Intelligently Balance Cost Optimization & Reliability on Databricks
Delve into the intersection of financial management and cloud computing on the Databricks Data Intelligence Platform
by Vuong Nguyen and Wasim Ahmad
The Databricks Data Intelligence Platform offers unparalleled flexibility, allowing users to access nearly instant, horizontally scalable compute resources. This ease of creation can lead to unchecked cloud costs if not properly managed.
Implement Observability to Track & Chargeback Cost
How to effectively use observability to track & charge back costs in Databricks
When working with complex technical ecosystems, proactively understanding the unknowns is key to maintaining platform stability and controlling costs. Observability provides a way to analyze and optimize systems based on the data they generate. This is different from monitoring, which focuses on identifying new patterns rather than tracking known issues.
Key features for cost tracking in Databricks
Tagging: Use tags to categorize resources and charges. This allows for more granular cost allocation.
System Tables: Leverage system tables for automated cost tracking and chargeback. Cloud-native cost monitoring tools: Utilize these tools for insights into costs across all resources.
What are System Tables & how to use them
Databricks provide great observability capabilities using System tables are Databricks-hosted analytical stores of a customer account’s operational data found in the system catalog. They provide historical observability across the account and include user-friendly tabular information on platform telemetry. .Key insights like Billing usage data are available in system tables (this currently only includes DBU’s List Price), with each usage record representing an hourly aggregate of a resource's billable usage.
How to enable system tables
System tables are managed by Unity Catalog and require a Unity Catalog-enabled workspace to access. They include data from all workspaces but can only be queried from enabled workspaces. Enabling system tables happens at the schema level - enabling a schema enables all its tables. Admins must manually enable new schemas using the API.

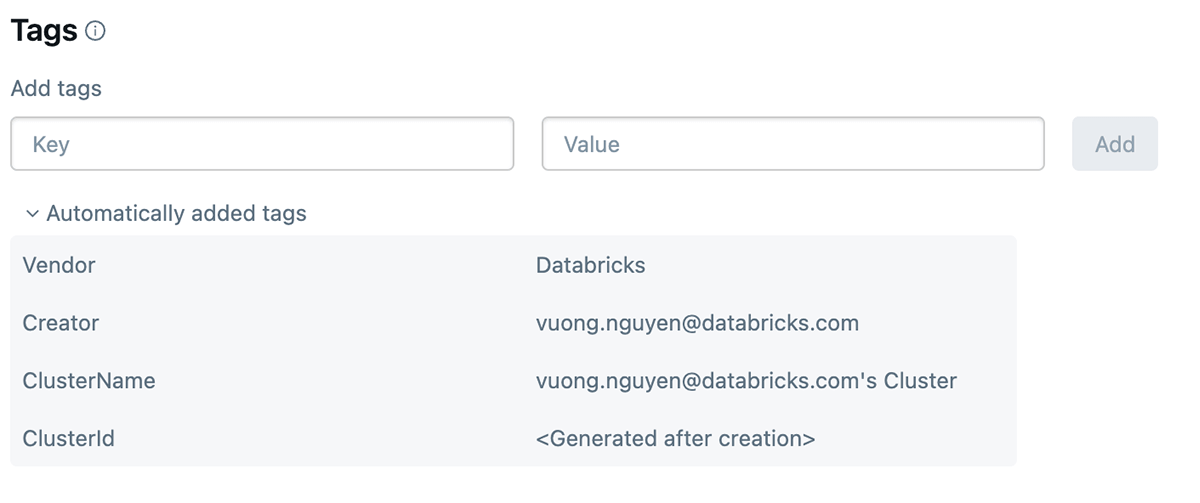
What are Databricks tags & how to use them
Databricks tagging lets you apply attributes (key-value pairs) to resources for better organization, search, and management. For tracking cost and charge back teams can tag their databricks jobs and compute (Clusters, SQL warehouse), which can help them track usage, costs, and attribute them to specific teams or units.
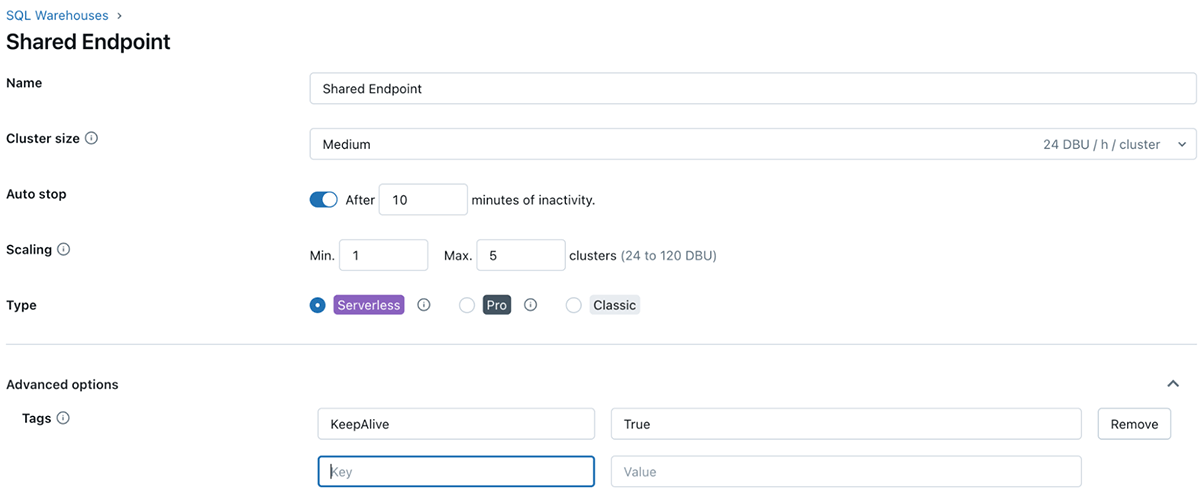
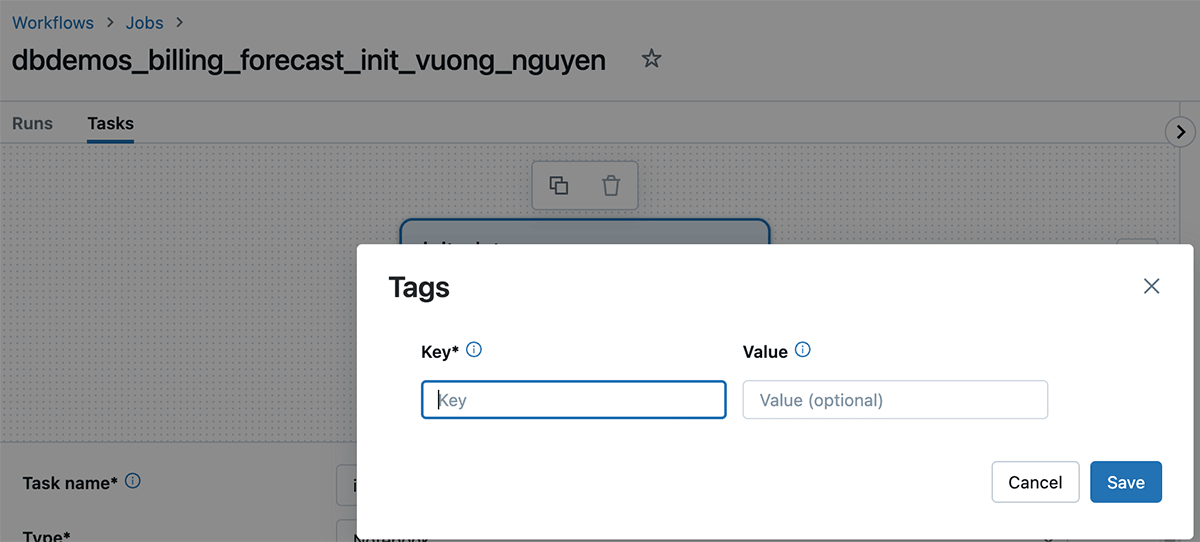
How to apply tags
Tags can be applied to the following databricks resources for tracking usage and cost:
- Databricks Compute
- Databricks Jobs
Once these tags are applied, detailed cost analysis can be performed using the billable usage system tables.
How to identify cost using cloud native tools
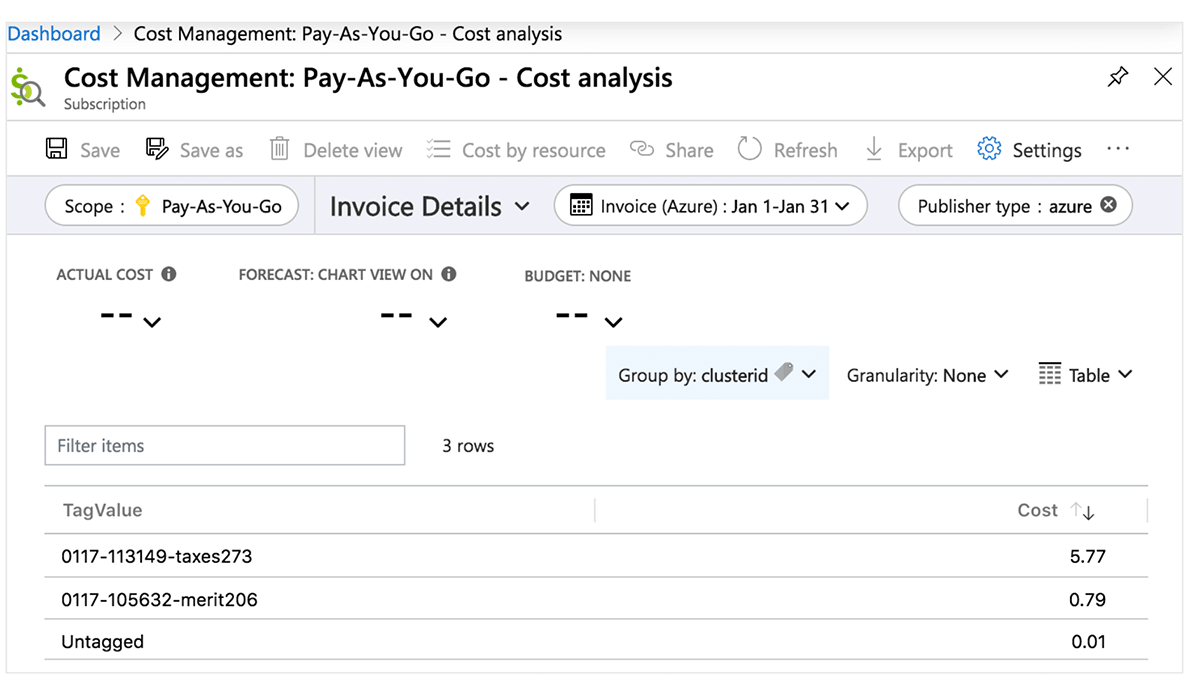
To monitor cost and accurately attribute Databricks usage to your organization’s business units and teams (for chargebacks, for example), you can tag workspaces (and the associated managed resource groups) as well as compute resources.
Azure Cost Center
The following table elaborates Azure Databricks objects where tags can be applied. These tags can propagate to detailed cost analysis reports that you can access in the portal and to the billable usage system table. Find more details on tag propagation and limitations in Azure.
| Azure Databricks Object | Tagging Interface (UI) | Tagging Interface (API) |
|---|---|---|
| Workspace | Azure Portal | Azure Resources API |
| Pool | Pools UI in the Azure Databricks workspace | Instance Pool API |
| All-purpose & Job compute | Compute UI in the Azure Databricks workspace | Clusters API |
| SQL Warehouse | SQL warehouse UI in the Azure Databricks workspace | Warehouse API |
AWS Cost Explorer
The following table elaborates AWS Databricks Objects where tags can be applied.These tags can propagate both to usage logs and to AWS EC2 and AWS EBS instances for cost analysis. Databricks recommends using system tables (Public Preview) to view billable usage data. Find more details on tags propagation and limitations in AWS.
| AWS Databricks Object | Tagging Interface (UI) | Tagging Interface (API) |
|---|---|---|
| Workspace | N/A | Account API |
| Pool | Pools UI in the Databricks workspace | Instance Pool API |
| All-purpose & Job compute | Compute UI in the Databricks workspace | Clusters API |
| SQL Warehouse | SQL warehouse UI in the Databricks workspace | Warehouse API |
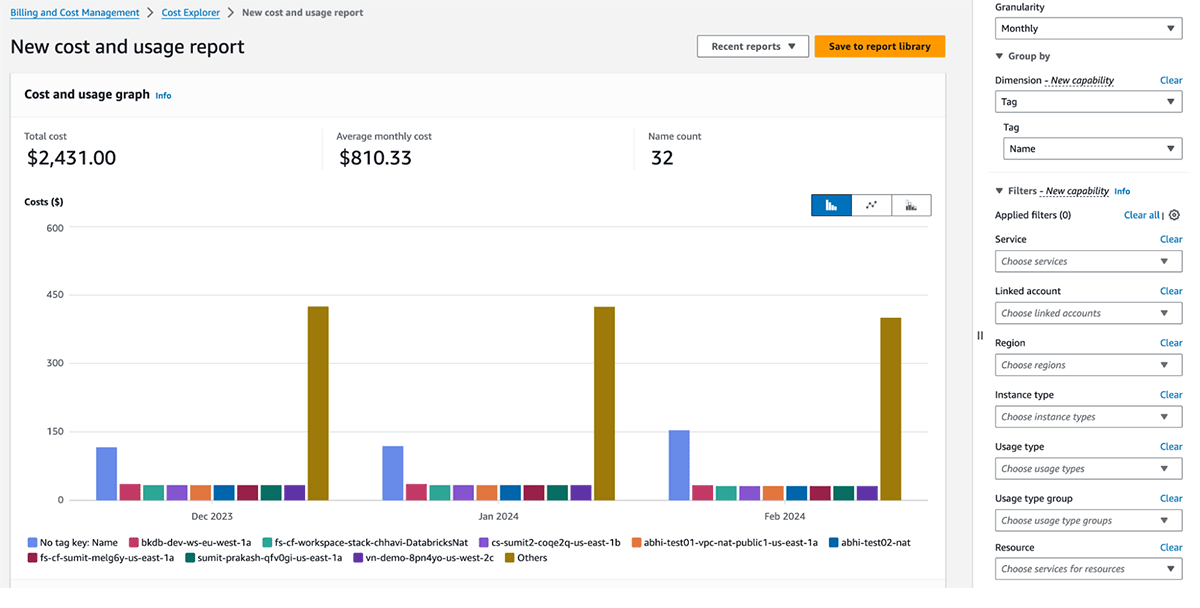
GCP Cost management and billing
The following table elaborates GCP databricks objects where tags can be applied. These tags/labels can be applied to compute resources. Find more details on tags/labels propagation and limitations in GCP.
The Databricks billable usage graphs in the account console can aggregate usage by individual tags. The billable usage CSV reports downloaded from the same page also include default and custom tags. Tags also propagate to GKE and GCE labels.
| GCP Databricks Object | Tagging Interface (UI) | Tagging Interface (API) |
|---|---|---|
| Pool | Pools UI in the Databricks workspace | Instance Pool API |
| All-purpose & Job compute | Compute UI in the Databricks workspace | Clusters API |
| SQL Warehouse | SQL warehouse UI in the Databricks workspace | Warehouse API |
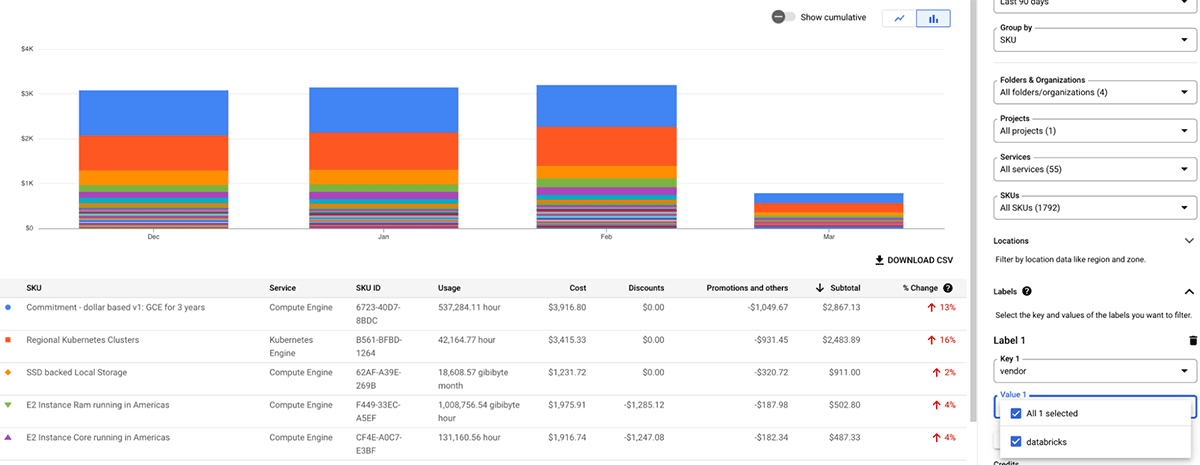
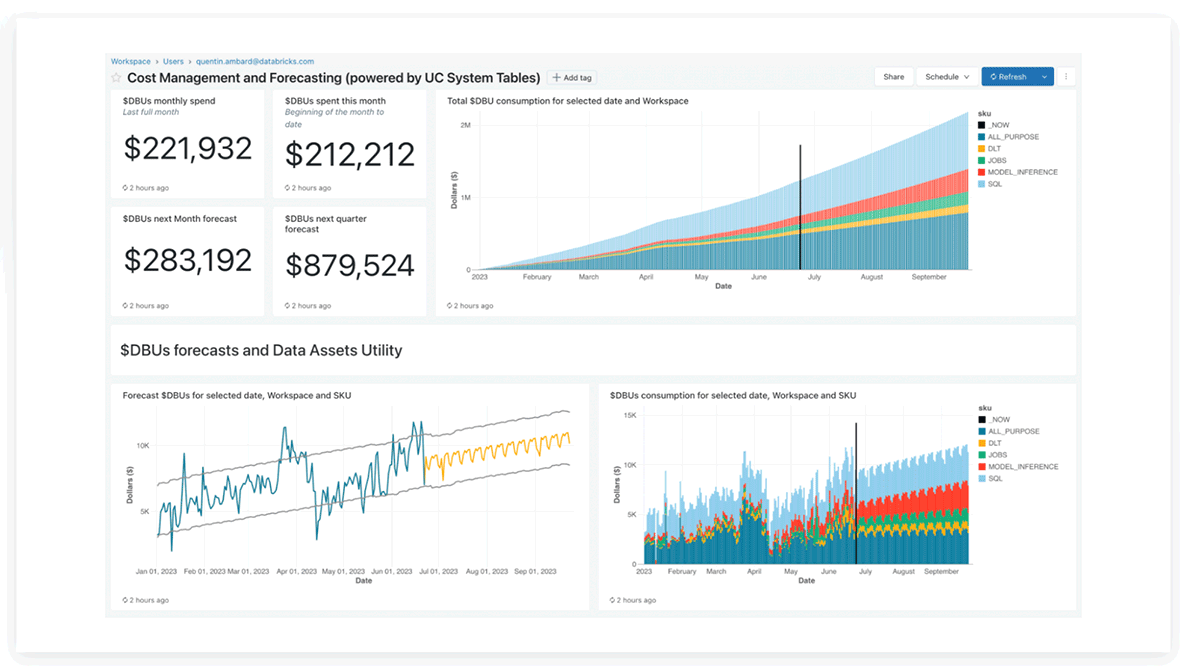
Databricks System tables Lakeview dashboard
The Databricks product team has provided precreated lakeview dashboards for cost analysis and forecasting using system tables, which customers can customize as well.
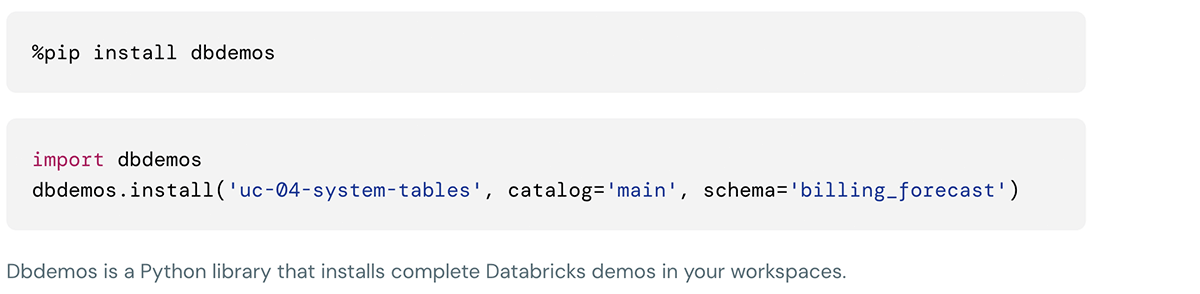
This demo can be installed using following commands in the databricks notebooks cell:
Best Practices to Maximize Value
When running workloads on Databricks, choosing the right compute configuration will significantly improve the cost/performance metrics. Below are some practical cost optimizations techniques:
Using the right compute type for the right job
For interactive SQL workloads, SQL warehouse is the most cost-efficient engine. Even more efficient could be Serverless compute, which comes with a very fast starting time for SQL warehouses and allows for shorter auto-termination time.
For non-interactive workloads, Jobs clusters cost significantly less than an all-purpose clusters. Multitask workflows can reuse compute resources for all tasks, bringing costs down even further
Picking the right instance type
Using the latest generation of cloud instance types will almost always bring performance benefits, as they come with the best performance and latest features. On AWS, Graviton2-based Amazon EC2 instances can deliver up to 3x better price-performance than comparable Amazon EC2 instances.
Based on your workloads, it is also important to pick the right instance family. Some simple rules of thumb are:
- Memory optimized for ML, heavy shuffle & spill workloads
- Compute optimized for Structured Streaming workloads, maintenance jobs (e.g. Optimize & Vacuum)
- Storage optimized for workloads that benefit from caching, e.g. ad-hoc & interactive data analysis
- GPU optimized for specific ML & DL workloads
- General purpose in absence of specific requirements
Picking the Right Runtime
The latest Databricks Runtime (DBR) usually comes with improved performance and will almost always be faster than the one before it.
Photon is a high-performance Databricks-native vectorized query engine that runs your SQL workloads and DataFrame API calls faster to reduce your total cost per workload. For those workloads, enabling Photon could bring significant cost savings.
Leveraging Autoscaling in Databricks Compute
Databricks provides a unique feature of cluster autoscaling making it easier to achieve high cluster utilization because you don’t need to provision the cluster to match a workload. This is particularly useful for interactive workloads or batch workloads with varying data load. However, classic Autoscaling does not work with Structured Streaming workloads, which is why we have developed Enhanced Autoscaling in Delta Live Tables to handle streaming workloads which are spiky and unpredictable.
Leveraging Spot Instances
All major cloud providers offer spot instances which allow you to access unused capacity in their data centers for up to 90% less than regular On-Demand instances. Databricks allows you to leverage these spot instances, with the ability to fallback to On-Demand instances automatically in case of termination to minimize disruption. For cluster stability, we recommend using On-Demand driver nodes.
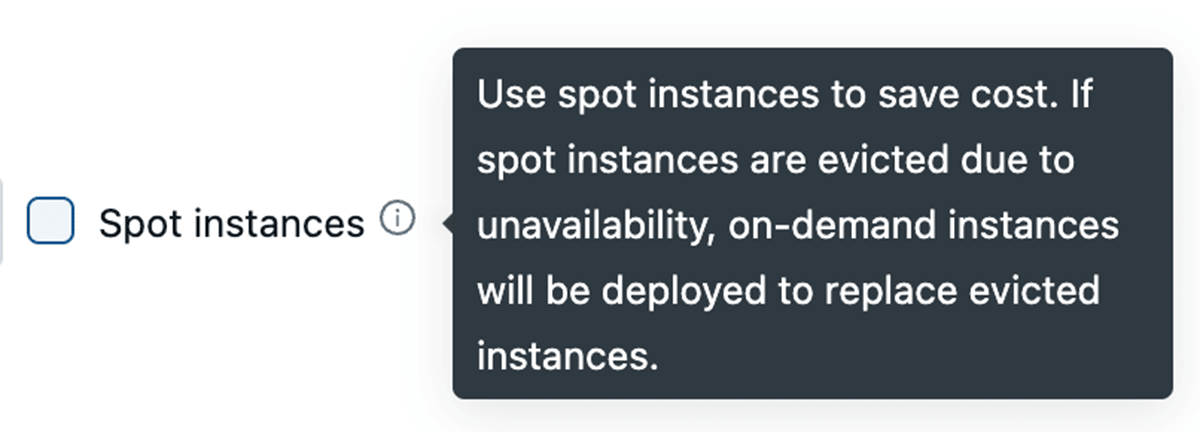
Leveraging Fleet instance type (on AWS)
Under the hood, when a cluster uses one of these fleet instance types, Databricks will select the matching physical AWS instance types with the best price and availability to use in your cluster.
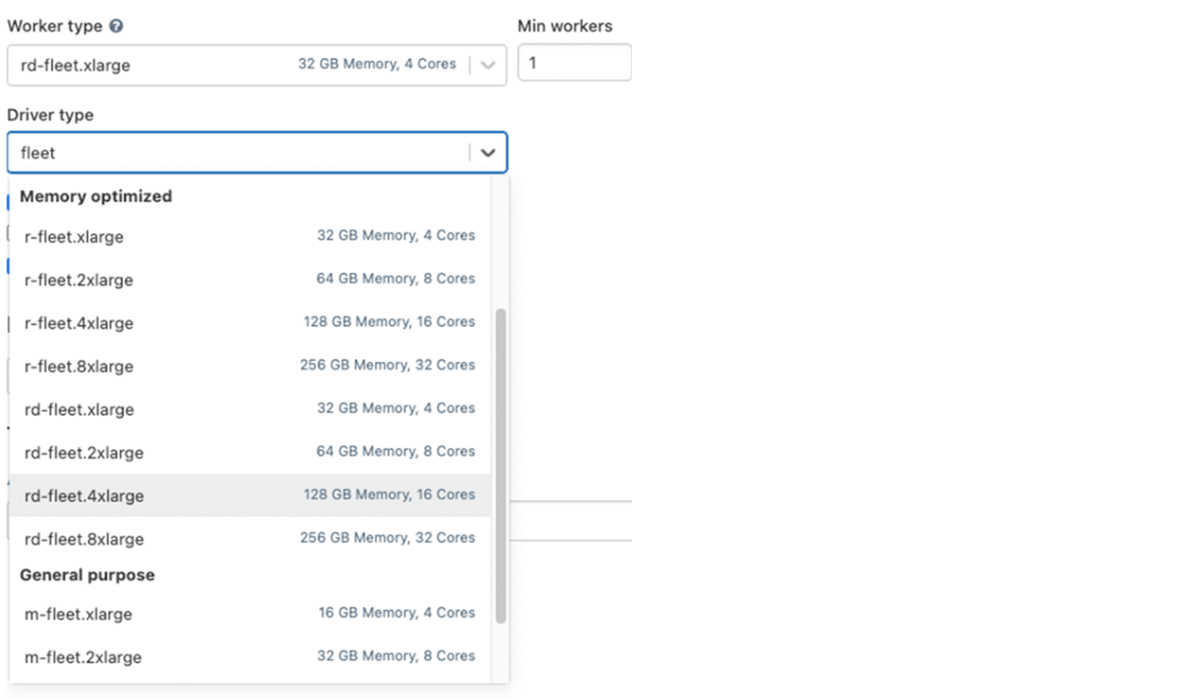
Cluster Policy
Effective use of cluster policies allows administrators to enforce cost specific restrictions for end users:
- Enable cluster auto termination with a reasonable value (for example, 1 hour) to avoid paying for idle times.
- Ensure that only cost-efficient VM instances can be selected
- Enforce mandatory tags for cost chargeback
- Control overall cost profile by limiting per-cluster maximum cost, e.g. max DBUs per hour or max compute resources per user
AI-powered Cost Optimisation
The Databricks Data Intelligence Platform integrates advanced AI features which optimizes performance, reduces costs, improves governance, and simplifies enterprise AI application development. Predictive I/O and Liquid Clustering enhance query speeds and resource utilization, while intelligent workload management optimizes autoscaling for cost efficiency. Overall, Databricks' platform offers a comprehensive suite of AI tools to drive productivity and cost savings while enabling innovative solutions for industry-specific use cases.
Liquid clustering
Delta Lake liquid clustering replaces table partitioning and ZORDER to simplify data layout decisions and optimize query performance. Liquid clustering provides flexibility to redefine clustering keys without rewriting existing data, allowing data layout to evolve alongside analytical needs over time.
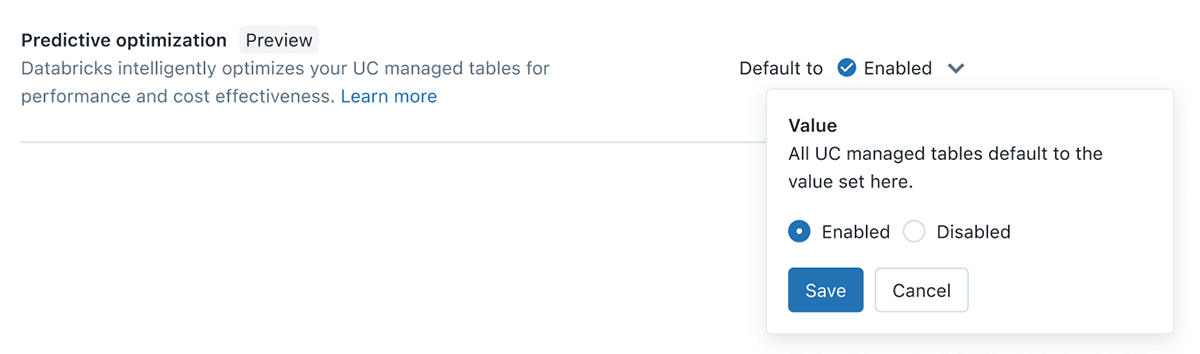
Predictive Optimization
Data engineers on the lakehouse will be familiar with the need to regularly OPTIMIZE & VACUUM their tables, however this creates ongoing challenges to figure out the right tables, the appropriate schedule and the right compute size for these tasks to run. With Predictive Optimization, we leverage Unity Catalog and Lakehouse AI to determine the best optimizations to perform on your data, and then run those operations on purpose-built serverless infrastructure. This all happens automatically, ensuring the best performance with no wasted compute or manual tuning effort.
Materialized View with Incremental Refresh
In Databricks, Materialized Views (MVs) are Unity Catalog managed tables that allow users to precompute results based on the latest version of data in source tables. Built on top of Delta Live Tables & serverless, MVs reduce query latency by pre-computing otherwise slow queries and frequently used computations. When possible, results are updated incrementally, but results are identical to those that would be delivered by full recomputation. This reduces computational cost and avoids the need to maintain separate clusters
Serverless features for Model Serving & Gen AI use cases
To better support model serving and Gen AI use cases, Databricks have introduced multiple capabilities on top of our serverless infrastructure that automatically scales to your workflows without the need to configure instances and server types.
- AI Search: Vector index that can be synchronized from any Delta Table with 1-click - no need for complex, custom built data ingestion/sync pipelines.
- Online Tables: Fully serverless tables that auto-scale throughput capacity with the request load and provide low latency and high throughput access to data of any scale
- Model Serving: highly available and low-latency service for deploying models. The service automatically scales up or down to meet demand changes, saving infrastructure costs while optimizing latency performance
Predictive I/O for updates and Deletes
With these AI powered features Databricks SQL now can analyze historical read and write patterns to intelligently build indexes and optimize workloads. Predictive I/O is a collection of Databricks optimizations that improve performance for data interactions. Predictive I/O capabilities are grouped into the following categories:
- Accelerated reads reduce the time it takes to scan and read data. It uses deep learning techniques to achieve this. More details can be found on this documentation
- Accelerated updates reduce the amount of data that needs to be rewritten during updates, deletes, and merges.Predictive I/O leverages deletion vectors to accelerate updates by reducing the frequency of full file rewrites during data modification on Delta tables. Predictive I/O optimizes
DELETE,MERGE, andUPDATEoperations.More details can be found on this documentation
Predictive I/O is exclusive to the Photon engine on Databricks.
Intelligent workload management (IWM)
One of the major pain points of technical platform admins is to manage different warehouses for small and large workloads and make sure code is optimized and fine tuned to run optimally and leverage the full capacity of the compute infrastructure. IWM is a suite of features that helps with above challenges and helps run these workloads faster while keeping the cost down. It achieves this by analyzing real time patterns and ensuring that the workloads have the optimal amount of compute to execute the incoming SQL statements without disrupting already-running queries.
The right FinOps foundation - through tagging, policies, and reporting - is crucial for transparency and ROI for your Data Intelligence Platform. It helps you realize business value faster and build a more successful company.
Use serverless and DatabricksIQ for rapid setup, cost-efficiency, and automatic optimizations that adapt to your workload patterns. This leads to lower TCO, better reliability, and simpler, more cost-effective operations.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.