Apresentando o Tipo de Dados Variant Aberto no Delta Lake e Apache Spark
Processamento mais rápido e mais flexibilidade ao trabalhar com dados semiestruturados
por Kent Marten, Gene Pang, Chenhao Li e Han Xiao
Estamos animados em anunciar um novo tipo de dados chamado variant para dados semiestruturados. Variant oferece melhorias de desempenho de uma ordem de magnitude em comparação com o armazenamento desses dados como strings JSON, mantendo a flexibilidade para suportar esquemas altamente aninhados e em evolução.
Trabalhar com dados semiestruturados tem sido há muito tempo uma capacidade fundamental do Lakehouse. Endpoint Detection & Response (EDR), análise de cliques de anúncios e telemetria de IoT são apenas alguns dos casos de uso populares que dependem de dados semiestruturados. À medida que migramos cada vez mais clientes de data warehouses proprietários, ouvimos que eles dependem do tipo de dados variant que esses data warehouses proprietários oferecem e adorariam ver um padrão de código aberto para isso, a fim de evitar qualquer dependência.
O tipo variant aberto é o resultado de nossa colaboração com a comunidade de código aberto Apache Spark e a comunidade Linux Foundation Delta Lake:
- O tipo de dados Variant, as expressões binárias Variant e o formato de codificação binária Variant já foram mesclados no Spark de código aberto. Detalhes sobre a codificação binária podem ser revisados aqui.
- O formato de codificação binária permite acesso e navegação mais rápidos dos dados em comparação com Strings. A implementação do formato de codificação binária Variant é empacotada em uma biblioteca de código aberto, para que possa ser usada em outros projetos.
- O suporte para o tipo de dados Variant também é de código aberto para Delta, e o protocolo RFC pode ser encontrado aqui. O suporte Variant será incluído no Spark 4.0 e Delta 4.0.
“Somos apoiadores da comunidade de código aberto com foco em dados por meio de nossa plataforma de dados de código aberto Legend”, disse Neema Raphael, Chief Data Officer e Head de Data Engineering na Goldman Sachs. “O lançamento do Open Source Variant no Spark é mais um grande passo para um ecossistema de dados aberto.”
E a partir do DBR 15.3, todas as capacidades mencionadas estarão disponíveis para nossos clientes usarem.
O que é Variant?
Variant é um novo tipo de dados para armazenar dados semiestruturados. Na Visualização Pública da próxima versão do Databricks Runtime 15.3, a entrada e saída de dados hierárquicos via JSON serão suportadas. Sem Variant, os clientes tinham que escolher entre flexibilidade e desempenho. Para manter a flexibilidade, os clientes armazenavam JSON em colunas únicas como strings. Para obter melhor desempenho, os clientes aplicavam abordagens de esquematização rigorosas com structs, que exigem processos separados para manter e atualizar com as mudanças de esquema. Com Variant, os clientes podem reter a flexibilidade (não há necessidade de definir um esquema explícito) e receber um desempenho vastamente melhorado em comparação com a consulta do JSON como uma string.
Variant é particularmente útil quando as fontes JSON têm esquemas desconhecidos, mutáveis e em constante evolução. Por exemplo, os clientes compartilharam casos de uso de Endpoint Detection & Response (EDR), com a necessidade de ler e combinar logs contendo diferentes esquemas JSON. Da mesma forma, para usos envolvendo cliques de anúncios e telemetria de aplicativos, onde o esquema é desconhecido e muda o tempo todo, Variant é bem adequado. Em ambos os casos, a flexibilidade do tipo de dados Variant permite que os dados sejam ingeridos e performáticos sem exigir um esquema explícito.
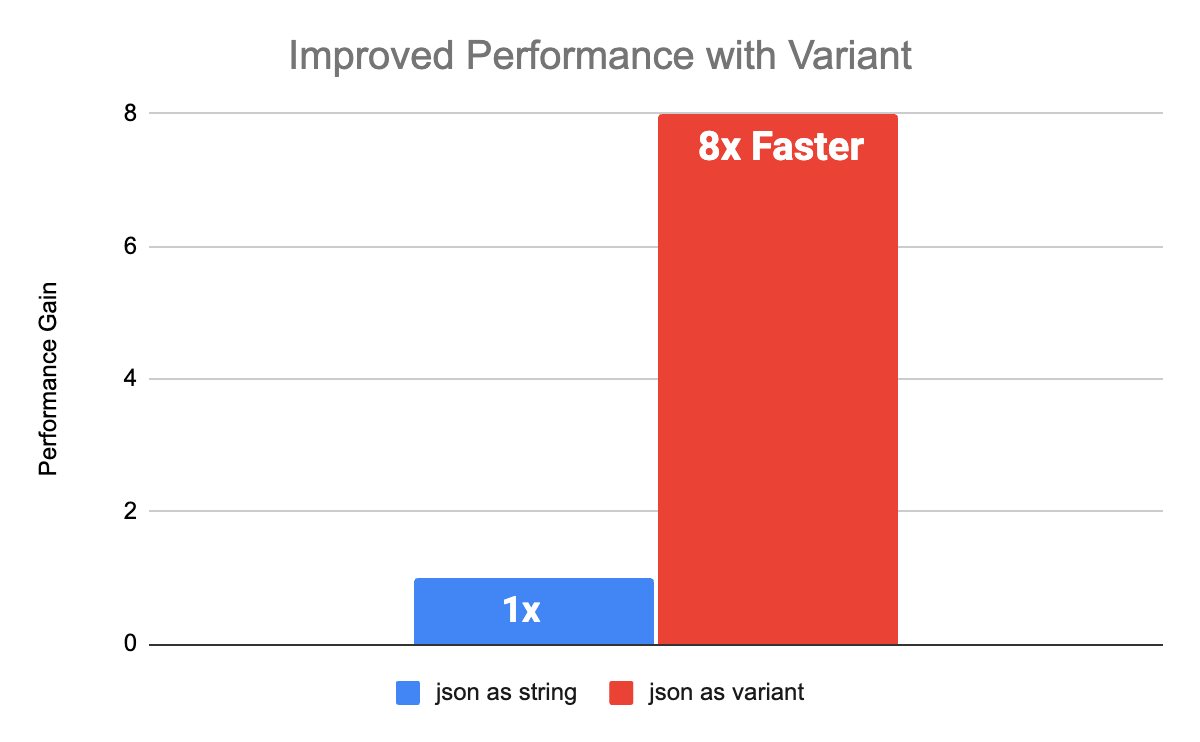
Benchmarks de Desempenho
Variant fornecerá desempenho aprimorado em relação às cargas de trabalho existentes que mantêm JSON como string. Realizamos vários benchmarks com esquemas inspirados em dados de clientes para comparar o desempenho de String vs Variant. Tanto para esquemas aninhados quanto planos, o desempenho com Variant melhorou 8x em relação às colunas String. Os benchmarks foram realizados com Databricks Runtime 15.0 com Photon ativado.
Como posso usar Variant?
Existem várias novas funções para suportar tipos Variant, que permitem inspecionar o esquema de um variant, explodir uma coluna variant e convertê-la para JSON. A função PARSE_JSON() será comumente usada para retornar um valor variant que representa a entrada da string JSON.
Para carregar dados Variant, você pode criar uma coluna de tabela com o tipo Variant. Você pode converter qualquer string formatada em JSON para Variant com a função PARSE_JSON() e inserir em uma coluna Variant.
Você pode usar CTAS para criar uma tabela com colunas Variant. O esquema da tabela que está sendo criada é derivado do resultado da consulta. Portanto, o resultado da consulta deve ter colunas Variant no esquema de saída para criar uma tabela com colunas Variant.
Você também pode usar COPY INTO para copiar dados JSON para uma tabela com uma ou mais colunas Variant.
A navegação de caminho segue a sintaxe intuitiva de notação de ponto.
Totalmente de código aberto, sem dependência de dados proprietários
Vamos recapitular:
- O tipo de dados Variant, expressões binárias e formato de codificação binária já foram mesclados no Apache Spark. O formato de codificação binária pode ser revisado em detalhes aqui.
- O formato de codificação binária é o que permite acesso e navegação mais rápidos dos dados em comparação com Strings. A implementação do formato de codificação binária é empacotada em uma biblioteca de código aberto, para que possa ser usada em outros projetos.
- O suporte para o tipo de dados Variant também é de código aberto para Delta, e o protocolo RFC pode ser encontrado aqui. O suporte Variant será incluído no Spark 4.0 e Delta 4.0.
Além disso, temos planos para implementar shredding/sub-colunarização para o tipo Variant. Shredding é uma técnica para melhorar o desempenho de consulta de caminhos específicos dentro dos dados Variant. Com shredding, os caminhos podem ser armazenados em sua própria coluna, e isso pode reduzir o IO e a computação necessários para consultar esse caminho. Shredding também permite a poda de dados para evitar trabalho adicional desnecessário. Shredding também estará disponível no Apache Spark e Delta Lake.
Você vai participar do DATA + AI Summit deste ano, de 10 a 13 de junho em São Francisco?
Por favor, participe de "Variant Data Type - Making Semi-Structured Data Fast and Simple".
Variant estará habilitado por padrão no Databricks Runtime 15.3 em Visualização Pública e no canal DBSQL Preview em breve. Teste seus casos de uso de dados semiestruturados e inicie uma conversa nos fóruns da comunidade Databricks se tiver pensamentos ou perguntas. Adoraríamos saber o que a comunidade pensa!
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.