Lakeflow Connect: Efficient and Easy Data Ingestion using the SQL Server connector
Explore Databricks Lakeflow Connect’s fully managed SQL Server Connector to simplify ingesting and integrating data seamlessly with Databricks tools for data processing and analytics
by Andrea Tardif, Prasanna Selvaraj, Hector Bustamante and Phanitha Kommareddi
- Leading tech companies face complex challenges when extracting value from their SQL Server data for AI and analytics.
- Lakeflow Connect for SQL Server provides efficient, incremental ingestion for both on-premises and cloud databases.
- This blog reviews architectural considerations, prerequisites, and step-by-step instructions for ingesting SQL Server data into your lakehouse.
Complexities of Extracting SQL Server Data
While digital native companies recognize AI's critical role in driving innovation, many still face challenges in making their data readily available for downstream uses, such as machine learning development and advanced analytics. For these organizations, supporting business teams that rely on SQL Server means having data engineering resources and maintaining custom connectors, preparing data for analytics, and ensuring it is available to data teams for model development. Often, this data needs to be enriched with additional sources and transformed before it can inform data-driven decisions.
Maintaining these processes quickly becomes complex and brittle, slowing down innovation. That’s why Databricks developed Lakeflow Connect, which includes built-in data connectors for popular databases, enterprise applications, and file sources. These connectors provide efficient end-to-end, incremental ingestion, are flexible and easy to set up, and are fully integrated with the Databricks Data Intelligence Platform for unified governance, observability, and orchestration. The new Lakeflow SQL Server connector is the first database connector with robust integration for both on-premises and cloud databases to help derive data insights from within Databricks.
In this blog, we’ll review the key considerations for when to use Lakeflow Connect for SQL Server and explain how to configure the connector to replicate data from an Azure SQL Server instance. Then, we’ll review a specific use case, best practices, and how to get started.
Key Architectural Considerations
Below are the key considerations to help decide when to use the SQL Server connector.
Region & Feature Compatibility
Lakeflow Connect supports a wide range of SQL Server database variations, including Microsoft Azure SQL Database, Amazon RDS for SQL Server, Microsoft SQL Server running on Azure VMs and Amazon EC2, and on-premises SQL Server accessed through Azure ExpressRoute or AWS Direct Connect.
Since Lakeflow Connect runs on Serverless pipelines under the hood, built-in features such as pipeline observability, event log alerting, and lakehouse monitoring can be leveraged. If Serverless is not supported in your region, work with your Databricks Account team to file a request to help prioritize development or deployment in that region.
Lakeflow Connect is built on the Data Intelligence Platform, which provides seamless integration with Unity Catalog (UC) to reuse established permissions and access controls across new SQL Server sources for unified governance. If your Databricks tables and views are on Hive, we recommend upgrading them to UC to benefit from these features (AWS | Azure | GCP)!
Change Data Requirements
Lakeflow Connect can be integrated with an SQL Server with Microsoft change tracking (CT) or Microsoft Change Data Capture (CDC) enabled to support efficient, incremental ingestion.
CDC provides historical change information about insert, update, and delete operations, and when the actual data has changed. Change tracking identifies which rows were modified in a table without capturing the actual data changes themselves. Learn more about CDC and the benefits of using CDC with SQL Server.
Databricks recommends using change tracking for any table with a primary key to minimize the load on the source database. For source tables without a primary key, use CDC. Learn more about when to use it here.
The SQL Server connector captures an initial load of historical data on the first run of your ingestion pipeline. Then, the connector tracks and ingests only the changes made to the data since the last run, leveraging SQL Server's CT/CDC features to streamline operations and efficiency.
Governance & Private Networking Security
When a connection is established with a SQL Server using Lakeflow Connect:
- Traffic between the client interface and the control plane is encrypted in transit using TLS 1.2 or later.
- The staging volume, where raw files are stored during ingestion, is encrypted by the underlying cloud storage provider.
- Data at rest is protected following best practices and compliance standards.
- When configured with private endpoints, all data traffic stays within the cloud provider's private network, avoiding the public internet.
Once the data is ingested into Databricks, it is encrypted like other datasets within UC. The ingestion gateway that extracts snapshots, change logs, and metadata from the source database lands in a UC Volume, a storage abstraction best for registering non-tabular datasets such as JSON files. This UC Volume resides within the customer’s cloud storage account within their Virtual Networks or Virtual Private Clouds.
Additionally, UC enforces fine-grained access controls and maintains audit trails to govern access to this newly ingested data. UC Service credentials and Storage Credentials are stored as securable objects within UC, ensuring secure and centralized authentication management. These credentials are never exposed in logs or hardcoded into SQL ingestion pipelines, providing robust protection and access control.
If your organization meets the above criteria, consider Lakeflow Connect for SQL Server to help simplify data ingestion into Databricks.
Breakdown of Technical Solution
Next, review the steps for configuring Lakeflow Connect for SQL Server and replicating data from an Azure SQL Server instance.
Configure Unity Catalog Permissions
Within Databricks, ensure serverless compute is enabled for notebooks, workflows, and pipelines (AWS | Azure | GCP). Then, validate that the user or service principal creating the ingestion pipeline has the following UC permissions:
| Permission Type | Reason | Documentation |
| CREATE CONNECTION on the metastore | Lakeflow Connect needs to establish a secure connection to the SQL Server. | CREATE CONNECTION |
| USE CATALOG on the target catalog | Required as it provides access to the catalog where Lakeflow Connect will land the SQL Server data tables in UC. | USE CATALOG |
| USE SCHEMA, CREATE TABLE, and CREATE VOLUME on an existing schema or CREATE SCHEMA on the target catalog | Provides the necessary rights to access schemas and create storage locations for ingested data tables. | GRANT PRIVILEGES |
| Unrestricted permissions to create clusters, or a custom cluster policy | Required to spin up the compute resources required for the gateway ingestion process | MANAGE COMPUTE POLICIES |
Set up Azure SQL Server
To use the SQL Server connector, confirm that the following requirements are met:
- Confirm SQL Version
- SQL Server 2012 or a later version must be enabled to use change tracking. However, 2016+ is recommended*. Review SQL Version requirements here.
- Configure the Database service account dedicated to the Databricks ingestion.
- Enable change tracking or built-in CDC
- You must have SQL Server 2012 or a later version to use CDC. Versions earlier than SQL Server 2016 additionally require the Enterprise edition.
* Requirements as of May 2025. Subject to change.
Example: Ingesting from Azure SQL Server to Databricks
Next, we will ingest a table from an Azure SQL Server database to Databricks using Lakeflow Connect. In this example, CDC and CT provide an overview of all available options. Since the table in this example has a primary key, CT could have been the primary choice. However, since there is only one small table in this example, there is no concern about load overhead, so CDC was also included. It is recommended to review when to use CDC, CT, or both to determine which is best for your data and refresh requirements.
1. [Azure SQL Server] Verify and Configure Azure SQL Server for CDC and CT
Start by accessing the Azure portal and signing in using your Azure account credentials. On the left-hand side, click All services and search for SQL Servers. Find and click your server, and click the ‘Query Editor’; in this example, sqlserver01 was selected.
The screenshot below shows that the SQL Server database has one table called ‘drivers’.
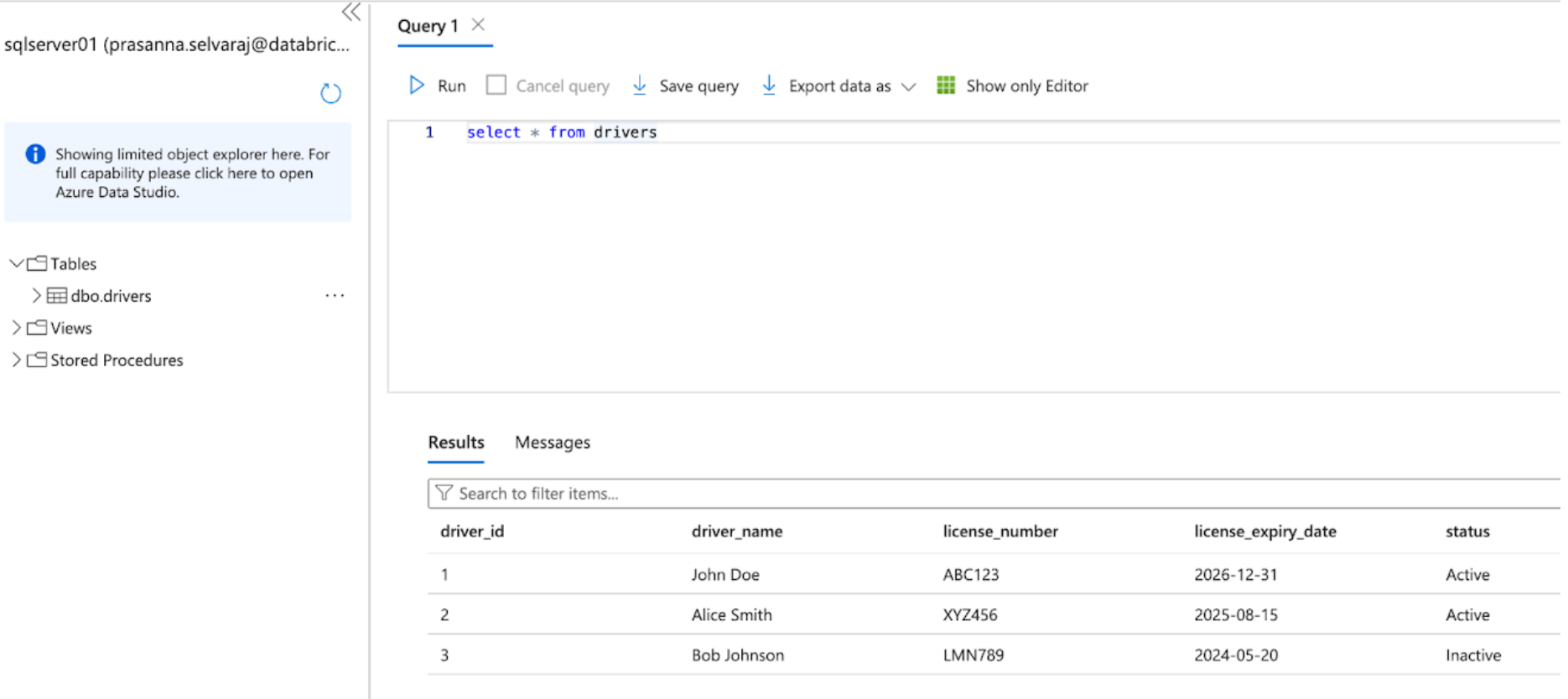
Before replicating the data to Databricks, either change data capture, change tracking, or both must be enabled.
For this example, the following script is run on the database to enable CT:
This command enables change tracking for the database with the following parameters:
- CHANGE_RETENTION = 3 DAYS: This value tracks changes for 3 days (72 hours). A full refresh will be required if your gateway is offline longer than the set time. It is recommended that this value be increased if more extended outages are expected.
- AUTO_CLEANUP = ON: This is the default setting. To maintain performance, it automatically removes change tracking data older than the retention period.
Then, the following script is run on the database to enable CDC:
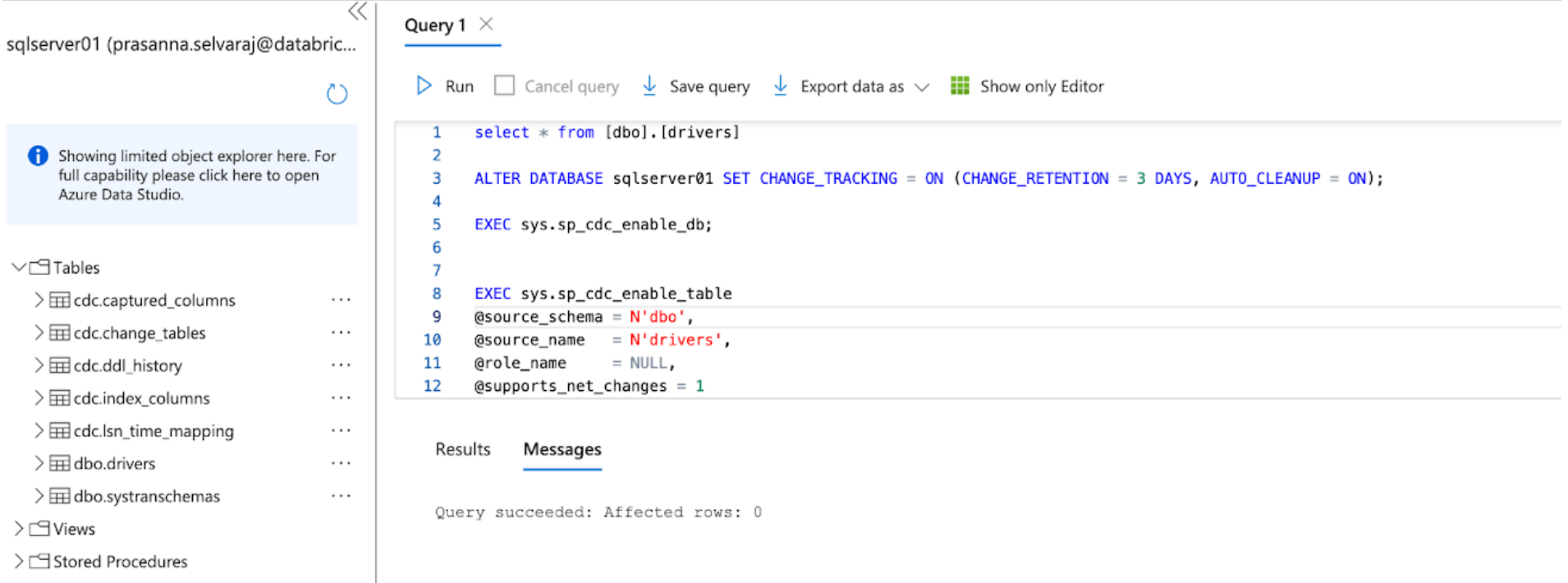
When both scripts finish running, review the tables section under the SQL Server instance in Azure and ensure that all CDC and CT tables are created.
2. [Databricks] Configure the SQL Server connector in Lakeflow Connect
In this next step, the Databricks UI will be shown to configure the SQL Server connector. Alternatively, Databricks Asset Bundles (DABs), a programmatic way to manage the Lakeflow Connect pipelines as code, can also be leveraged. An example of the full DABs script is in the appendix below.
Once all the permissions are set, as laid out in the Permission Prerequisites section, you are ready to ingest data. Click the + New button at the top left, then select Add or Upload data.
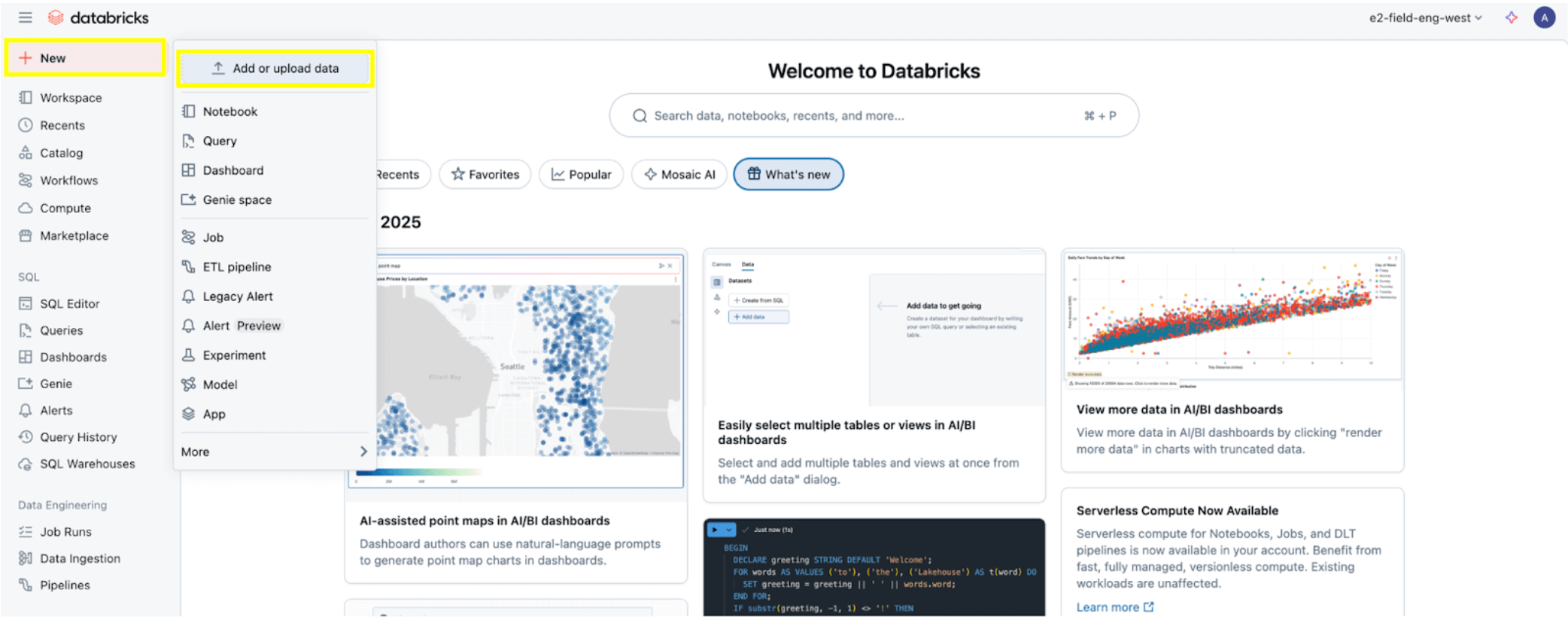
Then select the SQL Server option.
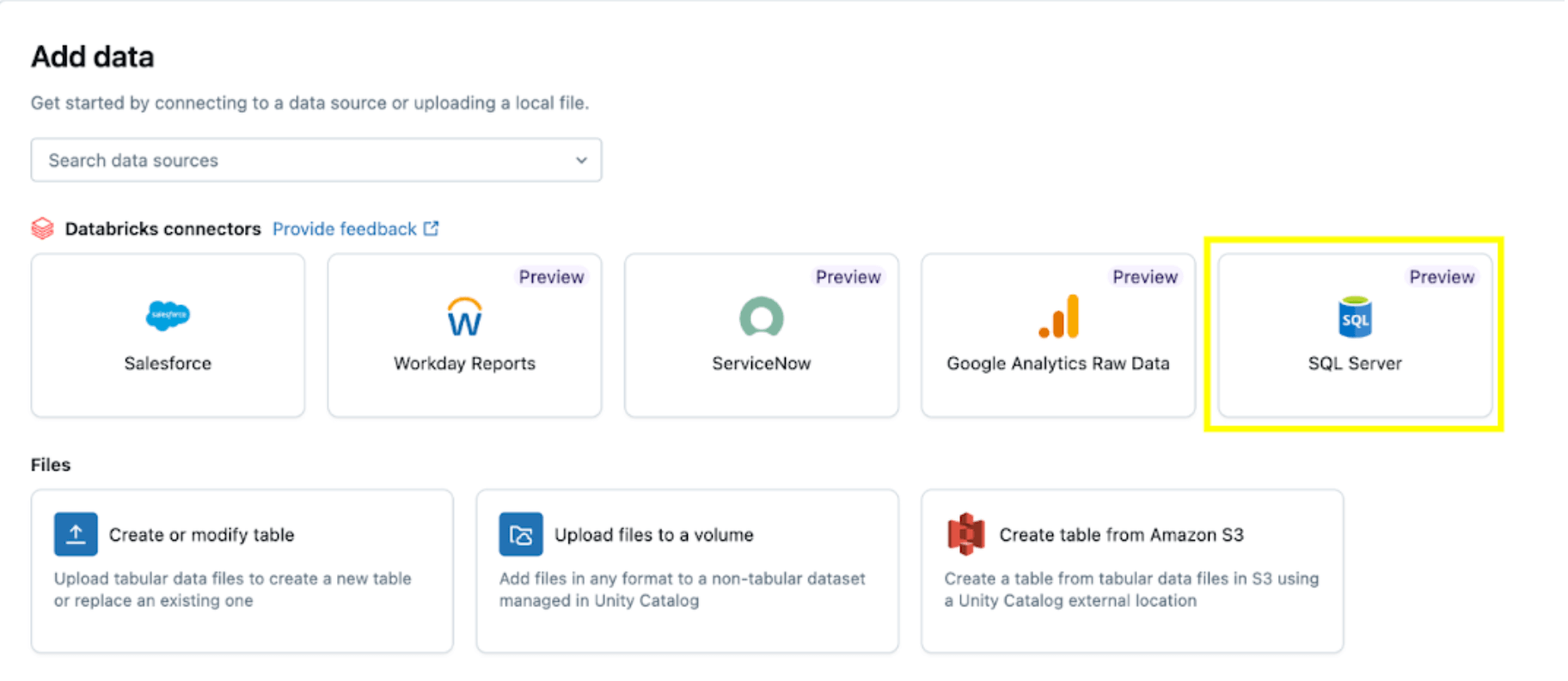
The SQL Server connector is configured in several steps.
1. Set up the ingestion gateway (AWS | Azure | GCP). In this step, provide a name for the ingestion gateway pipeline and a catalog and schema for the UC Volume location to extract snapshots and continually change data from the source database.
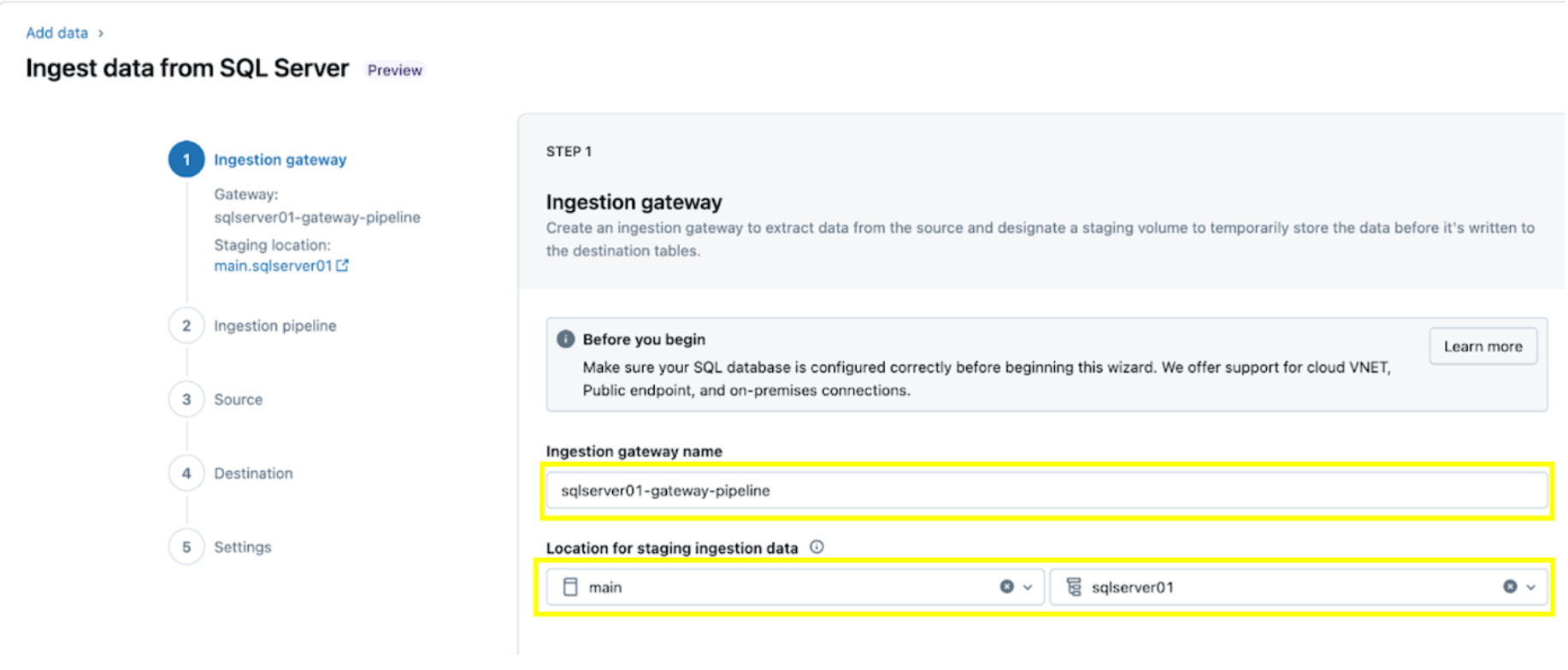
2. Configure the ingestion pipeline. This replicates the CDC/CT data source and the schema evolution events. A SQL Server connection is required, which is created through the UI following these steps or with the following SQL code below:
For this example, name the SQL server connection rebel as shown.
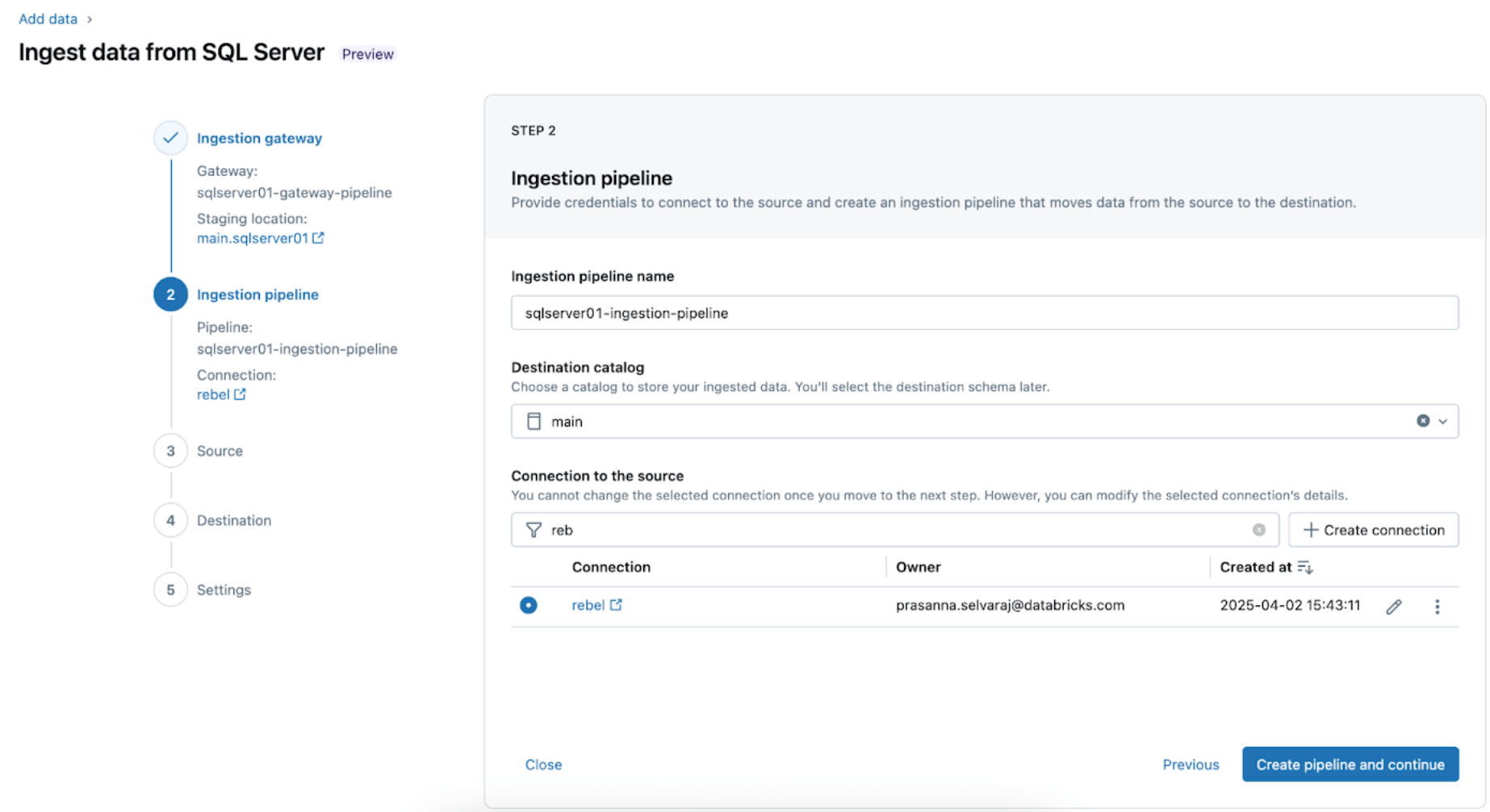
3. Selecting the SQL Server tables for replication. Select the whole schema to be ingested into Databricks instead of choosing individual tables to ingest.
The whole schema can be ingested into Databricks during initial exploration or migrations. If the schema is large or exceeds the allowed number of tables per pipeline (see connector limits), Databricks recommends splitting the ingestion across multiple pipelines to maintain optimal performance. For use case-specific workflows such as a single ML model, dashboard, or report, it’s generally more efficient to ingest individual tables tailored to that specific need, rather than the whole schema.
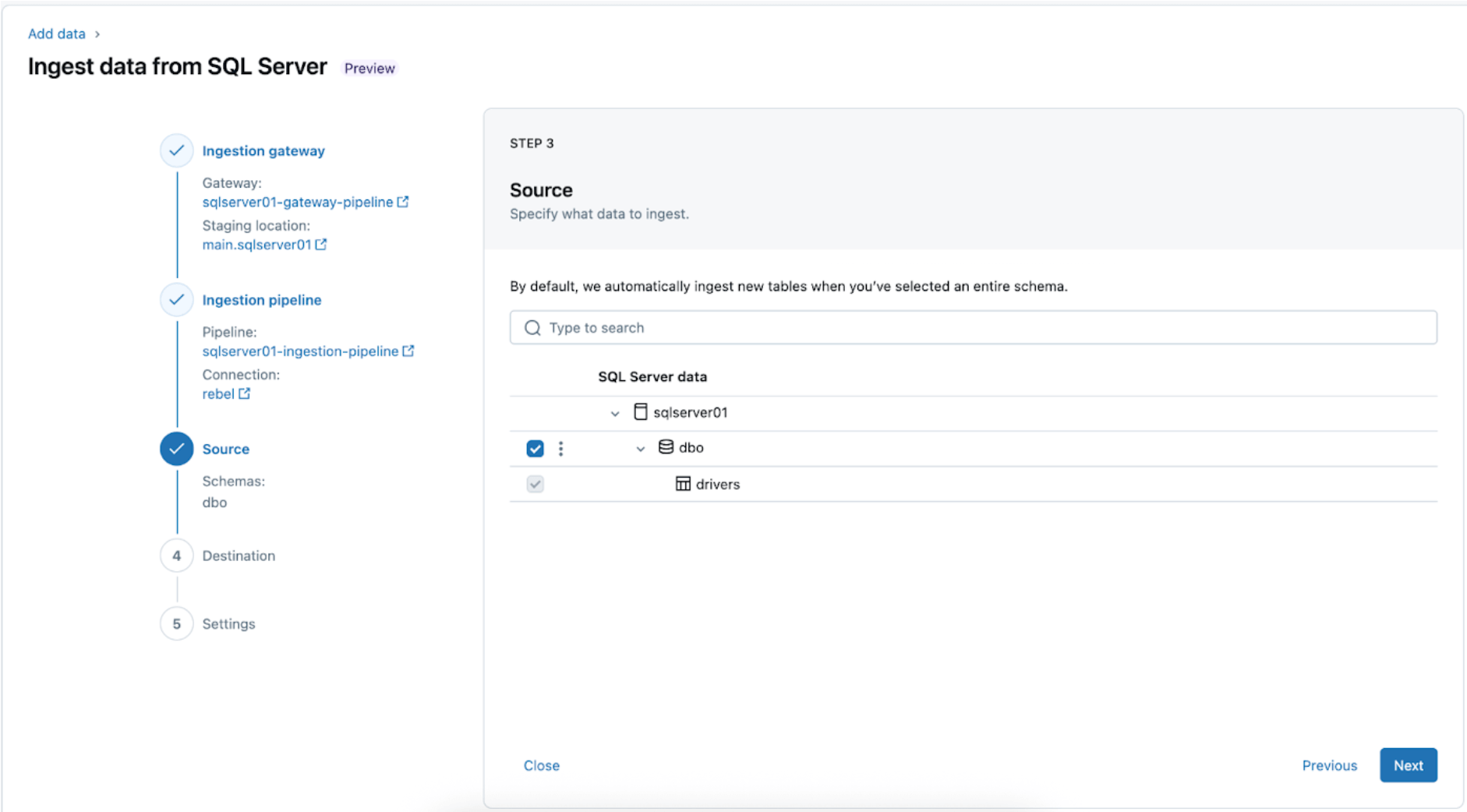
4. Configure the destination where the SQL Server tables will be replicated within UC. Select the main catalog and sqlserver01 schema to land the data in UC.
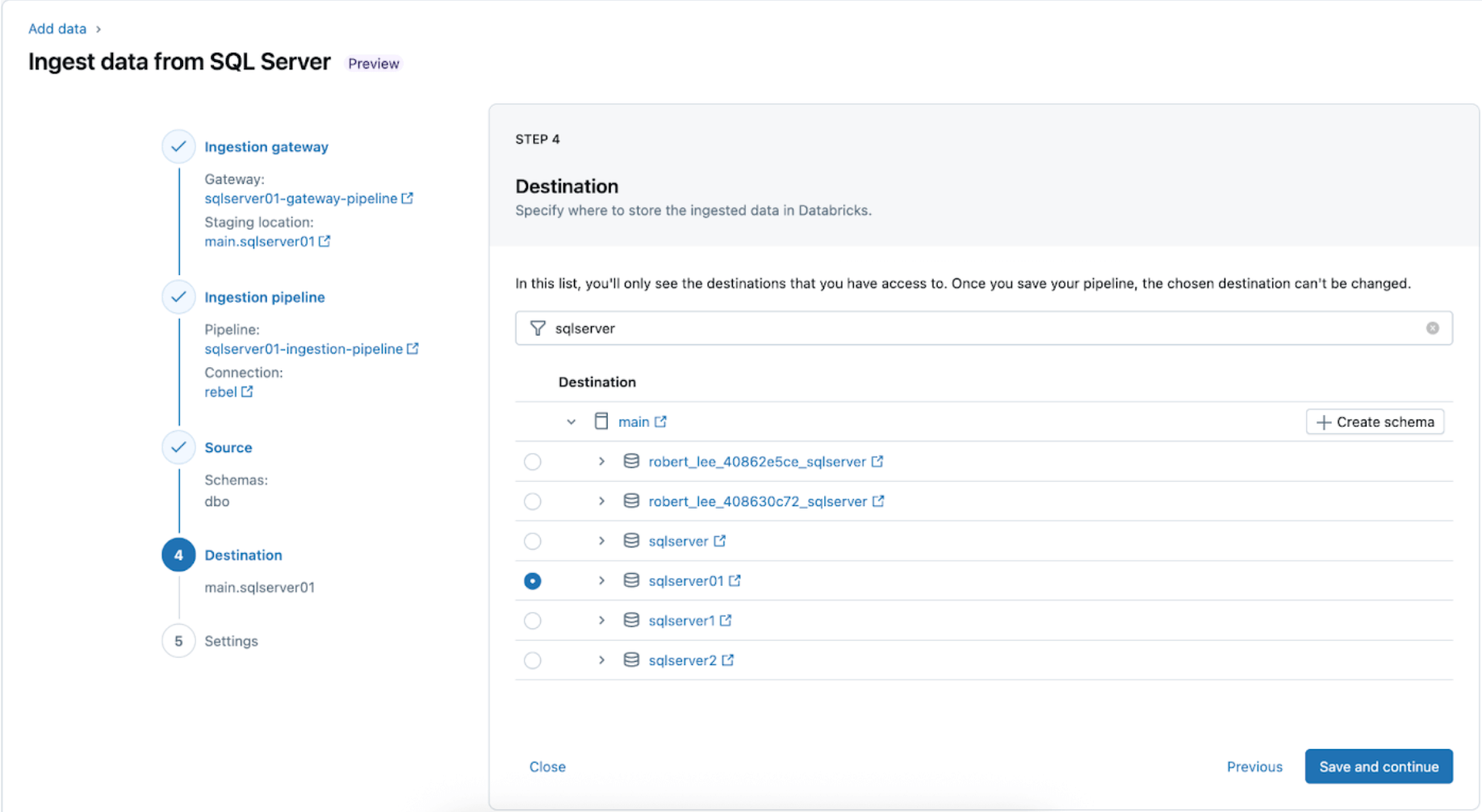
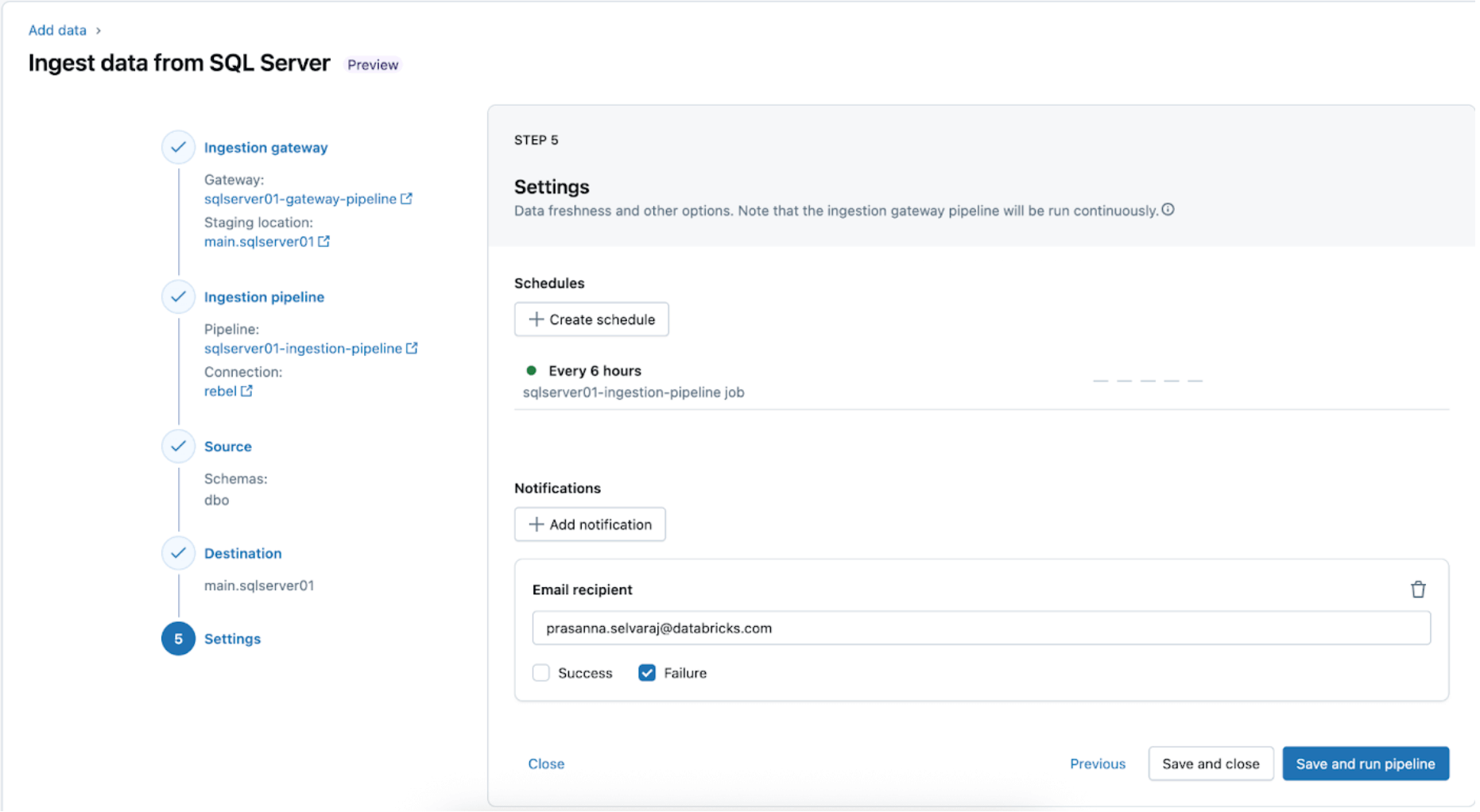
5. Configure schedules and notifications (AWS | Azure | GCP). This final step will help determine how often to run the pipeline and where success or failure messages should be sent. Set the pipeline to run every 6 hours and notify the user only of pipeline failures. This interval can be configured to meet the needs of your workload.
The ingestion pipeline can be triggered on a custom schedule. Lakeflow Connect will automatically create a dedicated job for each scheduled pipeline trigger. The ingestion pipeline is a task within the job. Optionally, more tasks can be added before or after the ingestion task for any downstream processing.
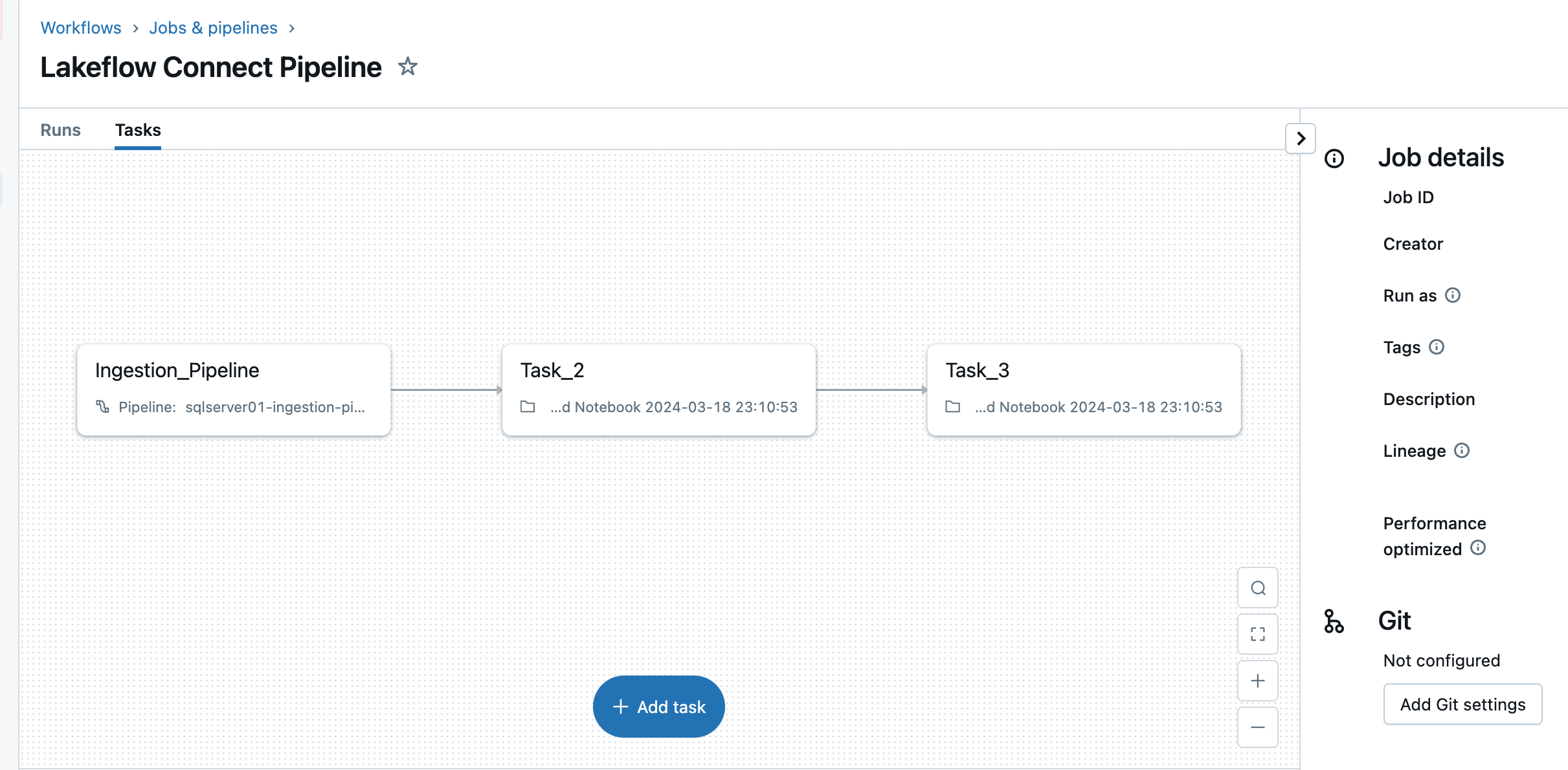
After this step, the ingestion pipeline is saved and triggered, starting a full data load from the SQL Server into Databricks.
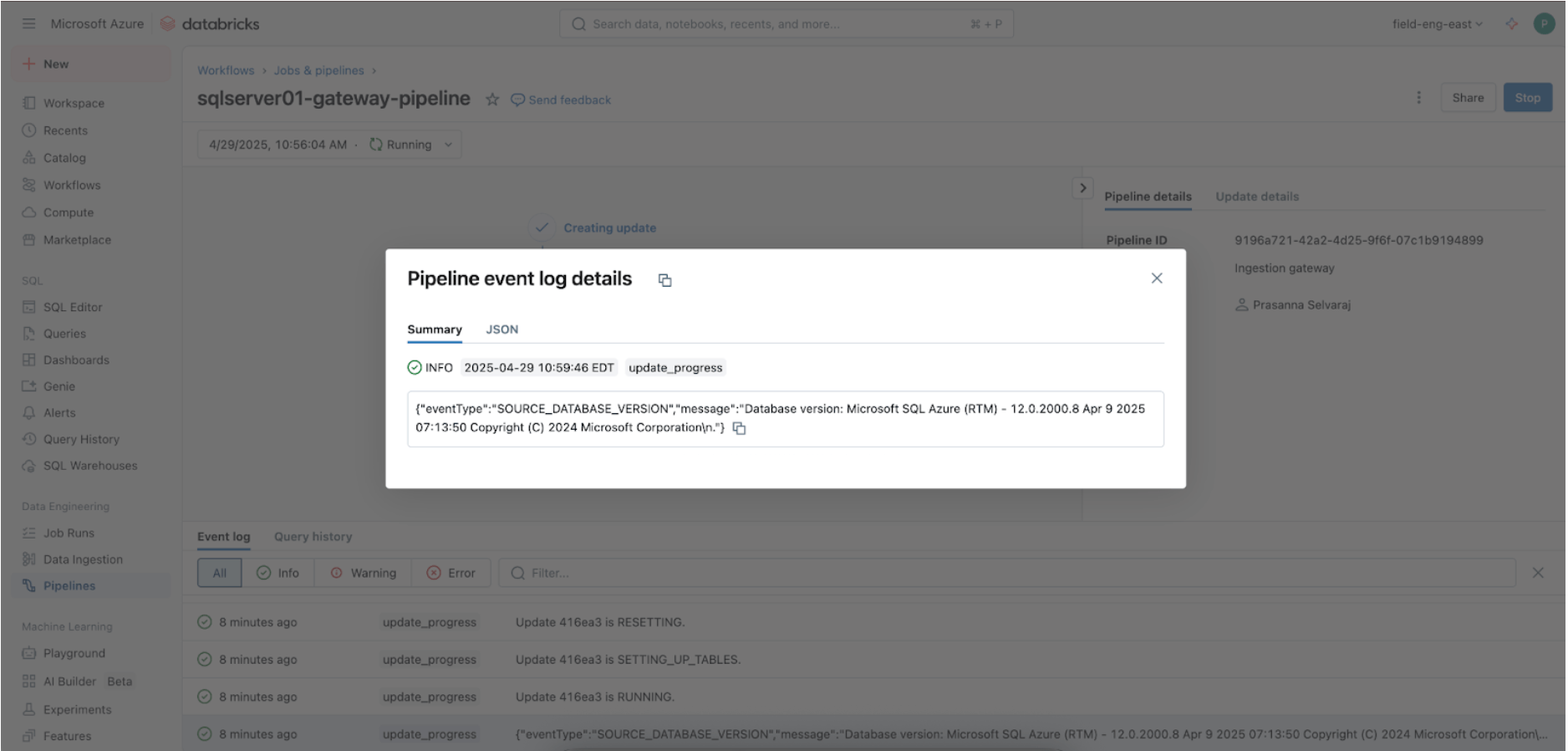
3. [Databricks] Validate Successful Runs of the Gateway and Ingestion Pipelines
Navigate to the Pipeline menu to check if the gateway ingestion pipeline is running. Once complete, search for ‘update_progress’ within the pipeline event log interface at the bottom pane to ensure the gateway successfully ingests the source data.
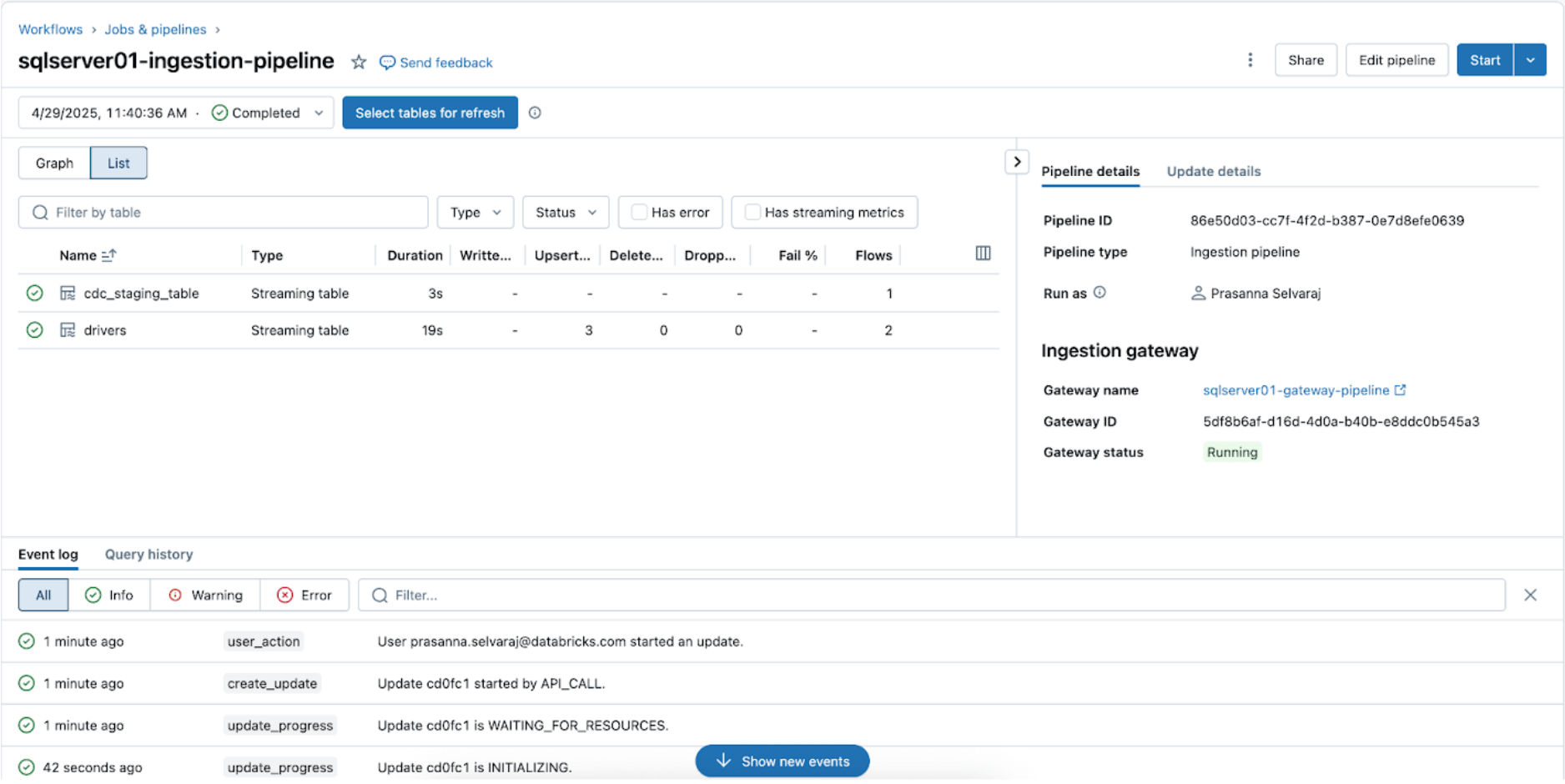
To check the sync status, navigate to the pipeline menu. The screenshot below shows that the ingestion pipeline has performed three insert and update (UPSERT) operations.
Navigate to the target catalog, main, and schema, sqlserver01, to view the replicated table, as shown below.

4. [Databricks] Test CDC and Schema Evolution
Next, verify a CDC event by performing insert, update, and delete operations in the source table. The screenshot of the Azure SQL Server below depicts the three events.
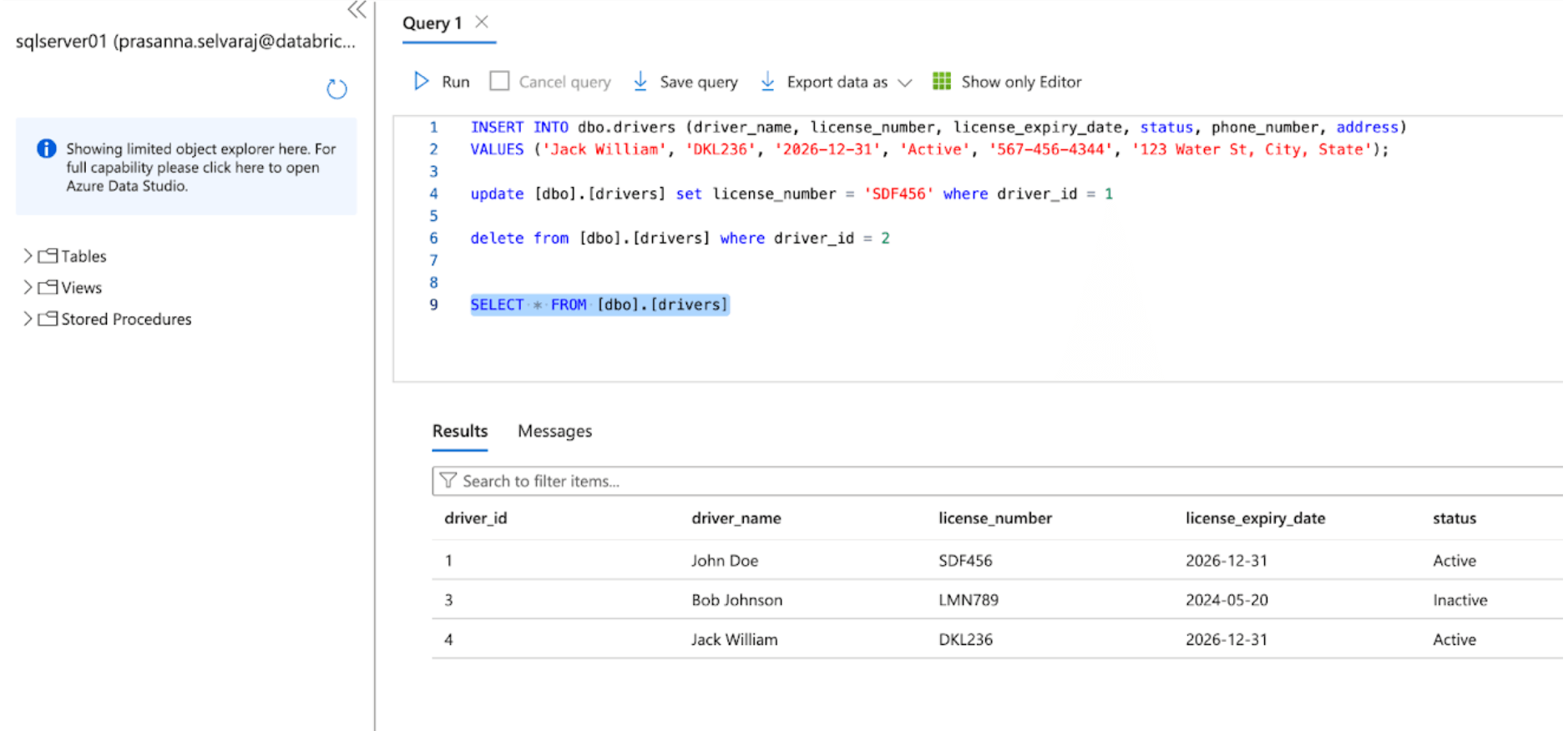
Once the pipeline is triggered and is completed, query the delta table under the target schema and verify the changes.
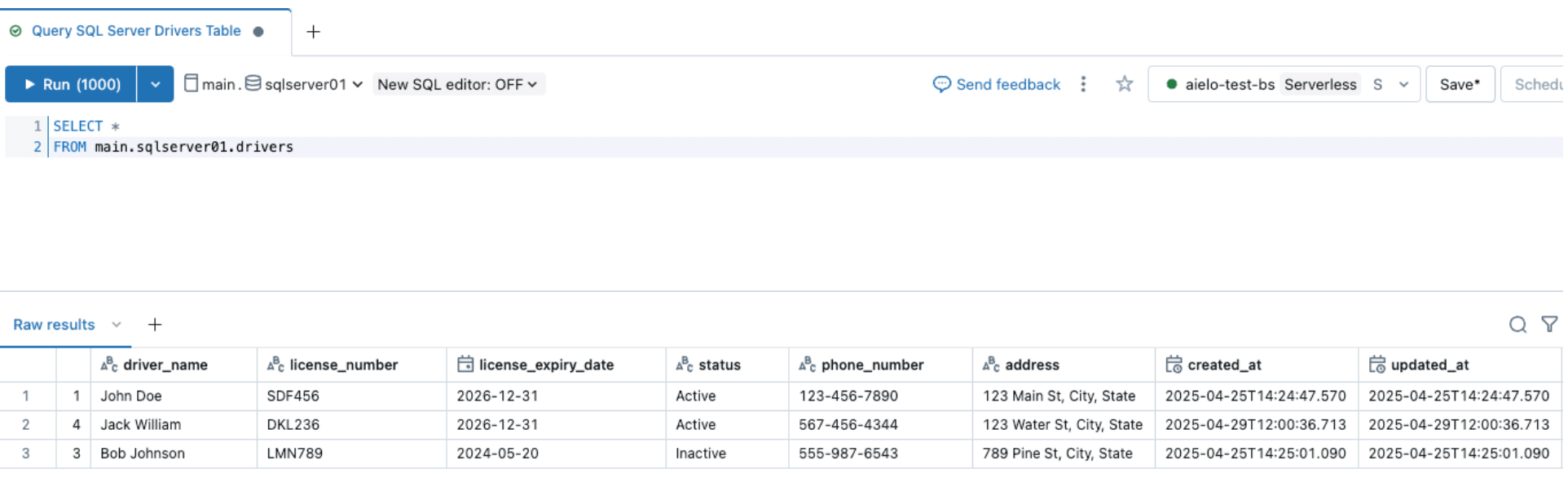
Similarly, let's perform a schema evolution event and add a column to the SQL Server source table, as shown below

After changing the sources, trigger the ingestion pipeline by clicking the start button within the Databricks DLT UI. Once the pipeline has been completed, verify the changes by browsing the target table, as shown below. The new column email will be appended to the end of the drivers table.
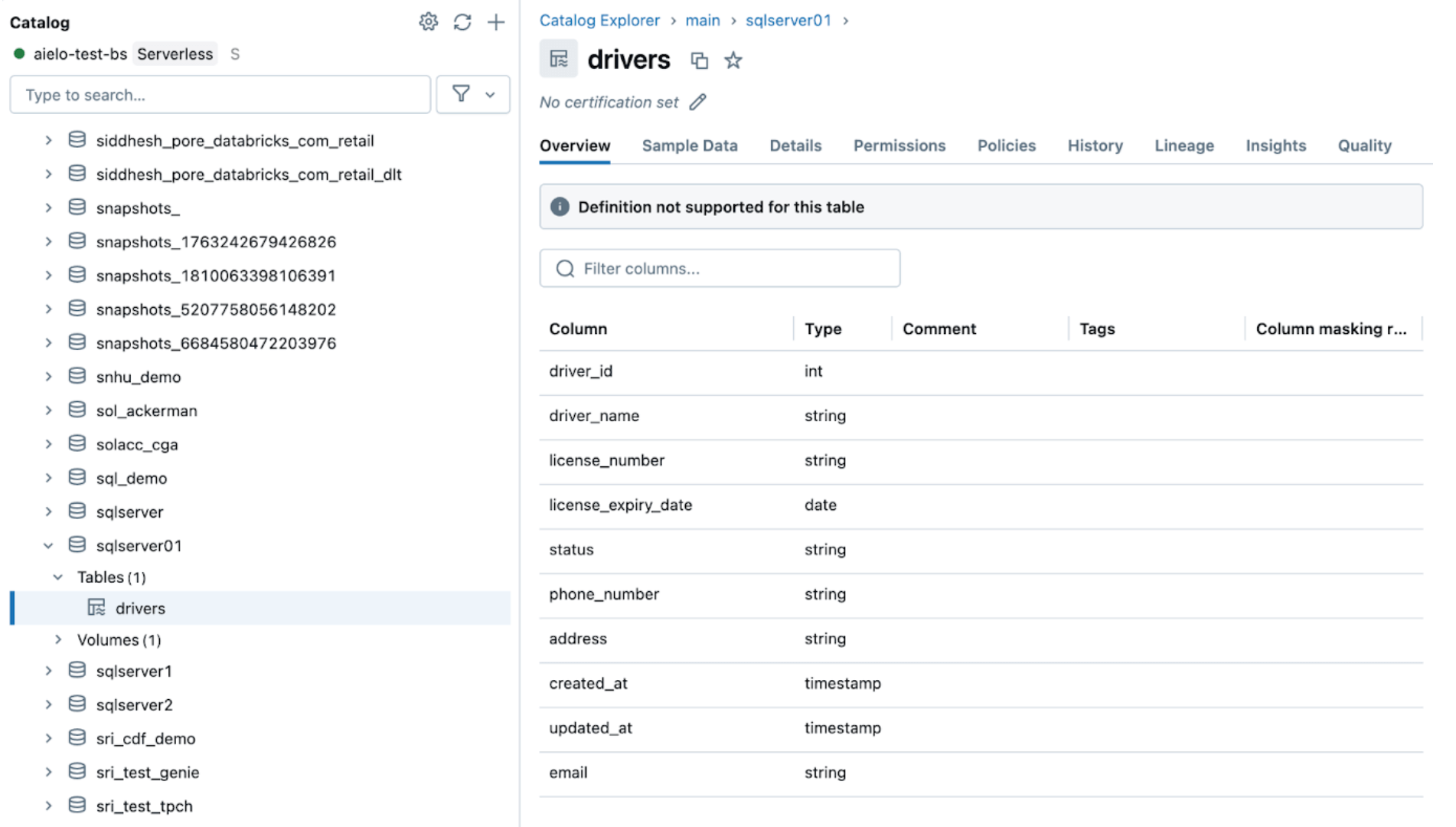
5. [Databricks] Continuous Pipeline Monitoring
Monitoring their health and behavior is crucial once the ingestion and gateway pipelines are successfully running. The pipeline UI provides data quality checks, pipeline progress, and data lineage information. To view the event log entries in the pipeline UI, locate the bottom pane under the pipeline DAG, as shown below.

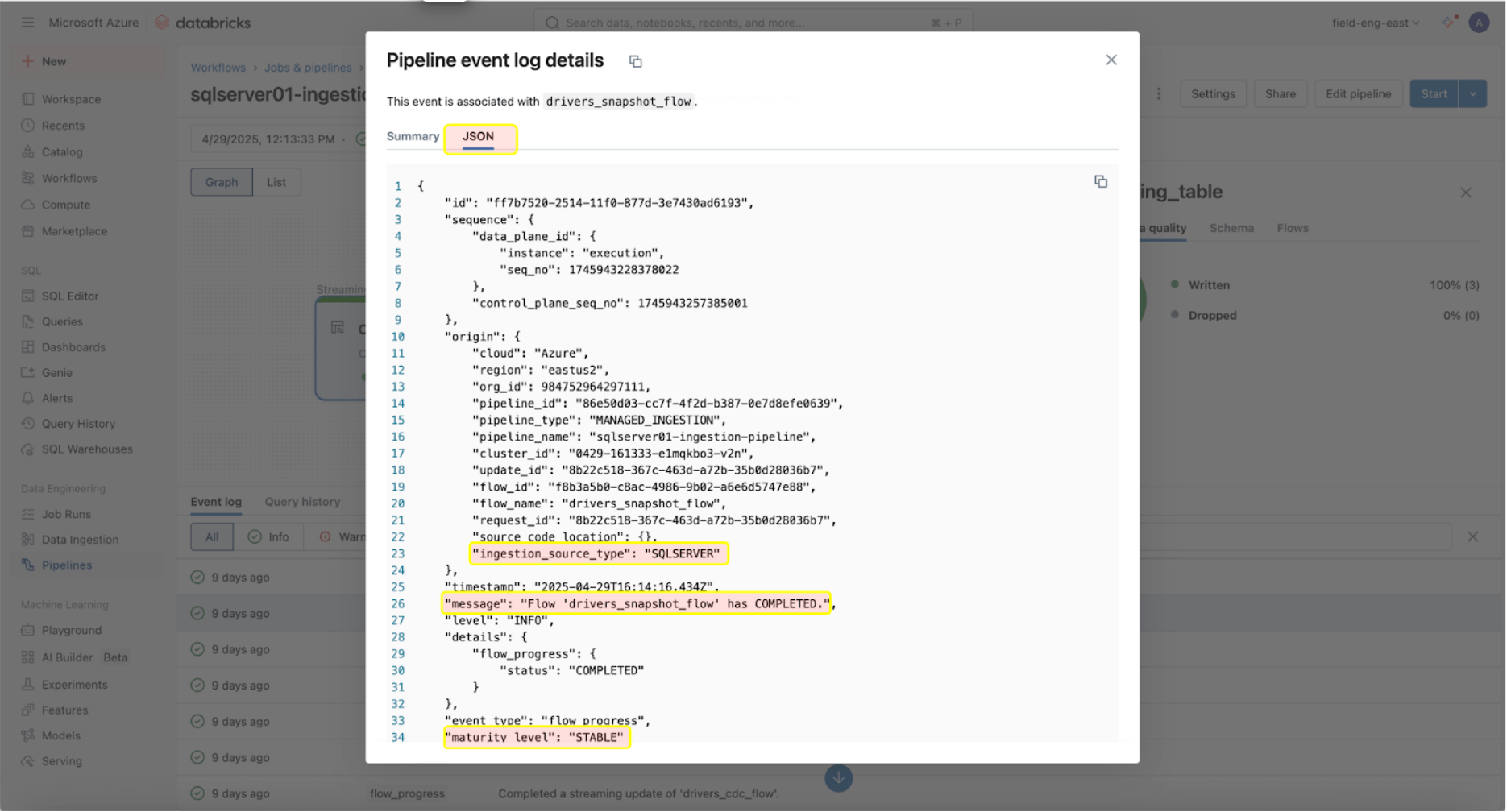
The event log entry above shows that the ‘drives_snapshot_flow’ was ingested from the SQL Server and completed. The maturity level of STABLE indicates that the schema is stable and has not changed. More information on the event log schema can be found here.
Real-World Example
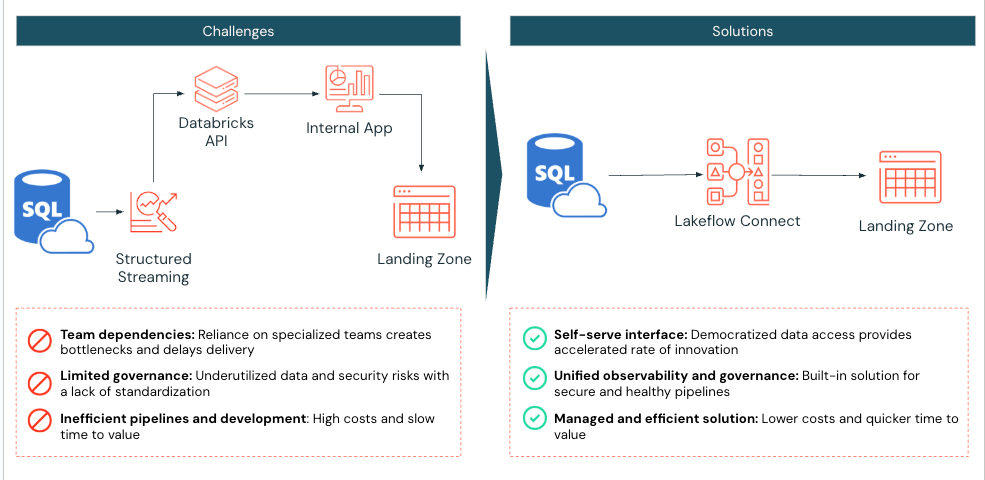
A large-scale medical diagnostic lab using Databricks faced challenges efficiently ingesting SQL Server data into its lakehouse. Before implementing Lakeflow Connect, the lab used Databricks Spark notebooks to pull two tables from Azure SQL Server into Databricks. Their application would then interact with the Databricks API to manage compute and job execution.
The medical diagnostic lab implemented Lakeflow Connect for SQL Server, recognizing that this process could be simplified. Once enabled, the implementation was completed in just one day, allowing the medical diagnostic lab to leverage Databricks’ built-in tools for observability with daily incremental ingestion refreshes.
Operational Considerations
Once the SQL Server connector has successfully established a connection to your Azure SQL Database, the next step is to efficiently schedule your data pipelines to optimize performance and resource utilization. In addition, it's essential to follow best practices for programmatic pipeline configuration to ensure scalability and consistency across environments.
Pipeline Orchestration
There is no limit on how often the ingestion pipeline can be scheduled to run. However, to minimize costs and ensure consistency in pipeline executions without overlap, Databricks recommends at least a 5-minute interval between ingestion executions. This allows new data to be introduced at the source while accounting for computational resources and startup time.
The ingestion pipeline can be configured as a task within a job. When downstream workloads rely on fresh data arrival, task dependencies can be set to ensure the ingestion pipeline run completes before executing downstream tasks.
Additionally, suppose the pipeline is still running when the next refresh is scheduled. In that case, the ingestion pipeline will behave similarly to a job and skip the update until the next scheduled one, assuming the currently running update completes on time.
Observability & Cost Tracking
Lakeflow Connect operates on a compute-based pricing model, ensuring efficiency and scalability for various data integration needs. The ingestion pipeline operates on serverless compute, which allows for flexibility in scaling based on demand and simplifies management by eliminating the need for users to configure and manage the underlying infrastructure.
However, it's important to note that while the ingestion pipeline can run on serverless compute, the ingestion gateway for database connectors currently operates on classic compute to simplify connections to the database source. As a result, users might see a combination of classic and serverless DLT DBU charges reflected in their billing.
The easiest way to track and monitor Lakeflow Connect usage is through system tables. Below is an example query to view a particular Lakeflow Connect pipeline’s usage:

The official pricing for Lakeflow Connect documentation (AWS | Azure | GCP) provides detailed rate information. Additional costs, such as serverless egress fees (pricing), may apply. Egress costs from the Cloud provider for classic compute can be found here (AWS | Azure | GCP).
Best Practices and Key Takeaways
As of May 2025, below are some of the best practices and considerations to follow when implementing this SQL Server connector:
- Configure each Ingestion Gateway to authenticate with a user or entity with access only to the replicated source database.
- Ensure the user is given the necessary permissions to create connections in UC and ingest the data.
- Utilize DABs to reliably configure Lakeflow Connect ingestion pipelines, ensuring repeatability and consistency in infrastructure management.
- For source tables with primary keys, enable Change Tracking to achieve lower overhead and improved performance.
- For source tables without a primary key, enable CDC due to its ability to capture changes at the column level, even without unique row identifiers.
Lakeflow Connect for SQL Server provides a fully managed, built-in integration for both on-premises and cloud databases for efficient, incremental ingestion into Databricks.
Next Steps & Additional Resources
Try the SQL Server connector today to help solve your data ingestion challenges. Follow the steps outlined in this blog or review the documentation. Learn more about Lakeflow Connect on the product page, view a product tour or view a demo of the Salesforce connector to help predict customer churn.
Databricks Delivery Solutions Architects (DSAs) accelerate Data and AI initiatives across organizations. They provide architectural leadership, optimize platforms for cost and performance, enhance developer experience, and drive successful project execution. DSAs bridge the gap between initial deployment and production-grade solutions, working closely with various teams, including data engineering, technical leads, executives, and other stakeholders to ensure tailored solutions and faster time to value. To benefit from a custom execution plan, strategic guidance, and support throughout your data and AI journey from a DSA, please contact your Databricks Account Team.
Appendix
In this optional step, to manage the Lakeflow Connect pipelines as code using DABs, you simply need to add two files to your existing bundle:
- A workflow file that controls the frequency of data ingestion (resources/sqlserver.yml).
- A pipeline definition file (resources/sqlserver_pipeline.yml).
resources/sqlserver.yml:
resources/sqlserver_job.yml:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.