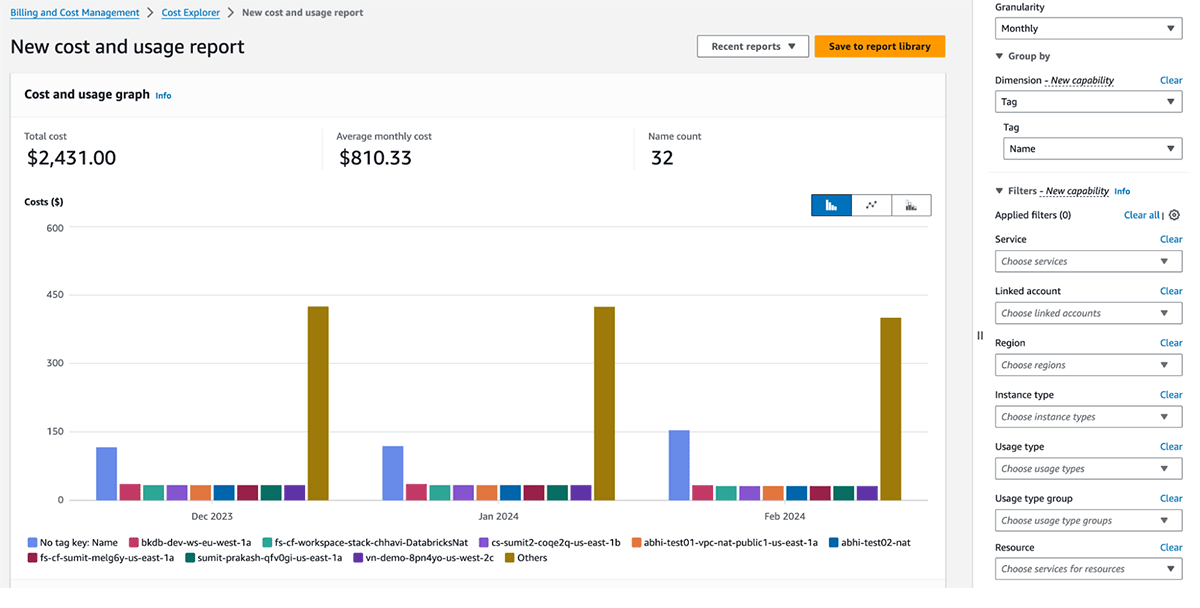
Gerenciamento de custos e faturamento do GCP
A tabela a seguir detalha os objetos do Databricks no GCP onde tags/rótulos podem ser aplicados. Esses tags/rótulos podem ser aplicados a recursos de computação. Encontre mais detalhes sobre a propagação e limitações de tags/rótulos no GCP.
Os gráficos de uso faturável do Databricks no console da conta podem agregar o uso por tags individuais. Os relatórios CSV de uso faturável baixados da mesma página também incluem tags padrão e personalizadas. As tags também se propagam para rótulos GKE e GCE.
| Objeto Databricks GCP | Interface de Marcação (UI) | Interface de Marcação (API) |
|---|---|---|
| Pool | UI de Pools no workspace Databricks | API de Instance Pool |
| Computação para todos os fins e trabalhos | Interface de computação no workspace Databricks | API de Clusters |
| SQL Warehouse | Interface do SQL warehouse no workspace Databricks | API de Warehouses |
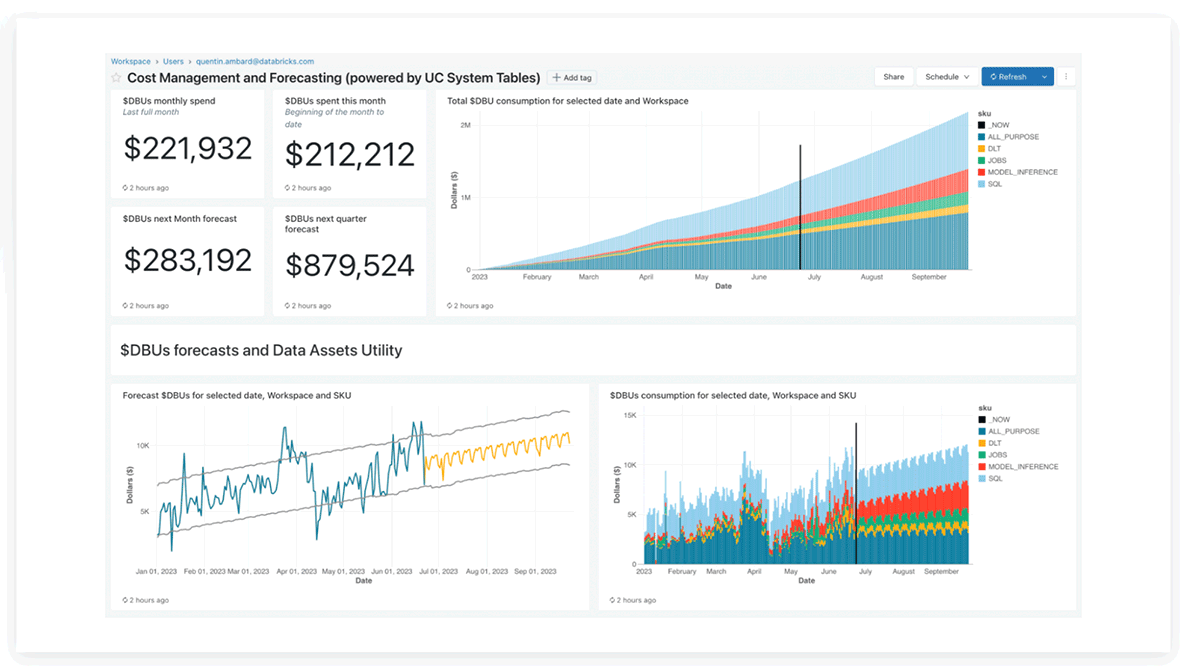
Painel do Lakeview de tabelas do sistema Databricks
A equipe de produtos Databricks forneceu painéis do Lakeview pré-criados para análise de custos e previsão usando tabelas do sistema, que os clientes também podem personalizar.
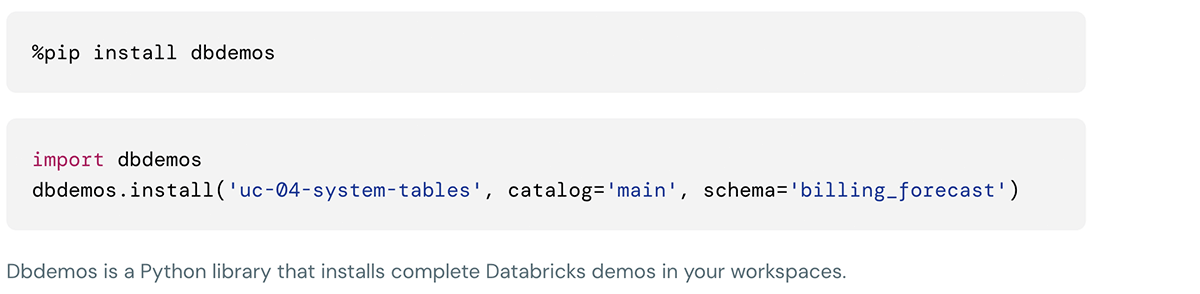
Esta demonstração pode ser instalada usando os seguintes comandos na célula de notebooks Databricks:
Melhores práticas para maximizar o valor
Ao executar cargas de trabalho no Databricks, escolher a configuração de computação correta melhorará significativamente as métricas de custo/desempenho. Abaixo estão algumas técnicas práticas de otimização de custos:
Usando o tipo de computação certo para o trabalho certo
Para cargas de trabalho SQL interativas, o SQL warehouse é o motor mais econômico. Ainda mais eficiente pode ser a computação Serverless, que vem com um tempo de inicialização muito rápido para SQL warehouses e permite um tempo de auto-terminação menor.
Para cargas de trabalho não interativas, os clusters de Jobs custam significativamente menos do que os clusters para todos os fins. Fluxos de trabalho multitarefa podem reutilizar recursos de computação para todas as tarefas, reduzindo ainda mais os custos.
Escolhendo o tipo de instância certo
Usar a geração mais recente de tipos de instância na nuvem quase sempre trará benefícios de desempenho, pois eles vêm com o melhor desempenho e os recursos mais recentes. Na AWS, as instâncias Amazon EC2 baseadas em Graviton2 podem oferecer até 3x melhor relação preço-desempenho do que instâncias Amazon EC2 comparáveis.
Com base em suas cargas de trabalho, também é importante escolher a família de instâncias correta. Algumas regras práticas são:
- Otimizado para memória para ML, cargas de trabalho com muitos embaralhamentos e derramamentos (shuffle & spill)
- Otimizado para computação para cargas de trabalho de Structured Streaming, trabalhos de manutenção (por exemplo, Optimize & Vacuum)
- Otimizado para armazenamento para cargas de trabalho que se beneficiam de cache, por exemplo, análise de dados ad-hoc e interativa
- Otimizado para GPU para cargas de trabalho específicas de ML e DL
- Uso geral na ausência de requisitos específicos
Escolhendo o Runtime Certo
O Databricks Runtime (DBR) mais recente geralmente vem com desempenho aprimorado e será quase sempre mais rápido que o anterior.
Photon é um motor de consulta vetorial nativo do Databricks de alto desempenho que executa suas cargas de trabalho SQL e chamadas de API DataFrame mais rapidamente para reduzir seu custo total por carga de trabalho. Para essas cargas de trabalho, habilitar o Photon pode trazer economias significativas.
Aproveitando a Escalabilidade Automática na Computação Databricks
O Databricks oferece um recurso exclusivo de escalabilidade automática de cluster, facilitando a obtenção de alta utilização do cluster, pois você não precisa provisionar o cluster para corresponder a uma carga de trabalho. Isso é particularmente útil para cargas de trabalho interativas ou cargas de trabalho em lote com carga de dados variável. No entanto, a escalabilidade automática clássica não funciona com cargas de trabalho de Structured Streaming, razão pela qual desenvolvemos a Escalabilidade Automática Aprimorada no Delta Live Tables para lidar com cargas de trabalho de streaming que são esporádicas e imprevisíveis.
Aproveitando Instâncias Spot
Todos os principais provedores de nuvem oferecem instâncias spot que permitem acessar capacidade não utilizada em seus data centers por até 90% menos do que as instâncias sob Demanda regulares. O Databricks permite que você aproveite essas instâncias spot, com a capacidade de fazer fallback para instâncias sob Demanda automaticamente em caso de término para minimizar interrupções. Para estabilidade do cluster, recomendamos o uso de nós de driver sob Demanda.
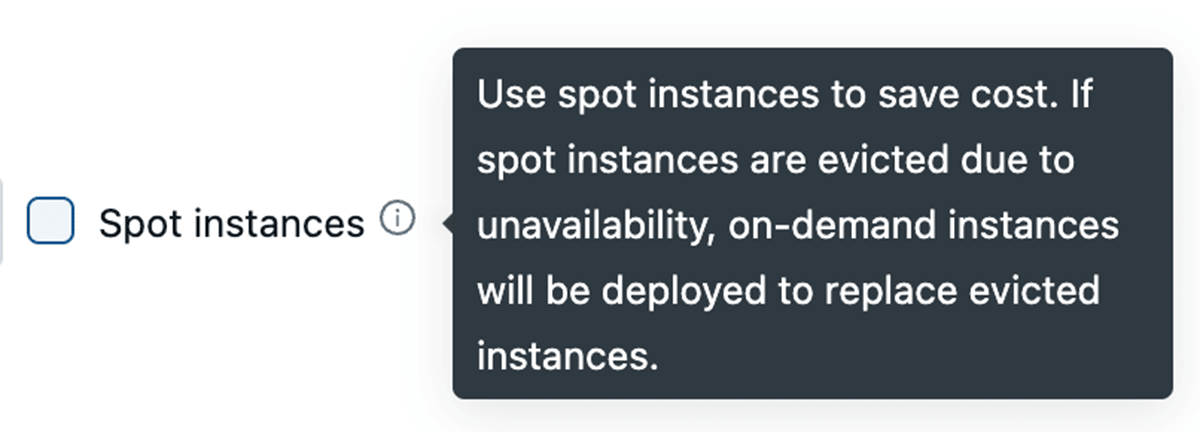
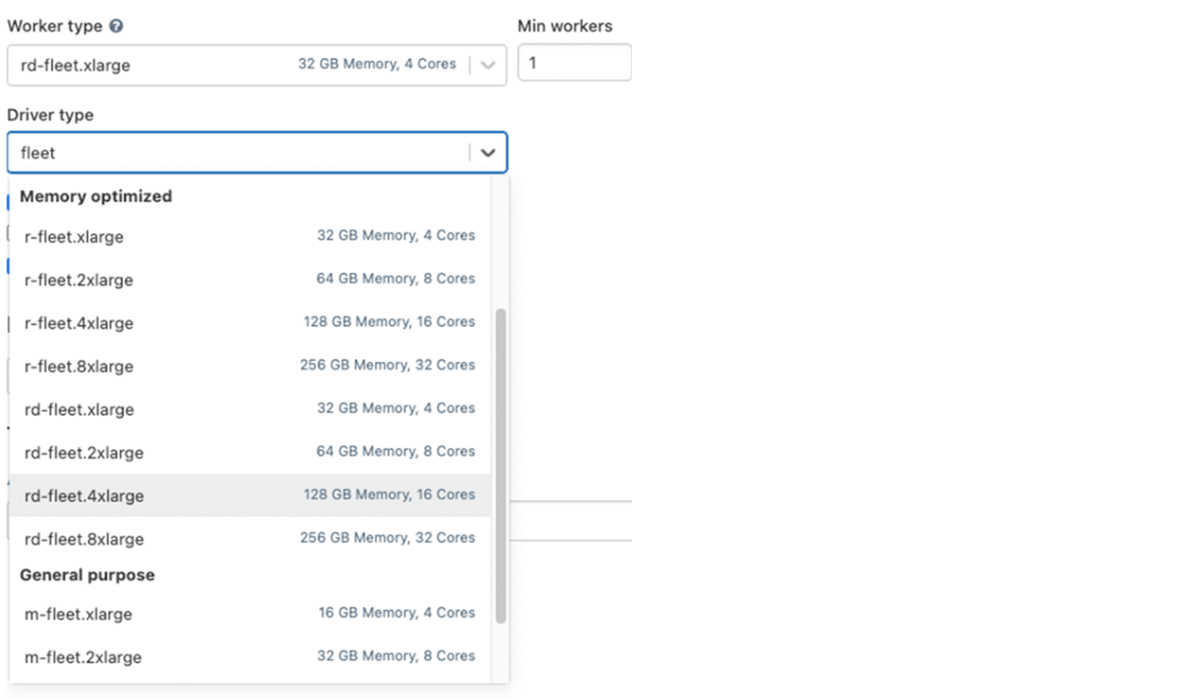
Aproveitando o tipo de instância Fleet (na AWS)
Por baixo dos panos, quando um cluster usa um desses tipos de instância fleet, o Databricks selecionará os tipos de instância física da AWS correspondentes com o melhor preço e disponibilidade para usar em seu cluster.
Política de Cluster
O uso eficaz de políticas de cluster permite que os administradores imponham restrições específicas de custo para os usuários finais:
- Habilite a auto-terminação do cluster com um valor razoável (por exemplo, 1 hora) para evitar o pagamento por tempos ociosos.
- Garanta que apenas instâncias de VM econômicas possam ser selecionadas
- Imponha tags obrigatórias para rateio de custos
- Controle o perfil de custo geral limitando o custo máximo por cluster, por exemplo, DBUs máximos por hora ou recursos de computação máximos por usuário
Otimização de Custos com IA
A Plataforma de Inteligência de Dados Databricks integra recursos avançados de IA que otimizam o desempenho, reduzem custos, melhoram a governança e simplificam o desenvolvimento de aplicações de IA empresariais. O I/O Preditivo e o Liquid Clustering aprimoram a velocidade das consultas e a utilização de recursos, enquanto o gerenciamento inteligente de cargas de trabalho otimiza a escalabilidade automática para eficiência de custos. No geral, a plataforma Databricks oferece um conjunto abrangente de ferramentas de IA para impulsionar a produtividade e a economia, ao mesmo tempo em que permite soluções inovadoras para casos de uso específicos da indústria.
Liquid Clustering
O liquid clustering do Delta Lake substitui o particionamento de tabelas e o ZORDER para simplificar as decisões de layout de dados e otimizar o desempenho das consultas. O liquid clustering oferece flexibilidade para redefinir chaves de cluster sem reescrever dados existentes, permitindo que o layout dos dados evolua junto com as necessidades analíticas ao longo do tempo.
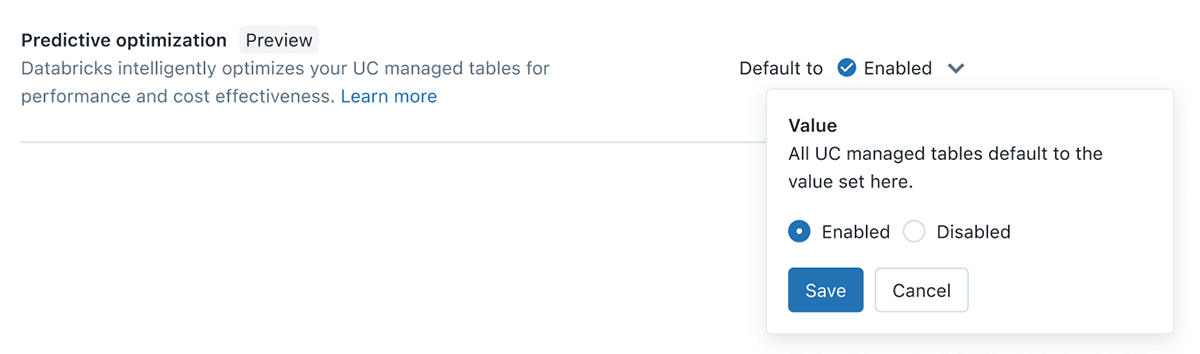
Otimização Preditiva
Engenheiros de dados no lakehouse estarão familiarizados com a necessidade de executar OPTIMIZE & VACUUM regularmente em suas tabelas, no entanto, isso cria desafios contínuos para descobrir as tabelas certas, o cronograma apropriado e o tamanho de computação correto para essas tarefas. Com a Otimização Preditiva, aproveitamos o Unity Catalog e o Lakehouse AI para determinar as melhores otimizações a serem realizadas em seus dados e, em seguida, executamos essas operações em infraestrutura serverless criada para esse fim. Tudo isso acontece automaticamente, garantindo o melhor desempenho sem desperdício de computação ou esforço manual de ajuste.
Visualização Materializada com Atualização Incremental
No Databricks, as Visualizações Materializadas (MVs) são tabelas gerenciadas pelo Unity Catalog que permitem aos usuários pré-calcular resultados com base na versão mais recente dos dados nas tabelas de origem. Construídas sobre o Delta Live Tables e serverless, as MVs reduzem a latência das consultas pré-calculando consultas lentas e computações frequentemente usadas. Sempre que possível, os resultados são atualizados incrementalmente, mas os resultados são idênticos aos que seriam entregues por um recálculo completo. Isso reduz o custo computacional e evita a necessidade de manter clusters separados
Recursos serverless para casos de uso de Model Serving e Gen AI
Para dar melhor suporte a casos de uso de model serving e Gen AI, o Databricks introduziu várias funcionalidades sobre nossa infraestrutura serverless que escala automaticamente para seus fluxos de trabalho sem a necessidade de configurar instâncias e tipos de servidor.
- AI Search: Índice vetorial que pode ser sincronizado de qualquer Delta Table com 1 clique - sem necessidade de pipelines de ingestão/sincronização de dados complexos e personalizados.
- Online Tables: Tabelas totalmente serverless que escalam automaticamente a capacidade de throughput com a carga de requisições e fornecem acesso de baixa latência e alto throughput a dados de qualquer escala
- Model Serving: Serviço altamente disponível e de baixa latência para implantação de modelos. O serviço escala automaticamente para cima ou para baixo para atender às mudanças na demanda, economizando custos de infraestrutura enquanto otimiza o desempenho de latência
Predictive I/O para atualizações e exclusões
Com esses recursos baseados em IA, o Databricks SQL agora pode analisar padrões históricos de leitura e gravação para construir índices de forma inteligente e otimizar cargas de trabalho. Predictive I/O é um conjunto de otimizações do Databricks que melhoram o desempenho para interações de dados. As capacidades do Predictive I/O são agrupadas nas seguintes categorias:
- Leituras aceleradas reduzem o tempo necessário para escanear e ler dados. Ele usa técnicas de deep learning para conseguir isso. Mais detalhes podem ser encontrados nesta documentação
- Atualizações aceleradas reduzem a quantidade de dados que precisam ser reescritos durante atualizações, exclusões e mesclagens. O Predictive I/O utiliza deletion vectors para acelerar atualizações, reduzindo a frequência de regravações completas de arquivos durante a modificação de dados em tabelas Delta. O Predictive I/O otimiza as operações
DELETE,MERGEeUPDATE. Mais detalhes podem ser encontrados nesta documentação
O Predictive I/O é exclusivo do motor Photon no Databricks.
Gerenciamento inteligente de carga de trabalho (IWM)
Um dos principais desafios dos administradores de plataformas técnicas é gerenciar diferentes warehouses para cargas de trabalho pequenas e grandes e garantir que o código seja otimizado e ajustado para rodar de forma ideal e aproveitar toda a capacidade da infraestrutura de computação. IWM é um conjunto de recursos que ajuda com os desafios acima e ajuda a executar essas cargas de trabalho mais rapidamente, mantendo os custos baixos. Ele consegue isso analisando padrões em tempo real e garantindo que as cargas de trabalho tenham a quantidade ideal de computação para executar as instruções SQL recebidas sem interromper as consultas já em execução.
A base certa de FinOps - através de tagging, políticas e relatórios - é crucial para a transparência e ROI da sua Plataforma de Inteligência de Dados. Ela ajuda você a obter valor de negócio mais rapidamente e a construir uma empresa mais bem-sucedida.
Use serverless e DatabricksIQ para configuração rápida, eficiência de custos e otimizações automáticas que se adaptam aos seus padrões de carga de trabalho. Isso leva a um TCO menor, melhor confiabilidade e operações mais simples e econômicas.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.