Jumpstart your Data Modeling with Databricks Industry Data Models
Pre-built, rule-validated and Silver-layer-ready data models for the world's biggest 40 industries — ready to be deployed and governed on the Databricks Platform.
by Amr Ali, Drew Triplett, Franco Patano and Shelley Shaffery
- 40+ industry data models, ready today. Pre-built, rule-validated Silver-layer models for 40 industries, in two scopes (MVM and ECM) — deploy as-is or customize.
- A complete, governed artifact set. Ships as one model.json (plus SQL DDL, DBML, ontology) that deploys to Unity Catalog with Delta tables, foreign keys, classification tags, and metric views.
- Deploy in hours. Point model.json at a Unity Catalog, pick a cataloging style, and get a classified, FK-validated Silver layer.
The Industry Data Model Problem
For three decades, regulated, data-heavy sectors have been sold the same shortcut: buy an industry data model. ACORD for insurance. FHIR and HL7 for healthcare. ARTS for retail. Hundreds — sometimes thousands — of tables, published by a standards body or vendor, pitched as a year of work in a single license.
The pitch is compelling. The reality is more painful. An industry data model is the average of every business in a sector. It does not know your product lines, your geographies, your regulatory footprint, your legacy constraints, your naming customs, or your organizational shape - it doesn't know what differentiates your business. Teams inherit hundreds of tables they will never populate, naming conventions that do not match their terminology, and relationship directions their workloads do not need. Most of the value of buying a template gets spent trimming, renaming, and rewiring it — which is exactly the work the template was supposed to save.
A solid analytical data model, the kind that actually runs production analytics and ML, has historically taken months to years to build.
We are publishing something different. A library of pre-built Lakehouse industry data models, available today in a public repo, ready to deploy as the Silver layer of your Databricks for the world's biggest 40 industries. Each industry data model ships in two scopes and is built on a strict structural ruleset spanning 200+ rules in 14 different modeling domains that make the output production-grade from day one, and the good news is they are not rigid or fixed data models, you have the means to evolve and customize them to fit your organization as required.
Where These Data Models Sit in the Lakehouse
In a Databricks medallion architecture, Bronze holds raw data, Silver holds the conformed analytical base model that every analyst, BI tool, and data scientist reads from, and Gold holds derived metrics, KPIs and aggregates.
These base data models are the Silver layer. Lakeflow and Auto Loader handle ingestion. Each model shipped with pre-calculated metrics like churn_score or monthly_revenue_summary. The base model is the analytical foundation: the place where the business’s concepts become trustworthy tables, ready for BI tools, feature pipelines, and downstream aggregates.
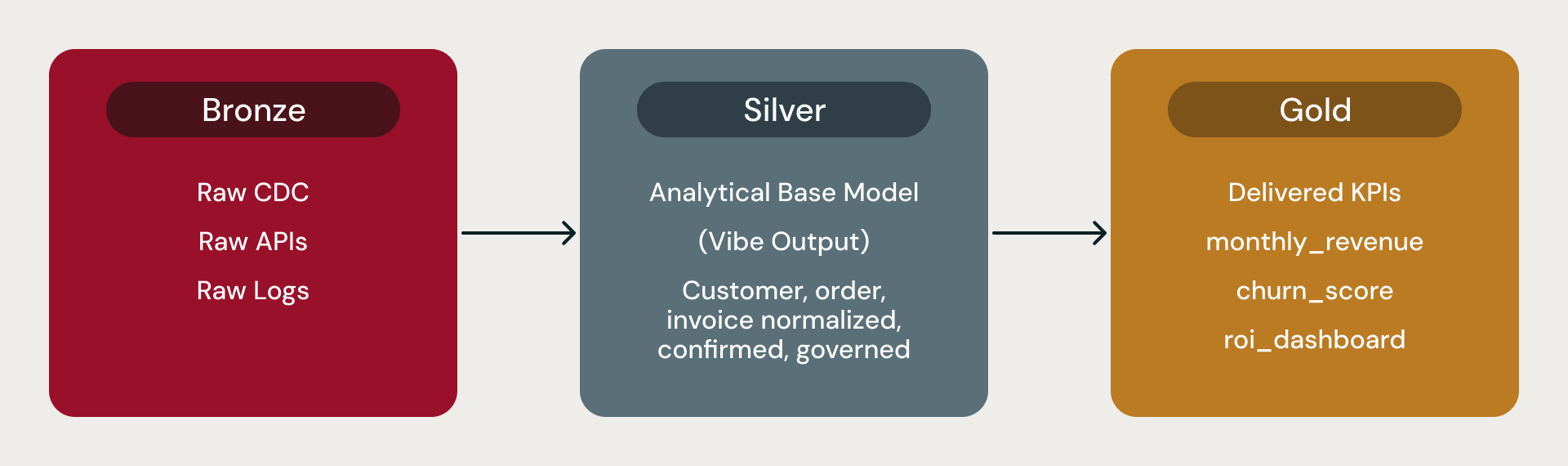
Bronze, Silver, Gold
Two Scopes: MVM and ECM
Every base model is published in two scopes. Both deploy from the same logical model.json; both follow the same rules; both have the same attribute depth per table. The difference is breadth.
Minimum Viable Model (MVM). Thirty to fifty percent of the ECM table count. Essential business functions only. Ideal for SMBs, rapid deployments, proofs of concept, and MVPs. An MVM is not a skeleton or a demo toy — every table has the same attribute richness as its ECM counterpart. The lightness comes from fewer domains and fewer tables, never from thinner tables.
Expanded Coverage Model (ECM). Full coverage. All divisions, including corporate back office. All the domains a Fortune 100 model would expect. Maximum breadth.
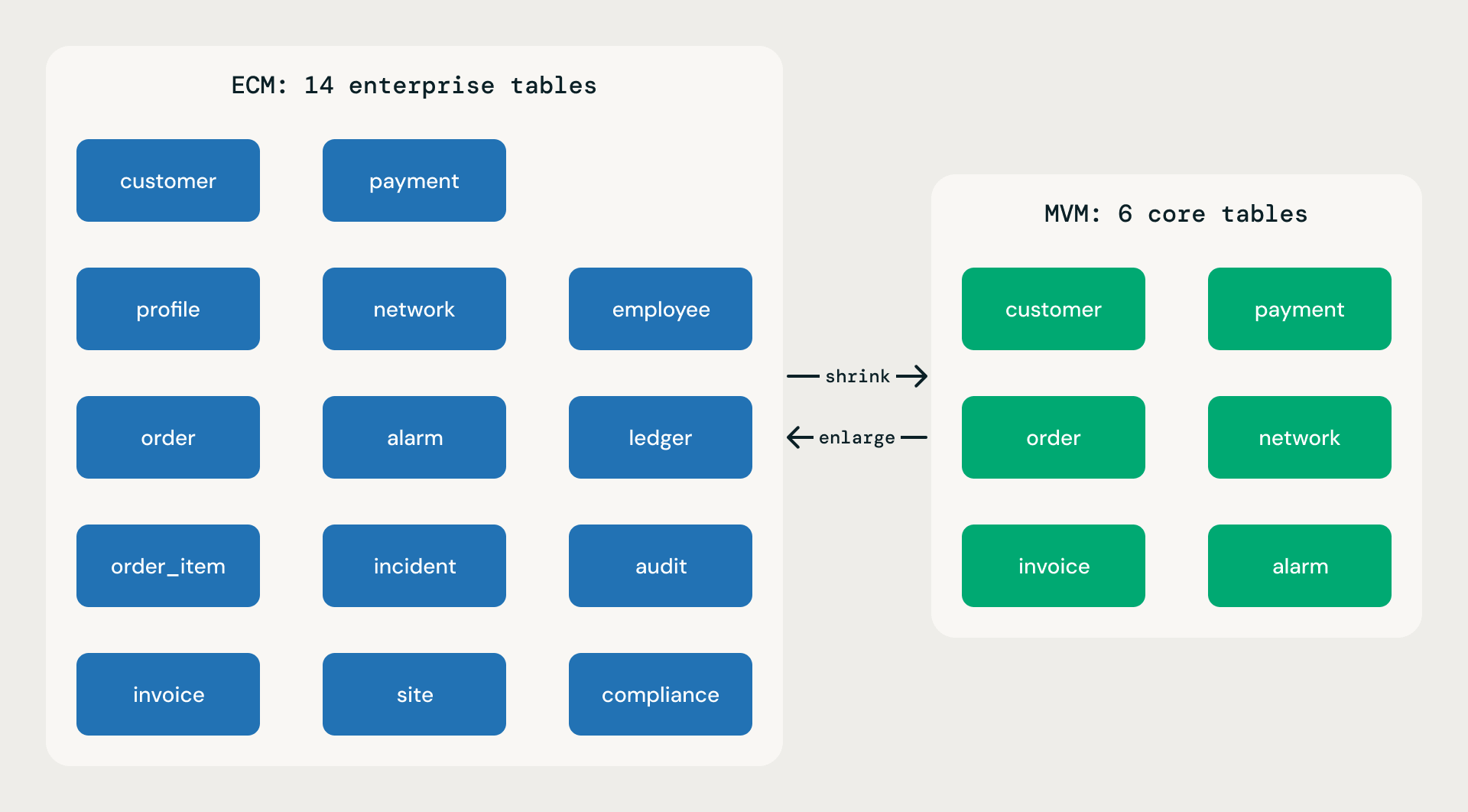
MVM vs ECM Scope
Why do both scopes matter? The goal is not for organizations to spend time fitting the model to their business data, but rather to quickly get started with analytics on the Lakehouse, so starting with the right scope is itself time saved.
The two scopes are not separate maintenance lines. Either can be derived from the other through a single transformation: shrink ecm produces an MVM subset that protects core products and keeps essential foreign keys; enlarge mvm does the opposite. No version is ever overwritten — both operations create a new numbered version alongside the original.
What Makes These Models Different
The base models we are publishing are not committee-standard industry templates renamed. They are produced by a disciplined, rules-driven AI agent that enforces structural quality at every modeling step. A few highlights:
Industry-tier sizing. Every model is sized for the actual complexity of its sector. The classifier uses seven dimensions — regulatory density, party complexity, product hierarchy depth, infrastructure management, industry canonical model, transaction complexity, and operational system landscape — to place each industry in one of five tiers, which then drives the number of domains, products per domain, and attribute depth.
| Tier | Label | Hallmarks | MVM Domains | ECM Products/Domain |
|---|---|---|---|---|
| tier_1 | Ultra-Complex | Banking, insurance, large pharma | 15–22 | 14–28 |
| tier_2 | Complex | Telecoms, energy, healthcare | 12–18 | 14–26 |
| tier_3 | Moderate | Manufacturing, retail | 10–15 | 12–24 |
| tier_4 | Standard | Logistics, agriculture | 8–12 | 10–20 |
| tier_5 | Simple | Consulting, SaaS, media | 5–8 | 8–18 |
Industry-specific jargon. Each model uses the terminology its sector actually speaks. Telecoms get msisdn, arpu, imsi, cdr. Mining gets rom, cut_off_grade, jorc. Healthcare gets icd, cpt, drg. Banking gets iban. These are not afterthoughts — they shape column names, primary key conventions, and the structure of governance tags.
The three-division scaffolding. Every model is organized into three concentric rings:
- Operations is what the business physically does — network, fleet, plant, infrastructure.
- Business is who it serves and how it earns — customer, billing, product, sales.
- Corporate is the supporting scaffolding — HR, finance, compliance.
The ratio is enforced by rules (rule G06-R001): Operations plus Business must be at least 80% of all domains; Corporate is capped at 20%. This prevents the most common failure mode of unconstrained modeling — models that are half HR, finance, and legal, and light on the operational core that actually runs the business.
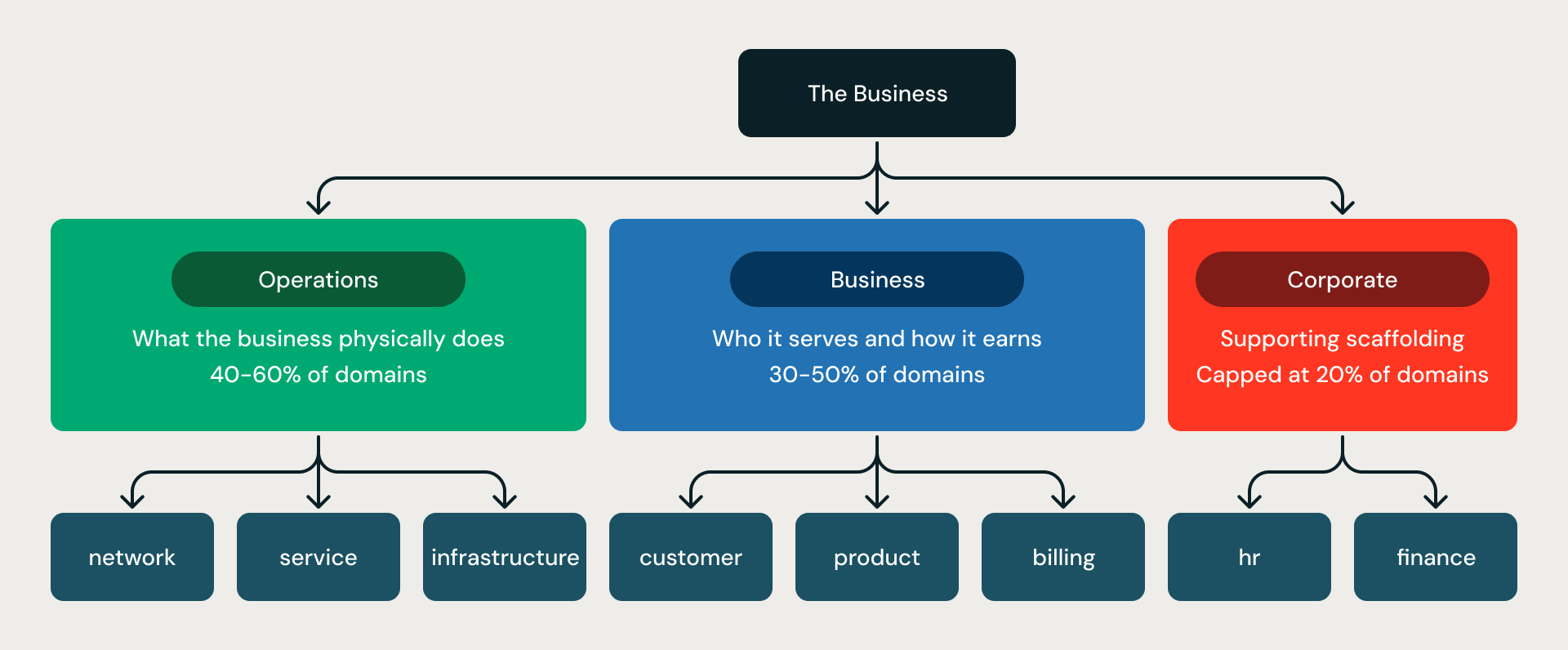
The Three Divisions
The six-level hierarchy. Every model follows the same strict shape: Organization → Division → Domain → Subdomain → Product → Attribute. The hierarchy is not a suggestion; it is enforced by structural rules, by two levels of architect review, and by static analysis at the end of every pipeline.
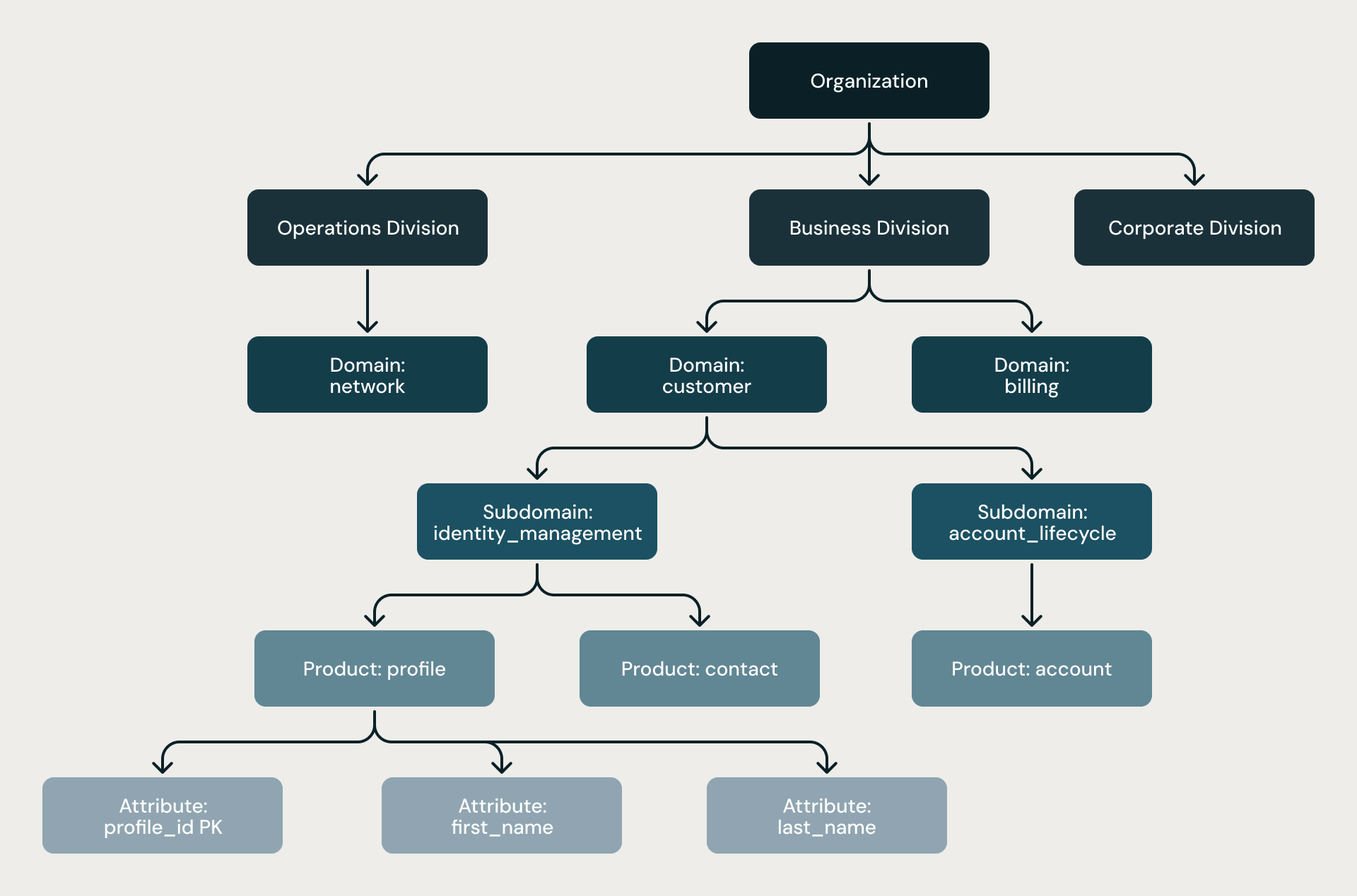
Four-Level Hierarchy
Over 200 enforceable rules. Every base model is validated against more than 200 rules organized into 14+ groups — naming conventions, semantic deduplication, foreign keys, primary keys, normalization, domain structure, data types, classification tags, relationship/DAG enforcement, quality, product design, vibe constraints, physical schema deployment, and subdomain sizing. Every table must have a primary key. Every foreign key points to an actual target. Every domain passes the org chart test: “Could a real department/team with this name exist in the organization?” No cycles. No silos, and strict Single Source Of Truth (SSOT) adherence.
One logical model, three physical layouts. Each base model ships as a single model.json that is environment-independent. The same logical model deploys cleanly to Unity Catalog in three cataloging styles: one catalog (single governance boundary), catalog per division (Operations / Business / Corporate isolated), or catalog per domain (data-mesh friendly). Redeploy to a different style and nothing about the logical model is touched.
A Worked Example: The Airline ECM Model v1
To make this concrete, here is the airline ECM that ships in the repo today.
| Metric | Value |
|---|---|
| Model Scope | ECM v1 |
| Total Domains | 19 |
| Total Subdomains | 60 |
| Total Products | 420 |
| Total Attributes | 17,278 |
| Primary Keys | 420 |
| Foreign Keys | 2,877 |
| Avg Attributes/Product | 41.1 |
| Metric Views | 203 |
Visualized as a graph, the full DAG looks like this (every rectangle is a domain, every tiny circle is a table, and every line is an FK link):

Airline ECM v1 as a Connected DAG
The nineteen domains break out cleanly across the three divisions. Operations holds airport, crew, fleet, flight, inventory, maintenance, and route. Business holds ancillary, cargo, loyalty, passenger, reservation, revenue, service, and ticket. Corporate holds compliance, finance, safety, and workforce.

Airline Domains by Division
Drill into a single domain — flight operations — and the structure becomes legible at a working level. Subdomains for resource loading, flight operations, and passenger services hold the products an operations analyst actually reaches for: leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment. (every circle is a table, every line is a FK relationship)

Flight Domain
Drill further, to a single data product — the Air Waybill (awb) inside the cargo domain — and you can see exactly how cross-domain links work. awb connects to corporate_account in the passenger domain, station in airport, leg in flight, profit_center, ledger_account, and company_code in finance, and screening_result in compliance. These are the joins a cargo revenue analyst runs every day, and they are present because the cross-domain DAG was built to support them.

Air Waybill Data Product
What You Get When You Deploy
Every base model ships with a complete artifact set.
Logical artifacts. A single model.json (the primary interchange format), a human-readable readme.md, flat exports of domains, products, and attributes, Excel and CSV exports, SQL DDL files (one per domain plus a cross-domain FK file), a DBML schema diagram, and an RDF/Turtle ontology.
Physical artifacts when you deploy to a Unity Catalog. Unity Catalog schemas (one per domain or per subdomain, depending on cataloging style), Delta tables for every product, foreign-key constraints applied in dependency order, Unity Catalog classification tags (PII, restricted, public), Databricks metric views for reusable KPI definitions, and synthetic sample data with valid FK references for immediate exploration.
The model.json file is the unit of currency. Check it into git. Diff two versions. Share it across environments. Hand it to a security reviewer without giving away production access. Redeploy it to dev, staging, and prod under three different cataloging styles and get three environments whose logical content is byte-identical.
Where This Approach Is Strong
- Speed. Silver-layer foundations that used to take months are now a deploy step.
- Specificity. Models use the language of the sector — its jargon, its regulatory shape, its operational reality.
- Rule coverage. Over 200 enforceable rules mean consistency most hand-written models never reach.
- Governance. Every column with sensitive data is classified and tagged. Every PK/FK follows a single convention. Every cataloging style is reproducible.
- Dual shape. The same artifact is a relational schema, a DBML diagram, a knowledge-graph ontology, and a physical Unity Catalog deployment.
- Logical-physical separation. One model.json, three cataloging styles. Redeploy with zero rework.
Things to Consider
The base models are a starting point, not a finished deliverable. Domain expertise still matters — expert review will always improve a model in ways only a practitioner working inside that business can see. Very narrow sub-verticals are less idiomatic out of the box than mainstream industries. And organizations with strict data-model approval committees still need to run the output through review; what changes is the speed of the artifact, not the requirement to govern it.
We think the tradeoff is the right one. A base model that deploys in hours and is structurally sound is a better starting point than a template that takes a year to adapt.
Try It Today
The 40 Lakehouse industry data models repository is at https://github.com/databricks-industry-solutions/databricks-industry-data-models Each industry ships with both an MVM and an ECM. Pick the scope that fits your organization, point it at a Unity Catalog, and you have a deployed, classified, FK-validated Silver layer ready for analytics.
Coming Next
A base model is a starting point; that's why all models stand at v1, and that’s not the final shape. Every organization has terminology, divisions, and business processes that even the best generic model will not get exactly right. In a follow-up post, we walk through how to customize and evolve the v1 models using a natural-language AI modeling agent — describing the changes you want in plain English and producing a tailored version (v2, v3, etc), while preserving the structural rigor of the original.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.