Acelere sua modelagem de dados com os Modelos de Dados Setoriais da Databricks
Modelos de dados pré-configurados, validados por regras e prontos para a camada Silver para os 40 maiores setores do mundo — prontos para serem implantados e governados na plataforma Databricks.
por Amr Ali, Drew Triplett, Franco Patano e Shelley Shaffery
- Mais de 40 modelos de dados setoriais prontos para uso. Modelos pré-configurados e validados por regras da camada Silver para 40 setores, em dois escopos (MVM e ECM) — implante como estão ou personalize.
- Um conjunto completo de artefatos governados. Entregue como um único model.json (além de SQL DDL, DBML, ontologia) que é implantado no Unity Catalog com tabelas Delta, chaves estrangeiras, tags de classificação e visualizações de métricas.
- Implante em horas. Aponte o model.json para um Unity Catalog, escolha um estilo de catalogação e obtenha uma camada Silver classificada e validada por FK.
O problema do modelo de dados do setor
Há três décadas, setores regulamentados e com grande volume de dados recebem a mesma promessa de atalho: comprar um modelo de dados do setor. ACORD para seguros. FHIR e HL7 para saúde. ARTS para varejo. Centenas — às vezes milhares — de tabelas, publicadas por um órgão de padronização ou fornecedor, vendidas como um ano de trabalho em uma única licença.
A proposta é atraente. A realidade é mais dolorosa. Um modelo de dados do setor é a média de todas as empresas de um segmento. Ele não conhece suas linhas de produtos, suas regiões geográficas, sua pegada regulatória, suas restrições de sistemas legados, seus costumes de nomenclatura ou seu formato organizacional — ele não sabe o que diferencia o seu negócio. As equipes herdam centenas de tabelas que nunca preencherão, convenções de nomenclatura que não correspondem à sua terminologia e direções de relacionamento que suas cargas de trabalho não exigem. A maior parte do valor de comprar um modelo é gasta ajustando, renomeando e reorganizando-o — exatamente o trabalho que o modelo deveria poupar.
Um modelo de dados analíticos sólido, do tipo que realmente executa análises em produção e ML, historicamente leva de meses a anos para ser construído.
Estamos publicando algo diferente. Uma biblioteca de modelos de dados do setor pré-construídos para Lakehouse, disponível hoje em um repositório público, pronta para ser implantada como a camada Silver do seu Databricks para os 40 maiores setores do mundo. Cada modelo de dados do setor vem em dois escopos e é construído com base em um conjunto rigoroso de regras estruturais que abrange mais de 200 regras em 14 domínios de modelagem diferentes, tornando o resultado pronto para produção desde o primeiro dia. A boa notícia é que eles não são modelos de dados rígidos ou fixos; você tem os meios para evoluí-los e personalizá-los para se adequarem à sua organização conforme necessário.
Oonde esses modelos de dados se posicionam no Lakehouse
Em uma arquitetura de medalhão do Databricks, a camada Bronze contém dados brutos, a Silver contém o modelo de base analítica em conformidade do qual todo analista, ferramenta de BI e cientista de dados faz a leitura, e a Gold contém métricas derivadas, KPIs e agregações.
Esses modelos de dados base são a camada Silver. O Lakeflow e o Auto Loader cuidam da ingestão. Cada modelo é fornecido com métricas pré-calculadas como churn_score ou monthly_revenue_summary. O modelo base é a fundação analítica: o local onde os conceitos do negócio se tornam tabelas confiáveis, prontas para ferramentas de BI, pipelines de features e agregações downstream.
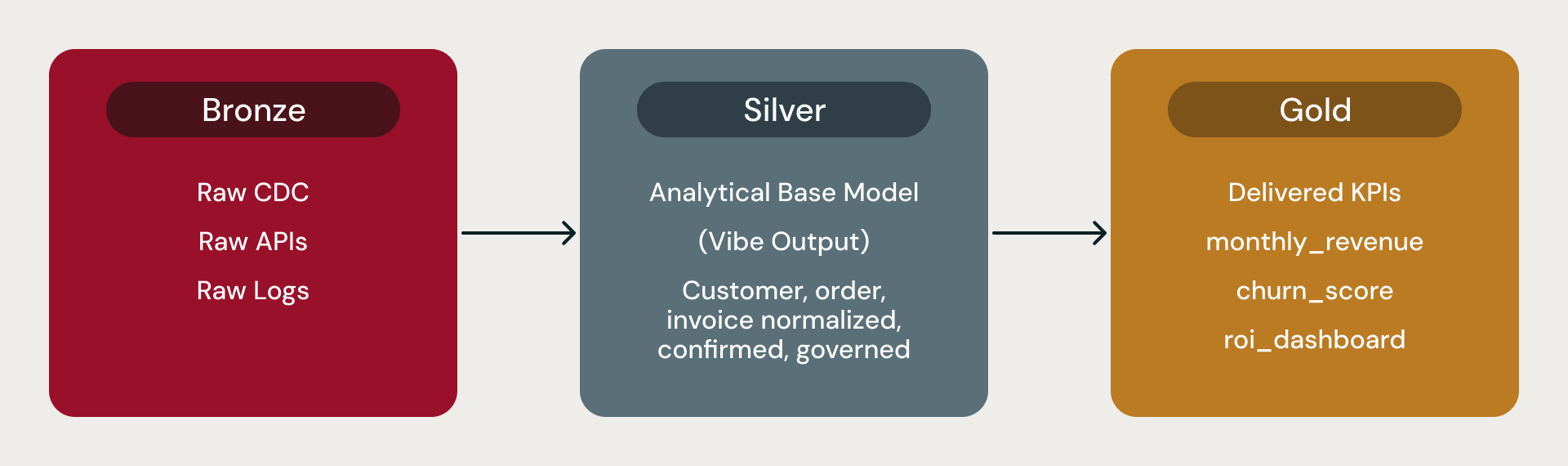
Bronze, Silver, Gold
Dois escopos: MVM e ECM
Cada modelo base é publicado em dois escopos. Ambos são implantados a partir do mesmo model.json lógico; ambos seguem as mesmas regras; ambos têm a mesma profundidade de atributos por tabela. A diferença está na amplitude.
Minimum Viable Model (MVM). De trinta a cinquenta por cento da contagem de tabelas do ECM. Apenas funções de negócios essenciais. Ideal para SMBs, implantações rápidas, provas de conceito e MVPs. Um MVM não é um esqueleto ou um brinquedo de demonstração — cada tabela tem a mesma riqueza de atributos que sua contraparte no ECM. A leveza vem de menos domínios e menos tabelas, nunca de tabelas mais vazias.
Expanded Coverage Model (ECM). Cobertura total. Todas as divisões, incluindo o back office corporativo. Todos os domínios que um modelo da Fortune 100 esperaria. Amplitude máxima.
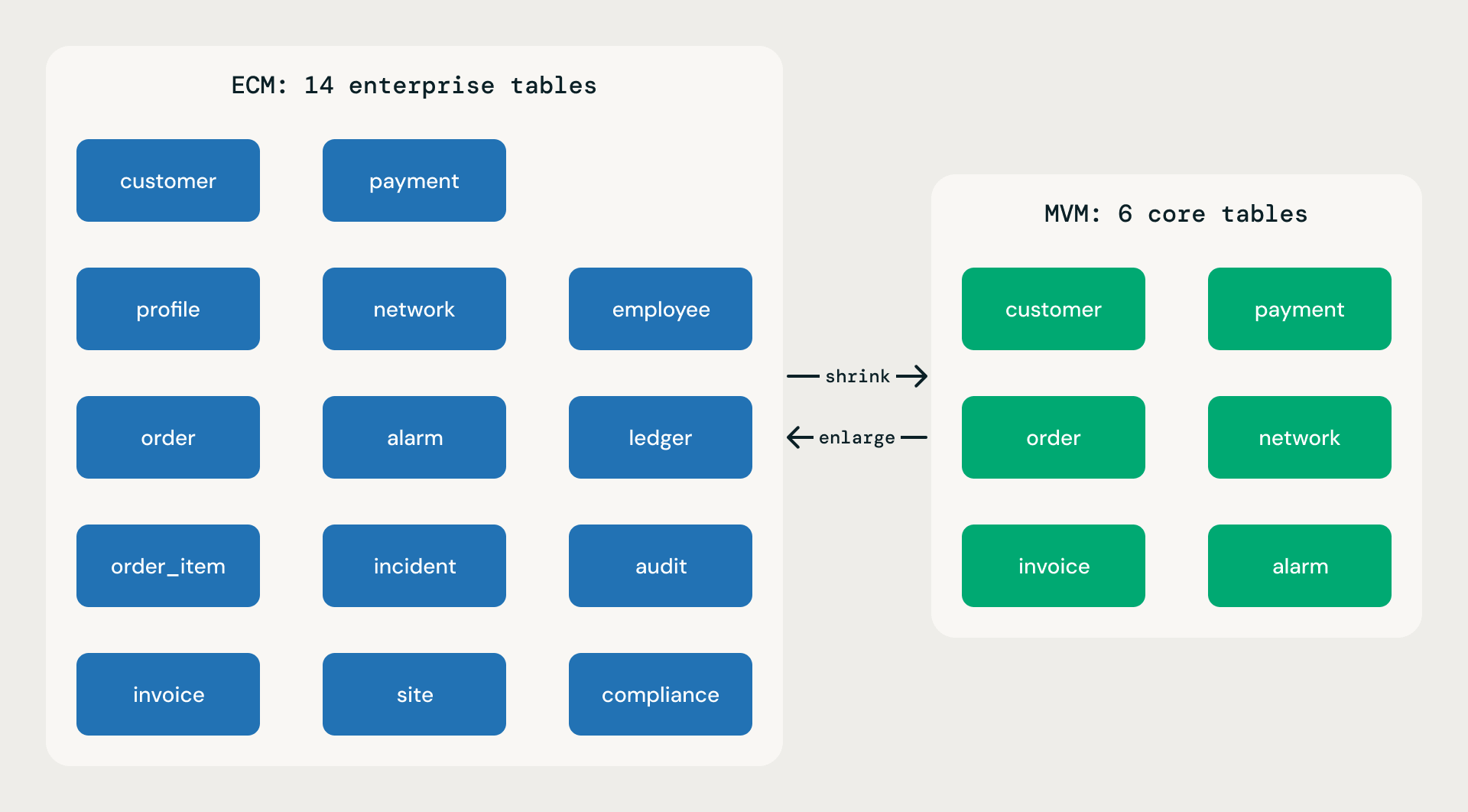
Escopo MVM vs. ECM
Por que ambos os escopos são importantes? O objetivo não é que as organizações percam tempo adaptando o modelo aos seus dados de negócios, mas sim começar rapidamente com análises no Lakehouse, de modo que começar com o escopo certo já é uma economia de tempo.
Os dois escopos não são linhas de manutenção separadas. Qualquer um deles pode ser derivado do outro por meio de uma única transformação: shrink ecm produz um subconjunto de MVM que protege os produtos principais e mantém as chaves estrangeiras essenciais; enlarge mvm faz o oposto. Nenhuma versão é sobrescrita — ambas operações criam uma nova versão numerada ao lado da original.
O que torna esses modelos diferentes
Os modelos base que estamos publicando não são modelos do setor padronizados por comitês com novos nomes. Eles são produzidos por um agente de IA disciplinado e orientado por regras que impõe qualidade estrutural em cada etapa de modelagem. Alguns destaques:
Dimensionamento por nível de setor. Cada modelo é dimensionado para a complexidade real do seu setor. O classificador usa sete dimensões — densidade regulatória, complexidade das partes, profundidade da hierarquia de produtos, gerenciamento de infraestrutura, modelo canônico do setor, complexidade das transações e panorama do sistema operacional — para colocar cada setor em um de cinco níveis, o que determina o número de domínios, produtos por domínio e profundidade de atributos.
| Nível | Rótulo | Características | Domínios MVM | Produtos/Domínio ECM |
|---|---|---|---|---|
| tier_1 | Ultracomplexo | Setor bancário, seguros, grandes indústrias farmacêuticas | 15–22 | 14–28 |
| tier_2 | Complexo | Telecomunicações, energia, saúde | 12–18 | 14–26 |
| tier_3 | Moderado | Manufatura, varejo | 10–15 | 12–24 |
| tier_4 | Padrão | Logística, agricultura | 8–12 | 10–20 |
| tier_5 | Simples | Consultoria, SaaS, mídia | 5–8 | 8–18 |
Jargão específico do setor. Cada modelo usa a terminologia que seu setor realmente utiliza. Telecomunicações recebem msisdn, arpu, imsi, cdr. Mineração recebe rom, cut_off_grade, jorc. Saúde recebe icd, cpt, drg. Setor bancário recebe iban. Esses termos não são meros detalhes secundários — eles moldam os nomes das colunas, as convenções de chaves primárias e a estrutura das tags de governança.
A estrutura de três divisões. Cada modelo é organizado em três anéis concêntricos:
- Operations é o que a empresa faz fisicamente — rede, frota, fábrica, infraestrutura.
- Business é a quem ela atende e como gera receita — cliente, faturamento, produto, vendas.
- Corporate é a estrutura de suporte — HR, finanças, conformidade.
A proporção é imposta por regras (rule G06-R001): Operations mais Business devem representar pelo menos 80% de todos os domínios; Corporate é limitado a 20%. Isso evita o modo de falha mais comum da modelagem sem restrições — modelos que são metade HR, finanças e jurídico, e superficiais no núcleo operacional que realmente administra o negócio.
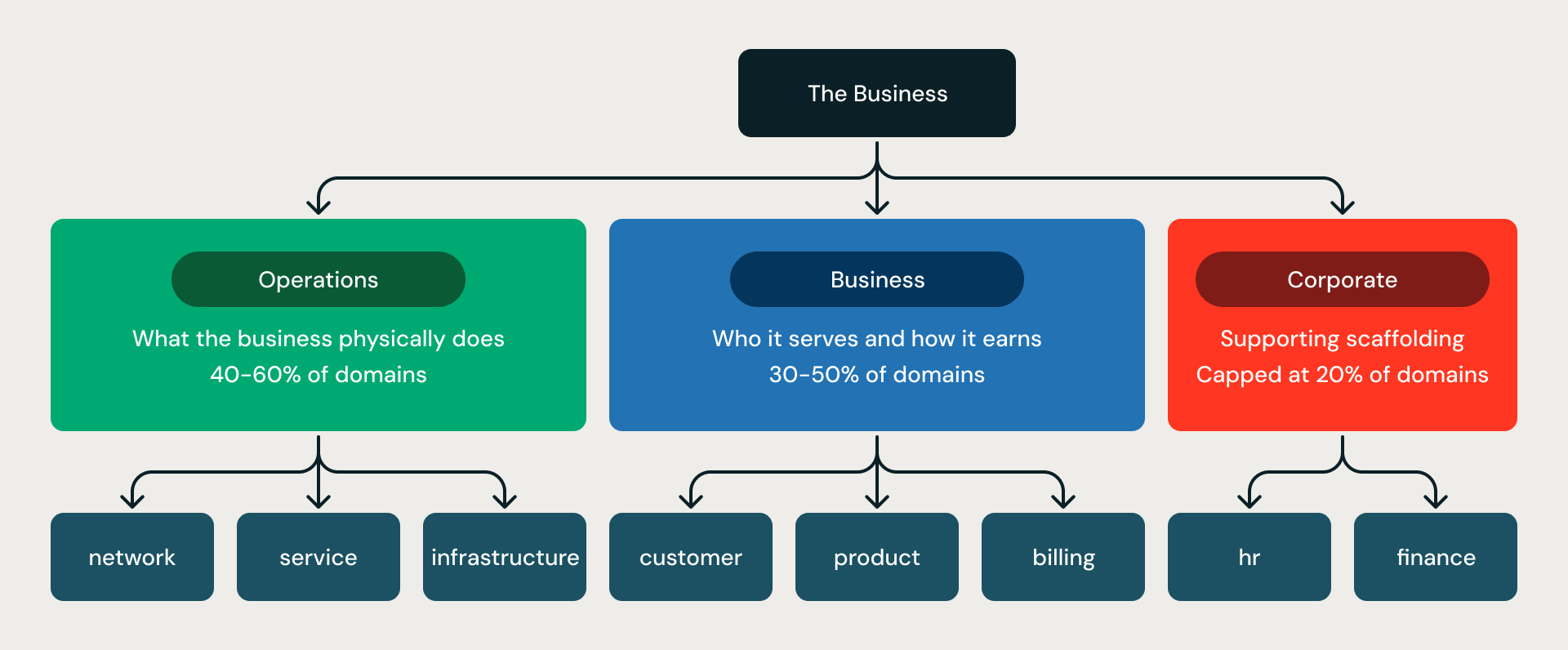
As três divisões
A hierarquia de seis níveis. Cada modelo segue a mesma estrutura rigorosa: Organização → Divisão → Domínio → Subdomínio → Produto → Atributo. A hierarquia não é uma sugestão; ela é imposta por regras estruturais, por dois níveis de revisão de arquitetos e por análise estática no final de cada pipeline.
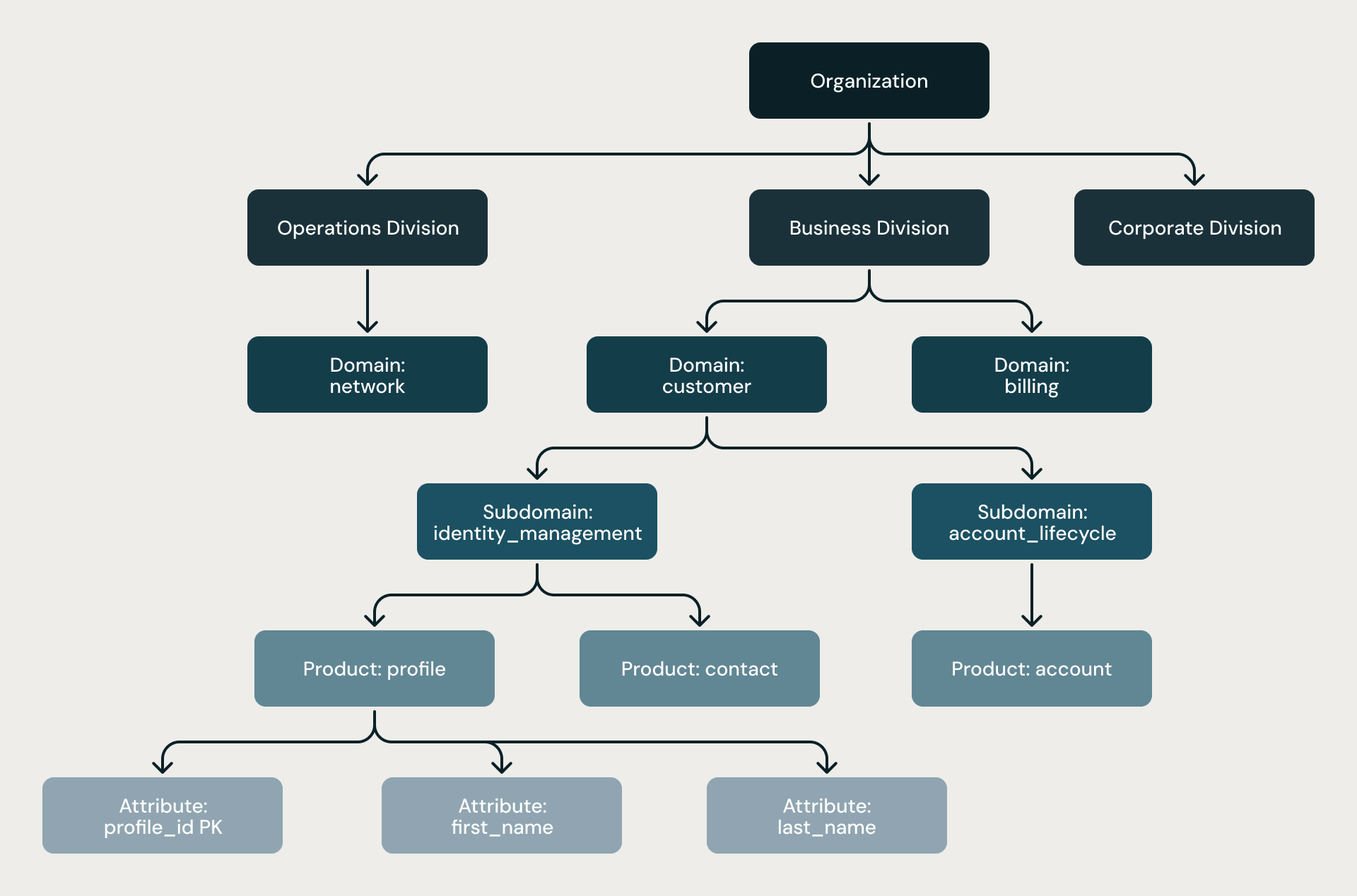
Hierarquia de quatro níveis
Mais de 200 regras aplicáveis. Cada modelo base é validado em relação a mais de 200 regras organizadas em mais de 14 grupos — convenções de nomenclatura, eliminação de duplicações semânticas, chaves estrangeiras, chaves primárias, normalização, estrutura de domínio, tipos de dados, tags de classificação, imposição de relacionamento/DAG, qualidade, design de produto, restrições de estilo, implantação de esquema físico e dimensionamento de subdomínio. Cada tabela deve ter uma chave primária. Cada chave estrangeira aponta para um destino real. Cada domínio passa no teste do organograma: “Um departamento/equipe real com este nome poderia existir na organização?” Sem ciclos. Sem silos e com adesão estrita à Single Source Of Truth (SSOT).
Um modelo lógico, três layouts físicos. Cada modelo base é fornecido como um único model.json independente de ambiente. O mesmo modelo lógico é implantado de forma limpa no Unity Catalog em três estilos de catalogação: um catálogo (limite de governança único), catálogo por divisão (Operations / Business / Corporate isolados) ou catálogo por domínio (compatível com data mesh). Implante novamente em um estilo diferente e nada no modelo lógico será alterado.
Um exemplo prático: o modelo ECM para companhias aéreas v1
Para tornar isso concreto, aqui está o ECM para companhias aéreas que está disponível no repositório hoje.
| Métrica | Valor |
|---|---|
| Escopo do modelo | ECM v1 |
| Total de domínios | 19 |
| Total de subdomínios | 60 |
| Total de produtos | 420 |
| Total de atributos | 17.278 |
| Chaves primárias | 420 |
| Chaves estrangeiras | 2.877 |
| Média de atributos/produto | 41.1 |
| Visualizações de Métricas | 203 |
Visualizado como um gráfico, o DAG completo se parece com isto (cada retângulo é um domínio, cada círculo pequeno é uma tabela e cada linha é um link de FK):

Airline ECM v1 como um DAG conectado
Os dezenove domínios se dividem claramente entre as três divisões. Operations contém airport, crew, fleet, flight, inventory, maintenance e route. Business contém ancillary, cargo, loyalty, passenger, reservation, revenue, service e ticket. Corporate contém compliance, finance, safety e workforce.

Domínios da companhia aérea por divisão
Ao aprofundar em um único domínio — flight operations —, a estrutura se torna legível em um nível prático. Subdomínios para resource loading, flight operations e passenger services contêm os produtos que um analista de operações realmente utiliza: leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment. (cada círculo é uma tabela, cada linha é uma relação FK)

Domínio Flight
Aprofundando ainda mais em um único produto de dados — o Air Waybill (awb) dentro do domínio cargo —, é possível ver exatamente como funcionam os links entre domínios. awb se conecta a corporate_account no domínio passenger, station em airport, leg em flight, profit_center, ledger_account e company_code em finance, e screening_result em compliance. Esses são os joins que um analista de receita de carga executa todos os dias, e eles estão presentes porque o DAG de domínios cruzados foi criado para dar suporte a eles.

Produto de dados Air Waybill
O que você recebe ao implantar
Cada modelo base é fornecido com um conjunto completo de artefatos.
Artefatos lógicos. Um único model.json (o formato de intercâmbio primário), um readme.md legível por humanos, exportações simples de domínios, produtos e atributos, exportações em Excel e CSV, arquivos SQL DDL (um por domínio mais um arquivo FK entre domínios), um diagrama de esquema DBML e uma ontologia RDF/Turtle.
Artefatos físicos ao implantar em um Unity Catalog. Esquemas do Unity Catalog (um por domínio ou por subdomínio, dependendo do estilo de catalogação), tabelas Delta para cada produto, restrições de chave estrangeira aplicadas na ordem de dependência, tags de classificação do Unity Catalog (PII, restrito, público), visualizações de métricas do Databricks para definições de KPI reutilizáveis e dados de amostra sintéticos com referências de FK válidas para exploração imediata.
O arquivo model.json é a moeda de troca. Faça o commit no git. Compare duas versões. Compartilhe-o entre ambientes. Entregue-o a um revisor de segurança sem expor o acesso de produção. Implante-o novamente em dev, staging e prod sob três estilos de catalogação diferentes e obtenha três ambientes cujo conteúdo lógico é idêntico em nível de bytes.
Onde essa abordagem se destaca
- Velocidade. As fundações da camada Silver que costumavam levar meses agora são apenas uma etapa de implantação.
- Especificidade. Os modelos usam a linguagem do setor — seu jargão, sua estrutura regulatória, sua realidade operacional.
- Cobertura de regras. Mais de 200 regras aplicáveis significam uma consistência que a maioria dos modelos escritos à mão nunca alcança.
- Governança. Cada coluna com dados confidenciais é classificada e marcada com tags. Cada PK/FK segue uma única convenção. Cada estilo de catalogação é reproduzível.
- Formato duplo. O mesmo artefato é um esquema relacional, um diagrama DBML, uma ontologia de grafo de conhecimento e uma implantação física do Unity Catalog.
- Separação lógico-física. Um model.json, três estilos de catalogação. Implante novamente com zero retrabalho.
Pontos a considerar
Os modelos base são um ponto de partida, não um produto finalizado. A experiência no domínio ainda importa — a revisão de especialistas sempre melhorará um modelo de maneiras que apenas um profissional que trabalha dentro desse negócio pode ver. Subverticais muito específicas são menos adaptadas por padrão do que os setores convencionais. E organizações com comitês rígidos de aprovação de modelos de dados ainda precisam submeter o resultado a uma revisão; o que muda é a velocidade do artefato, não a exigência de governá-lo.
Acreditamos que essa compensação vale a pena. Um modelo base que é implantado em horas e é estruturalmente sólido é um ponto de partida melhor do que um modelo que leva um ano para ser adaptado.
Experimente hoje mesmo
O repositório de 40 modelos de dados do setor para Lakehouse está em https://github.com/databricks-industry-solutions/databricks-industry-data-models Cada setor é fornecido com um MVM e um ECM. Escolha o escopo que se adapta à sua organização, aponte-o para um Unity Catalog e você terá uma camada Silver implantada, classificada e validada por FK, pronta para análise.
O que vem a seguir
Um modelo base é um ponto de partida; é por isso que todos os modelos estão na v1, e esse não é o formato final. Cada organização tem terminologias, divisões e processos de negócios que mesmo o melhor modelo genérico não conseguirá reproduzir com exatidão. Em uma publicação posterior, mostraremos como personalizar e evoluir os modelos v1 usando um agente de modelagem de IA em linguagem natural — descrevendo as alterações desejadas em linguagem simples e produzindo uma versão personalizada (v2, v3, etc.), preservando o rigor estrutural do original.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.