Lakeflow Connect: Ingestão de Dados Eficiente e Fácil usando o conector SQL Server
Explore o Conector SQL Server totalmente gerenciado do Databricks Lakeflow Connect para simplificar a ingestão e integração de dados de maneira contínua com as ferramentas Databricks para processamento e análise de dados
por Andrea Tardif, Prasanna Selvaraj, Hector Bustamante e Phanitha Kommareddi
- As principais empresas de tecnologia enfrentam desafios complexos ao extrair valor de seus dados do SQL Server para IA e análises.
- O Lakeflow Connect para SQL Server oferece ingestão incremental eficiente para bancos de dados locais e na nuvem.
- Este blog revisa considerações arquitetônicas, pré-requisitos e instruções passo a passo para ingerir dados do SQL Server em seu lakehouse.
Complexidades da Extração de Dados do SQL Server
Embora empresas nativas digitais reconheçam o papel crítico da IA na promoção da inovação, muitas ainda enfrentam desafios para tornar seus dados prontamente disponíveis para usos downstream, como desenvolvimento de aprendizado de máquina e análises avançadas. Para essas organizações, apoiar equipes de negócios que dependem do SQL Server significa ter recursos de engenharia de dados e manter conectores personalizados, preparar dados para análises e garantir que estejam disponíveis para equipes de dados para desenvolvimento de modelos. Muitas vezes, esses dados precisam ser enriquecidos com fontes adicionais e transformados antes que possam informar decisões orientadas por dados.
Manter esses processos rapidamente se torna complexo e frágil, retardando a inovação. É por isso que a Databricks desenvolveu o Lakeflow Connect, que inclui conectores de dados integrados para bancos de dados populares, aplicativos empresariais e fontes de arquivos. Esses conectores fornecem ingestão incremental eficiente de ponta a ponta, são flexíveis e fáceis de configurar, e estão totalmente integrados com a Plataforma de Inteligência de Dados Databricks para governança unificada, observabilidade e orquestração. O novo conector Lakeflow SQL Server é o primeiro conector de banco de dados com integração robusta para bancos de dados locais e na nuvem para ajudar a obter insights de dados dentro da Databricks.
Neste blog, vamos revisar as principais considerações para quando usar o Lakeflow Connect para SQL Server e explicar como configurar o conector para replicar dados de uma instância do Azure SQL Server. Então, vamos revisar um caso de uso específico, melhores práticas e como começar.
Principais Considerações Arquitetônicas
Abaixo estão as principais considerações para ajudar a decidir quando usar o conector do SQL Server.
Compatibilidade de Região & Recurso
O Lakeflow Connect suporta uma ampla gama de variações de banco de dados SQL Server, incluindo Microsoft Azure SQL Database, Amazon RDS para SQL Server, Microsoft SQL Server rodando em VMs Azure e Amazon EC2, e SQL Server local acessado através do Azure ExpressRoute ou AWS Direct Connect.
Como o Lakeflow Connect é executado em pipelines Serverless, recursos integrados como observabilidade de pipeline, alertas de log de eventos e monitoramento de lakehouse podem ser aproveitados. Se o Serverless não for suportado em sua região, trabalhe com sua equipe de conta Databricks para enviar uma solicitação para ajudar a priorizar o desenvolvimento ou implantação nessa região.
Lakeflow Connect é construído na Plataforma de Inteligência de Dados, que proporciona uma integração perfeita com o Catálogo Unity (UC) para reutilizar permissões estabelecidas e controles de acesso em novas fontes do SQL Server para uma governança unificada. Se suas tabelas e visualizações do Databricks estão no Hive, recomendamos atualizá-las para UC para se beneficiar desses recursos (AWS | Azure | GCP)!
Alterar Requisitos de Dados
O Lakeflow Connect pode ser integrado a um servidor SQL com rastreamento de alterações da Microsoft (CT) ou Captura de Dados de Alteração da Microsoft (CDC) habilitados para suportar ingestão incremental eficiente.
O CDC fornece informações históricas sobre operações de inserção, atualização e exclusão, e quando os dados reais foram alterados. O rastreamento de alterações identifica quais linhas foram modificadas em uma tabela sem capturar as próprias alterações de dados. Saiba mais sobre CDC e os benefícios do uso do CDC com o SQL Server.
A Databricks recomenda o uso de rastreamento de alterações para qualquer tabela com uma chave primária para minimizar a carga no banco de dados de origem. Para tabelas de origem sem uma chave primária, use CDC. Saiba mais sobre quando usar aqui.
O conector do SQL Server captura uma carga inicial de dados históricos na primeira execução do seu pipeline de ingestão. Em seguida, o conector rastreia e ingere apenas as alterações feitas nos dados desde a última execução, aproveitando os recursos CT/CDC do SQL Server para otimizar operações e eficiência.
Governança & Segurança de Rede Privada
Quando uma conexão é estabelecida com um SQL Server usando o Lakeflow Connect:
- O tráfego entre a interface do cliente e o plano de controle é criptografado em trânsito usando TLS 1.2 ou posterior.
- O volume de staging, onde os arquivos brutos são armazenados durante a ingestão, é criptografado pelo provedor de armazenamento em nuvem subjacente.
- Os dados em repouso são protegidos seguindo as melhores práticas e padrões de conformidade.
- Quando configurado com pontos finais privados, todo o tráfego de dados permanece dentro da rede privada do provedor de nuvem, evitando a internet pública.
Uma vez que os dados são ingeridos no Databricks, eles são criptografados como outros conjuntos de dados dentro do UC. O gateway de ingestão que extrai snapshots, logs de alterações e metadados do banco de dados de origem aterrissa em um Volume UC, uma abstração de armazenamento melhor para registrar conjuntos de dados não tabulares, como arquivos JSON. Este Volume UC reside dentro da conta de armazenamento em nuvem do cliente, dentro de suas Redes Virtuais ou Nuvens Privadas Virtuais.
Além disso, o UC impõe controles de acesso refinados e mantém registros de auditoria para governar o acesso a esses dados recém-ingestados. As credenciais de serviço e credenciais de armazenamento do UC são armazenadas como objetos seguráveis dentro do UC, garantindo uma gestão de autenticação segura e centralizada. Essas credenciais nunca são expostas em logs ou codificadas em pipelines de ingestão SQL, proporcionando proteção robusta e controle de acesso.
Se a sua organização atende aos critérios acima, considere o Lakeflow Connect para SQL Server para ajudar a simplificar a ingestão de dados na Databricks.
Desmembramento da Solução Técnica
Em seguida, revise as etapas para configurar o Lakeflow Connect para SQL Server e replicar dados de uma instância do Azure SQL Server.
Configurar Permissões do Catálogo Unity
No Databricks, certifique-se de que o cálculo sem servidor está habilitado para notebooks, fluxos de trabalho e pipelines (AWS | Azure | GCP). Em seguida, valide se o usuário ou o principal do serviço que está criando o pipeline de ingestão possui as seguintes permissões UC:
|
Tipo de Permissão |
Motivo: |
Documentação |
|
CRIAR CONEXÃO no metastore |
O Lakeflow Connect precisa estabelecer uma conexão segura com o SQL Server. |
|
|
USE CATALOG no catálogo de destino |
Necessário, pois fornece acesso ao catálogo onde o Lakeflow Connect irá aterrissar as tabelas de dados do SQL Server no UC. |
|
|
USE SCHEMA, CREATE TABLE e CREATE VOLUME em um esquema existente ou CREATE SCHEMA no catálogo de destino |
Fornece os direitos necessários para acessar esquemas e criar locais de armazenamento para tabelas de dados ingeridos. |
|
|
Permissões irrestritas para criar clusters, ou uma política de cluster personalizada |
Necessário para acionar os recursos computacionais necessários para o processo de ingestão do gateway |
Configurar o Servidor SQL Azure
Para usar o conector SQL Server, confirme que os seguintes requisitos são atendidos:
- Confirmar Versão SQL
- SQL Server 2012 ou uma versão posterior deve estar habilitado para usar o rastreamento de alterações. No entanto, é recomendado 2016+*. Revise os requisitos da versão SQL aqui.
- Configurar a conta de serviço do banco de dados dedicada à ingestão do Databricks.
- Ative o rastreamento de alterações ou CDC integrado
- Você deve ter o SQL Server 2012 ou uma versão posterior para usar o CDC. Versões anteriores ao SQL Server 2016 também exigem a edição Enterprise.
* Requisitos a partir de maio de 2025. Sujeito a alterações.
Exemplo: Ingestão do Azure SQL Server para Databricks
Em seguida, vamos ingerir uma tabela de um banco de dados Azure SQL Server para Databricks usando o Lakeflow Connect. Neste exemplo, CDC e CT fornecem uma visão geral de todas as opções disponíveis. Como a tabela neste exemplo tem uma chave primária, CT poderia ter sido a escolha principal. No entanto, como há apenas uma pequena tabela neste exemplo, não há preocupação com a sobrecarga de carga, então CDC também foi incluído. É recomendado revisar quando usar CDC, CT, ou ambos para determinar qual é o melhor para seus dados e requisitos de atualização.
1. [Azure SQL Server] Verifique e configure o Azure SQL Server para CDC e CT
Comece acessando o portal Azure e faça login usando suas credenciais de conta Azure. No lado esquerdo, clique em Todos os serviços e procure por SQL Servers. Encontre e clique no seu servidor, e clique em 'Query Editor'; neste exemplo, o sqlserver01 foi selecionado.
A captura de tela abaixo mostra que o banco de dados do SQL Server tem uma tabela chamada 'drivers'.
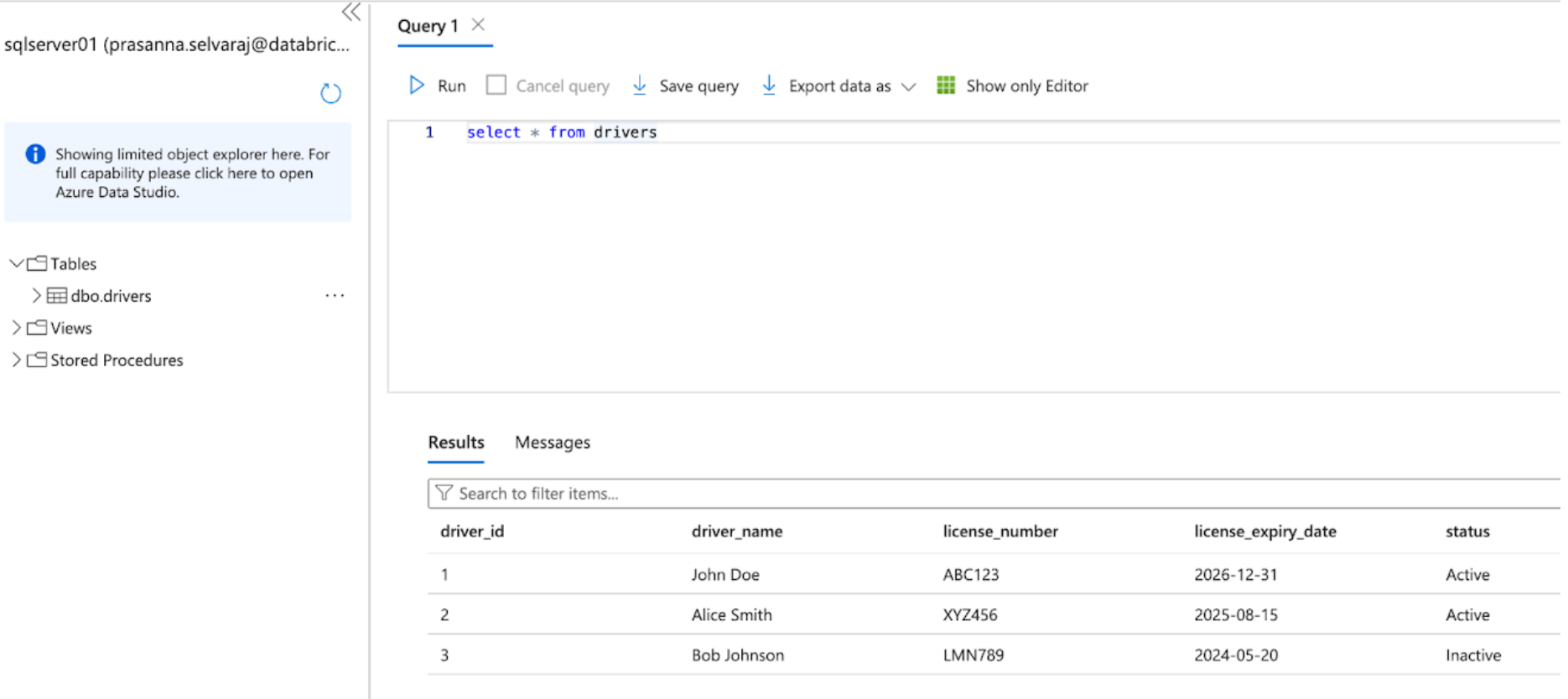
Antes de replicar os dados para o Databricks, a captura de alterações de dados, o rastreamento de alterações ou ambos devem estar habilitados.
Para este exemplo, o seguinte script é executado no banco de dados para habilitar o CT:
Este comando habilita o rastreamento de alterações para o banco de dados com os seguintes parâmetros:
- CHANGE_RETENTION = 3 DAYS: Este valor rastreia alterações por 3 dias (72 horas). Uma atualização completa será necessária se o seu gateway ficar offline por mais tempo do que o tempo definido. É recomendado que este valor seja aumentado se forem esperadas interrupções mais prolongadas.
- AUTO_CLEANUP = ON: Esta é a configuração padrão. Para manter o desempenho, ele remove automaticamente os dados de rastreamento de alterações mais antigos do que o período de retenção.
Em seguida, o seguinte script é executado no banco de dados para habilitar o CDC:
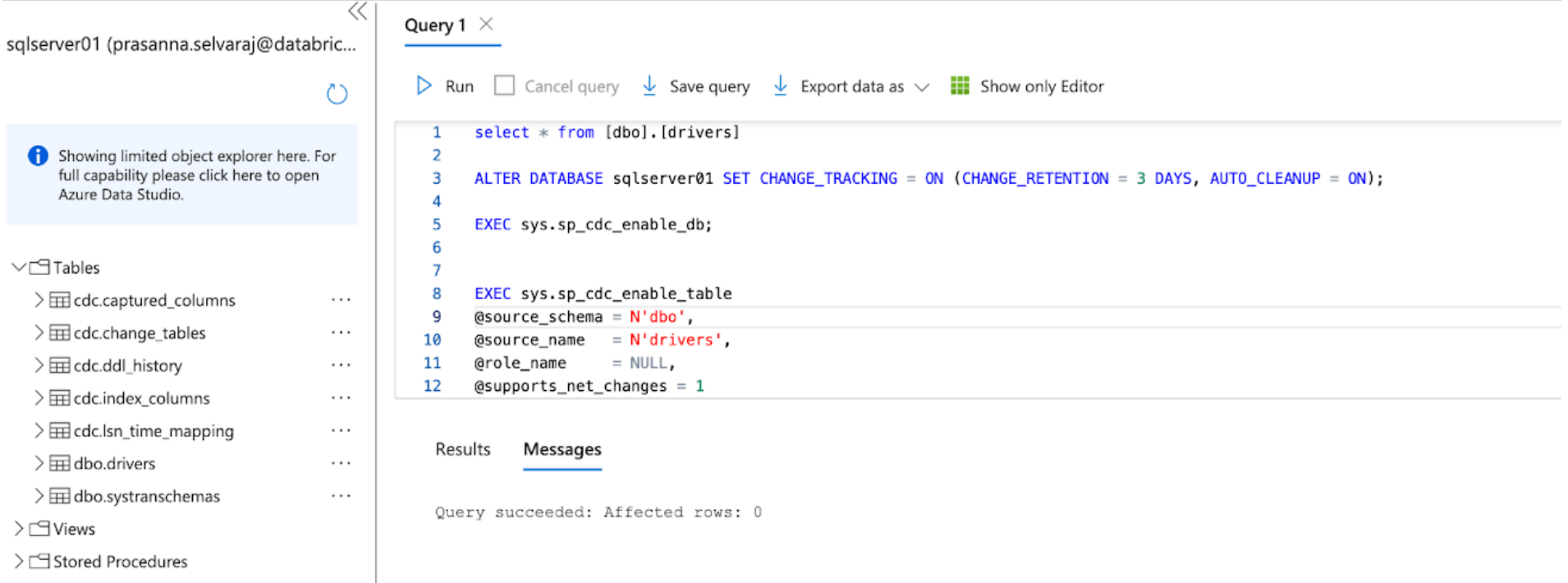
Quando ambos os scripts terminarem de executar, revise a seção de tabelas sob a instância do servidor SQL no Azure e garanta que todas as tabelas CDC e CT foram criadas.
2. [Databricks] Configure o conector SQL Server no Lakeflow Connect
Neste próximo passo, a interface do usuário da Databricks será mostrada para configurar o conector do SQL Server. Alternativamente, Databricks Asset Bundles (DABs), uma maneira programática de gerenciar os pipelines do Lakeflow Connect como código, também pode ser aproveitada. Um exemplo do script completo do DABs está no apêndice abaixo.
Uma vez que todas as permissões estão definidas, conforme descrito na seção Pré-requisitos de Permissão, você está pronto para ingerir dados. Clique no botão + Novo no canto superior esquerdo, em seguida, selecione Adicionar ou fazer upload de dados.
Em seguida, selecione a opção SQL Server.
O conector SQL Server é configurado em várias etapas.
1. Configure o gateway de ingestão (AWS | Azure | GCP). Nesta etapa, forneça um nome para o pipeline de gateway de ingestão e um catálogo e esquema para o local do Volume UC para extrair snapshots e alterar continuamente os dados do banco de dados de origem.
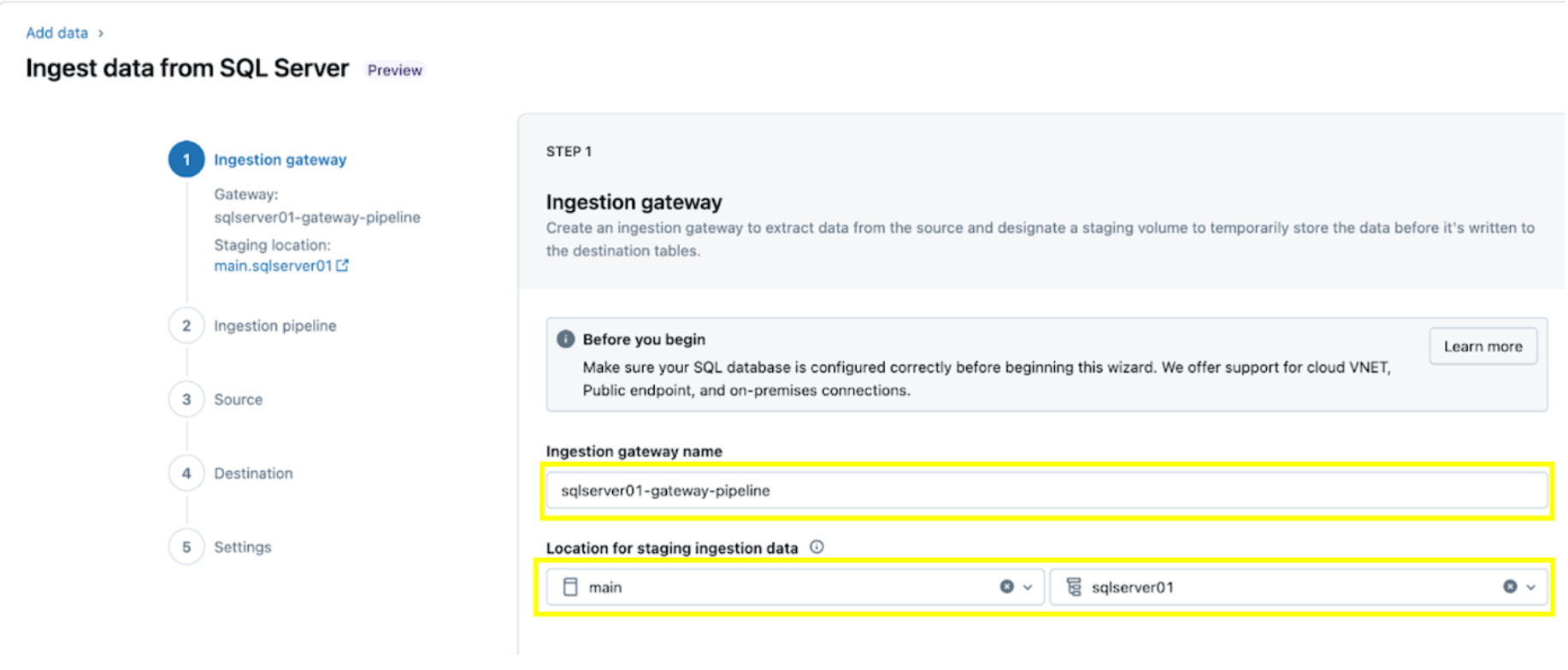
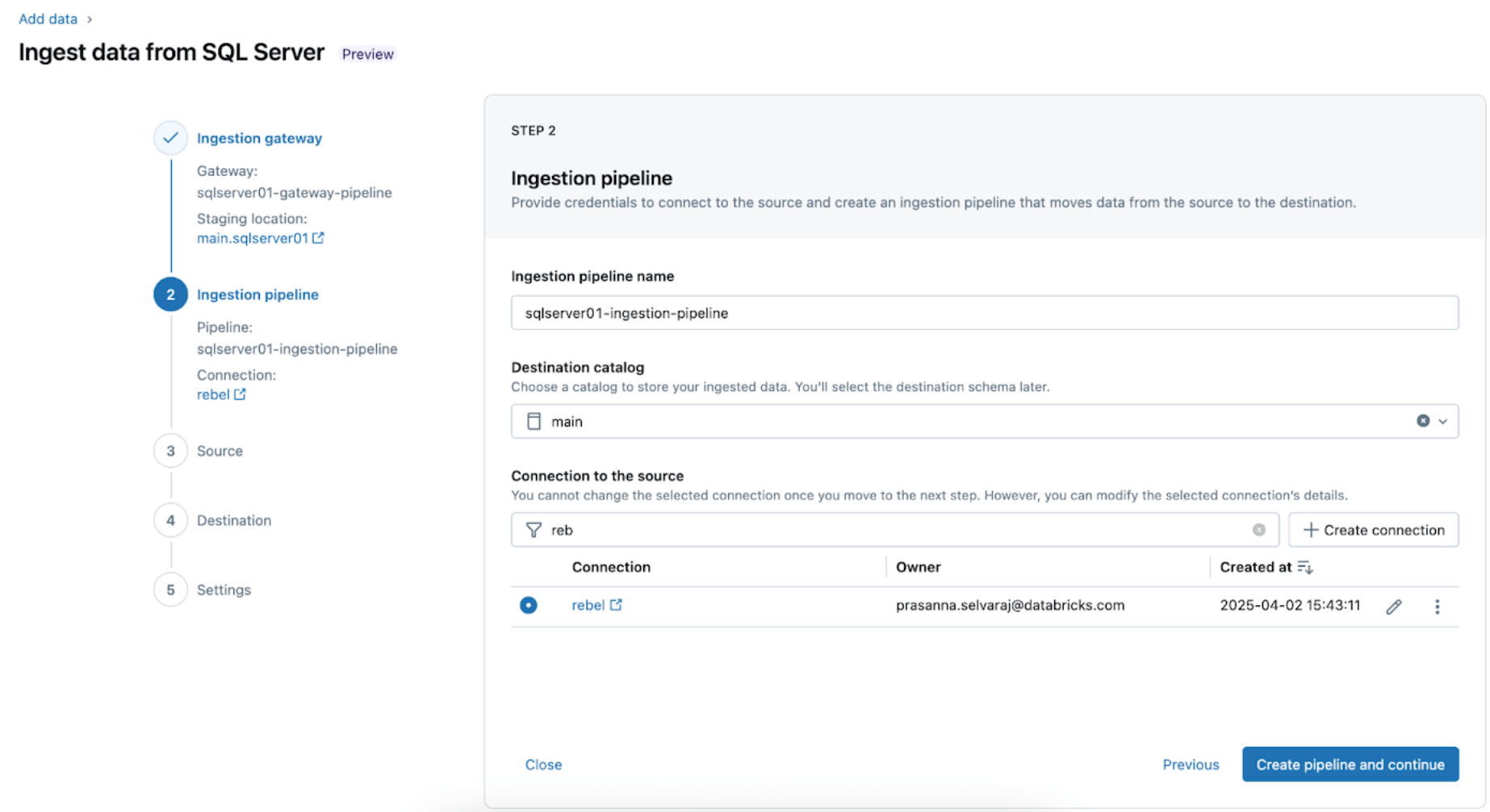
2. Configure o pipeline de ingestão. Isso replica a fonte de dados CDC/CT e os eventos de evolução do esquema. É necessária uma conexão com o SQL Server, que é criada através da interface do usuário seguindo estas etapas ou com o seguinte código SQL abaixo:
Para este exemplo, nomeie a conexão do servidor SQL rebel como mostrado.
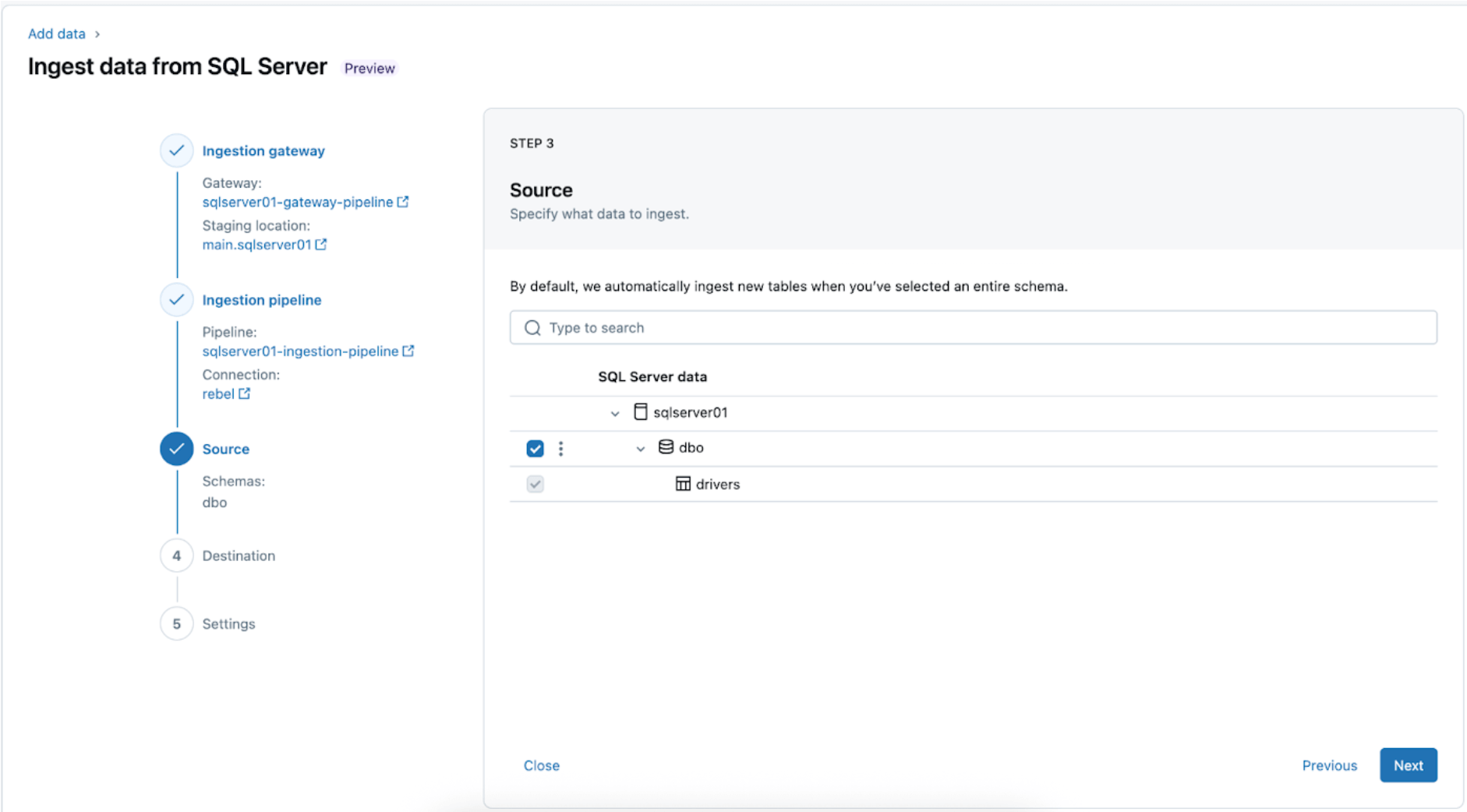
3. Selecionando as tabelas do SQL Server para replicação. Selecione todo o esquema a ser ingerido no Databricks em vez de escolher tabelas individuais para ingestão.
Todo o esquema pode ser ingerido no Databricks durante a exploração inicial ou migrações. Se o esquema for grande ou exceder o número permitido de tabelas por pipeline (veja limites do conector), a Databricks recomenda dividir a ingestão em vários pipelines para manter o desempenho ideal. Para fluxos de trabalho específicos de casos de uso, como um único modelo de ML, painel ou relatório, geralmente é mais eficiente ingerir tabelas individuais adaptadas a essa necessidade específica, em vez de todo o esquema.
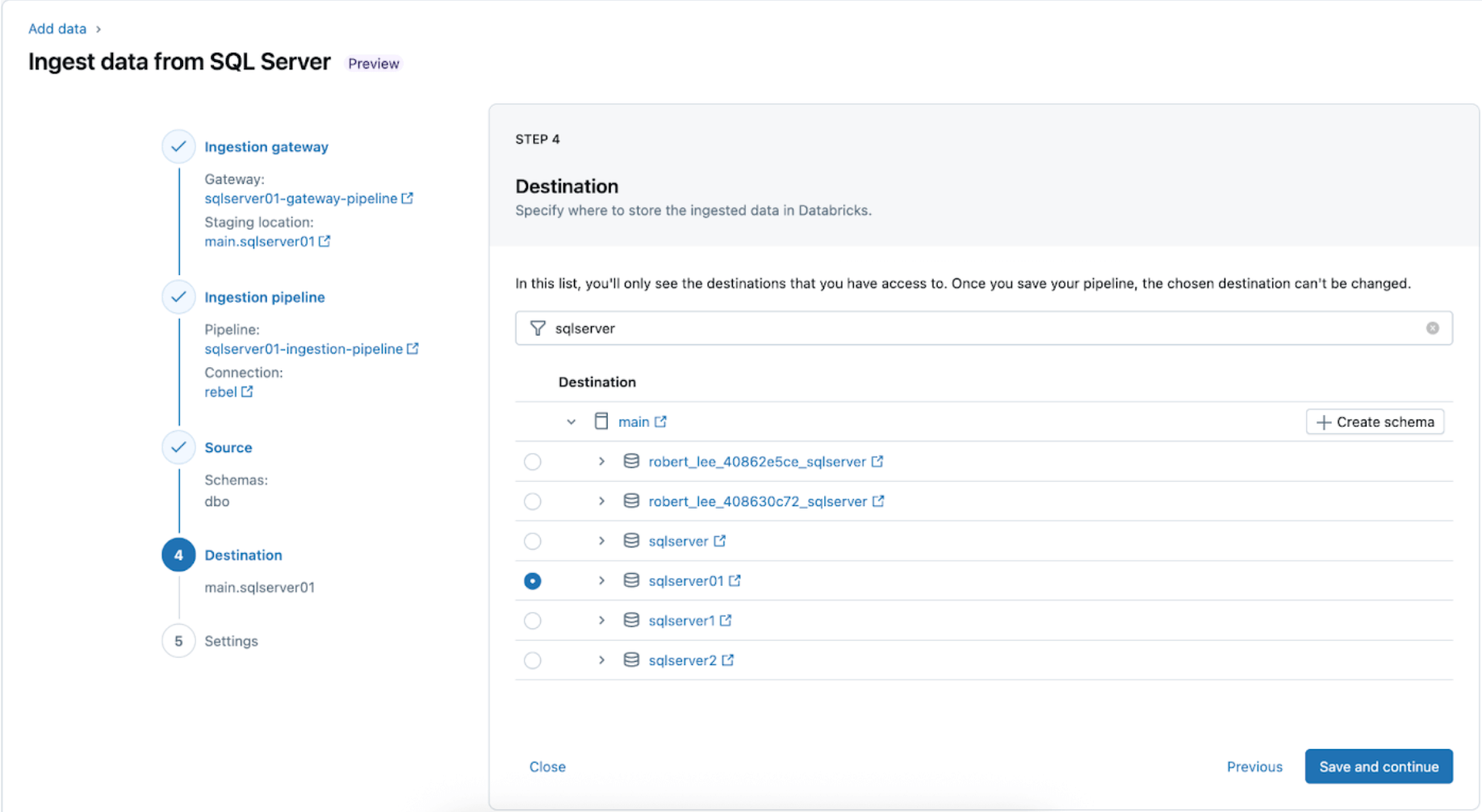
4. Configure o destino onde as tabelas do SQL Server serão replicadas dentro do UC. Selecione o catálogo principal e o esquema sqlserver01 para aterrissar os dados no UC.
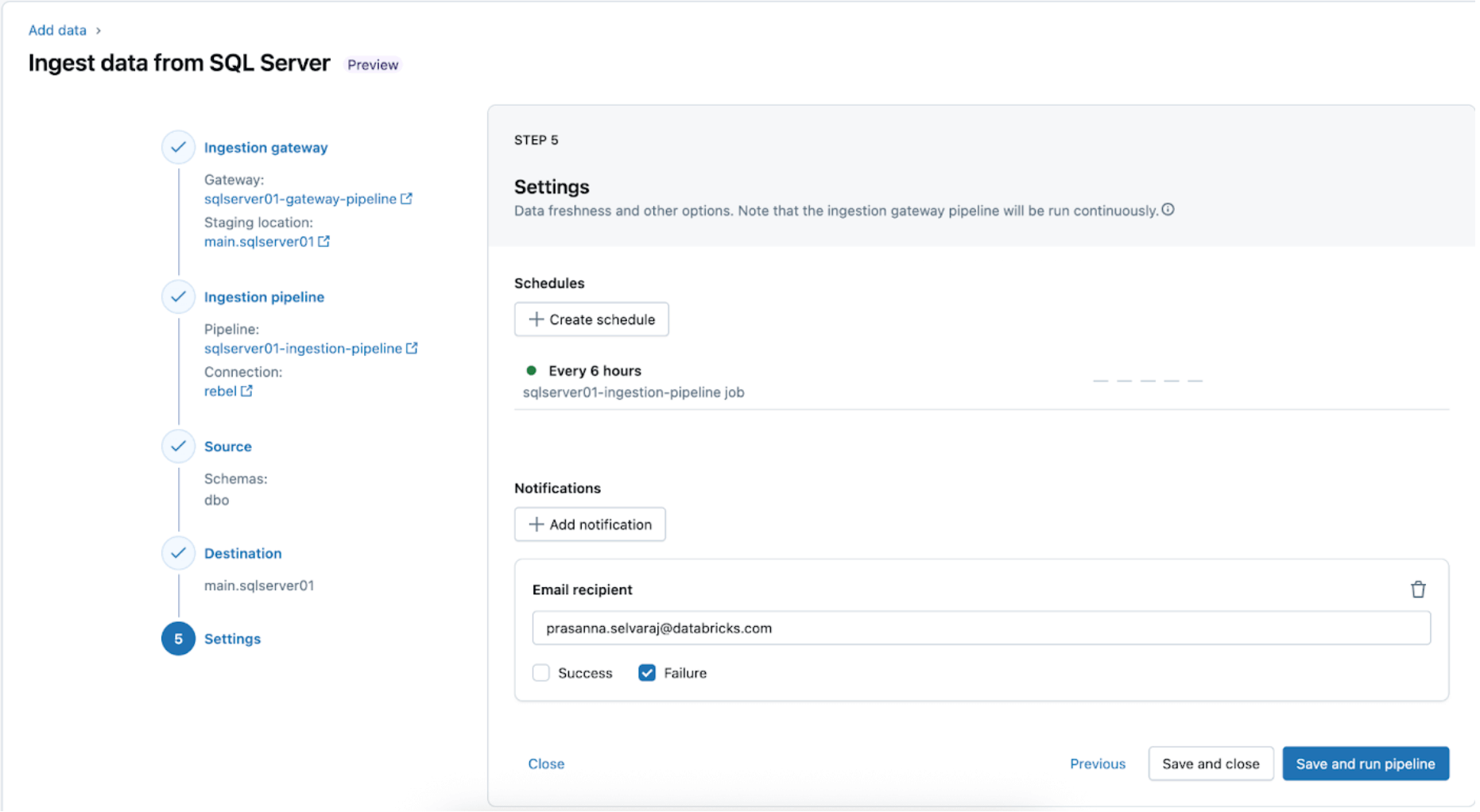
5. Configure horários e notificações (AWS | Azure | GCP). Esta etapa final ajudará a determinar com que frequência executar o pipeline e onde as mensagens de sucesso ou falha devem ser enviadas. Configure o pipeline para ser executado a cada 6 horas e notifique o usuário apenas sobre falhas do pipeline. Este intervalo pode ser configurado para atender às necessidades da sua carga de trabalho.
O pipeline de ingestão pode ser acionado em um cronograma personalizado. O Lakeflow Connect criará automaticamente um trabalho dedicado para cada gatilho de pipeline programado. O pipeline de ingestão é uma tarefa dentro do trabalho. Opcionalmente, mais tarefas podem ser adicionadas antes ou depois da tarefa de ingestão para qualquer processamento downstream.
Após esta etapa, o pipeline de ingestão é salvo e acionado, iniciando um carregamento completo de dados do SQL Server para o Databricks.
3. [Databricks] Valide as execuções bem-sucedidas dos pipelines de Gateway e Ingestão
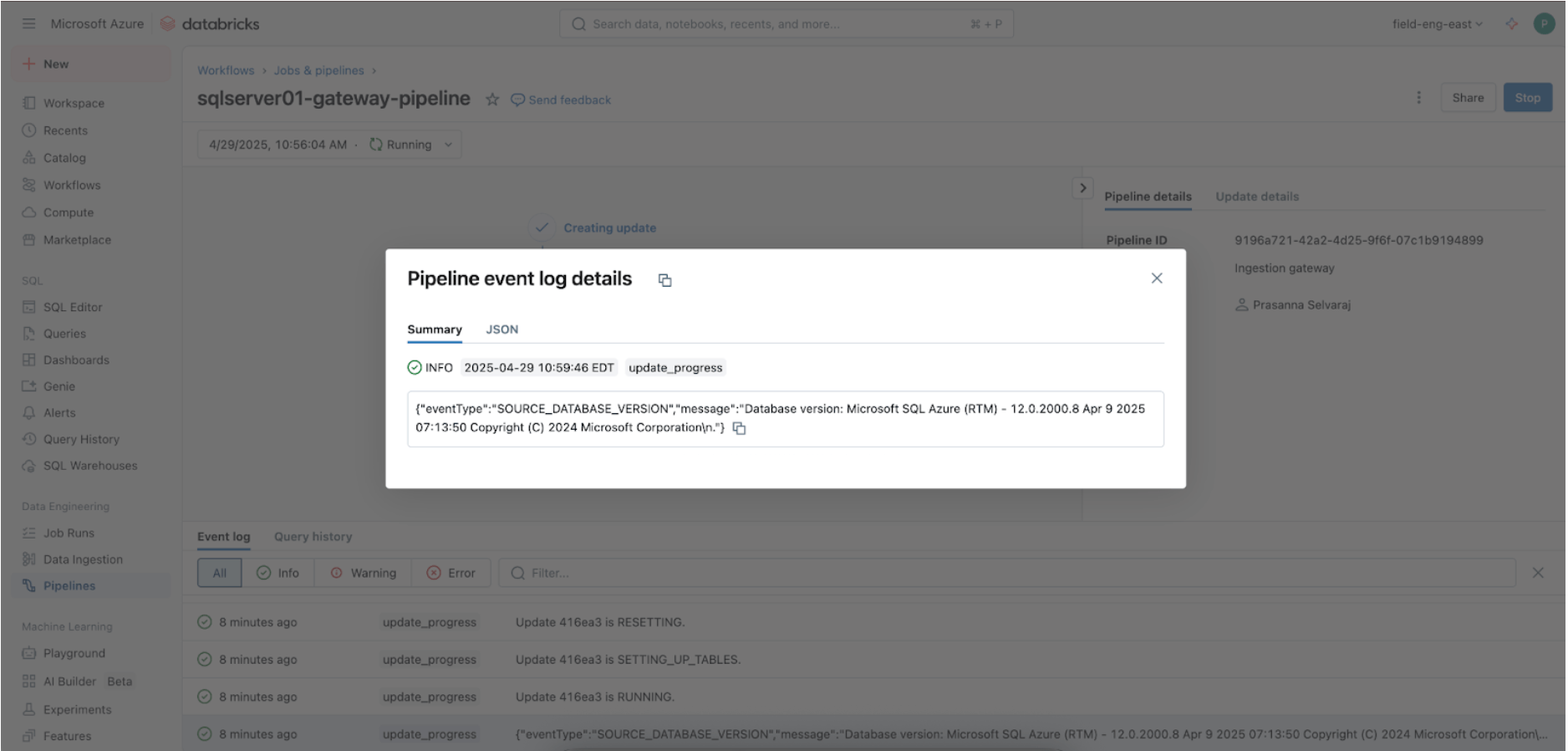
Navegue até o menu Pipeline para verificar se o pipeline de ingestão do gateway está em execução. Uma vez concluído, procure por 'update_progress' dentro da interface do log de eventos do pipeline na parte inferior para garantir que o gateway ingere com sucesso os dados de origem.
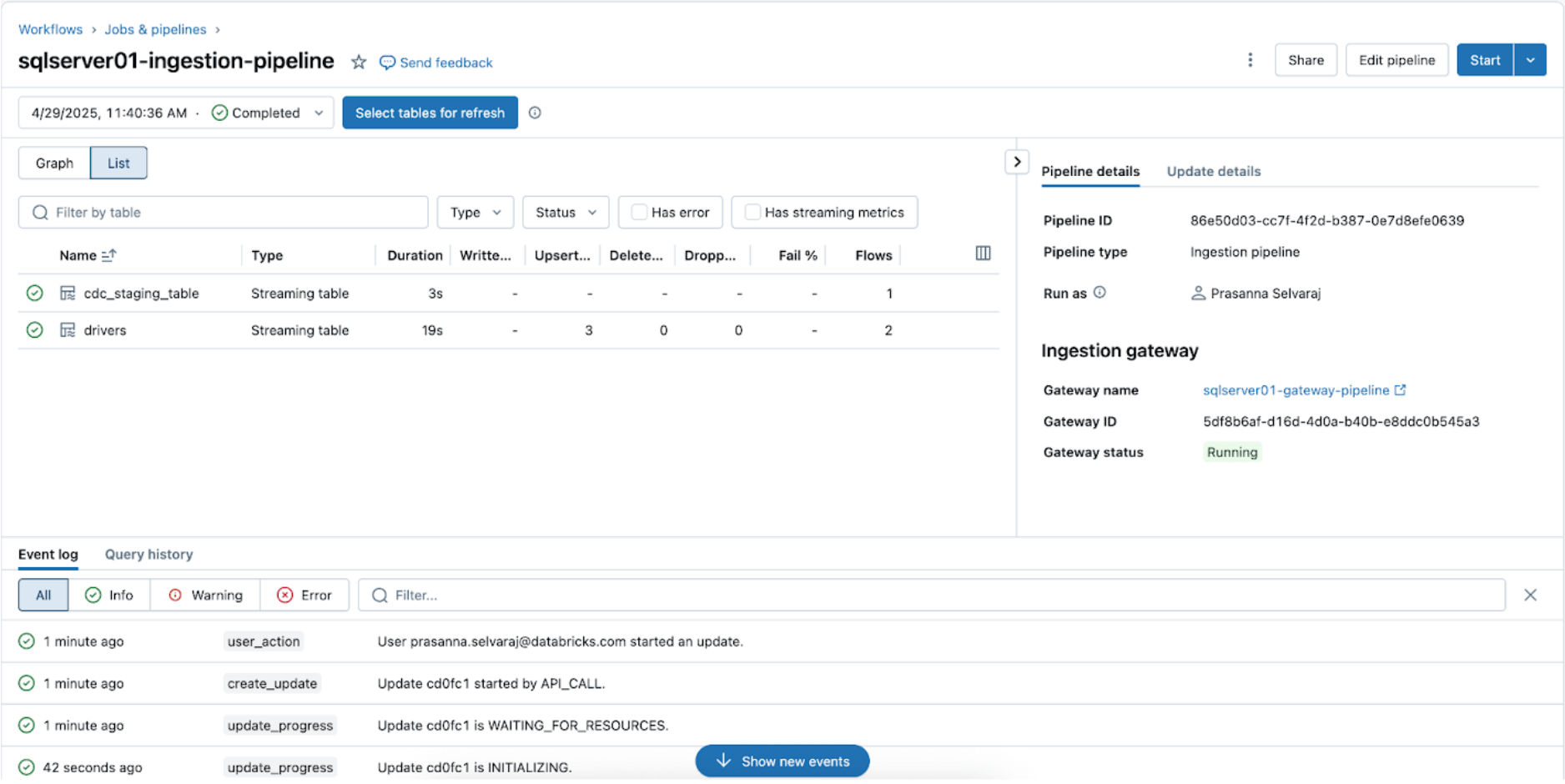
Para verificar o status de sincronização, navegue até o menu do pipeline. A captura de tela abaixo mostra que o pipeline de ingestão realizou três operações de inserção e atualização (UPSERT).
Navegue até o catálogo de destino, principal, e esquema, sqlserver01, para visualizar a tabela replicada, conforme mostrado abaixo.

4. [Databricks] Teste CDC e Evolução de Esquema
Em seguida, verifique um evento CDC realizando operações de inserção, atualização e exclusão na tabela de origem. A captura de tela do Azure SQL Server abaixo mostra os três eventos.
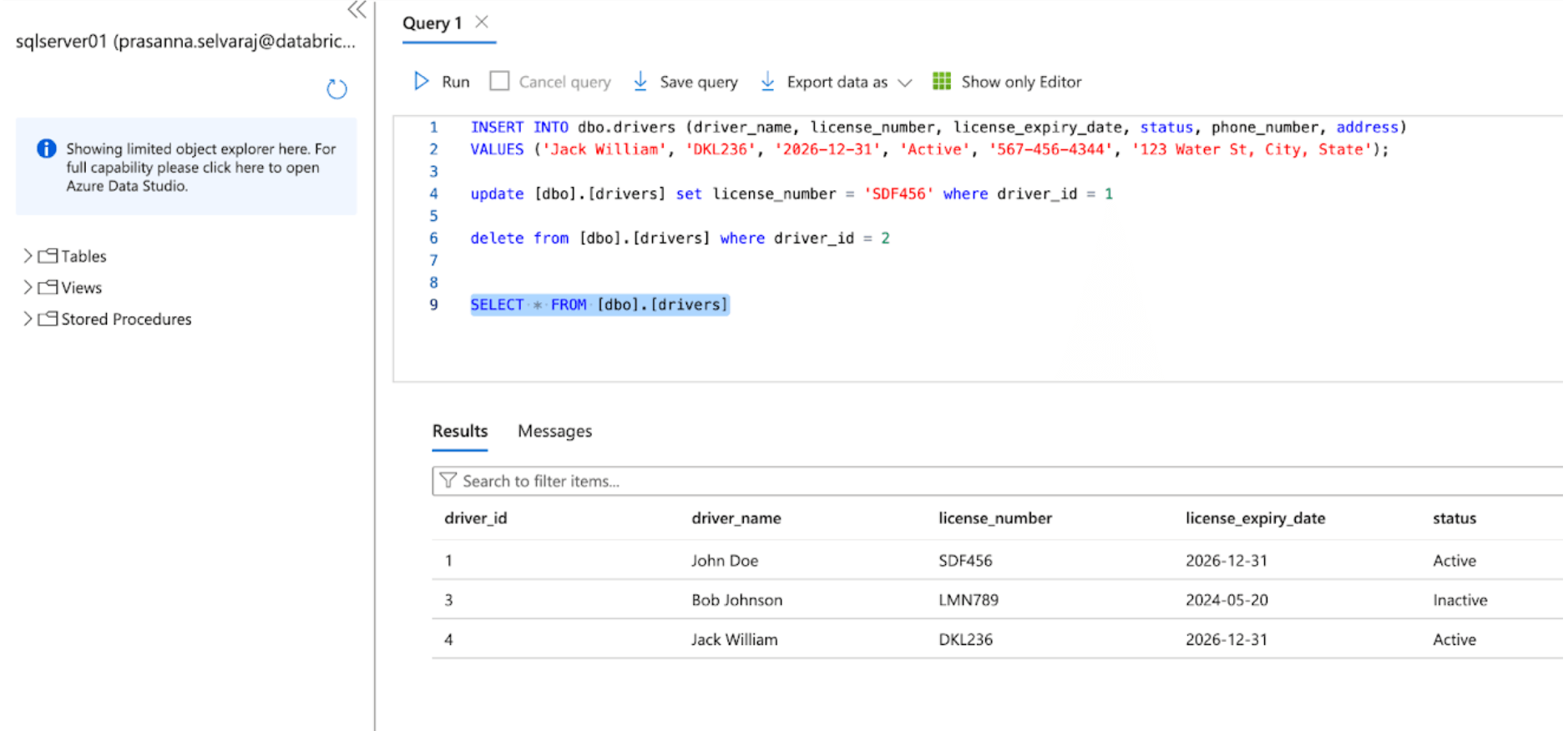
Uma vez que o pipeline é acionado e concluído, consulte a tabela delta sob o esquema alvo e verifique as alterações.
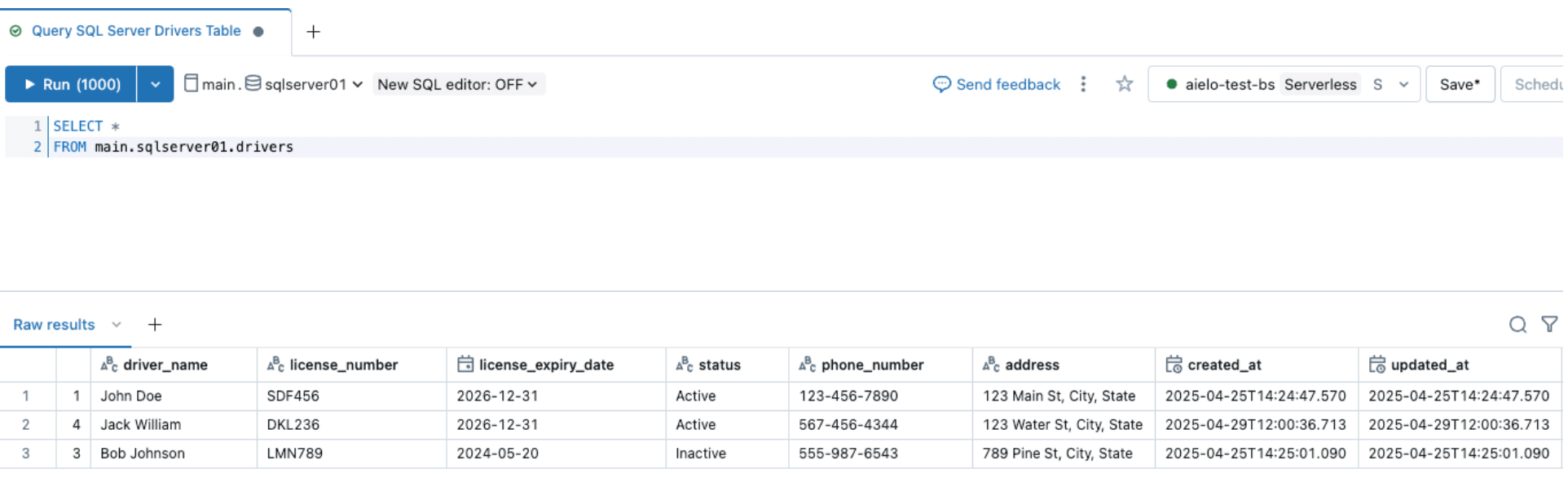
Da mesma forma, vamos realizar um evento de evolução de esquema e adicionar uma coluna à tabela de origem do SQL Server, conforme mostrado abaixo

Após alterar as fontes, acione o pipeline de ingestão clicando no botão iniciar dentro do Databricks DLT UI. Uma vez que o pipeline foi concluído, verifique as alterações navegando pela tabela de destino, conforme mostrado abaixo. A nova coluna email será anexada ao final da tabela de motoristas.
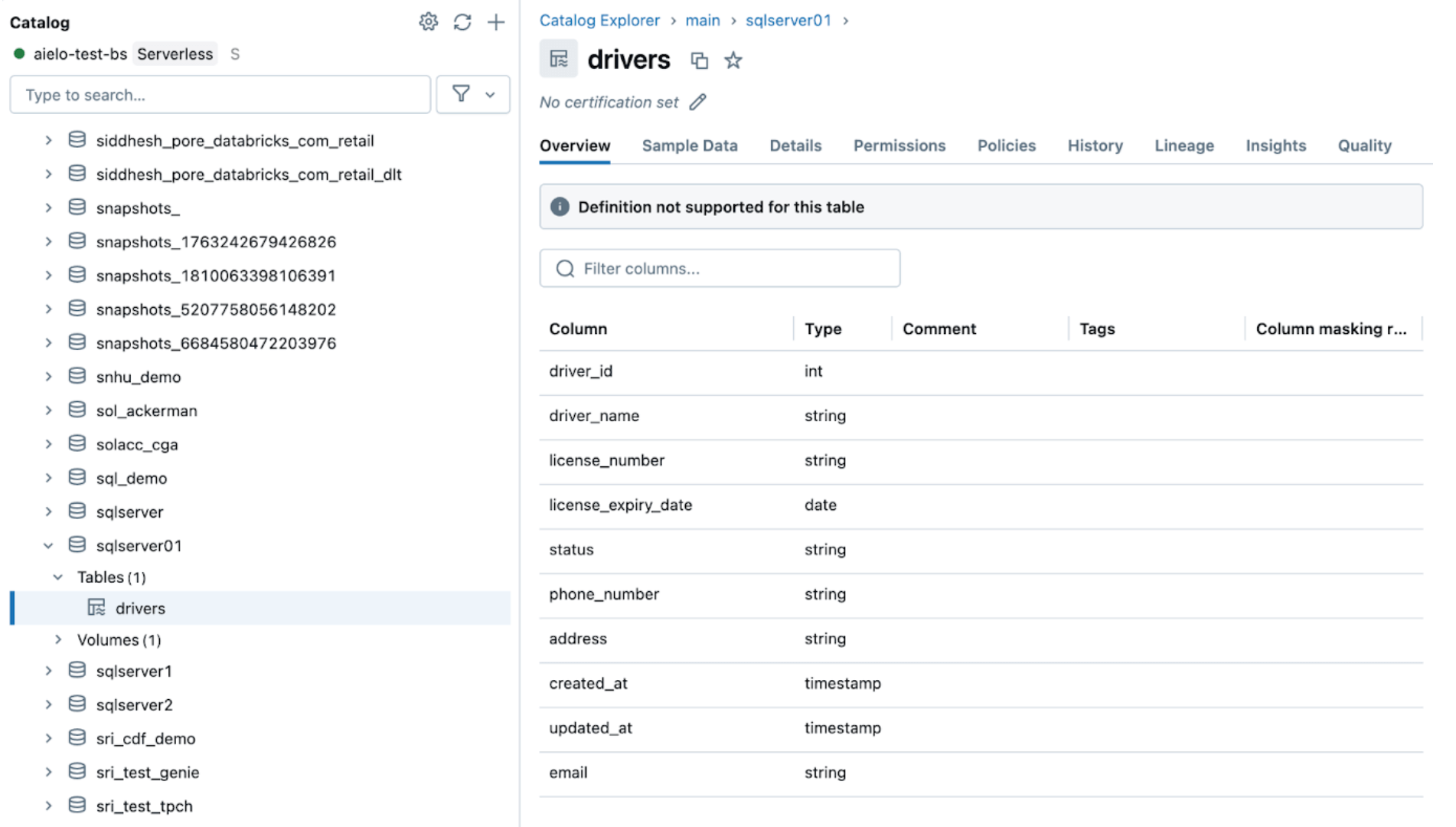
5. [Databricks] Monitoramento Contínuo de Pipeline
Monitorar sua saúde e comportamento é crucial uma vez que os pipelines de ingestão e gateway estão funcionando com sucesso. A interface do usuário do pipeline fornece verificações de qualidade de dados, progresso do pipeline e informações de linhagem de dados. Para visualizar as entradas do registro de eventos na interface do usuário do pipeline, localize o painel inferior sob o DAG do pipeline, conforme mostrado abaixo.

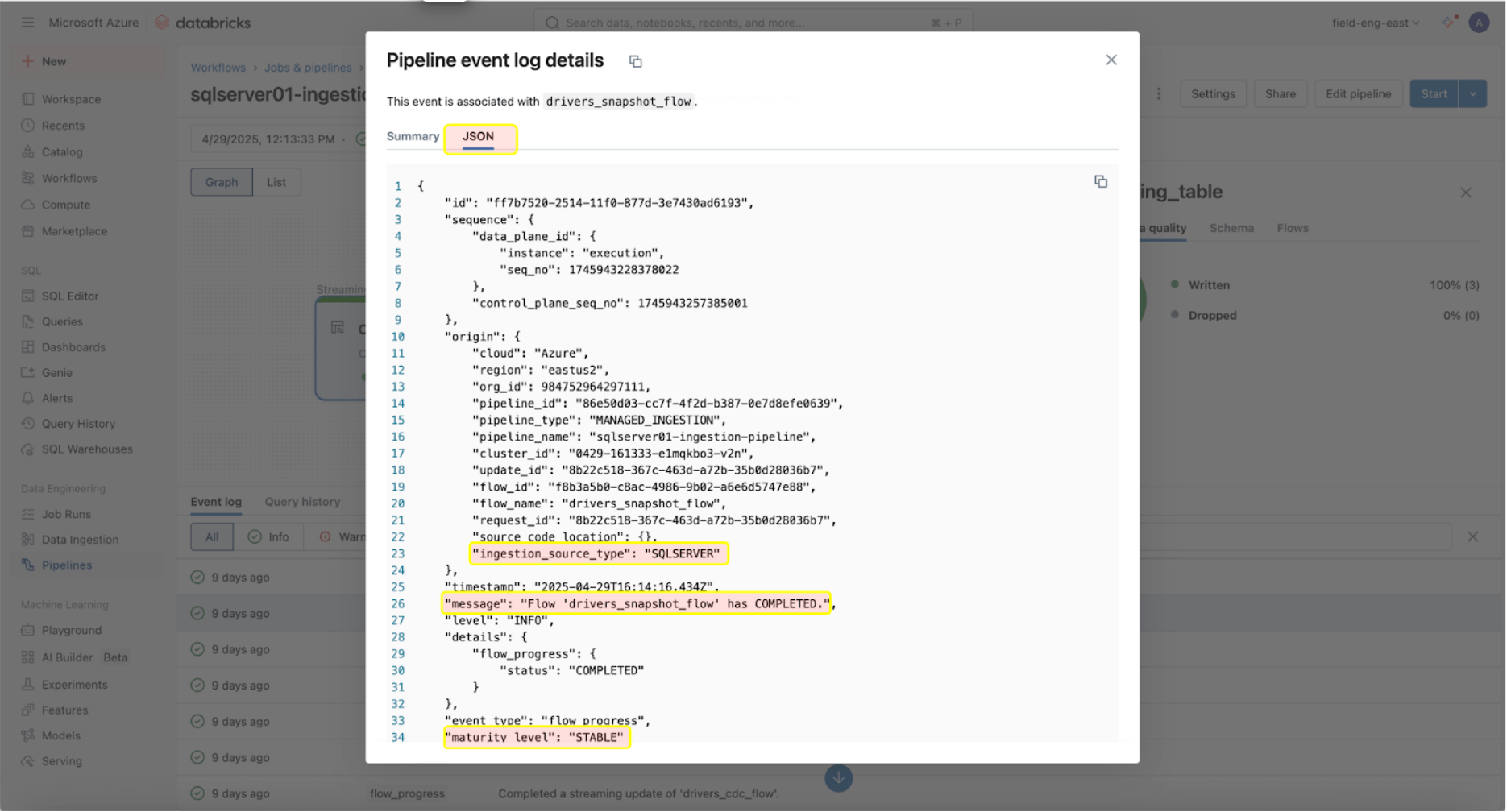
A entrada do log de eventos acima mostra que o ‘drives_snapshot_flow’ foi ingerido do SQL Server e concluído. O nível de maturidade ESTÁVEL indica que o esquema é estável e não mudou. Mais informações sobre o esquema de log de eventos podem ser encontradas aqui.
Exemplo do Mundo Real
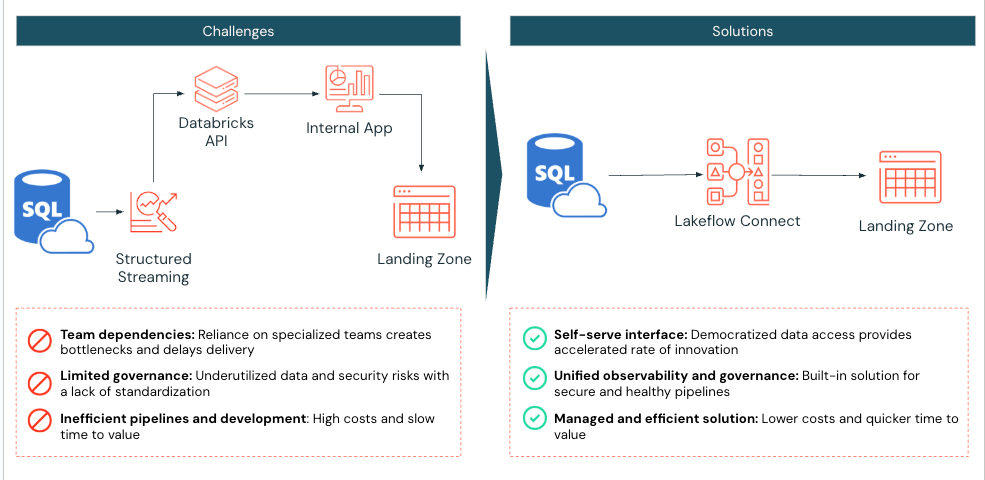
Um laboratório de diagnóstico médico em grande escala usando Databricks enfrentou desafios para ingerir dados do SQL Server em seu lakehouse de forma eficiente. Antes de implementar o Lakeflow Connect, o laboratório usava notebooks Spark do Databricks para puxar duas tabelas do Azure SQL Server para o Databricks. Seu aplicativo então interagiria com a API do Databricks para gerenciar a computação e a execução de tarefas.
O laboratório de diagnóstico médico implementou o Lakeflow Connect para SQL Server, reconhecendo que esse processo poderia ser simplificado. Uma vez habilitado, a implementação foi concluída em apenas um dia, permitindo que o laboratório de diagnóstico médico aproveitasse as ferramentas integradas da Databricks para observabilidade com atualizações incrementais diárias de ingestão.
Considerações Operacionais
Uma vez que o conector do SQL Server estabeleceu com sucesso uma conexão com o seu Banco de Dados SQL Azure, o próximo passo é agendar eficientemente seus pipelines de dados para otimizar o desempenho e a utilização de recursos. Além disso, é essencial seguir as melhores práticas para a configuração programática do pipeline para garantir escalabilidade e consistência entre os ambientes.
Orquestração de Pipeline
Não há limite para a frequência com que o pipeline de ingestão pode ser programado para ser executado. No entanto, para minimizar custos e garantir consistência nas execuções do pipeline sem sobreposição, a Databricks recomenda pelo menos um intervalo de 5 minutos entre as execuções de ingestão. Isso permite que novos dados sejam introduzidos na fonte, levando em conta os recursos computacionais e o tempo de inicialização.
O pipeline de ingestão pode ser configurado como uma tarefa dentro de um trabalho. Quando as cargas de trabalho a jusante dependem da chegada de dados frescos, as dependências de tarefas podem ser definidas para garantir que a execução do pipeline de ingestão seja concluída antes de executar tarefas a jusante.
Além disso, suponha que o pipeline ainda esteja em execução quando a próxima atualização está programada. Nesse caso, o pipeline de ingestão se comportará de maneira semelhante a um trabalho e pulará a atualização até a próxima programada, supondo que a atualização em execução seja concluída a tempo.
Observabilidade & Rastreamento de Custos
O Lakeflow Connect opera em um modelo de precificação baseado em computação, garantindo eficiência e escalabilidade para diversas necessidades de integração de dados. O pipeline de ingestão opera em computação serverless, o que permite flexibilidade na escala com base na demanda e simplifica o gerenciamento ao eliminar a necessidade dos usuários configurarem e gerenciarem a infraestrutura subjacente.
No entanto, é importante notar que, enquanto o pipeline de ingestão pode ser executado em computação sem servidor, o gateway de ingestão para conectores de banco de dados atualmente opera em computação clássica para simplificar as conexões com a fonte do banco de dados. Como resultado, os usuários podem ver uma combinação de cobranças clássicas e sem servidor DLT DBU refletidas em sua fatura.
A maneira mais fácil de rastrear e monitorar o uso do Lakeflow Connect é através de tabelas de sistema. Abaixo está um exemplo de consulta para visualizar o uso de um pipeline específico do Lakeflow Connect:

A precificação oficial para a documentação do Lakeflow Connect (AWS | Azure | GCP) fornece informações detalhadas sobre as taxas. Custos adicionais, como taxas de saída serverless (precificação), podem ser aplicados. Os custos de saída do provedor de nuvem para computação clássica podem ser encontrados aqui (AWS | Azure | GCP).
Melhores Práticas e Principais Conclusões
A partir de maio de 2025, abaixo estão algumas das melhores práticas e considerações a seguir ao implementar este conector SQL Server:
- Configure cada Gateway de Ingestão para autenticar com um usuário ou entidade com acesso apenas ao banco de dados de origem replicado.
- Certifique-se de que o usuário recebe as permissões necessárias para criar conexões no UC e ingerir os dados.
- Utilize DABs para configurar de forma confiável os pipelines de ingestão do Lakeflow Connect, garantindo repetibilidade e consistência na gestão de infraestrutura.
- Para tabelas de origem com chaves primárias, habilite Rastreamento de Alterações para obter menor sobrecarga e melhor desempenho.
- Para tabelas de origem sem uma chave primária, habilite o CDC devido à sua capacidade de capturar alterações no nível da coluna, mesmo sem identificadores de linha únicos.
O Lakeflow Connect para SQL Server oferece uma integração integrada totalmente gerenciada para bancos de dados locais e na nuvem para ingestão incremental eficiente na Databricks.
Próximos Passos & Recursos Adicionais
Experimente o conector SQL Server hoje para ajudar a resolver seus desafios de ingestão de dados. Siga as etapas descritas neste blog ou revise a documentação. Saiba mais sobre o Lakeflow Connect na página do produto, veja um tour do produto ou assista a uma demonstração do conector Salesforce para ajudar a prever a rotatividade de clientes.
Os Arquitetos de Soluções de Entrega da Databricks (DSAs) aceleram as iniciativas de Dados e IA em organizações. Eles fornecem liderança arquitetônica, otimizam plataformas para custo e desempenho, aprimoram a experiência do desenvolvedor e conduzem a execução bem-sucedida do projeto. DSAs preenchem a lacuna entre a implantação inicial e as soluções de produção, trabalhando de perto com várias equipes, incluindo engenharia de dados, líderes técnicos, executivos e outros stakeholders para garantir soluções personalizadas e um tempo mais rápido para obter valor. Para se beneficiar de um plano de execução personalizado, orientação estratégica e suporte ao longo de sua jornada de dados e IA com um DSA, entre em contato com sua Equipe de Contas Databricks.
Apêndice
Neste passo opcional, para gerenciar os pipelines do Lakeflow Connect como código usando DABs, você simplesmente precisa adicionar dois arquivos ao seu pacote existente:
- Um arquivo de fluxo de trabalho que controla a frequência de ingestão de dados (resources/sqlserver.yml).
- Um arquivo de definição de pipeline (resources/sqlserver_pipeline.yml).
resources/sqlserver.yml:
resources/sqlserver_job.yml:
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.